제품 판매 데이터에 대한 변칙 검색 애플리케이션을 빌드하는 방법을 알아봅니다. 이 자습서에서는 Visual Studio에서 C#을 사용하여 .NET 콘솔 애플리케이션을 만듭니다.
이 튜토리얼에서는 다음을 배우게 됩니다:
- 데이터 로드
- 스파이크 이상 감지를 위한 변환 만들기
- 변환을 사용하여 급증 변칙 검색
- 변경 지점 변칙 검색을 위한 변환 만들기
- 변환을 사용하여 변경 지점 변칙 검색
이 자습서의 소스 코드는 dotnet/samples 리포지토리에서 찾을 수 있습니다.
필수 조건
.NET Desktop Development 워크로드가 설치된 Visual Studio 2022 이상.
비고
데이터 형식은 원래 DataMarket에서 product-sales.csv 공급되고 Rob Hyndman이 만든 TSDL(시계열 데이터 라이브러리)에서 제공하는 데이터 세트 "3년 동안의 샴푸 판매"를 기반으로 합니다.
DataMarket 기본 오픈 라이선스에 따라 라이선스가 부여된 "3년 동안의 샴푸 판매" 데이터 세트.
콘솔 애플리케이션 만들기
"ProductSalesAnomalyDetection"이라는 C# 콘솔 애플리케이션 을 만듭니다. 다음 단추를 클릭합니다.
사용할 프레임워크로 .NET 8을 선택합니다. 만들기 버튼을 클릭합니다.
프로젝트에 Data 라는 디렉터리를 만들어 데이터 집합 파일을 저장합니다.
Microsoft.ML NuGet 패키지를 설치합니다.
비고
이 샘플에서는 달리 명시되지 않는 한 언급된 안정적인 최신 버전의 NuGet 패키지를 사용합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다. 패키지 원본으로 "nuget.org"을 선택하고 찾아보기 탭을 선택하고 Microsoft.ML 검색한 다음 설치를 선택합니다. 변경 내용 미리 보기 대화 상자에서 확인단추를 선택한 다음, 나열된 패키지의 사용 조건에 동의하는 경우 라이선스 승인 대화 상자에서 동의 단추를 선택합니다. Microsoft.ML.TimeSeries에 대해 다음 단계를 반복합니다.
using파일의 맨 위에 다음 지시문을 추가합니다.using Microsoft.ML; using ProductSalesAnomalyDetection;
데이터 다운로드
데이터 세트를 다운로드하고 이전에 만든 데이터 폴더에 저장합니다.
product-sales.csv에서 마우스 오른쪽 버튼을 클릭하고 "링크(또는 대상) 다른 이름으로 저장…"을 선택합니다.
*.csv 파일을 데이터 폴더에 저장하거나 다른 곳에 저장한 후 *.csv 파일을 데이터 폴더로 이동해야 합니다.
솔루션 탐색기에서 *.csv 파일을 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다. 고급 탭에서 출력 디렉터리에 복사 설정을 새 버전인 경우에만 복사로 변경합니다.
다음 표는 *.csv 파일의 데이터 미리 보기입니다.
| Month | ProductSales |
|---|---|
| 1월 1일 | 271 |
| 1월 2일 | 150.9 |
| ..... | ..... |
| 2월 1일 | 199.3 |
| ..... | ..... |
클래스 만들기 및 경로 정의
다음으로 입력 및 예측 클래스 데이터 구조를 정의합니다.
프로젝트에 새 클래스를 추가합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭한 다음 새 항목 추가>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 ProductSalesData.cs 변경합니다. 그런 후 추가를 선택합니다.
ProductSalesData.cs 파일이 코드 편집기에서 열립니다.
using맨 위에 다음 지시문을 추가합니다.using Microsoft.ML.Data;기존 클래스 정의를 제거하고 두 개의 클래스가 있는 다음 코드를
ProductSalesData파일에 추가합니다ProductSalesPrediction.public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesData은 입력 데이터 클래스를 지정합니다. LoadColumn 특성은 데이터 세트에서 로드할 열(열 인덱스 기준)을 지정합니다.ProductSalesPrediction는 예측 데이터 클래스를 지정합니다. 변칙 검색의 경우 예측은 변칙, 원시 점수 및 p-값이 있는지 여부를 나타내는 경고로 구성됩니다. p-값이 0에 가까울수록 변칙이 발생했을 가능성이 높습니다.최근에 다운로드한 데이터 세트 파일 경로와 저장된 모델 파일 경로를 저장할 두 개의 전역 필드를 만듭니다.
-
_dataPath에는 모델을 학습시키는 데 사용되는 데이터 세트의 경로가 있습니다. -
_docsize에는 데이터 세트 파일의 레코드 수가 있습니다. 를 계산_docSize하는 데 사용합니다pvalueHistoryLength.
-
지시문 바로 아래 줄에
using다음 코드를 추가하여 해당 경로를 지정합니다.string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
변수 초기화
Console.WriteLine("Hello World!")다음 코드로 줄을 바꿔 변수를 선언하고 초기화합니다mlContext.MLContext mlContext = new MLContext();MLContext 클래스는 모든 ML.NET 작업의 시작점이며 초기화
mlContext하면 모델 생성 워크플로 개체 간에 공유할 수 있는 새 ML.NET 환경이 만들어집니다. 개념적으로DBContextEntity Framework와 유사합니다.
데이터 로드
ML.NET 데이터는 IDataView 인터페이스로 표시됩니다.
IDataView 는 테이블 형식 데이터(숫자 및 텍스트)를 유연하고 효율적으로 설명하는 방법입니다. 데이터는 텍스트 파일이나 다른 소스(예: SQL 데이터베이스 또는 로그 파일)에서 IDataView 개체로 로드할 수 있습니다.
변수를 만든 후 다음 코드를 추가합니다
mlContext.IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');LoadFromTextFile()은 데이터 스키마를 정의하고 파일에서 읽습니다. 데이터 경로 변수를 가져와서 .를
IDataView반환합니다.
시계열 변칙 검색
이상 탐지는 예기치 않거나 비정상적인 이벤트 또는 동작을 지목합니다. 그것은 문제를 찾을 수 있는 단서를 제공하고 "이것이 이상한가?"라는 질문에 대답하는 데 도움이 됩니다.

이상 탐지는 시계열 데이터의 이상값을 탐지하는 과정입니다. 이는 주어진 시계열 데이터에서 예상과 다른 방식으로 동작하는 지점을 식별하는 것을 의미합니다.
변칙 검색은 여러 가지 방법으로 유용할 수 있습니다. 예를 들면 다음과 같습니다.
자동차가 있는 경우 다음을 알고 싶을 수 있습니다. 이 오일 게이지가 정상인가요, 아니면 누출이 있습니까? 전력 소비를 모니터링하는 경우 다음을 알고 싶습니다. 가동 중단이 있나요?
다음 두 가지 유형의 시계열 변칙을 검색할 수 있습니다.
스파이크는 시스템에서 비정상적인 동작의 일시적인 현상을 나타냅니다.
변경 지점 은 시스템에서 시간이 지남에 따라 지속적인 변경의 시작을 나타냅니다.
ML.NET IID 스파이크 검색 또는 IID 변경 지점 검색 알고리즘은 독립적이고 동일하게 분산된 데이터 세트에 적합합니다. 입력 데이터는 하나의 고정 배포에서 독립적으로 샘플링되는 데이터 요소 시퀀스라고 가정합니다.
다른 자습서의 모델과 달리 시계열 변칙 탐지기 변환은 입력 데이터에서 직접 작동합니다. 이 메서드는 IEstimator.Fit() 변환을 생성하기 위해 학습 데이터가 필요하지 않습니다. 하지만 빈 목록에서 ProductSalesData생성된 데이터 뷰에서 제공하는 데이터 스키마가 필요합니다.
동일한 제품 판매 데이터를 분석하여 급증 및 변경 지점을 검색합니다. 빌드 및 학습 모델 프로세스는 스파이크 감지 및 변경 지점 검색과 동일합니다. 주요 차이점은 사용되는 특정 검색 알고리즘입니다.
스파이크 검출
스파이크 검색의 목표는 대부분의 시계열 데이터 값과 크게 다른 갑작스럽지만 일시적인 버스트를 식별하는 것입니다. 이러한 의심스러운 희귀 항목, 이벤트 또는 관찰을 적시에 감지하여 최소화하는 것이 중요합니다. 다음 방법을 사용하여 중단, 사이버 공격 또는 바이러스 성 웹 콘텐츠와 같은 다양한 변칙을 검색할 수 있습니다. 다음 이미지는 시계열 데이터 세트의 급증 예입니다.
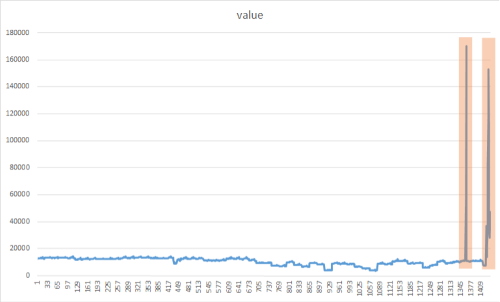
CreateEmptyDataView() 메서드 추가
다음 메서드를 다음 메서드에 추가합니다 Program.cs.
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
메서드 CreateEmptyDataView() 에 대한 입력으로 사용할 올바른 스키마를 사용하여 빈 데이터 뷰 개체를 IEstimator.Fit() 생성합니다.
DetectSpike() 메서드 만들기
DetectSpike() 메서드는 다음 작업을 수행합니다.
- 추정 모델로부터 변환을 생성합니다.
- 기록 판매 데이터를 기반으로 급증을 감지합니다.
- 결과를 표시합니다.
DetectSpike()다음 코드를 사용하여 Program.cs 파일의 맨 아래에 메서드를 만듭니다.DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }IidSpikeEstimator를 사용하여 스파이크 검색을 위한 모델을 학습시킵니다. 다음 코드를 사용하여
DetectSpike()메서드에 추가합니다.var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);다음 코드를
DetectSpike()메서드의 다음 줄로 추가하여 스파이크 감지 변환을 만드십시오.팁 (조언)
및
confidence매개 변수는pvalueHistoryLength급증이 감지되는 방식에 영향을 줍니다.confidence는 모델이 급증할 때 얼마나 중요한지를 결정합니다. 신뢰도가 낮을수록 알고리즘이 "더 작은" 스파이크를 감지할 가능성이 높습니다. 매개 변수는pvalueHistoryLength슬라이딩 윈도우의 데이터 요소 수를 정의합니다. 이 매개 변수의 값은 일반적으로 전체 데이터 세트의 백분율입니다. 낮을수록pvalueHistoryLength모델이 이전의 큰 급증을 잊는 속도가 빨라집니다.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));다음 코드 줄을
productSales데이터를DetectSpike()메서드의 다음 줄로 변환하기 위해 추가하십시오.IDataView transformedData = iidSpikeTransform.Transform(productSales);이전 코드는 Transform() 메서드를 사용하여 데이터 세트의 여러 입력 행에 대한 예측을 만듭니다.
다음 코드와 함께
transformedData메서드를 사용하여 보다 쉽게 표시할 수 있게 강력한 형식IEnumerable으로 변환합니다.var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);다음 Console.WriteLine() 코드를 사용하여 표시 헤더 줄을 만듭니다.
Console.WriteLine("Alert\tScore\tP-Value");스파이크 탐지 결과에 다음 정보를 표시합니다.
-
Alert는 지정된 데이터 요소에 대한 급증 경고를 나타냅니다. -
Score는ProductSales데이터 세트의 지정된 데이터 요소에 대한 값입니다. -
P-Value"P"는 확률을 의미합니다. p-값이 0에 가까울수록 데이터 요소가 변칙일 가능성이 높습니다.
-
다음 코드를 사용하여
predictionsIEnumerable를 반복하고 결과를 표시합니다.foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");메서드 호출
DetectSpike()아래에 메서드에 대한 호출을 추가합니다LoadFromTextFile().DetectSpike(mlContext, _docsize, dataView);
급증 검색 결과
결과는 다음과 유사해야 합니다. 처리하는 동안 메시지가 표시됩니다. 경고 또는 메시지 처리가 표시 될 수 있습니다. 명확성을 위해 다음 결과에서 일부 메시지가 제거되었습니다.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
변경 지점 검색
Change points 는 수준 변경 및 추세와 같은 값의 시계열 이벤트 스트림 분포에서 지속적인 변경 내용입니다. 이러한 영구적 변경은 치명적인 이벤트보다 spikes 훨씬 오래 지속되며 치명적인 이벤트를 나타낼 수 있습니다.
Change points 는 일반적으로 육안으로 표시되지 않지만 다음 방법과 같은 방법을 사용하여 데이터에서 검색할 수 있습니다. 다음 이미지는 변경 지점 검색의 예입니다.
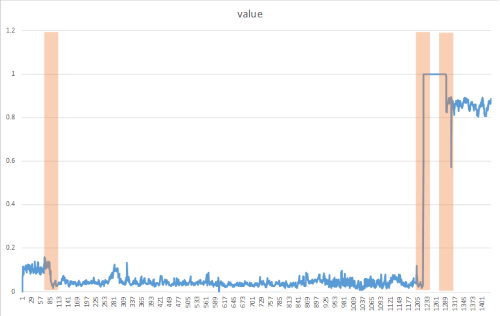
DetectChangepoint() 메서드 만들기
메서드는 DetectChangepoint() 다음 작업을 실행합니다.
- 추정 모델로부터 변환을 생성합니다.
- 기록 판매 데이터를 기반으로 변경 지점을 검색합니다.
- 결과를 표시합니다.
DetectChangepoint()다음 코드를 사용하여 메서드 선언 바로 다음에DetectSpike()메서드를 만듭니다.void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }다음 코드를 사용하여 메서드에서
DetectChangepoint()를 만듭니다.var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);앞에서 했던 것처럼,
DetectChangePoint()메서드에 다음 코드 줄을 추가하여 추정기로부터 변환을 생성합니다.팁 (조언)
변경 지점의 검색은 모델이 경고를 만들기 전에 일부 임의 급증이 아니라 현재 편차가 영구적 변경인지 확인해야 하기 때문에 약간의 지연으로 발생합니다. 이 지연의 양은 매개 변수와
changeHistoryLength같습니다. 이 매개 변수의 값을 늘리면 변경 검색 경고가 더 지속적인 변경에 대해 경고하지만 장차는 더 긴 지연이 될 수 있습니다.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));메서드를
Transform()사용하여 다음 코드를 추가하여 데이터를 변환합니다DetectChangePoint().IDataView transformedData = iidChangePointTransform.Transform(productSales);앞에서 했던 것처럼 다음 코드와 함께 메서드를 사용하여
transformedData보다 쉽게 표시할 수 있는 강력한 형식IEnumerable으로 변환합니다CreateEnumerable().var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);다음 코드를 메서드의 다음 줄로 사용하여 표시 헤더를
DetectChangePoint()만듭니다.Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");변경 지점 검색 결과에 다음 정보를 표시합니다.
-
Alert는 지정된 데이터 요소에 대한 변경 지점 경고를 나타냅니다. -
Score는ProductSales데이터 세트의 지정된 데이터 요소에 대한 값입니다. -
P-Value"P"는 확률을 의미합니다. P-값이 0에 가까울수록 데이터 요소가 변칙일 가능성이 높습니다. -
Martingale value는 P 값의 시퀀스를 기반으로 데이터 요소의 "이상한"을 식별하는 데 사용됩니다.
-
다음 코드를 사용하여
predictionsIEnumerable결과를 반복하고 표시합니다.foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");메서드를 호출한 후 메서드에
DetectChangepoint()다음 호출을 추가합니다DetectSpike().DetectChangepoint(mlContext, _docsize, dataView);
변경 지점 검색 결과
결과는 다음과 유사해야 합니다. 처리하는 동안 메시지가 표시됩니다. 경고 또는 메시지 처리가 표시 될 수 있습니다. 명확성을 위해 다음 결과에서 일부 메시지가 제거되었습니다.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
축하합니다! 이제 판매 데이터의 급증 및 변경 지점 변칙을 검색하기 위한 기계 학습 모델을 성공적으로 빌드했습니다.
이 자습서의 소스 코드는 dotnet/samples 리포지토리에서 찾을 수 있습니다.
이 자습서에서는 다음 방법을 알아보았습니다.
- 데이터 로드
- 급증 변칙 검색을 위한 모델 학습
- 학습된 모델을 사용하여 급증 변칙 검색
- 변경 지점 변칙 검색을 위한 모델 학습
- 학습된 모드를 사용하여 변경 지점 변칙 검색
다음 단계
Machine Learning 샘플 GitHub 리포지토리를 확인하여 계절성 데이터 변칙 검색 샘플을 살펴봅니다.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET