System.IO.Pipelines는 .NET에서 고성능 I/O를 더 쉽게 수행할 수 있도록 설계된 라이브러리입니다. .NET Standard를 대상으로 하며 모든 .NET 구현에서 작동하는 라이브러리입니다.
라이브러리는 System.IO.Pipelines Nuget 패키지에서 사용할 수 있습니다.
System.IO.Pipelines이 해결하는 문제
스트리밍 데이터를 구문 분석하는 앱은 특수하고 비정상적인 코드 흐름이 많은 상용구 코드로 구성됩니다. 상용구와 특수 사례 코드는 복잡하고 유지관리가 어렵습니다.
System.IO.Pipelines는 다음을 위해 설계되었습니다.
- 고성능 스트리밍 데이터 구문 분석 수행
- 코드 복잡성 감소
다음 코드는 클라이언트에서 줄로 구분된 메시지를 수신하는 TCP 서버('\n'으로 구분됨)에서 일반적입니다.
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
위의 코드에는 몇 가지 문제가 있습니다.
-
ReadAsync에 대한 단일 호출에서 전체 메시지(줄의 끝)를 수신하지 못할 수 있습니다. -
stream.ReadAsync의 결과를 무시합니다.stream.ReadAsync가 읽은 데이터의 양을 반환합니다. - 단일
ReadAsync호출에서 여러 줄을 읽는 경우를 처리하지 않습니다. - 각 읽기에
byte배열을 할당합니다.
위의 문제를 해결하려면 다음과 같이 변경해야 합니다.
새 줄을 찾을 때까지 들어오는 데이터를 버퍼링합니다.
버퍼에 반환된 모든 줄을 구문 분석합니다.
줄이 1KB(1024바이트)보다 클 수 있습니다. 버퍼 내부의 전체 줄을 맞추려면 구분 기호를 찾을 때까지 코드에서 입력 버퍼의 크기를 조정해야 합니다.
- 버퍼 크기를 조정하는 경우 입력에 더 긴 줄이 표시되면 더 많은 버퍼 복사본이 생성됩니다.
- 불필요한 공간을 줄이려면 줄 읽기에 사용되는 버퍼를 압축합니다.
메모리를 반복해서 할당하지 않도록 버퍼 풀링을 사용하는 것이 좋습니다.
다음 코드는 이러한 문제 중 일부를 해결합니다.
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
이전 코드는 복잡하며, 식별된 모든 문제를 해결하지는 않습니다. 고성능 네트워킹은 일반적으로 성능을 최대화하는 매우 복잡한 코드를 작성하는 것을 의미합니다.
System.IO.Pipelines는 이러한 종류의 코드 작성을 더 쉽게 만들기 위해 설계되었습니다.
파이프
Pipe 클래스를 사용하여 PipeWriter/PipeReader 쌍을 만들 수 있습니다.
PipeWriter에 작성된 모든 데이터는 PipeReader에서 사용할 수 있습니다.
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
파이프 기본 사용 방법
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
두 가지 루프가 있습니다.
-
FillPipeAsync는Socket에서 읽고PipeWriter에 씁니다. -
ReadPipeAsync는PipeReader에서 읽고 들어오는 줄을 구문 분석합니다.
할당된 명시적 버퍼가 없습니다. 모든 버퍼 관리는 PipeReader 및 PipeWriter 구현에 위임됩니다. 버퍼 관리를 위임하면 더 쉽게 코드 사용을 비즈니스 논리에만 집중할 수 있습니다.
첫 번째 루프에서 다음을 수행합니다.
- PipeWriter.GetMemory(Int32)는 기본 작성기에서 메모리를 가져오기 위해 호출됩니다.
-
PipeWriter.Advance(Int32)는 버퍼에 기록된 데이터의 양을
PipeWriter에 알리기 위해 호출됩니다. -
PipeWriter.FlushAsync는
PipeReader에서 데이터를 사용할 수 있도록 호출됩니다.
두 번째 루프에서 PipeReader는 PipeWriter로 작성된 버퍼를 사용합니다. 버퍼는 소켓에서 나옵니다.
PipeReader.ReadAsync에 대한 호출:
두 가지 중요 한 정보를 포함하는 ReadResult를 반환합니다.
-
ReadOnlySequence<byte>형식으로 읽은 데이터입니다. - EOF(데이터의 끝)에 도달했는지 여부를 나타내는 부울
IsCompleted입니다.
-
EOL(줄의 끝) 구분 기호를 찾은 후 줄을 구문 분석합니다.
- 논리는 버퍼를 처리하여 이미 처리된 작업을 건너뜁니다.
-
PipeReader.AdvanceTo를 호출하여 사용되고 검사된 데이터의 양을PipeReader에 알려줍니다.
판독기 및 작성기 루프는 Complete를 호출하여 종료됩니다.
Complete는 기본 파이프가 할당된 메모리를 해제하도록 합니다.
역 압력 및 흐름 제어
다음과 같이 읽기와 구문 분석이 함께 작동하는 것이 가장 좋습니다.
- 쓰기 스레드는 네트워크의 데이터를 사용하며 이를 버퍼에 저장합니다.
- 구문 분석 스레드는 적절한 데이터 구조를 생성합니다.
일반적으로 다음과 같은 이유로 인해 구문 분석에는 네트워크에서 데이터 블록을 복사하는 것보다 시간이 더 걸립니다.
- 읽기 스레드가 구문 분석 스레드 앞에 있습니다.
- 읽기 스레드의 속도가 느려야 하거나 구문 분석 스레드에 대한 데이터를 저장하기 위해 더 많은 메모리를 할당해야 합니다.
성능을 최적화하기 위해 잦은 일시 중지와 더 많은 메모리 할당 사이에서 균형을 유지합니다.
위의 문제를 해결하기 위해 Pipe에는 데이터 흐름을 제어하는 두 가지 설정이 있습니다.
- PauseWriterThreshold: FlushAsync 일시 중지를 호출하기 전에 버퍼링되어야 하는 데이터의 양을 결정합니다.
-
ResumeWriterThreshold:
PipeWriter.FlushAsync호출을 다시 시작하기 전에 판독기가 관찰해야 하는 데이터의 양을 결정합니다.
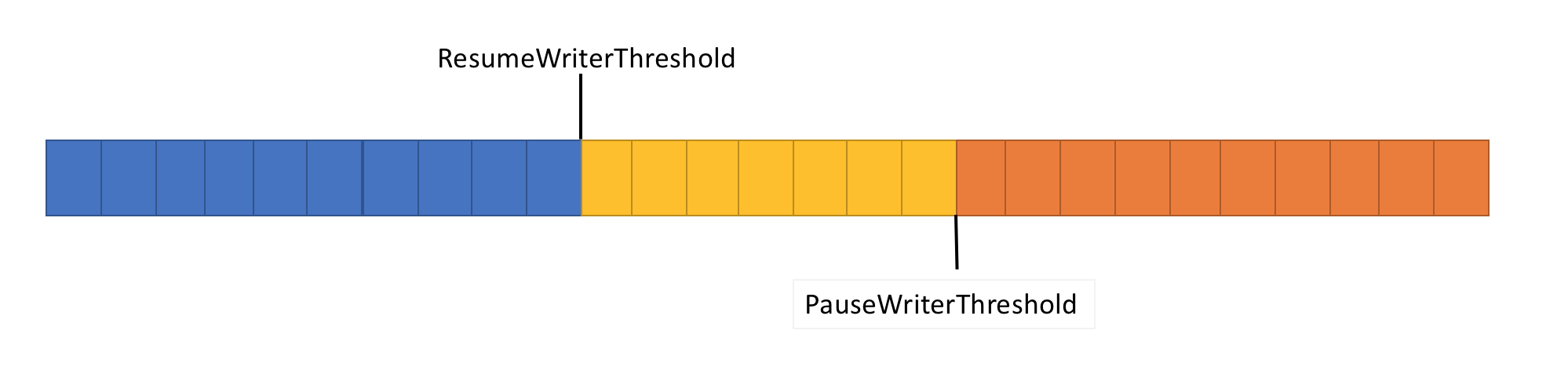
:
-
ValueTask<FlushResult>의 데이터 크기가Pipe를 넘으면 불완전한PauseWriterThreshold를 반환합니다. -
ValueTask<FlushResult>보다 작으면ResumeWriterThreshold가 완료됩니다.
하나의 값이 사용될 경우 발생할 수 있는 빠른 순환을 방지하기 위해 두 값이 사용됩니다.
예제
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
파이프 스케줄러
일반적으로 async 및 await를 사용하는 경우 비동기 코드는 TaskScheduler 또는 현재 SynchronizationContext에서 다시 시작됩니다.
I/O를 수행하는 경우 I/O가 수행되는 위치를 세부적으로 제어하는 것이 중요합니다. 이 컨트롤을 사용하면 CPU 캐시를 효과적으로 활용할 수 있습니다. 효율적인 캐싱은 웹 서버와 같은 고성능 앱에 매우 중요합니다. PipeScheduler는 비동기 콜백이 실행되는 위치에 대한 제어를 제공합니다. 기본적으로:
- 현재 SynchronizationContext가 사용됩니다.
-
SynchronizationContext가 없으면 스레드 풀을 사용하여 콜백을 실행합니다.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool은 스레드 풀에 대한 콜백을 큐에 대기시키는 PipeScheduler 구현입니다.
PipeScheduler.ThreadPool은 기본값이며 일반적으로 최상의 선택입니다.
PipeScheduler.Inline은 교착 상태와 같은 의도하지 않은 결과를 발생시킬 수 있습니다.
파이프 다시 설정
Pipe 개체를 다시 사용하는 것이 효율적인 경우가 많습니다. 파이프를 다시 설정하려면 PipeReader와 Reset가 모두 완료될 때 PipeReaderPipeWriter을 호출합니다.
PipeReader
PipeReader는 호출자를 대신하여 메모리를 관리합니다.
항상PipeReader.AdvanceTo를 호출한 후 PipeReader.ReadAsync를 호출합니다. 이를 통해 PipeReader는 호출자가 메모리를 작업을 완료하는 시기를 알 수 있어서 메모리를 추적할 수 있습니다.
ReadOnlySequence<byte>에서 반환된 PipeReader.ReadAsync는 PipeReader.AdvanceTo를 호출할 때까지만 유효합니다.
ReadOnlySequence<byte>를 호출한 후에는 PipeReader.AdvanceTo를 사용할 수 없습니다.
PipeReader.AdvanceTo는 두 개의 SequencePosition 인수를 사용합니다.
- 첫 번째 인수는 사용된 메모리의 양을 결정합니다.
- 두 번째 인수는 관찰된 버퍼의 양을 결정합니다.
데이터를 사용됨으로 표시하면 파이프가 메모리를 기본 버퍼 풀로 반환할 수 있다는 의미입니다. 데이터를 관찰됨으로 표시하면 PipeReader.ReadAsync에 대한 다음 호출의 수행 내용을 제어합니다. 모든 항목을 관찰됨으로 표시하면 파이프에 더 많은 데이터를 쓸 때까지 PipeReader.ReadAsync에 대한 다음 호출이 반환되지 않는다는 의미입니다. 다른 모든 값을 사용하면 PipeReader.ReadAsync에 대한 다음 호출이 관찰된 데이터 ‘및’ 관찰되지 않은 데이터로 즉시 반환되지만 이미 사용된 데이터는 반환되지 않습니다.
스트리밍 데이터 읽기 시나리오
스트리밍 데이터를 읽으려고 할 때 나타나는 몇 가지 일반적인 패턴은 다음과 같습니다.
- 데이터 스트림이 지정된 경우 단일 메시지를 구문 분석합니다.
- 데이터 스트림이 지정된 경우 사용 가능한 모든 메시지를 구문 분석합니다.
다음 예에서는 TryParseLines의 메시지를 구문 분석하는 데 ReadOnlySequence<byte> 메서드를 사용합니다.
TryParseLines는 단일 메시지를 구문 분석하고 입력 버퍼를 업데이트하여 버퍼에서 구문 분석된 메시지를 자릅니다.
TryParseLines는 .NET의 일부가 아니므로 다음 섹션에서 사용되는 사용자 작성 메서드입니다.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
단일 메시지 읽기
다음 코드는 PipeReader에서 단일 메시지를 읽고 호출자에게 반환합니다.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
앞의 코드가 하는 역할은 다음과 같습니다.
- 단일 메시지를 구문 분석합니다.
- 사용된
SequencePosition을 업데이트하고SequencePosition을 검사하여 잘린 입력 버퍼의 시작을 가리킵니다.
SequencePosition는 입력 버퍼에서 구문 분석된 메시지를 제거하므로 두 개의 TryParseLines 인수가 업데이트됩니다. 일반적으로 버퍼에서 단일 메시지를 구문 분석할 때 검사된 위치는 다음 중 하나여야 합니다.
- 메시지 끝
- 메시지를 찾을 수 없는 경우 받은 버퍼의 끝
단일 메시지 사례에서 오류가 발생할 가능성이 가장 높습니다. 검사됨으로 잘못된 값을 전달하면 메모리 부족 예외 또는 무한 루프가 발생할 수 있습니다. 자세한 내용은 이 문서의 PipeReader의 일반적인 문제 섹션을 참조하세요.
여러 메시지 읽기
다음 코드는 PipeReader에서 모든 메시지를 읽고 각각에 대해 ProcessMessageAsync를 호출합니다.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
취소
:
- CancellationToken 전달을 지원합니다.
- 읽기 보류 중에 OperationCanceledException이 취소되는 경우
CancellationToken이 throw됩니다. -
PipeReader.CancelPendingRead을 통해 현재 읽기 작업을 취소하는 방법을 지원하여 예외 증가를 방지합니다.
PipeReader.CancelPendingRead를 호출하면PipeReader.ReadAsync에 대한 현재 또는 다음 호출이 ReadResult가IsCanceled로 설정된true를 반환합니다. 이는 기존 읽기 루프를 비파괴적이고 예외 없는 방식으로 중지하는 데 유용할 수 있습니다.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
PipeReader의 일반적인 문제
consumed또는examined에 잘못된 값을 전달하면 이미 읽은 데이터를 읽을 수 있습니다.buffer.End를 검사됨으로 전달하면 다음과 같은 결과를 초래할 수 있습니다.- 중단된 데이터
- 데이터가 사용되지 않는 경우 OOM(메모리 부족) 예외 발생 (예: 버퍼에서 한 번에 하나의 메시지를 처리하는 경우
PipeReader.AdvanceTo(position, buffer.End))
consumed또는examined에 잘못된 값을 전달하면 무한 루프가 발생할 수 있습니다. 예를 들어PipeReader.AdvanceTo(buffer.Start)는buffer.Start이 변경되지 않은 경우PipeReader.ReadAsync에 대한 다음 호출이 새 데이터가 도착하기 전에 즉시 반환되도록 합니다.consumed또는examined에 잘못된 값을 전달하면 무한 버퍼링(최종 OOM)이 발생할 수 있습니다.ReadOnlySequence<byte>를 호출한 후PipeReader.AdvanceTo를 사용하면 메모리가 손상될 수 있습니다(사용 가능해진 이후 사용).PipeReader.Complete/CompleteAsync를 호출하지 못하면 메모리 누수가 발생할 수 있습니다.버퍼를 처리하기 전에 ReadResult.IsCompleted를 확인하고 읽기 논리를 종료하면 데이터 손실이 발생합니다. 루프 종료 조건은
ReadResult.Buffer.IsEmpty및ReadResult.IsCompleted를 기반으로 해야 합니다. 이렇게 하면 무한 루프가 잘못 발생할 수 있습니다.
문제 코드
❌ 데이터 손실
ReadResult가 IsCompleted로 설정된 경우 true는 최종 데이터 세그먼트를 반환할 수 있습니다. 읽기 루프를 종료하기 전에 해당 데이터를 읽지 않으면 데이터가 손실됩니다.
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
❌ 무한 루프
Result.IsCompleted가 true이지만 버퍼에 완전한 메시지가 없는 경우 다음 논리로 인해 무한 루프가 발생할 수 있습니다.
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
동일한 문제가 있는 또 다른 코드는 다음과 같습니다.
ReadResult.IsCompleted를 확인하기 전에 비어 있지 않은 버퍼를 확인하는 것입니다.
else if이기 때문에 버퍼에 완전한 메시지가 없는 경우 무한 반복됩니다.
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
❌ 응답하지 않는 애플리케이션
PipeReader.AdvanceTo 위치에서 buffer.End를 사용하여 examined을 무조건 호출하면 단일 메시지를 구문 분석할 때 애플리케이션이 응답하지 않을 수 있습니다.
PipeReader.AdvanceTo에 대한 다음 호출은 다음까지 반환되지 않습니다.
- 파이프에 기록된 데이터가 더 있음
- 새 데이터는 이전에 검사되지 않았음
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
❌ OOM(메모리 부족)
다음 조건에서 다음 코드는 OutOfMemoryException이 발생할 때까지 버퍼링을 유지합니다.
- 최대 메시지 크기가 없습니다.
-
PipeReader에서 반환된 데이터는 완전한 메시지를 생성하지 않습니다. 예를 들어, 다른 쪽에서 매우 용량이 큰 메시지(예: 4GB 메시지)를 작성하기 때문에 완전한 메시지를 생성하지 않습니다.
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
❌ 메모리 손상
버퍼를 읽는 도우미를 작성하는 경우 Advance를 호출하기 전에 반환된 모든 페이로드를 복사해야 합니다. 다음 예제에서는 Pipe가 버렸고 다음 작업(읽기/쓰기)에 다시 사용할 수도 있는 메모리를 반환합니다.
경고
다음 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 다음 샘플은 PipeReader의 일반적인 문제 를 설명하기 위해 제공됩니다.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
경고
앞의 코드를 사용하지 마세요. 이 샘플을 사용하면 데이터가 손실되거나 중단되고 보안 문제가 발생하며, 복사되지 않습니다. 위의 샘플은 PipeReader 일반적인 문제를 설명하기 위해 제공됩니다.
PipeWriter
PipeWriter는 호출자를 대신해 쓰기 위한 버퍼를 관리합니다.
PipeWriter는 IBufferWriter<byte>를 구현합니다.
IBufferWriter<byte>는 추가 버퍼 복사본 없이 쓰기를 수행하기 위해 버퍼에 액세스할 수 있습니다.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
이전 코드는 다음과 같습니다.
-
PipeWriter을 사용하여 GetMemory에서 최소 5바이트의 버퍼를 요청합니다. - 반환된
"Hello"에 ASCII 문자열Memory<byte>를 위한 바이트를 씁니다. - Advance를 호출하여 버퍼에 쓴 바이트 수를 표시합니다.
- 기본 디바이스로 바이트를 전송하는
PipeWriter를 플러시합니다.
이전 작성 메서드에서는 PipeWriter에서 제공하는 버퍼를 사용합니다.
PipeWriter.WriteAsync을 사용할 수도 있습니다.
- 기존 버퍼를
PipeWriter에 복사합니다. -
GetSpan,Advance를 적절하게 호출하고 FlushAsync를 호출합니다.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
취소
FlushAsync에서는 CancellationToken 전달을 지원합니다.
CancellationToken을 전달하면 플러시가 보류 중인 동안 토큰이 취소되는 경우 OperationCanceledException을 반환됩니다.
PipeWriter.FlushAsync는 예외를 발생시키지 않고 PipeWriter.CancelPendingFlush을 통해 현재 플러시 작업을 취소하는 메서드를 지원합니다.
PipeWriter.CancelPendingFlush를 호출하면 PipeWriter.FlushAsync 또는 PipeWriter.WriteAsync에 대한 현재 또는 다음 호출이 FlushResult가 IsCanceled로 설정된 true를 반환합니다. 이는 생성 플러시를 비파괴적이고 예외 없는 방식으로 중지하는 데 유용할 수 있습니다.
PipeWriter의 일반적인 문제
- GetSpan 및 GetMemory는 적어도 요청된 양의 메모리를 포함하는 버퍼를 반환합니다. 정확한 버퍼 크기를 가정하지 마세요.
- 연속 호출이 동일한 버퍼 또는 동일한 크기의 버퍼를 반환한다는 보장은 없습니다.
- 추가 데이터를 계속 작성하려면 Advance를 호출한 후 새 버퍼를 요청해야 합니다. 이전에 획득한 버퍼에 쓸 수 없습니다.
-
GetMemory또는GetSpan을 호출하면FlushAsync에 대한 불완전한 호출이 안전하지 않습니다. - 플러시된 데이터가 없는 상태에서
Complete또는CompleteAsync를 호출하면 메모리가 손상될 수 있습니다.
PipeReader 및 PipeWriter를 사용하기 위한 팁
다음 팁은 System.IO.Pipelines 클래스를 성공적으로 사용하는 데 도움이 됩니다.
- 해당하는 경우 예외를 포함하여 항상 PipeReader 및 PipeWriter를 완료합니다.
- 항상 PipeReader.AdvanceTo를 호출한 후 PipeReader.ReadAsync를 호출합니다.
- 정기적으로
awaitPipeWriter.FlushAsync 글을 쓰는 동안 항상 FlushResult.IsCompleted를 확인합니다. 읽기 프로그램이 완료되었으며 더 이상 작성된 내용에 대해 신경 쓰지 않음을 나타내기 때문에IsCompleted가true이면 쓰기 중단합니다. -
PipeWriter.FlushAsync가 액세스할 수 있도록 항목을 작성한 후
PipeReader를 호출합니다. -
FlushAsync를 완료할 때까지 판독기를 시작할 수 없는 경우 교착 상태가 발생할 수 있으므로FlushAsync을 호출하지 마세요. - 하나의 컨텍스트만
PipeReader또는PipeWriter를 “소유”하거나 액세스하는지 확인합니다. 이러한 형식은 스레드로부터 안전하지 않습니다. -
ReadResult.Buffer를 호출하거나
AdvanceTo을 완료한 후에는PipeReader에 액세스하지 않습니다.
IDuplexPipe
IDuplexPipe는 읽기와 쓰기를 모두 지원하는 형식에 대한 계약입니다. 예를 들어 네트워크 연결은 IDuplexPipe로 표시됩니다.
Pipe 및 PipeReader를 포함하는 PipeWriter와 달리 IDuplexPipe는 전이중 연결의 단일 측면을 나타냅니다. 이는 PipeWriter로 쓴 내용이 PipeReader에서 읽히지 않는다는 의미입니다.
스트림
스트림 데이터를 읽거나 쓸 때는 일반적으로 역직렬 변환기를 사용하여 데이터를 읽고 직렬 변환기를 사용하여 데이터를 씁니다. 대부분의 읽기 및 쓰기 스트림 API에는 Stream 매개 변수가 있습니다. 기존 API와 더욱 쉽게 통합할 수 있도록 PipeReader 및 PipeWriter는 AsStream 메서드를 제공합니다.
AsStream은 Stream 또는 PipeReader 주위에 PipeWriter 구현을 반환합니다.
스트림 예제
PipeReader 개체와 선택적으로 해당하는 생성 옵션이 제공된 경우 정적 PipeWriter 메서드를 사용하여 Create 및 Stream 인스턴스를 만들 수 있습니다.
StreamPipeReaderOptions를 사용하면 다음 매개 변수로 PipeReader 인스턴스 생성을 제어할 수 있습니다.
-
StreamPipeReaderOptions.BufferSize은 풀에서 메모리를 대여할 때 사용되는 최소 버퍼 크기(바이트)이며, 기본값은
4096입니다. -
StreamPipeReaderOptions.LeaveOpen 플래그는
PipeReader가 완료된 후 기본 스트림을 열어 둘지 여부를 결정하며, 기본값은false입니다. -
StreamPipeReaderOptions.MinimumReadSize은 새 버퍼가 할당되기 전에 버퍼에 남은 바이트의 임계값을 나타내며, 기본값은
1024입니다. -
StreamPipeReaderOptions.Pool은 메모리를 할당할 때 사용되는
MemoryPool<byte>이며, 기본값은null입니다.
StreamPipeWriterOptions를 사용하면 다음 매개 변수로 PipeWriter 인스턴스 생성을 제어할 수 있습니다.
-
StreamPipeWriterOptions.LeaveOpen 플래그는
PipeWriter가 완료된 후 기본 스트림을 열어 둘지 여부를 결정하며, 기본값은false입니다. -
StreamPipeWriterOptions.MinimumBufferSize은 Pool에서 메모리를 대여할 때 사용할 최소 버퍼 크기를 나타내며, 기본값은
4096입니다. -
StreamPipeWriterOptions.Pool은 메모리를 할당할 때 사용되는
MemoryPool<byte>이며, 기본값은null입니다.
중요합니다
PipeReader 메서드를 사용하여 PipeWriter 및 Create 인스턴스를 만드는 경우 Stream 개체 수명을 고려해야 합니다. 판독기 또는 기록기 작업이 완료된 후 스트림에 액세스해야 하는 경우 생성 옵션의 LeaveOpen 플래그를 true로 설정해야 합니다. 그러지 않으면 스트림이 닫힙니다.
다음 코드는 스트림에서 PipeReader 메서드를 사용하여 PipeWriter 및 Create 인스턴스를 만드는 방법을 보여 줍니다.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
애플리케이션은 StreamReader파일을 스트림으로 읽는 데 을 사용하며 빈 줄로 끝나야 합니다.
FileStream이 PipeReader.Create 개체를 인스턴스화하는 PipeReader에 전달됩니다. 그런 다음, 콘솔 애플리케이션이 PipeWriter.Create을 사용하여 표준 출력 스트림을 Console.OpenStandardOutput()에 전달합니다. 이 예제에서는 취소를 지원합니다.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET