사용자 지정 Spark 풀을 사용하여 패브릭에서 워크로드에 맞게 컴퓨팅을 조정합니다. 노드 크기를 선택하고, 자동 크기 조정 동작을 구성하고, 동적 실행기 할당을 사용하도록 설정할 수 있습니다.
사용자 지정 풀을 사용하면 워크로드 수요와 일치하는 크기 조정 제한을 설정하여 성능과 비용의 균형을 맞출 수 있습니다.
메모
사용자 지정 Spark 풀은 라이브러리 게시에 전체 모드를 사용하는 환경이 있는 사용자 지정 라이브 풀 로 구성된 경우 약 5초의 세션 시작을 달성할 수 있습니다. 라이브 풀 구성이 없으면 사용자 지정 Spark 풀을 시작하는 데 약 3분이 걸립니다.
이미 시작 풀을 사용하는 경우 사용자 지정 풀은 특정 워크로드의 크기 조정 및 크기 조정 동작에 대한 더 많은 제어가 필요한 경우 보완적인 옵션입니다. 빠른 시작 및 기본 설정에 시작 풀을 사용하고 워크로드별 컴퓨팅 튜닝이 필요할 때 사용자 지정 풀로 이동합니다. 시작 풀에 대한 자세한 내용은 Fabric에서 시작 풀 구성을 참조하세요.
필수 조건
사용자 지정 Spark 풀을 만들려면 다음을 수행합니다.
- 작업 영역에서 관리자 역할이 필요합니다.
- 용량 관리자는 용량에 대해 Spark Compute 설정에서 사용자 지정된 작업 영역 풀을 사용하도록 설정해야 합니다.
자세한 내용은 패브릭 용량에 대한 데이터 엔지니어링 및 데이터 과학 설정 구성 및 관리를 참조하세요.
사용자 지정 Spark 풀을 만듭니다.
작업 영역과 연결된 Spark 풀을 만들거나 관리하려면 다음을 수행합니다.
작업 영역으로 이동하여 작업 영역 설정을 선택합니다.

데이터 엔지니어링/과학 옵션을 선택하여 메뉴를 확장한 다음, Spark 설정선택합니다.
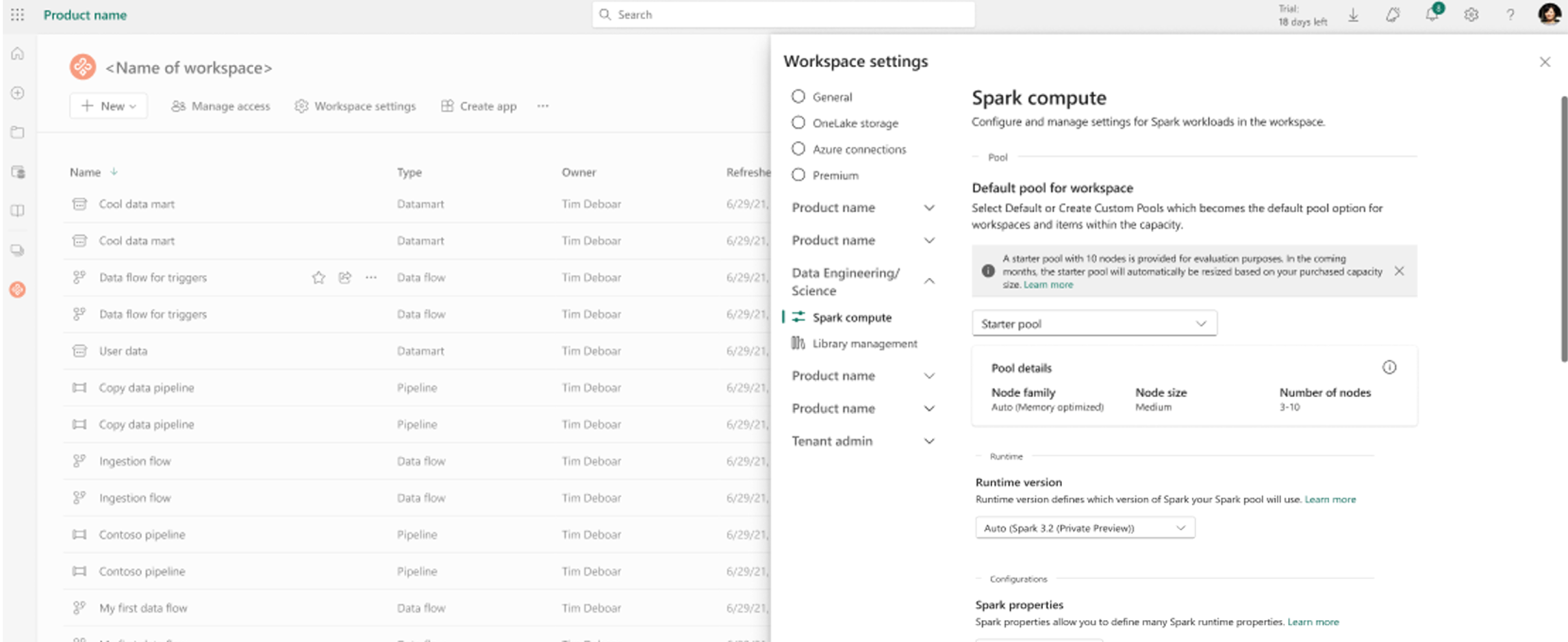
작업 영역 드롭다운에 대한 기본 풀에서 새 풀을 선택하여 새 사용자 지정 Spark 풀을 만듭니다. 여러 사용자 지정 풀을 만들고 작업 영역의 기본 풀로 선택할 수 있습니다.
새 풀 만들기 페이지에서 풀 이름을 입력합니다. 워크로드 요구 사항에 따라 노드 패밀리 (예: 메모리 최적화) 및 노드 크기를 선택합니다. 노드 크기에 대한 자세한 내용은 아래 의 노드 크기 옵션 섹션을 참조하세요.
팁 (조언)
노드 크기는 각 노드에 할당된 컴퓨팅 용량을 나타내는 CU(용량 단위)에 따라 결정됩니다.

편집 보기에서 자동 크기 조정 을 구성하고 실행기를 동적으로 할당합니다.

슬라이더를 사용하여 워크로드 요구 사항에 따라 각 설정을 늘리거나 줄입니다.
자동 크기 조정을 사용하는 경우 풀은 활동에 따라 구성된 최소 노드 값과 최대 노드 값 사이의 크기를 조정합니다.
동적으로 할당 실행기를 사용하는 경우 Fabric은 구성된 범위 내에서 워크로드 수요에 따라 실행기 할당을 조정합니다.
선택하고생성합니다.




팁 (조언)
사용자 지정 Spark 풀을 만든 후 라이브러리 배포 타이밍은 연결된 환경의 게시 모드에 따라 달라집니다. 빠른 모드는 약 5초 안에 게시되고 세션 시작 시 라이브러리를 설치합니다. 전체 모드는 세션 시작의 일부로 라이브러리를 게시하고 배포하는 데 3~6분이 걸립니다(1~3분). 가장 빠른 환경을 위해 풀을 전체 모드의 사용자 지정 라이브 풀 로 구성하여 약 5초의 세션 시작을 달성합니다.
사용자 지정 풀의 기본 자동 일시 중지 기간은 비활성 후 2분입니다. 자동 일시 중지에 도달하면 세션이 만료되고 클러스터의 할당이 취소됩니다. 청구는 컴퓨팅이 적극적으로 사용되는 동안에만 적용됩니다. Microsoft Fabric 사용자 지정 Spark 풀은 현재 최대 노드 한도인 200을 지원하므로 최소 및 최대 자동 크기 조정 값이 이 제한 내에 남아 있는지 확인합니다.
노드 크기 옵션
사용자 지정 Spark 풀을 설정할 때 다음 노드 크기 중에서 선택합니다.
| 노드 크기 | vCores | 메모리(GB) | 설명 |
|---|---|---|---|
| 소형 | 4 | 32 | 경량 개발 및 테스트 작업의 경우. |
| 미디엄 | 8 (여덟) | 64 | 일반 워크로드 및 일반적인 작업의 경우 |
| 크다 | 16 | 128 | 메모리 집약적 작업 또는 대용량 데이터 처리 작업의 경우 |
| X-Large | 32 | 256 | 상당한 리소스가 필요한 가장 까다로운 Spark 워크로드의 경우. |
| XX-Large | 64 | 512 | 노드당 가장 높은 컴퓨팅 및 메모리가 필요한 가장 큰 Spark 워크로드의 경우 |
관련 콘텐츠
- Apache Spark 공개 문서에서 자세히 알아보세요.
- Microsoft FabricSpark 작업 영역 관리 설정을 시작합니다>.
- 패브릭 환경에서 라이브러리 관리