파이프라인에서 복사 작업을 사용하여 클라우드의 데이터 저장소 간에 데이터를 복사할 수 있습니다. 데이터를 복사한 후 파이프라인의 다른 활동을 사용하여 데이터를 변환하고 분석할 수 있습니다.
복사 작업은 데이터 원본 및 대상에 연결한 다음 데이터 간에 데이터를 효율적으로 이동합니다. 서비스에서 복사 프로세스를 처리하는 방법은 다음과 같습니다.
- 원본에 연결: 원본 데이터 저장소에서 데이터를 읽는 보안 연결을 만듭니다.
- 데이터 처리: 구성에 따라 serialization/deserialization, 압축/압축 해제, 열 매핑 및 데이터 형식 변환을 처리합니다.
- 대상에 쓰기: 처리된 데이터를 대상 데이터 저장소로 전송합니다.
- 모니터링 제공: 복사 작업을 추적하고 문제 해결 및 최적화를 위한 자세한 로그 및 메트릭을 제공합니다.
Tip
데이터만 복사해야 하고 변환이 필요하지 않은 경우 복사 작업이 더 나은 옵션이 될 수 있습니다. 복사 작업은 전체 파이프라인을 만들 필요가 없는 데이터 이동 시나리오에 대한 간소화된 환경을 제공합니다. 참조: 작업 복사 개요 또는 의사 결정 테이블을 사용하여 복사 활동과 복사 작업을 비교하십시오.
Prerequisites
시작하려면 다음 필수 구성 요소를 완료해야 합니다.
- 구독이 활성 상태인 Microsoft Fabric 테넌트 계정. 무료로 계정을 만드세요.
- Microsoft Fabric 지원 작업 영역.
복사 도우미를 사용하여 복사 작업 추가
복사 도우미를 사용하여 복사 작업을 설정하려면 다음 단계를 수행합니다.
복사 도우미로 시작
기존 파이프라인을 열거나 새 파이프라인을 만듭니다.
캔버스에서 데이터 복사를 선택하여 복사 도우미 도구를 열어 시작합니다. 또는 리본의 활동 탭에 있는 데이터 복사 드롭다운 목록에서 복사 도우미 사용 을 선택합니다.
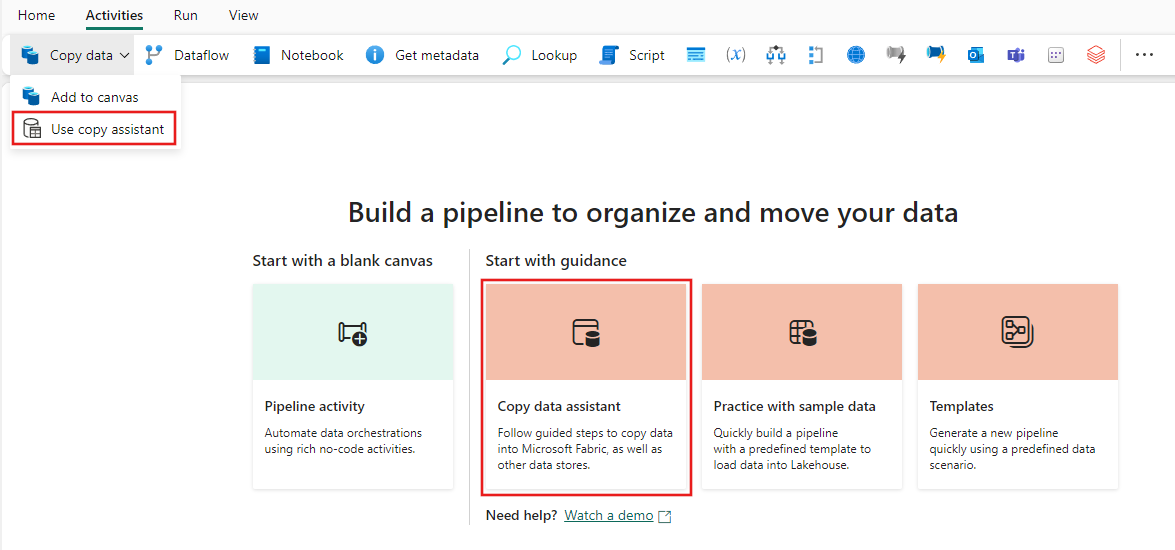

원본 설정
범주에서 데이터 원본 형식을 선택합니다. Azure Blob Storage를 예로 들어 보겠습니다. Azure Blob Storage를 선택합니다.
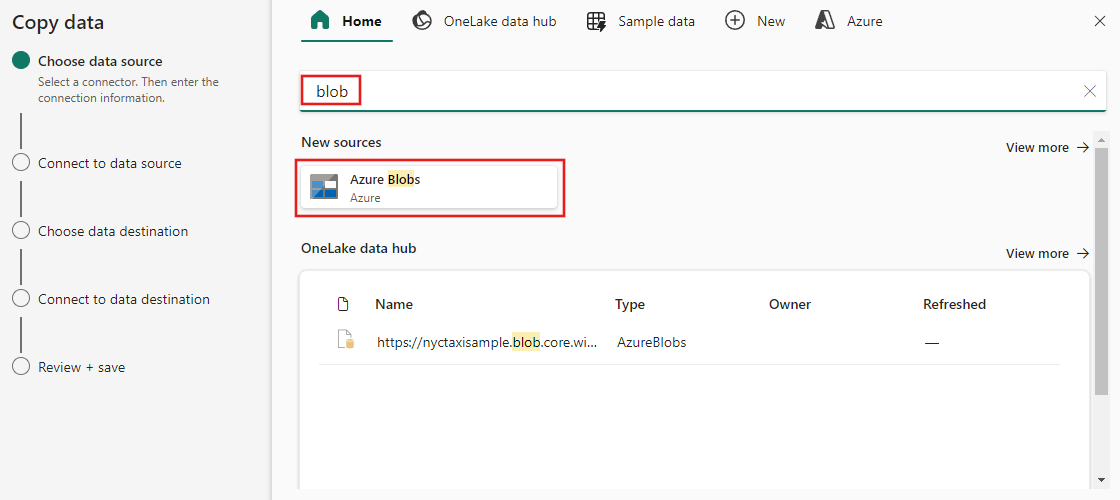
새 연결 만들기를 선택하여 데이터 원본에 대한 연결을 만듭니다.
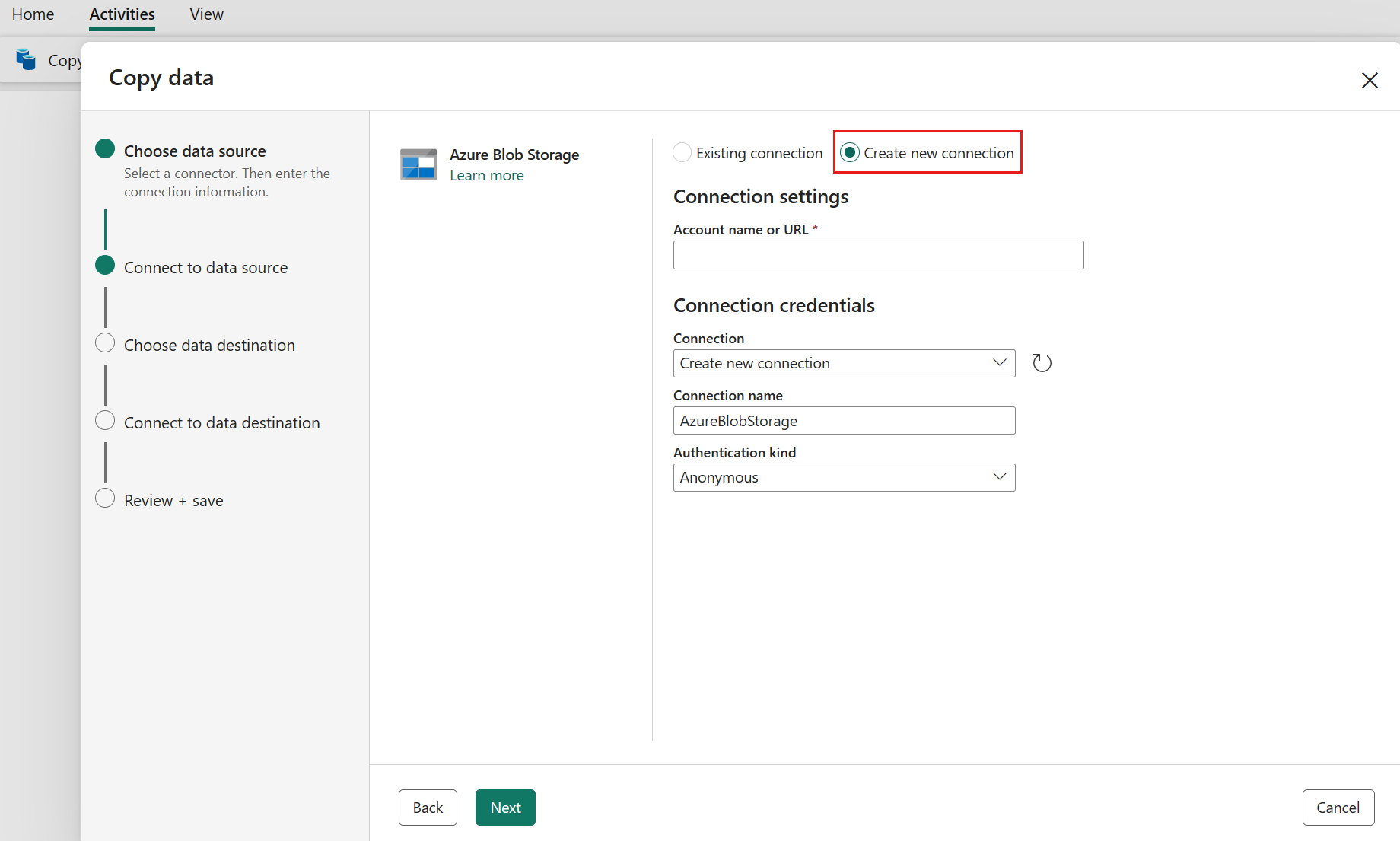
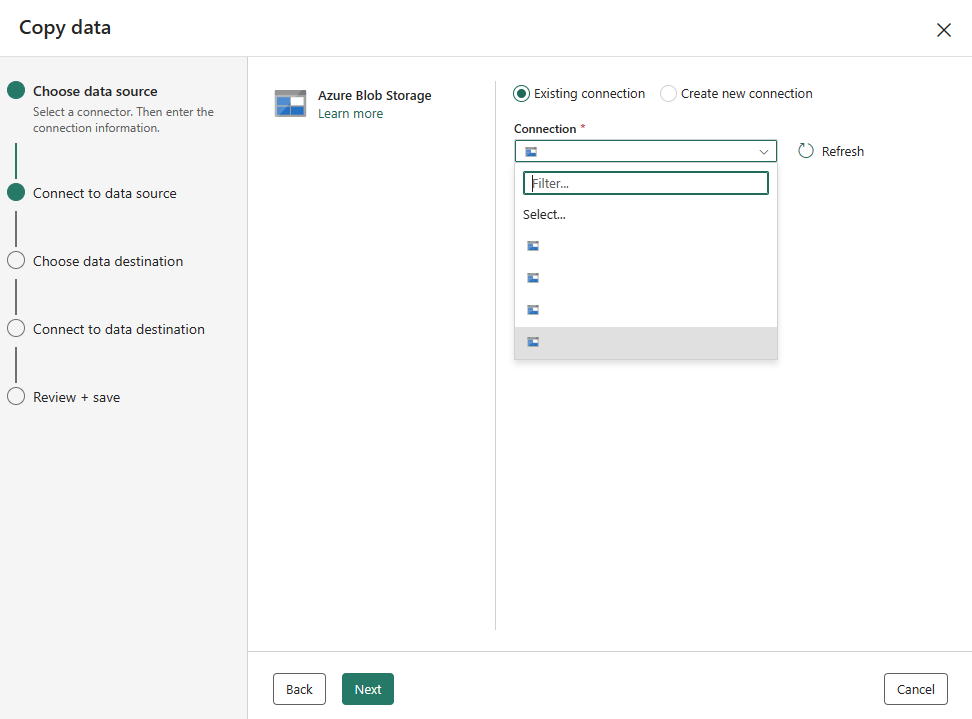
새 연결 만들기를 선택한 후 필요한 연결 정보를 입력하고 다음을 선택합니다. 각 데이터 원본 유형에 대한 연결 만들기에 대한 자세한 내용은 각 커넥터 문서를 참조할 수 있습니다.
이미 연결이 있는 경우 기존 연결을 선택하고 드롭다운 목록에서 연결을 선택할 수 있습니다.
이 원본 구성 단계에서 복사할 파일 또는 폴더를 선택한 다음, 다음을 선택합니다.
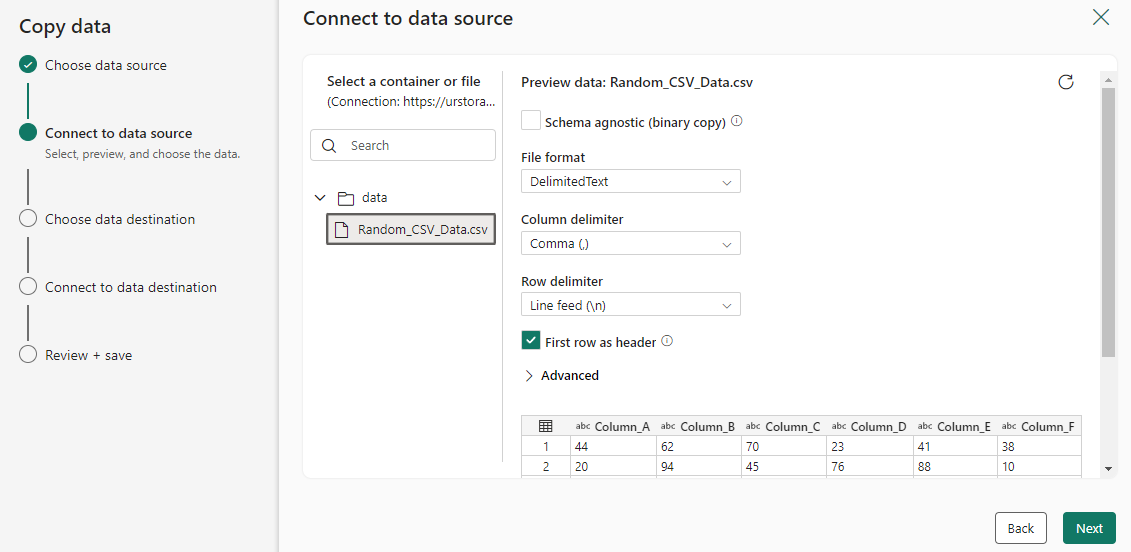




대상 설정
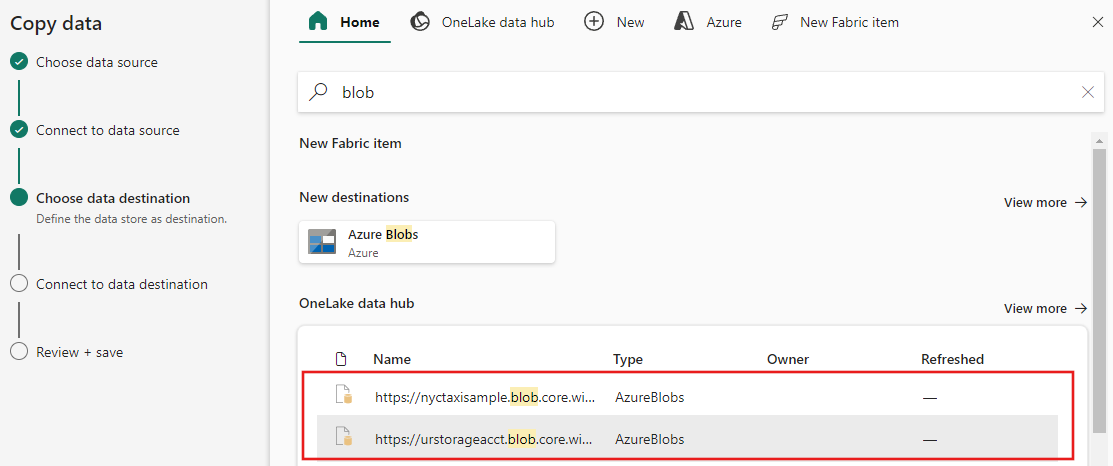
범주에서 데이터 원본 형식을 선택합니다. Azure Blob Storage를 예로 들어 보겠습니다. 이전 섹션의 단계에 따라 새 Azure Blob Storage 계정에 연결되는 새 연결을 만들거나 연결 드롭다운 목록의 기존 연결을 사용할 수 있습니다. 선택한 각 연결에 대해 테스트 연결 및 편집 기능을 사용할 수 있습니다.
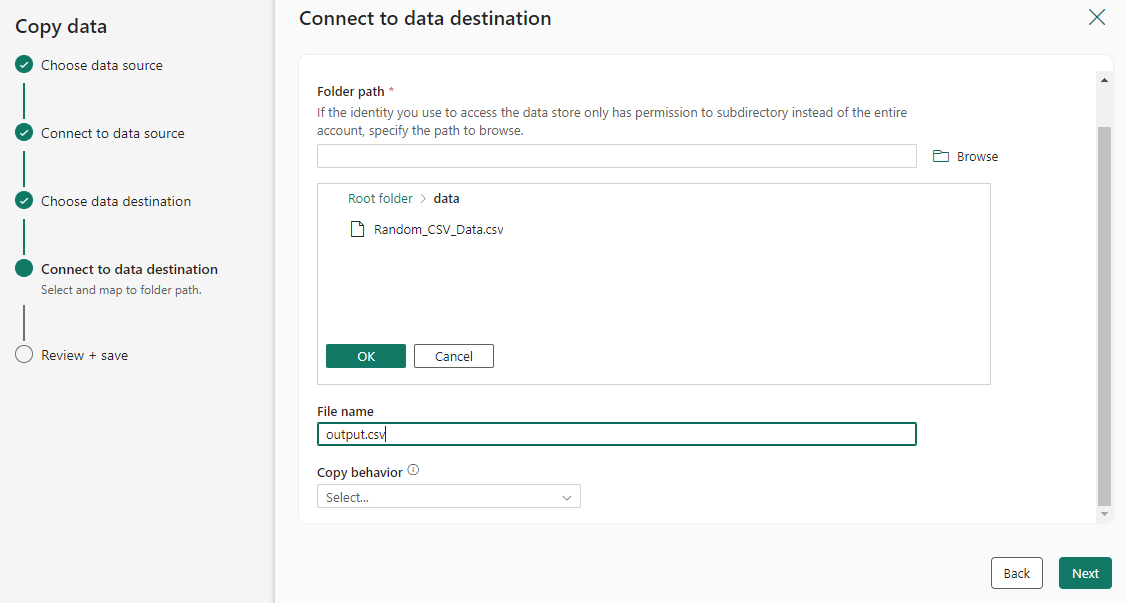
원본 데이터를 구성하고 대상에 매핑합니다. 그런 다음 다음을 선택하여 대상 구성을 완료합니다.
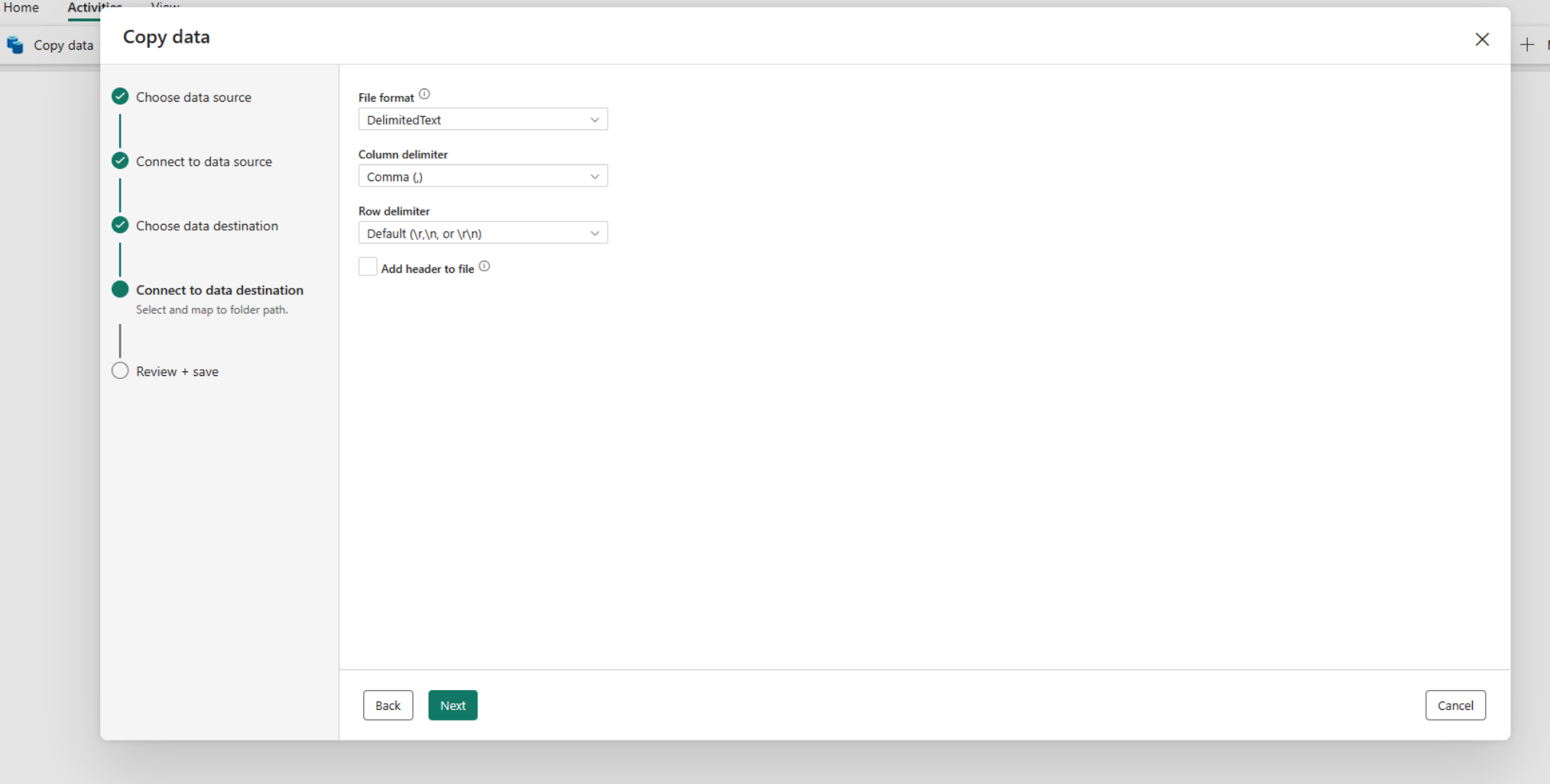
Note
동일한 복사 작업 내에서는 단일 온-프레미스 데이터 게이트웨이만 사용할 수 있습니다. 원본 및 싱크가 모두 온-프레미스 데이터 원본인 경우 동일한 게이트웨이를 사용해야 합니다. 서로 다른 게이트웨이를 사용하는 온-프레미스 데이터 원본 간에 데이터를 이동하려면 첫 번째 게이트웨이를 사용하여 하나의 복사 작업에서 중간 클라우드 원본으로 복사해야 합니다. 그런 다음 다른 복사 작업 사용하여 두 번째 게이트웨이를 사용하여 중간 클라우드 원본에서 복사할 수 있습니다.



복사 작업 검토 및 만들기
이전 단계에서 복사 작업 설정을 검토하고 확인을 선택하여 완료합니다. 또는 도구에서 필요한 경우 이전 단계로 돌아가 설정을 편집할 수 있습니다.


완료되면 복사 작업이 파이프라인 캔버스에 추가됩니다. 이 복사 작업에 대한 고급 설정을 비롯한 모든 설정은 탭에서 선택할 수 있습니다.

이제 이 단일 복사 작업으로 파이프라인을 저장하거나 파이프라인을 계속 디자인할 수 있습니다.
복사 작업 직접 추가
복사 작업을 직접 추가하려면 다음 단계를 수행합니다.
복사 작업을 추가합니다.
기존 파이프라인을 열거나 새 파이프라인을 만듭니다.
파이프라인 활동 추가를 선택하여 >을 추가하거나, 데이터 복사 및 캔버스에 추가를 > 탭에서 선택합니다.
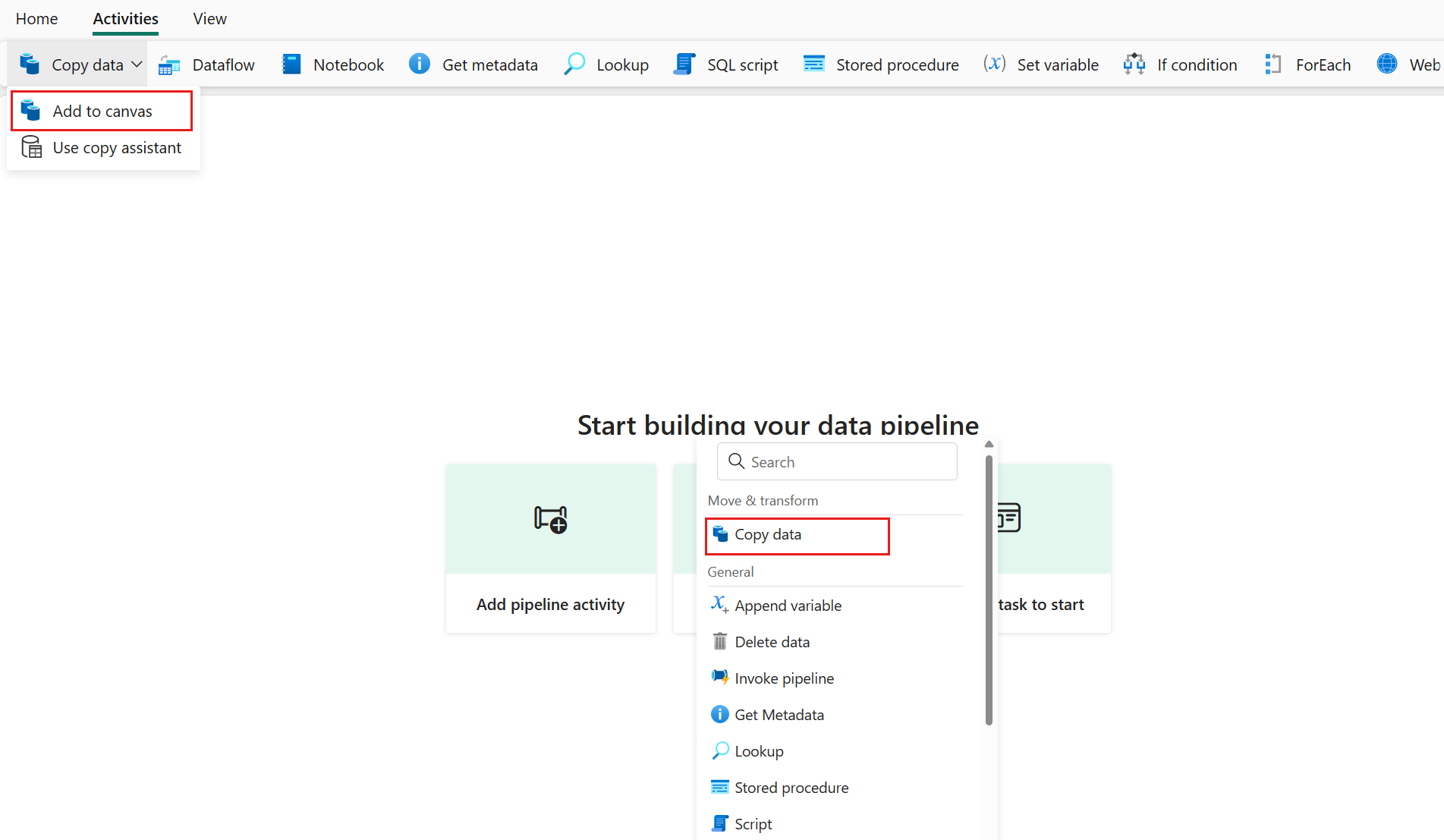

일반 탭에서 일반 설정 구성
일반 설정을 구성하는 방법을 알아보려면 일반을 참조하세요.
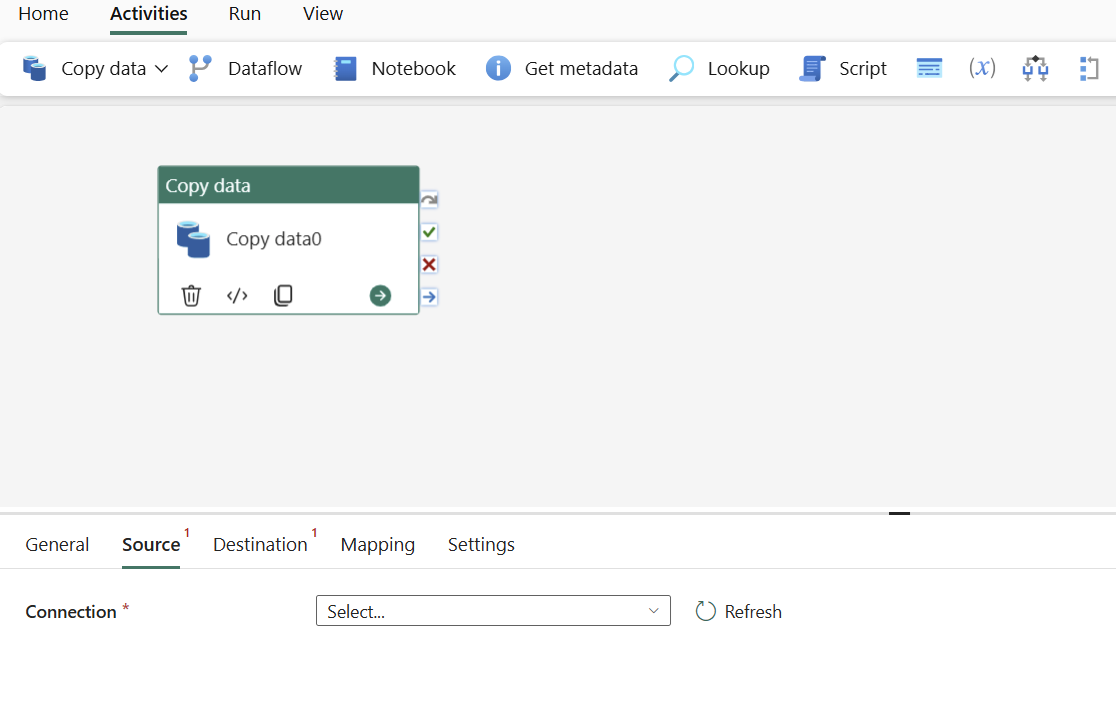
원본 탭을 선택하고 원본을 설정하세요
연결에서 기존 연결을 선택하거나 자세히를 선택하여 새 연결을 만듭니다.
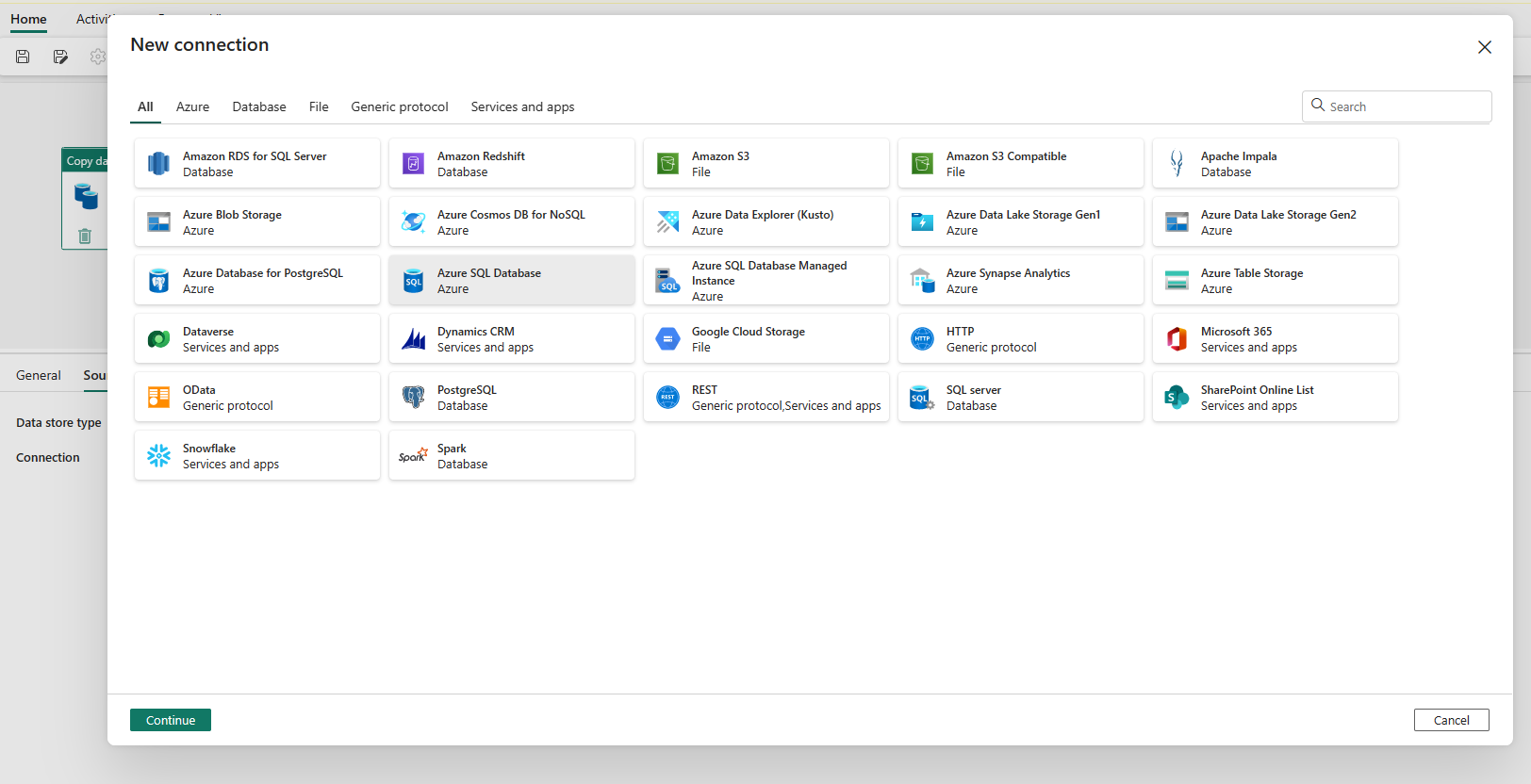
팝업 창에서 데이터 원본 형식을 선택합니다. Azure SQL 데이터베이스를 예로 들어보겠습니다. Azure SQL Database를 선택한 다음, 계속을 선택합니다.
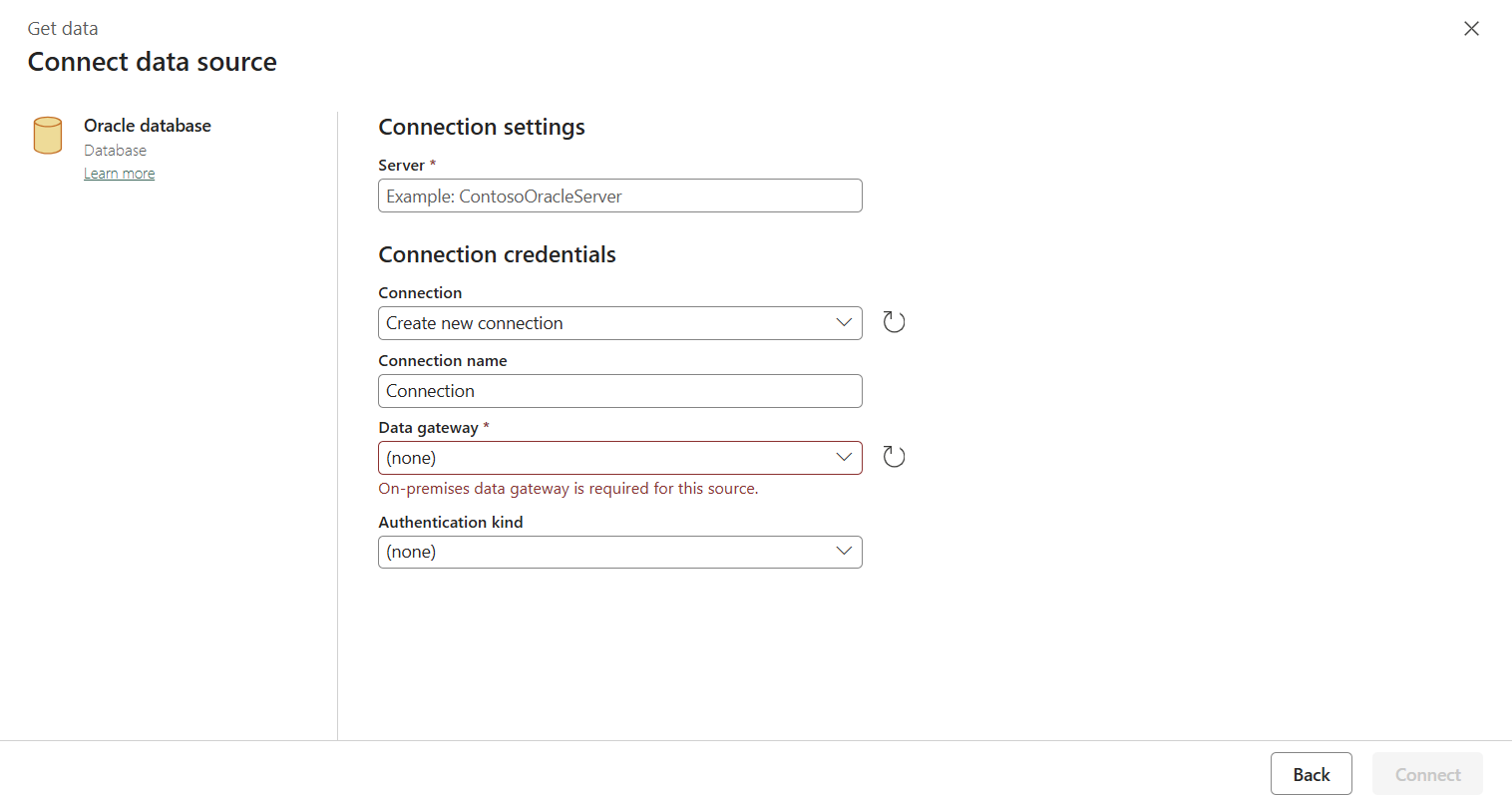
연결 만들기 페이지로 이동합니다. 패널에 필요한 연결 정보를 입력한 다음 만들기를 선택합니다. 각 데이터 원본 유형에 대한 연결 만들기에 대한 자세한 내용은 각 커넥터 문서를 참조할 수 있습니다.
연결이 만들어지면 파이프라인 페이지로 돌아갑니다. 그런 다음 새로 고침 을 선택하여 드롭다운 목록에서 만든 연결을 가져옵니다. 이전에 이미 만든 경우 드롭다운에서 직접 기존 Azure SQL Database 연결을 선택할 수도 있습니다. 선택한 각 연결에 대해 테스트 연결 및 편집 기능을 사용할 수 있습니다. 그런 다음 연결 유형에서 Azure SQL 데이터베이스를 선택합니다.
복사할 테이블을 지정합니다. 데이터 미리 보기를 선택하여 원본 테이블을 미리 봅니다. 쿼리 및 저장 프로시저를 사용하여 원본에서 데이터를 읽을 수도 있습니다.
쿼리 시간 제한 또는 분할과 같은 고급 설정을 위해 고급 을 확장합니다. (고급 설정은 커넥터에 따라 다릅니다.)



대상 탭에서 설정을 구성하세요
연결에서 기존 연결을 선택하거나 자세히를 선택하여 새 연결을 만듭니다. Lakehouse와 같은 작업 영역의 내부 일류 데이터 저장소 또는 외부 데이터 저장소일 수 있습니다. 이 예제에서는 Lakehouse를 사용합니다.
연결이 만들어지면 파이프라인 페이지로 돌아갑니다. 그런 다음 새로 고침 을 선택하여 드롭다운 목록에서 만든 연결을 가져옵니다. 이전에 이미 만든 경우 드롭다운에서 직접 기존 Lakehouse 연결을 선택할 수도 있습니다.
테이블을 지정하거나 파일 경로를 설정하여 파일 또는 폴더를 대상으로 정의합니다. 여기에서 테이블을 선택하고 데이터를 쓸 테이블을 지정합니다.
파일당 최대 행 또는 테이블 작업과 같은 고급 설정을 위해 고급 을 확장합니다. (고급 설정은 커넥터에 따라 다릅니다.)
이제 이 복사 작업으로 파이프라인을 저장하거나 파이프라인을 계속 디자인할 수 있습니다.
매핑 탭에서 매핑을 구성하세요.
사용하는 커넥터가 매핑을 지원하는 경우 매핑 탭으로 이동하여 매핑을 구성할 수 있습니다.
스키마 가져오기를 선택하여 데이터 스키마를 가져옵니다.
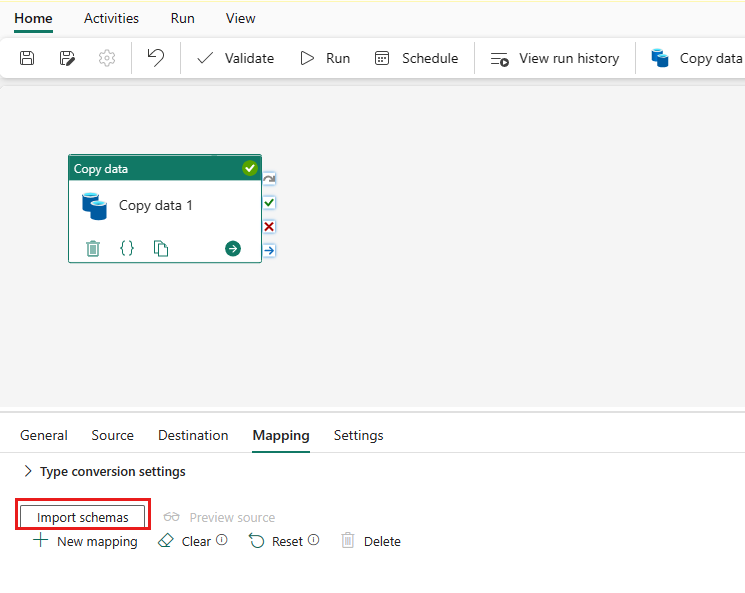
자동 매핑이 표시되는 것을 볼 수 있습니다. 원본 열과 대상 열을 지정합니다. 대상에 새 테이블을 만드는 경우 여기에서 대상 열 이름을 사용자 지정할 수 있습니다. 기존 대상 테이블에 데이터를 쓰려는 경우 기존 대상 열 이름을 수정할 수 없습니다. 원본 및 대상 열의 유형을 볼 수도 있습니다.
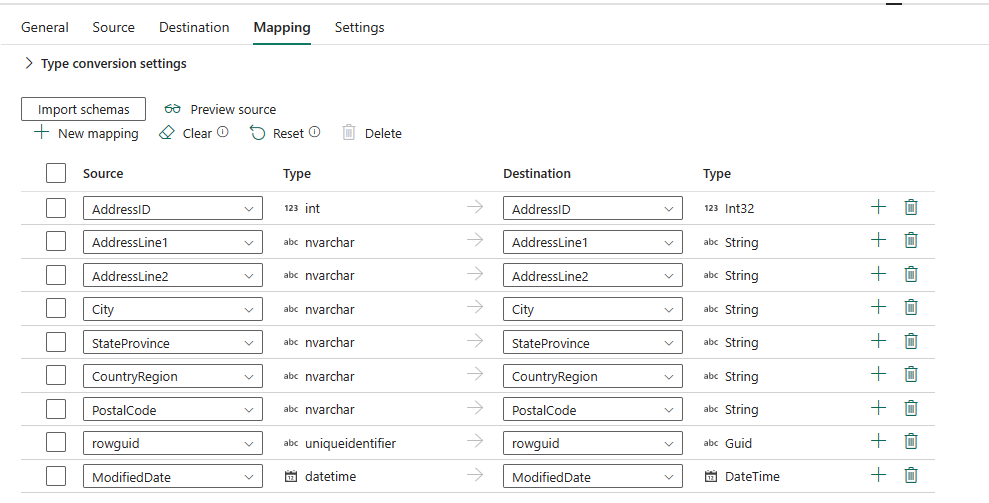


+ 새 매핑을 선택하여 새 매핑을 추가하고, [지우기]를 선택하여 모든 매핑 설정을 지우고, [다시 설정]을 선택하여 모든 매핑 원본 열을 다시 설정할 수도 있습니다.
데이터 형식 매핑
파이프라인의 복사 활동과 복사 작업은 다음 흐름을 사용하여 원본 형식을 대상 형식으로 매핑합니다.
- 원본 네이티브 데이터 형식에서 Fabric Data Factory에서 사용하는 중간 데이터 형식으로 변환합니다.
- 필요에 따라 중간 데이터 형식을 해당 대상 형식과 일치하도록 자동으로 변환합니다.
- 중간 데이터 형식에서 대상 네이티브 데이터 형식으로 변환합니다.
파이프라인 및 복사 작업의 복사 작업은 현재 부울, 바이트, 바이트 배열, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 및 UInt64 중간 데이터 형식을 지원합니다.
다음 데이터 형식 변환은 원본에서 대상으로 중간 형식 간에 지원됩니다.
| 소스\목적지 | 불리언 (Boolean) | 바이트 배열 | 날짜/시간 | Decimal | 부동 소수점 | GUID | 정수 | 스트링 | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| 불리언 (Boolean) | ✓ | ✓ | ✓ | ✓ | |||||
| 바이트 배열 | ✓ | ✓ | |||||||
| 날짜/시간 | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| 부동 소수점 | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| 정수 | ✓ | ✓ | ✓ | ✓ | |||||
| 스트링 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) 날짜/시간에는 DateTime, DateTimeOffset, 날짜 및 시간이 포함됩니다.
(2) Float-point에는 Single 및 Double이 포함됩니다.
(3) 정수에는 SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 및 UInt64가 포함됩니다.
특정 커넥터에 대한 자세한 데이터 형식 변환을 알아보려면 여기에서 해당 커넥터에 대한 복사 작업 구성 문서로 이동합니다.
Note
현재 이러한 데이터 형식 변환은 테이블 형식 데이터 간에 복사할 때 지원됩니다. 계층적 원본/대상은 지원되지 않으므로 원본과 대상 중간 형식 간에 시스템 정의 데이터 형식 변환이 없습니다.
설정 탭에서 다른 설정 구성
설정 탭에는 성능, 스테이징 등의 설정이 포함되어 있습니다.

각 설정에 대한 설명은 다음 표를 참조하세요.
| Setting | Description | JSON 스크립트 속성 |
|---|---|---|
| 지능형 처리량 최적화 | 처리량을 최적화하도록 지정합니다. 다음 중에서 선택할 수 있습니다. • 자동 • 표준 • 균형 잡힌 • 최대값 자동을 선택하면 원본-대상 쌍 및 데이터 패턴에 따라 최적의 설정이 동적으로 적용됩니다. 처리량을 사용자 지정할 수도 있고 사용자 지정 값은 4-256일 수 있지만 값이 높을수록 더 많은 이익을 얻을 수 있습니다. |
dataIntegrationUnits |
| 복사 병렬 처리 수준 | 데이터 로드에서 사용할 병렬 처리 수준을 지정합니다. | parallelCopies |
| 적응 성능 튜닝(미리 보기) | 서비스에서 사용자 지정 구성에 따라 성능 최적화 및 튜닝을 적용할 수 있는지 여부를 지정합니다. | 적응형 성능 조정 |
| 데이터 일관성 확인 | 이 속성에 대해 설정한 true 경우 이진 파일을 복사할 때 복사 작업은 원본 저장소에서 대상 저장소로 복사된 각 이진 파일에 대한 파일 크기, lastModifiedDate 및 체크섬을 확인하여 원본과 대상 저장소 간의 데이터 일관성을 보장합니다. 표 형식 데이터를 복사하는 경우, 원본에서 읽은 전체 행 개수가 대상으로 복사된 행 개수에 호환되지 않는 건너뛴 행 개수를 더한 값과 같은지 확인하기 위해 복사 작업은 작업 완료 후에 전체 행 개수를 확인합니다. 이 옵션을 사용하도록 설정하면 복사 성능이 영향을 받습니다. |
validateDataConsistency |
| 내결함성 | 이 옵션을 선택하면 복사 프로세스 중간에 발생하는 일부 오류를 무시할 수 있습니다. 예를 들어 원본과 대상 저장소 간의 호환되지 않는 행, 데이터 이동 중에 삭제되는 파일 등이 있습니다. | • 호환되지 않는 행 건너뛰기 활성화 (enableSkipIncompatibleRow) • skipErrorFile: fileMissing fileForbidden invalidFileName |
| 로깅 활성화 | 이 옵션을 선택하면 복사한 파일, 건너뛴 파일 및 행을 기록할 수 있습니다. | / |
| 스테이징 활성화 | 중간 준비 저장소를 통해 데이터를 복사할지 여부를 지정합니다. 유용한 시나리오에 대해서만 스테이징을 사용하도록 설정합니다. | enableStaging |
| 작업 영역에 대해 | ||
| Workspace | 기본 제공 스테이징 스토리지를 사용하도록 지정합니다. 파이프라인에 대해 마지막으로 수정된 사용자에게 작업 영역에 적어도 기여자 역할이 할당되어 있는지 확인합니다. | / |
| 외부용으로 | ||
| 스테이징 계정 연결 | 중간 스테이징 저장소로 사용하는 저장소 인스턴스를 참조하는 Azure Blob 저장소 또는 Azure Data Lake 저장소 Gen2의 연결을 지정합니다. 스테이징 연결이 없으면 새로 만드세요. | 연결(externalReferences 아래) |
| 스토리지 경로 | 준비 데이터를 포함할 경로를 지정합니다. 경로를 제공하지 않으면, 서비스는 임시 데이터를 저장하는 컨테이너를 만듭니다. 공유 액세스 서명을 포함한 스토리지를 사용하거나 특정 위치에 임시 데이터가 필요한 경우에만 경로를 지정합니다. | path |
| 압축 사용 | 대상을 복사하기 전에 데이터 압축 여부를 지정합니다. 이 설정은 전송되는 데이터 양을 줄입니다. | enableCompression |
| Preserve | 데이터를 복사하는 동안 메타데이터/ACL을 유지할지 여부를 지정합니다. | preserve |
Note
압축이 활성화된 상태에서 준비된 복사본을 사용하는 경우, 스테이징 Blob 연결을 위한 서비스 주체 인증은 지원되지 않습니다.
Note
작업 공간 스테이징은 60분 후에 종료됩니다. 장기 실행 작업의 경우 스테이징에 외부 스토리지를 사용하는 것이 좋습니다.
복사 작업에서 매개 변수 구성
매개 변수를 사용하여 파이프라인 및 해당 활동의 동작을 제어할 수 있습니다. 동적 콘텐츠 추가를 사용하여 복사 작업 속성에 대한 매개 변수를 지정할 수 있습니다. 예제로 Lakehouse/Data Warehouse를 지정하여 사용하는 방법을 살펴보겠습니다.
원본 또는 대상의 연결 드롭다운 목록에서 동적 콘텐츠 사용을 선택합니다.
팝업 동적 콘텐츠 추가 창의 매개 변수 탭에서 +를 선택합니다.
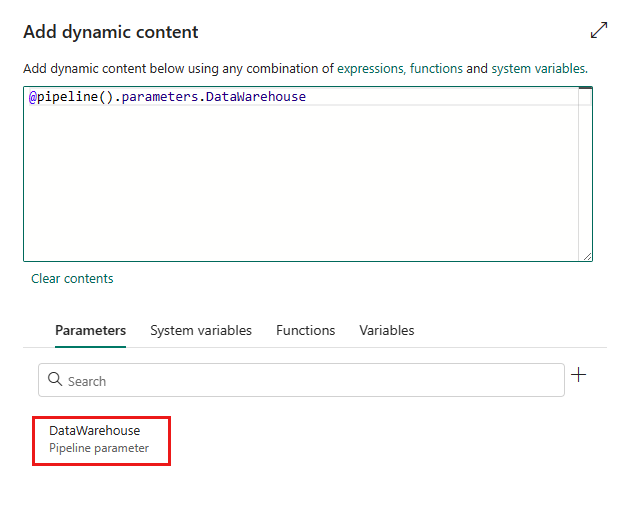
매개 변수의 이름을 지정하고 원하는 경우 기본값을 지정하거나 파이프라인에서 트리거될 때 매개 변수의 값을 지정할 수 있습니다.

매개 변수 값은 Lakehouse/Data Warehouse 연결 ID여야 합니다. 이를 가져오려면 연결 및 게이트웨이 관리를 열고, 사용할 Lakehouse/Data Warehouse 연결을 선택하고, 설정을 열어 연결 ID를 가져옵니다. 새 연결을 만들려면 이 페이지에서 + 새로 만들기를 선택하거나 연결 드롭다운 목록을 통해 데이터 페이지를 가져올 수 있습니다.
저장을 선택하여 동적 콘텐츠 추가 창으로 돌아갑니다. 그런 다음 식 상자에 표시되도록 매개 변수를 선택합니다. 그런 다음 확인을 선택합니다. 파이프라인 페이지로 돌아가서 연결 후에 매개 변수 식이 지정된 것을 볼 수 있습니다.
Lakehouse 또는 Data Warehouse의 ID를 지정합니다. ID를 찾으려면 작업 영역에서 Lakehouse 또는 Data Warehouse로 이동합니다. ID는
/lakehouses/또는/datawarehouses/뒤의 URL에 나타납니다.레이크하우스 ID:

웨어하우스 ID:
