빠른 시작: 데이터 흐름 및 데이터 파이프라인을 사용하여 데이터 이동 및 변환
이 자습서에서는 데이터 흐름 및 데이터 파이프라인 환경이 강력하고 포괄적인 Data Factory 솔루션을 만드는 방법을 알아보세요.
필수 조건
시작하려면 다음 필수 구성 요소가 있어야 합니다.
- 활성 구독이 있는 테넌트 계정입니다. 체험 계정을 만드세요.
- Microsoft Fabric 사용 작업 영역이 있는지 확인합니다 . 기본 내 작업 영역이 아닌 작업 영역을 만듭니다.
- 테이블 데이터가 있는 Azure SQL 데이터베이스입니다.
- Blob Storage 계정입니다.
파이프라인과 비교한 데이터 흐름
데이터 흐름 Gen2를 사용하면 낮은 코드 인터페이스와 300개 이상의 데이터 및 AI 기반 변환을 활용하여 다른 도구보다 더 많은 유연성으로 데이터를 쉽게 클린, 준비 및 변환할 수 있습니다. 데이터 파이프라인을 사용하면 풍부한 기본 데이터 오케스트레이션 기능을 통해 엔터프라이즈 요구 사항을 충족하는 유연한 데이터 워크플로를 작성할 수 있습니다. 파이프라인에서 작업을 수행하는 작업의 논리적 그룹화(데이터 흐름을 호출하여 데이터를 클린 준비)를 만들 수 있습니다. 두 기능 간에는 몇 가지 기능이 겹치지만 특정 시나리오에 사용할 옵션은 파이프라인의 전체 풍부도가 필요한지 아니면 더 간단하지만 제한된 데이터 흐름 기능을 사용할 수 있는지에 따라 달라집니다. 자세한 내용은 패브릭 의사 결정 가이드를 참조하세요.
데이터 흐름을 사용하여 데이터 변환
다음 단계에 따라 데이터 흐름을 설정합니다.
1단계: 데이터 흐름 만들기
패브릭 사용 작업 영역을 선택한 다음 새로 만들기를 선택합니다. 그런 다음, Dataflow Gen2를 선택합니다.
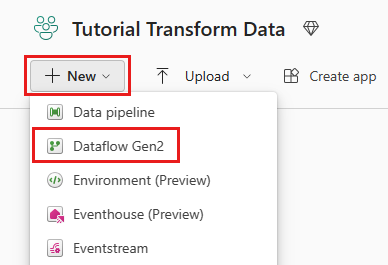
데이터 흐름 편집기 창이 나타납니다. SQL Server 카드 가져오기를 선택합니다.

2단계: 데이터 가져오기
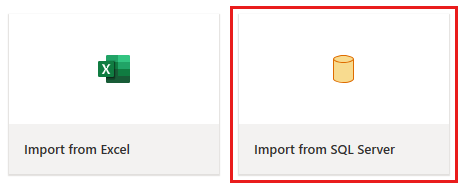
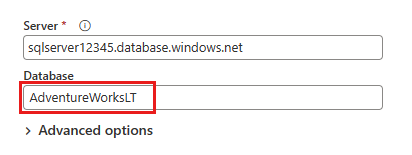
다음에 표시되는 데이터 원본 대화 상자에 커넥트 Azure SQL 데이터베이스에 연결할 세부 정보를 입력한 다음, 다음을 선택합니다. 이 예제에서는 필수 구성 요소에서 Azure SQL 데이터베이스를 설정할 때 구성된 AdventureWorksLT 샘플 데이터베이스를 사용합니다.
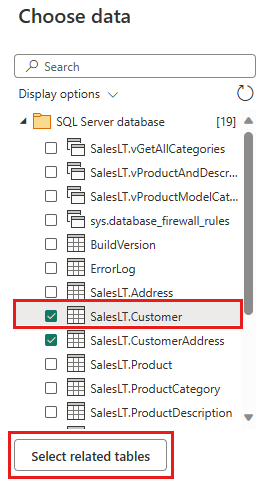
변환할 데이터를 선택한 다음 만들기를 선택합니다. 이 빠른 시작에서는 Azure SQL DB에 제공된 AdventureWorksLT 샘플 데이터에서 SalesLT.Customer를 선택한 다음, 관련 테이블 선택 단추를 선택하여 다른 두 개의 관련 테이블을 자동으로 포함합니다.


3단계: 데이터 변환
선택하지 않은 경우 페이지 아래쪽의 상태 표시줄을 따라 다이어그램 보기 단추를 선택하거나 파워 쿼리 편집기 맨 위에 있는 보기 메뉴에서 다이어그램 보기를선택합니다. 이러한 옵션 중 하나를 사용하여 다이어그램 보기를 전환할 수 있습니다.
SalesLT Customer 쿼리를 마우스 오른쪽 단추로 클릭하거나 쿼리 오른쪽의 세로 줄임표를 선택한 다음 쿼리 병합을 선택합니다.
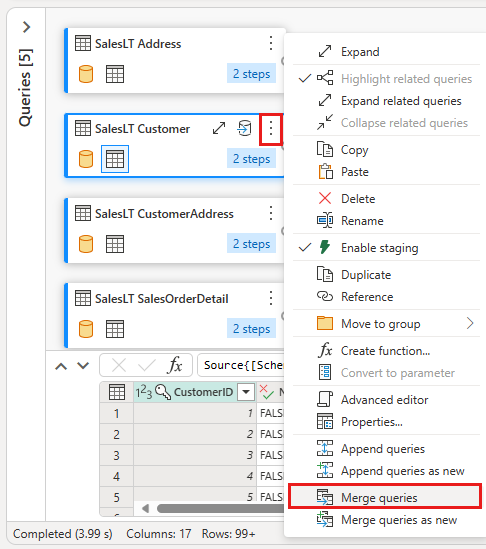
병합에 적합한 테이블로 SalesLTOrderHeader 테이블을 선택하고 각 테이블의 CustomerID 열을 조인 열로, 왼쪽 외부를 조인 종류로 선택하여 병합을 구성합니다. 그런 다음 확인을 선택하여 병합 쿼리를 추가합니다.
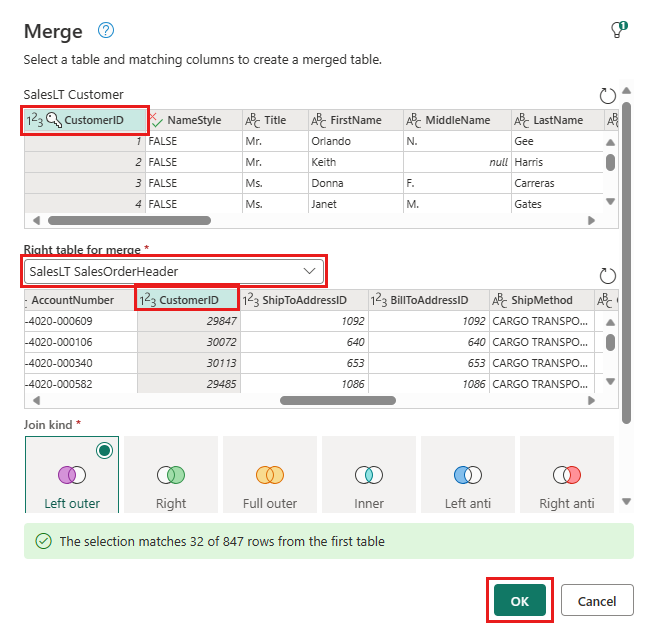
방금 만든 새 병합 쿼리에서 위에 화살표가 있는 데이터베이스 기호처럼 보이는 데이터 대상 추가 단추를 선택합니다. 그런 다음, 대상 유형으로 Azure SQL 데이터베이스를 선택합니다.
병합 쿼리를 게시할 Azure SQL 데이터베이스 연결에 대한 세부 정보를 제공합니다. 이 예제에서는 대상의 데이터 원본으로 사용한 AdventureWorksLT 데이터베이스도 사용할 수 있습니다.
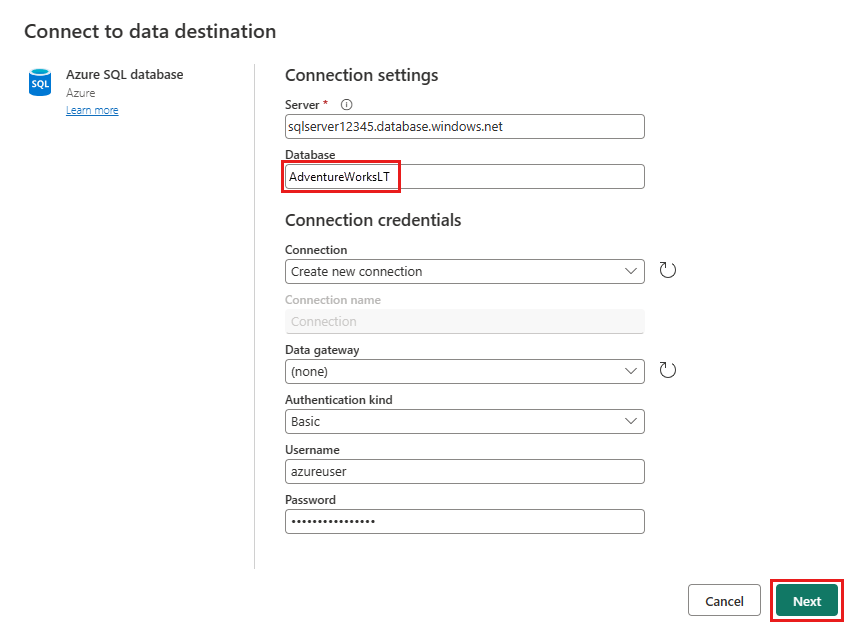
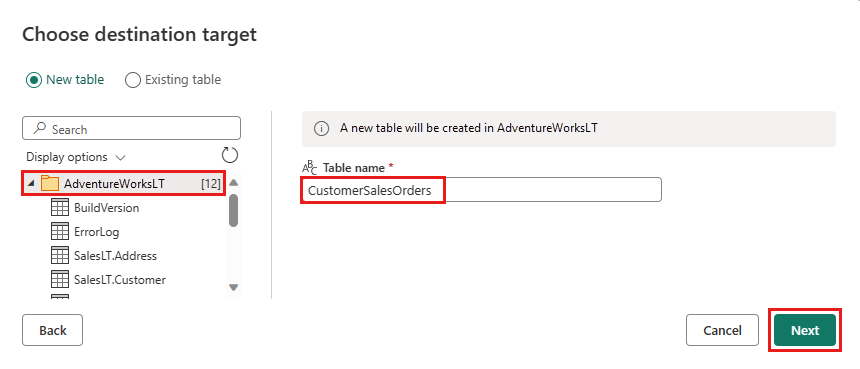
데이터를 저장할 데이터베이스를 선택하고 테이블 이름을 입력한 다음, 다음을 선택합니다.
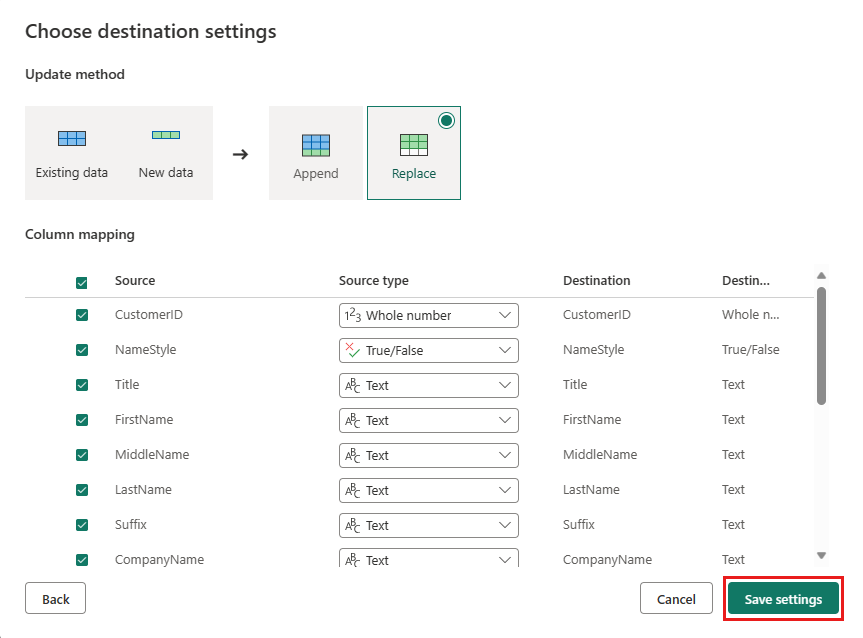
대상 설정 선택 대화 상자에서 기본 설정을 그대로 두고 여기에서 변경하지 않고 설정 저장을 선택할 수 있습니다.
데이터 흐름 편집기 페이지에서 다시 게시를 선택하여 데이터 흐름을 게시합니다.



데이터 파이프라인을 사용하여 데이터 이동
이제 Dataflow Gen2를 만들었으므로 파이프라인에서 작업할 수 있습니다. 이 예제에서는 데이터 흐름에서 생성된 데이터를 Azure Blob Storage 계정의 텍스트 형식으로 복사합니다.
1단계: 새 데이터 파이프라인 만들기
작업 영역에서 새로 만들기를 선택한 다음 데이터 파이프라인을 선택합니다.
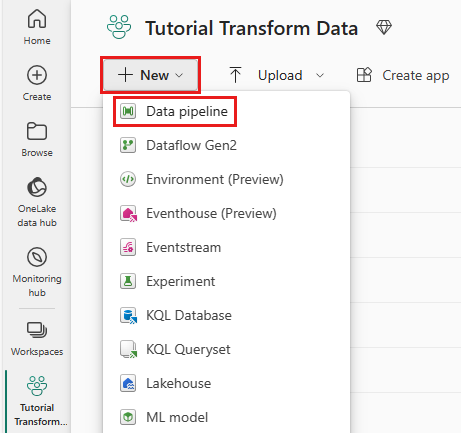
파이프라인 이름을 지정한 다음 만들기를 선택합니다.
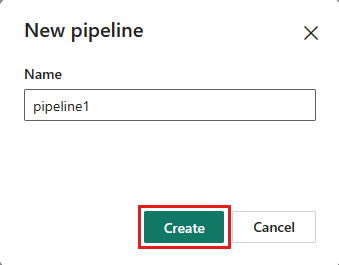
2단계: 데이터 흐름 구성
활동 탭에서 데이터 흐름을 선택하여 데이터 파이프라인에 새 데이터 흐름 작업을 추가합니다.

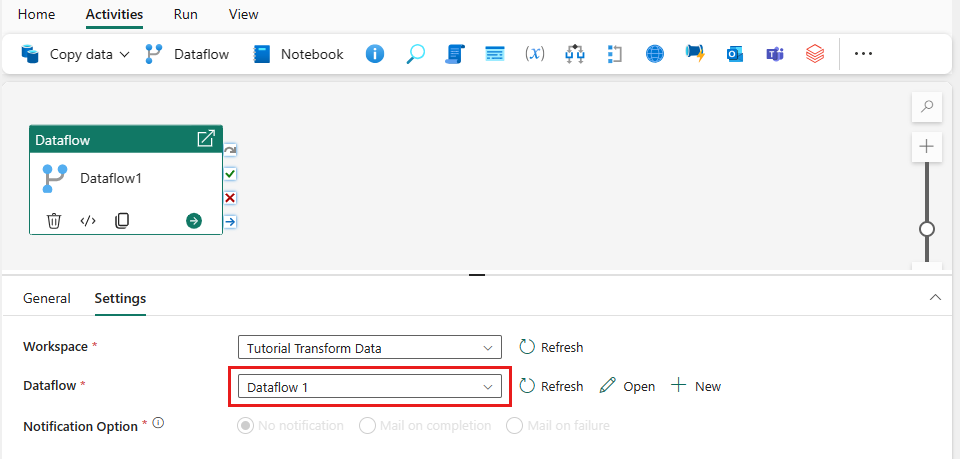
파이프라인 캔버스에서 데이터 흐름을 선택한 다음 설정 탭을 선택합니다. 드롭다운 목록에서 이전에 만든 데이터 흐름을 선택합니다.
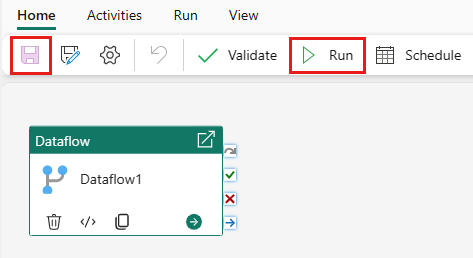
저장을 선택한 다음 실행하여 데이터 흐름을 실행하여 이전 단계에서 디자인한 병합된 쿼리 테이블을 처음에 채웁다.
3단계: 복사 도우미 사용하여 복사 작업 추가
캔버스에서 데이터 복사를 선택하여 복사 도우미 도구를 열어 시작합니다. 또는 리본 메뉴의 활동 탭에 있는 데이터 복사 드롭다운 목록에서 복사 도우미 사용을 선택합니다.
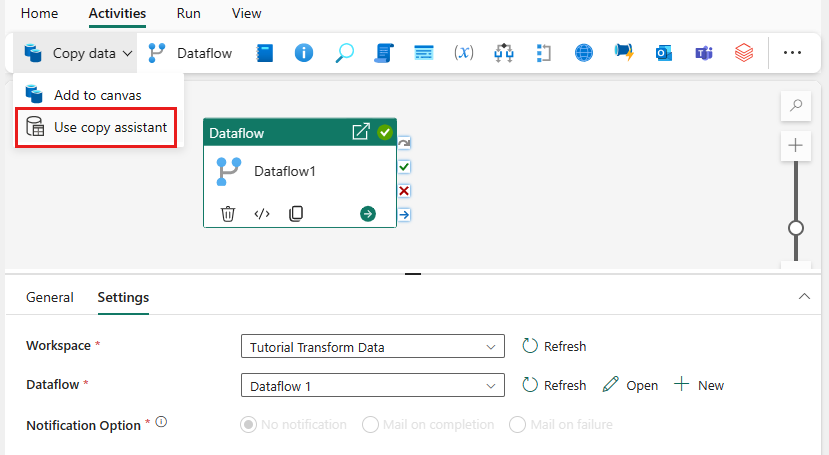
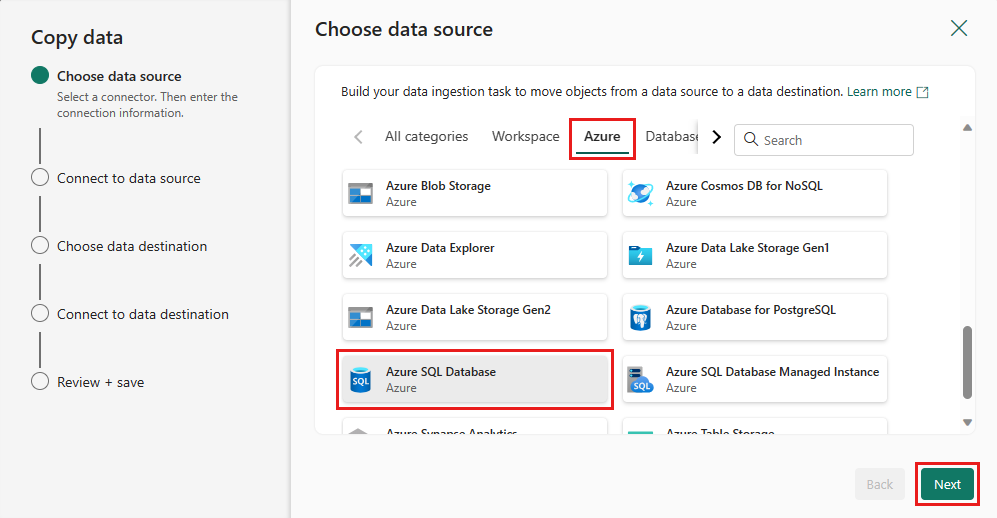
데이터 원본 형식을 선택하여 데이터 원본을 선택합니다. 이 자습서에서는 데이터 흐름을 만들 때 이전에 사용한 Azure SQL Database를 사용하여 새 병합 쿼리를 생성합니다. 샘플 데이터 제품 아래로 스크롤하여 Azure 탭, Azure SQL Database를 선택합니다. 그런 다음 다음을 선택하여 계속합니다.
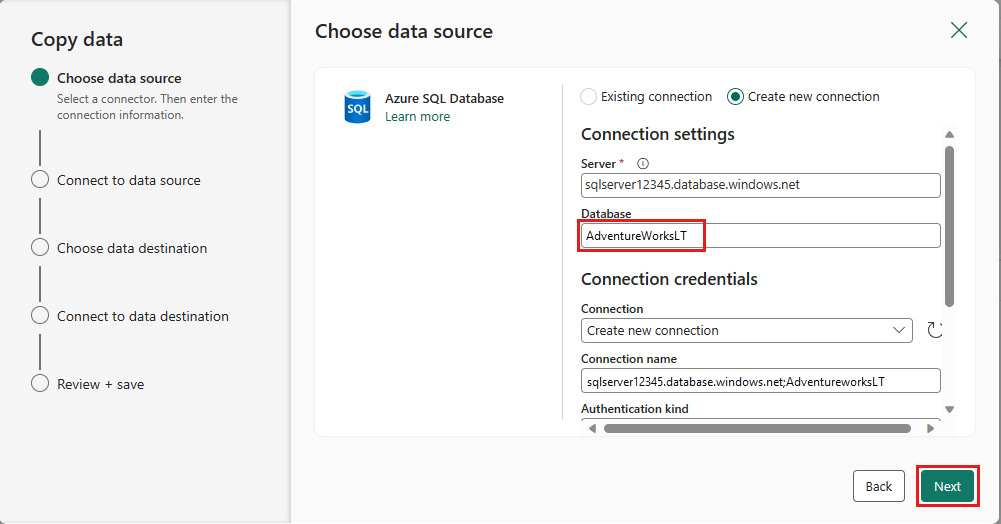
새 연결 만들기를 선택하여 데이터 원본에 대한 연결을 만듭니다. 패널에서 필요한 연결 정보를 입력하고 데이터베이스에 대한 AdventureWorksLT를 입력합니다. 여기서 데이터 흐름에서 병합 쿼리를 생성했습니다. 그런 후 다음을 선택합니다.
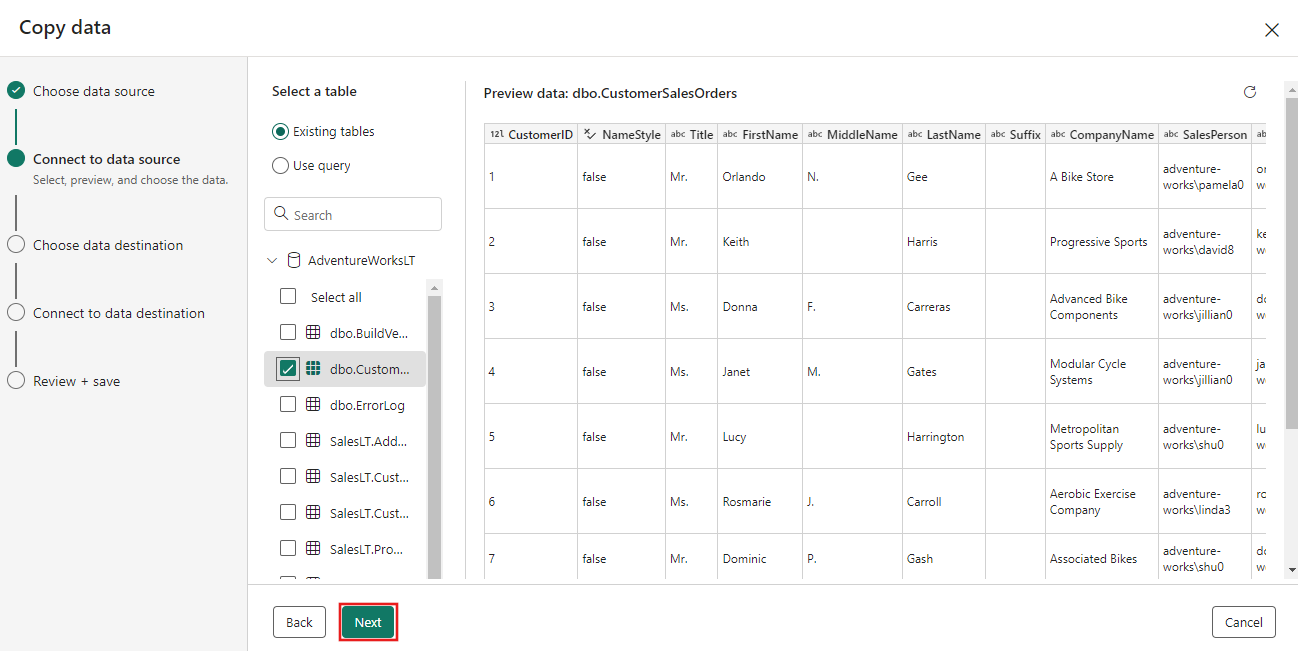
앞서 데이터 흐름 단계에서 생성한 테이블을 선택한 다음, 다음을 선택합니다.
대상에 대해 Azure Blob Storage를 선택한 다음, 다음을 선택합니다.
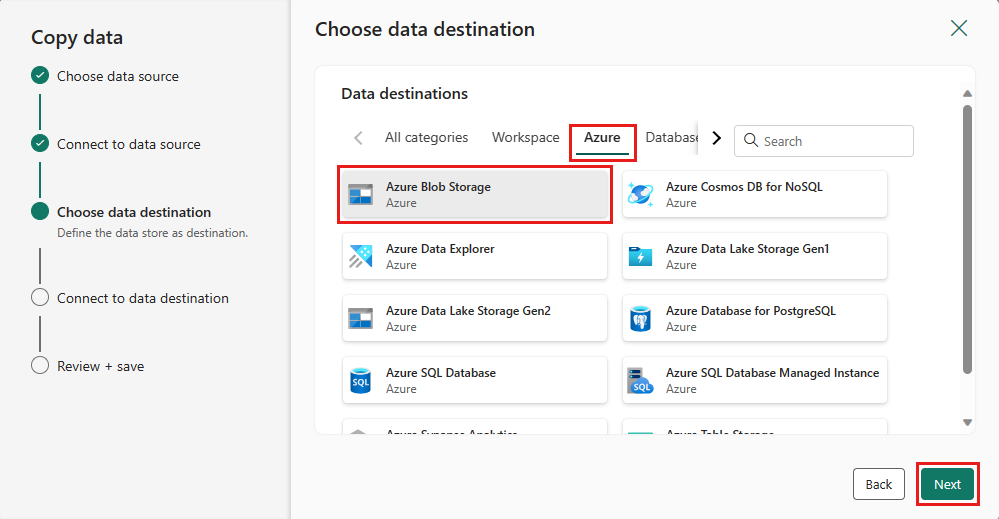
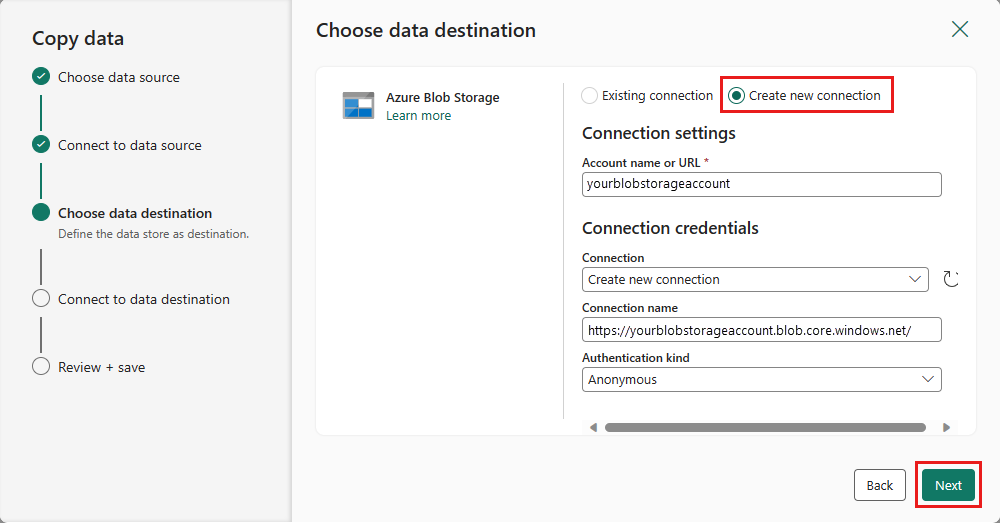
새 연결 만들기를 선택하여 대상에 대한 연결을 만듭니다. 연결에 대한 세부 정보를 입력한 다음, 다음을 선택합니다.
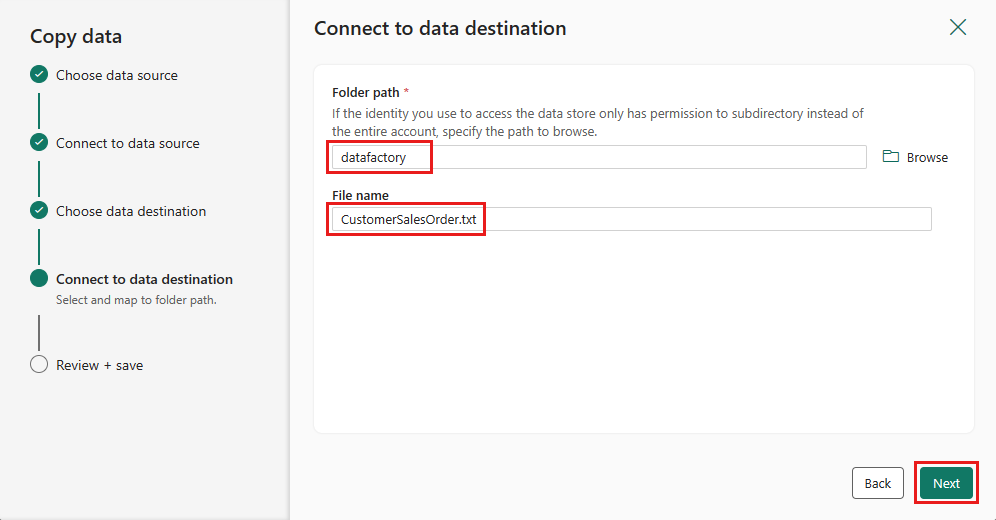
폴더 경로를 선택하고 파일 이름을 입력한 다음, 다음을 선택합니다.
기본 파일 형식, 열 구분 기호, 행 구분 기호 및 압축 형식(선택 사항)을 적용하려면 [다음]을 다시 선택합니다.
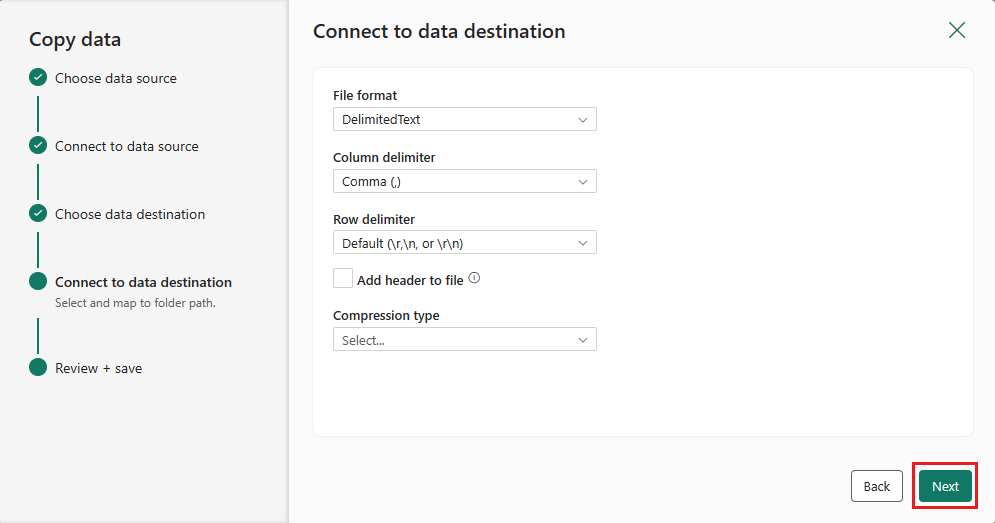
설정을 완료합니다. 그런 다음 저장 + 실행을 검토하고 선택하여 프로세스를 완료합니다.
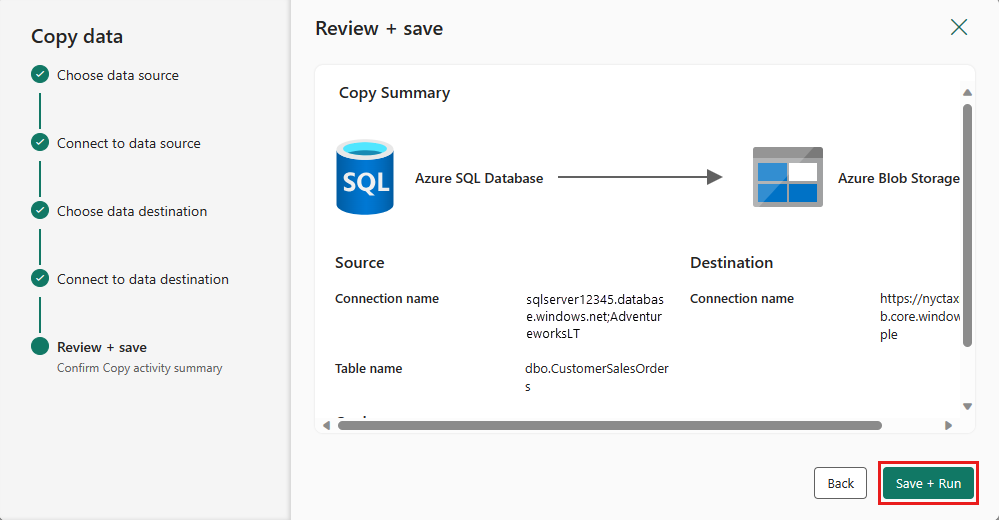
5단계: 데이터 파이프라인 디자인 및 데이터 실행 및 로드를 위해 저장
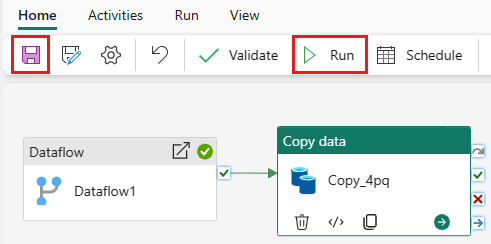
데이터 흐름 작업 후에 복사 작업을 실행하려면 데이터 흐름 작업의 Succeeded에서 복사 작업으로 끌어옵니다. 복사 작업은 데이터 흐름 작업이 성공한 후에만 실행됩니다.

저장을 선택하여 데이터 파이프라인을 저장합니다. 그런 다음 실행을 선택하여 데이터 파이프라인을 실행하고 데이터를 로드합니다.
파이프라인 실행 예약
파이프라인 개발 및 테스트가 완료되면 파이프라인이 자동으로 실행되도록 예약할 수 있습니다.
파이프라인 편집기 창의 홈 탭에서 일정을 선택합니다.
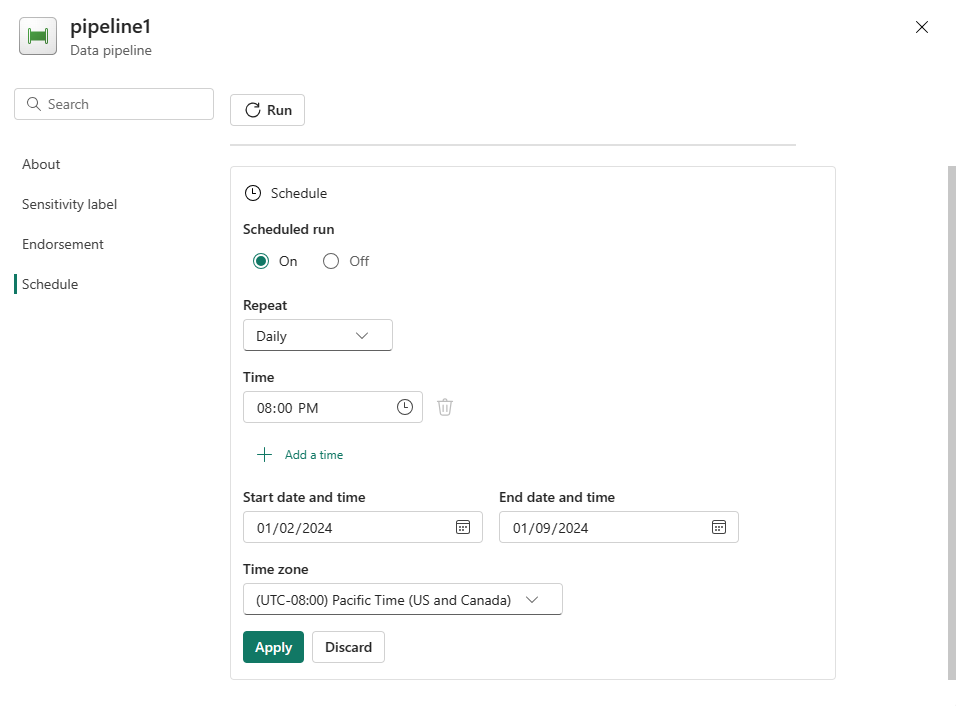
필요에 따라 일정을 구성합니다. 이 예제에서는 파이프라인이 연중 말까지 매일 오후 8시에 실행되도록 예약합니다.
관련 콘텐츠
이 샘플에서는 병합 쿼리를 만들고 Azure SQL 데이터베이스에 저장하기 위해 Dataflow Gen2를 만들고 구성한 다음, 데이터베이스에서 Azure Blob Storage의 텍스트 파일로 데이터를 복사하는 방법을 보여 줍니다. 다음 방법에 대해 알아보았습니다.
- 데이터 흐름 만들기.
- 데이터 흐름을 사용하여 데이터를 변환합니다.
- 데이터 흐름을 사용하여 데이터 파이프라인을 만듭니다.
- 파이프라인의 단계 실행을 순서대로 지정합니다.
- 복사 도우미를 사용하여 데이터를 복사합니다.
- 데이터 파이프라인을 실행하고 예약합니다.
다음으로 파이프라인 실행 모니터링에 대해 자세히 알아보세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기