Microsoft Fabric 확장 가능한 PREDICT 함수를 사용하여 machine learning 모델을 운영할 수 있습니다. 이 함수는 모든 컴퓨팅 엔진에서 일괄 처리 채점을 지원합니다. Microsoft Fabric Notebook 또는 지정된 ML 모델의 항목 페이지에서 직접 일괄 처리 예측을 생성할 수 있습니다.
이 문서에서는 코드를 직접 작성하거나 일괄 처리 채점을 처리하는 안내된 UI 환경을 사용하여 PREDICT를 적용하는 방법을 알아봅니다.
필수 조건
Microsoft Fabric 구독을 받으세요. 또는 무료 Microsoft Fabric 평가판 등록합니다.
Microsoft Fabric 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

제한 사항
- PREDICT 함수는 현재 다음 ML 모델 버전만 지원합니다.
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- statsmodels
- TensorFlow
- XGBoost
- PREDICT 를 사용하려면 해당 서명이 채워진 MLflow 형식으로 ML 모델을 저장해야 합니다.
- PREDICT 는 다중 텐서 입력 또는 출력이 있는 ML 모델을 지원하지 않습니다.
Notebook에서 PREDICT 호출
PREDICT는 Microsoft Fabric 레지스트리에서 MLflow 패키지 모델을 지원합니다. 이미 학습되고 등록된 ML 모델이 작업 영역에 있는 경우 2단계로 건너뛸 수 있습니다. 그렇지 않은 경우 1단계는 샘플 로지스틱 회귀 분석 모델 학습을 안내하는 샘플 코드를 제공합니다. 이 모델을 사용하여 프로시저가 끝날 때 일괄 처리 예측을 생성합니다.
ML 모델을 학습하고 MLflow에 등록합니다. 다음 코드 샘플에서는 MLflow API를 사용하여 machine learning 실험을 만든 다음 scikit-learn 로지스틱 회귀 모델에 대한 MLflow 실행을 시작합니다. 그런 다음 모델 버전이 저장되고 Microsoft Fabric 레지스트리에 등록됩니다. 모델 학습 및 자체 실험 추적에 대한 자세한 내용은 scikit-learn을 사용하여 ML 모델을 학습하는 방법을 참조하세요.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Spark DataFrame으로 테스트 데이터 로드 이전 단계에서 학습된 ML 모델을 사용하여 일괄 처리 예측을 생성하려면 Spark DataFrame 형식의 테스트 데이터가 필요합니다. 다음 코드에서 변수 값을 사용자 고유의
test데이터로 대체합니다.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))추론을 위해 ML 모델을 로드하는
MLFlowTransformer개체를 만듭니다. 일괄 처리 예측을 생성하는 개체를 만들MLFlowTransformer려면 다음 작업을 수행합니다.-
test모델 입력으로 필요한 DataFrame 열을 지정합니다(이 경우 모두). - 새 출력 열의 이름을 선택합니다(이 경우
predictions). - 이러한 예측을 생성하기 위한 올바른 모델 이름 및 모델 버전을 제공합니다.
사용자 고유의 ML 모델을 사용하는 경우 입력 열, 출력 열 이름, 모델 이름 및 모델 버전의 값을 대체합니다.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )-
PREDICT 함수를 사용하여 예측을 생성합니다. PREDICT 함수를 호출하려면 변환기 API, Spark SQL API 또는 PySpark UDF(사용자 정의 함수)를 사용합니다. 다음 섹션에서는 PREDICT 함수를 호출하는 다른 메서드를 사용하여 이전 단계에서 정의된 테스트 데이터 및 ML 모델을 사용하여 일괄 처리 예측을 생성하는 방법을 보여 줍니다.
변환기 API를 사용하여 예측
이 코드는 변환기 API를 사용하여 PREDICT 함수를 호출합니다. 사용자 고유의 ML 모델을 사용하는 경우 모델의 값을 대체하고 데이터를 테스트합니다.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
Spark SQL API를 사용하여 예측
이 코드는 Spark SQL API를 사용하여 PREDICT 함수를 호출합니다. 고유한 ML 모델을 사용하는 경우, model_name을(를) 모델 이름으로, model_version을(를) 모델 버전으로, features을(를) 기능 열로 바꾸세요.
참고 사항
Spark SQL API를 사용하여 예측을 생성하는 경우 3단계와 같이 개체를 MLFlowTransformer 만들어야 합니다.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
사용자 정의 함수를 사용하여 예측하기
이 코드는 PySpark UDF를 사용하여 PREDICT 함수를 호출합니다. 사용자 고유의 ML 모델을 사용하는 경우 모델 및 기능에 대한 값을 대체합니다.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
ML 모델의 항목 페이지에서 PREDICT 코드 생성
ML 모델의 항목 페이지에서 PREDICT 함수를 사용하여 특정 모델 버전에 대한 일괄 처리 예측 생성을 시작하는 다음 옵션 중 하나를 선택할 수 있습니다.
- 코드 템플릿을 Notebook에 복사하고 매개 변수를 직접 사용자 지정합니다.
- 안내된 UI 환경을 사용하여 PREDICT 코드를 생성합니다.
안내된 UI 환경 사용
안내되는 UI 경험이 다음 단계를 통해 안내합니다.
- 채점할 원본 데이터를 선택합니다.
- 데이터를 ML 모델 입력에 올바르게 매핑합니다.
- 모델 출력의 대상을 지정합니다.
- PREDICT를 사용하여 예측 결과를 생성하고 저장하는 Notebook을 만듭니다.
안내된 환경을 사용하려면
지정된 ML 모델 버전의 항목 페이지로 이동합니다.
이 버전 적용 드롭다운에서 마법사에서 이 모델을 적용을 선택합니다.
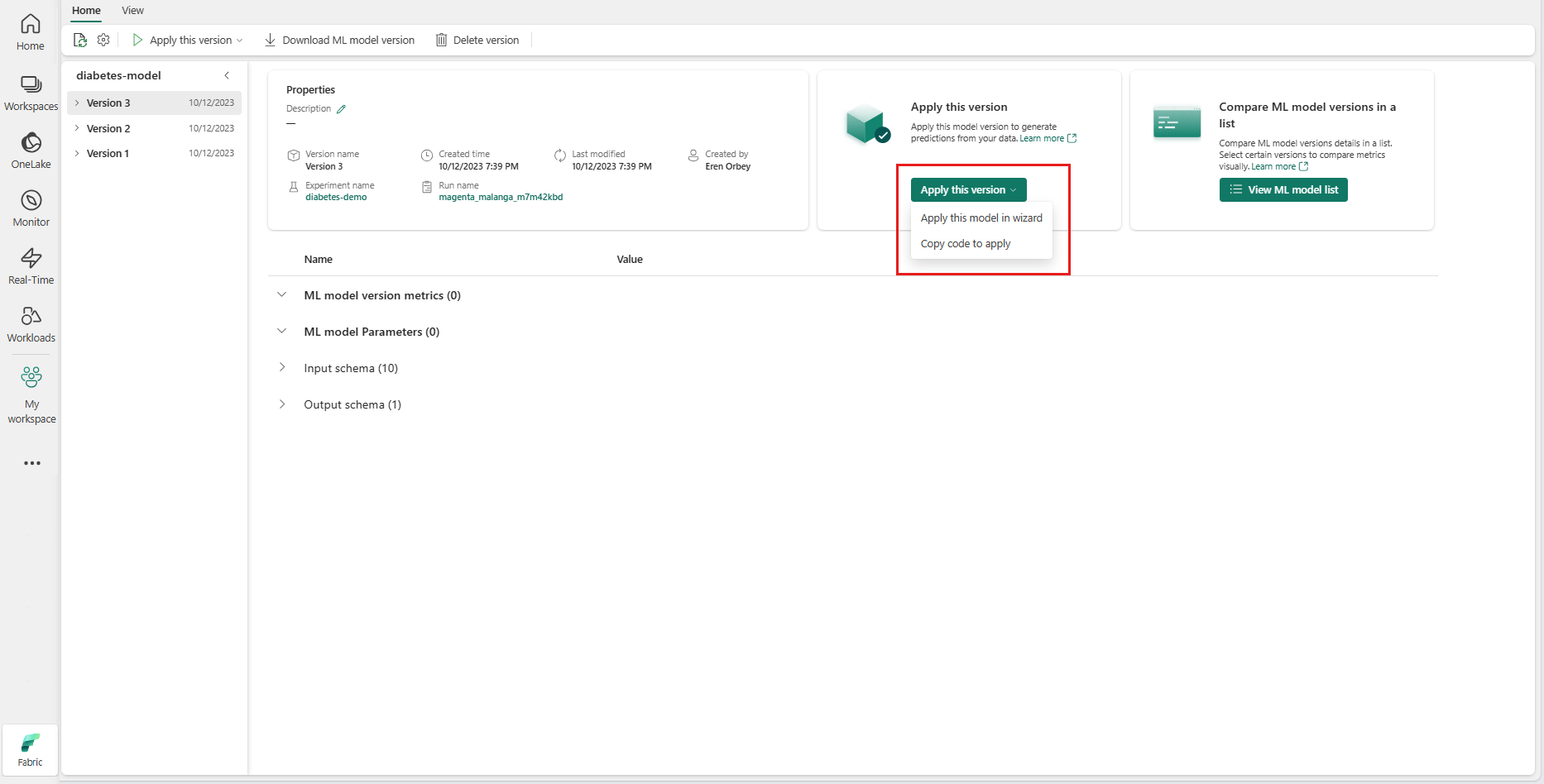
"입력 테이블 선택" 단계에서 "ML 모델 예측 적용" 창이 열립니다.
현재 작업 영역의 레이크하우스에서 입력 테이블을 선택합니다.
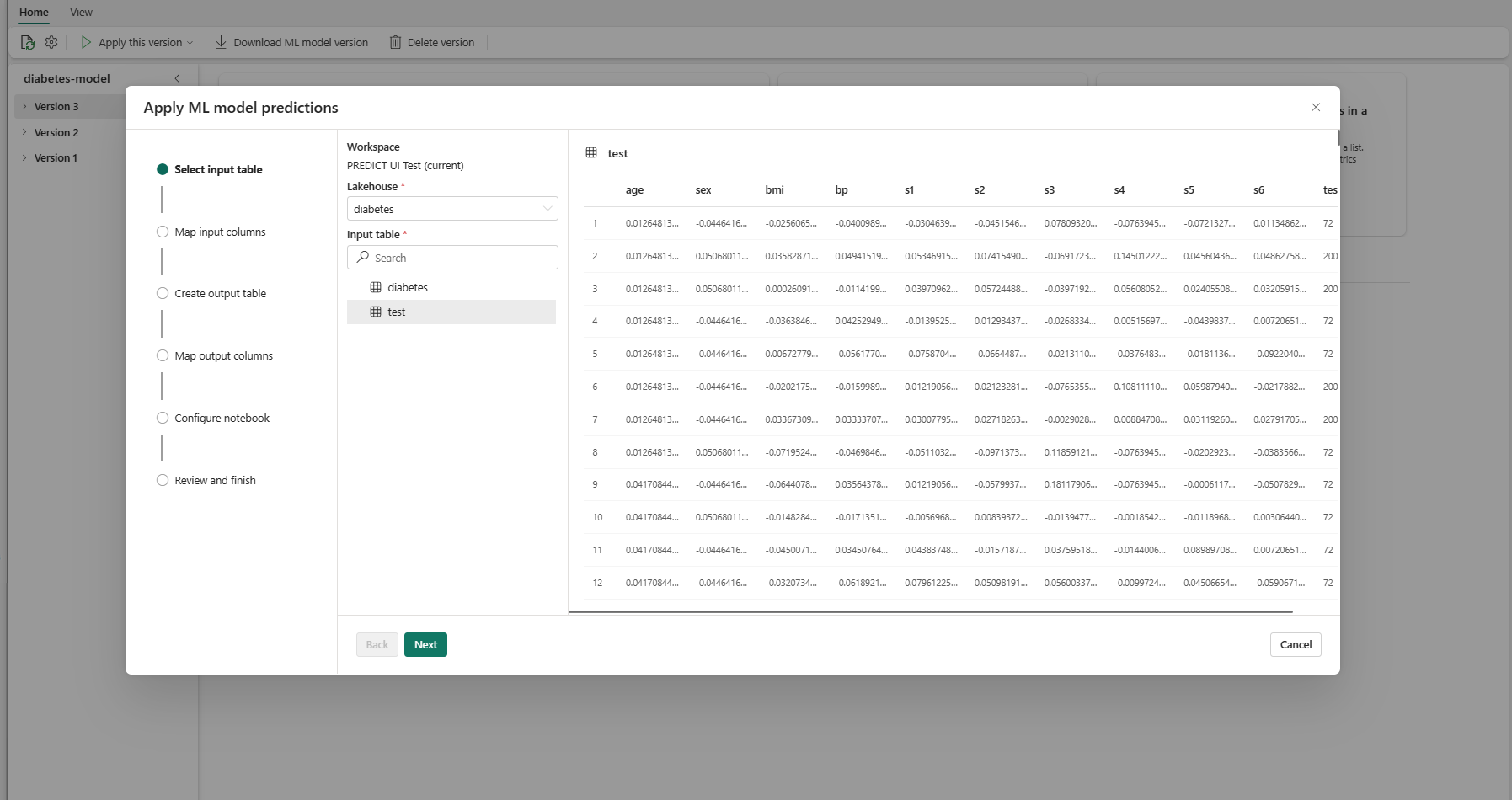
다음을 선택하여 "입력 열 매핑" 단계로 이동합니다.
원본 테이블의 열 이름을 모델의 서명에서 가져온 ML 모델의 입력 필드에 매핑합니다. 모델의 모든 필수 필드에 대한 입력 열을 제공해야 합니다. 또한 원본 열 데이터 형식은 모델의 예상 데이터 형식과 일치해야 합니다.
팁
입력 테이블 열의 이름이 ML 모델 서명에 기록된 열 이름과 일치하는 경우 마법사에서 이 매핑을 미리 채우게 됩니다.
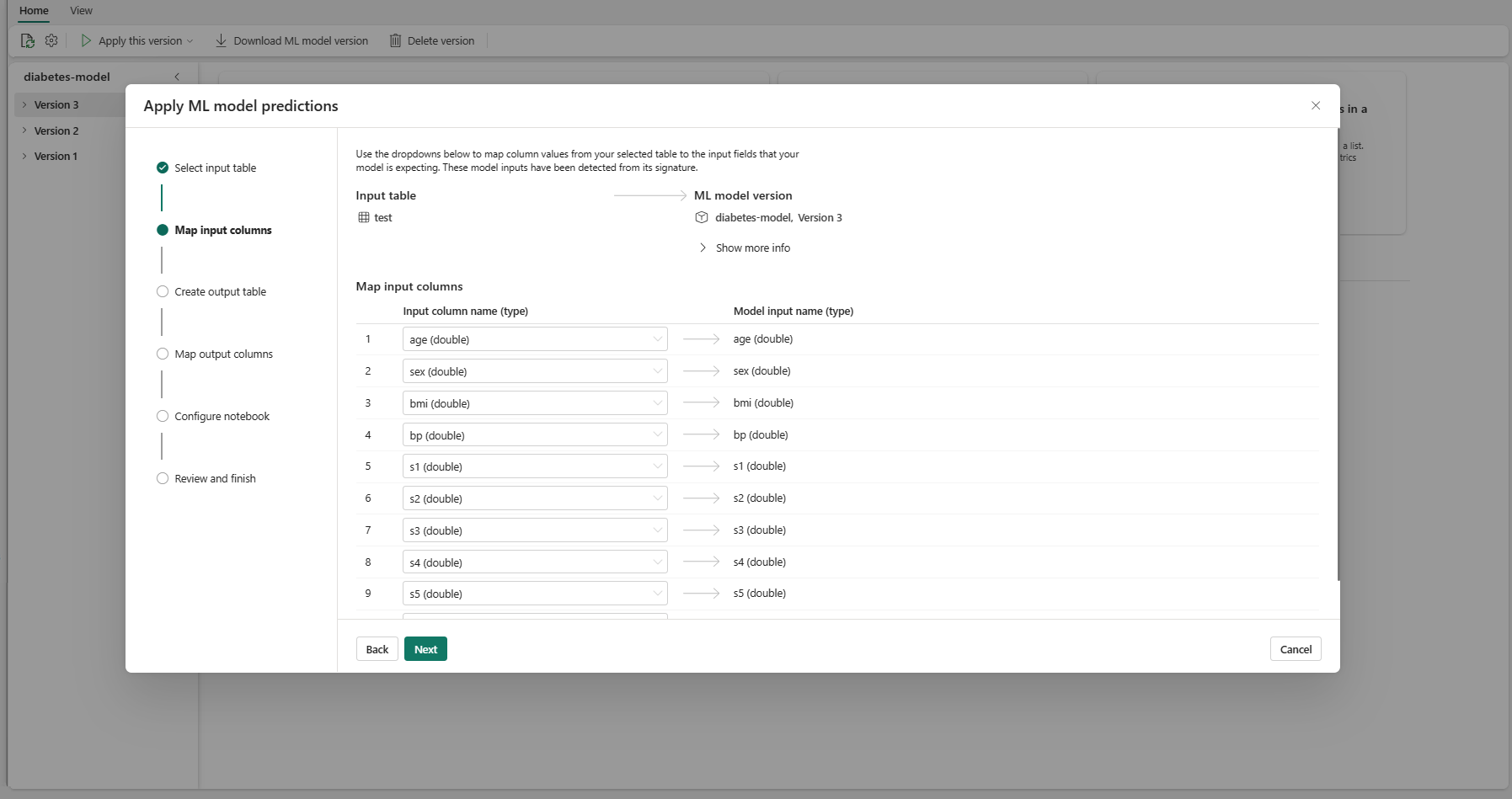
다음을 선택하여 "출력 테이블 만들기" 단계로 이동합니다.
현재 작업 영역의 선택한 레이크하우스 내에서 새 테이블의 이름을 제공합니다. 이 출력 테이블은 ML 모델의 입력 값을 저장하고 해당 테이블에 예측 값을 추가합니다. 기본적으로 출력 테이블은 입력 테이블과 동일한 레이크하우스에 만들어집니다. 대상 레이크하우스를 변경할 수 있습니다.
다음을 선택하여 "출력 열 매핑" 단계로 이동합니다.
제공된 텍스트 필드를 사용하여 ML 모델 예측을 저장하는 출력 테이블의 열 이름을 지정합니다.
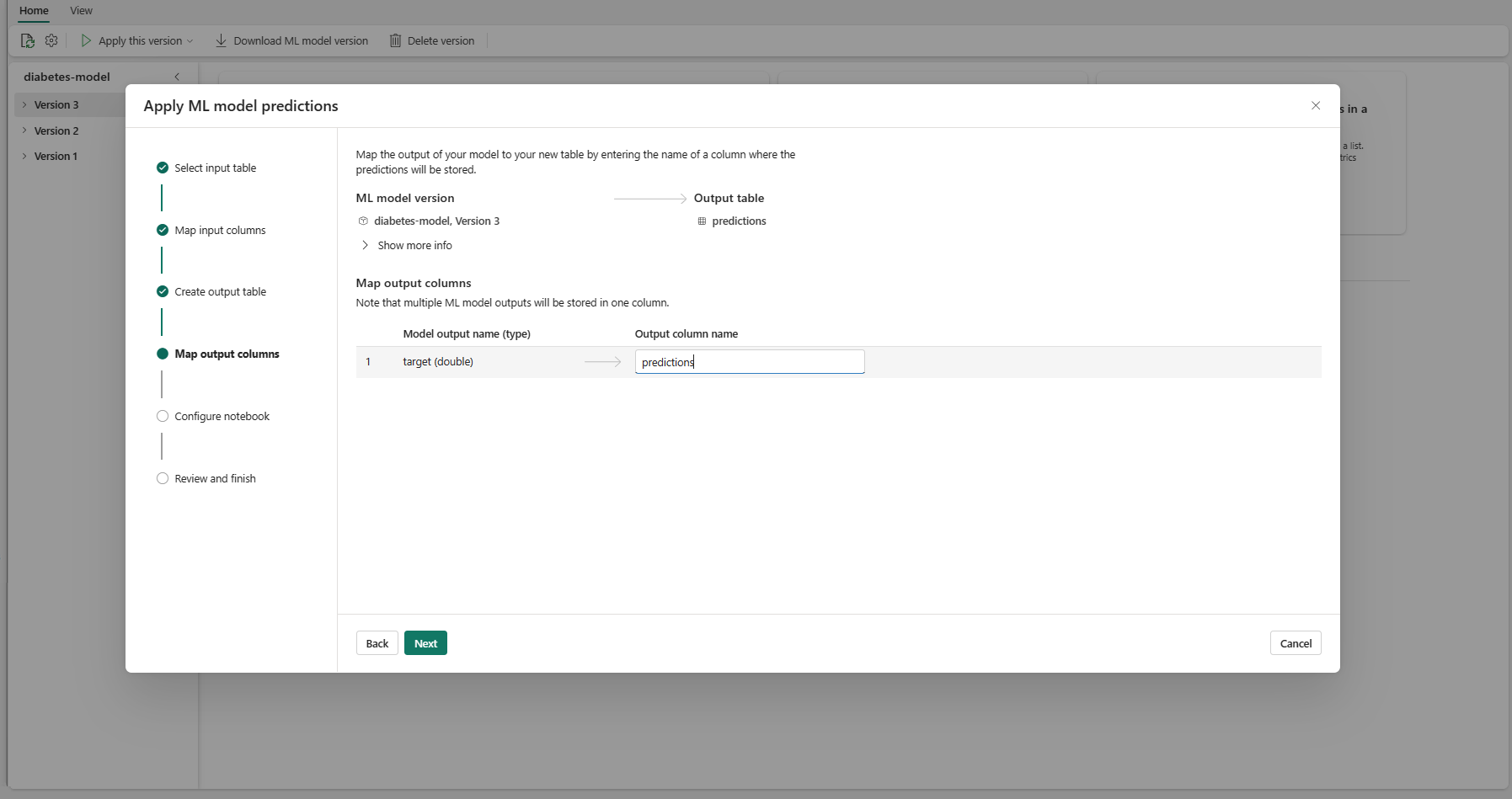
다음을 선택하여 "Notebook 구성" 단계로 이동합니다.
생성된 PREDICT 코드를 실행하는 새 Notebook의 이름을 제공합니다. 마법사는 이 단계에서 생성된 코드의 미리 보기를 표시합니다. 원하는 경우 코드를 클립보드에 복사하여 기존 Notebook에 붙여넣을 수 있습니다.

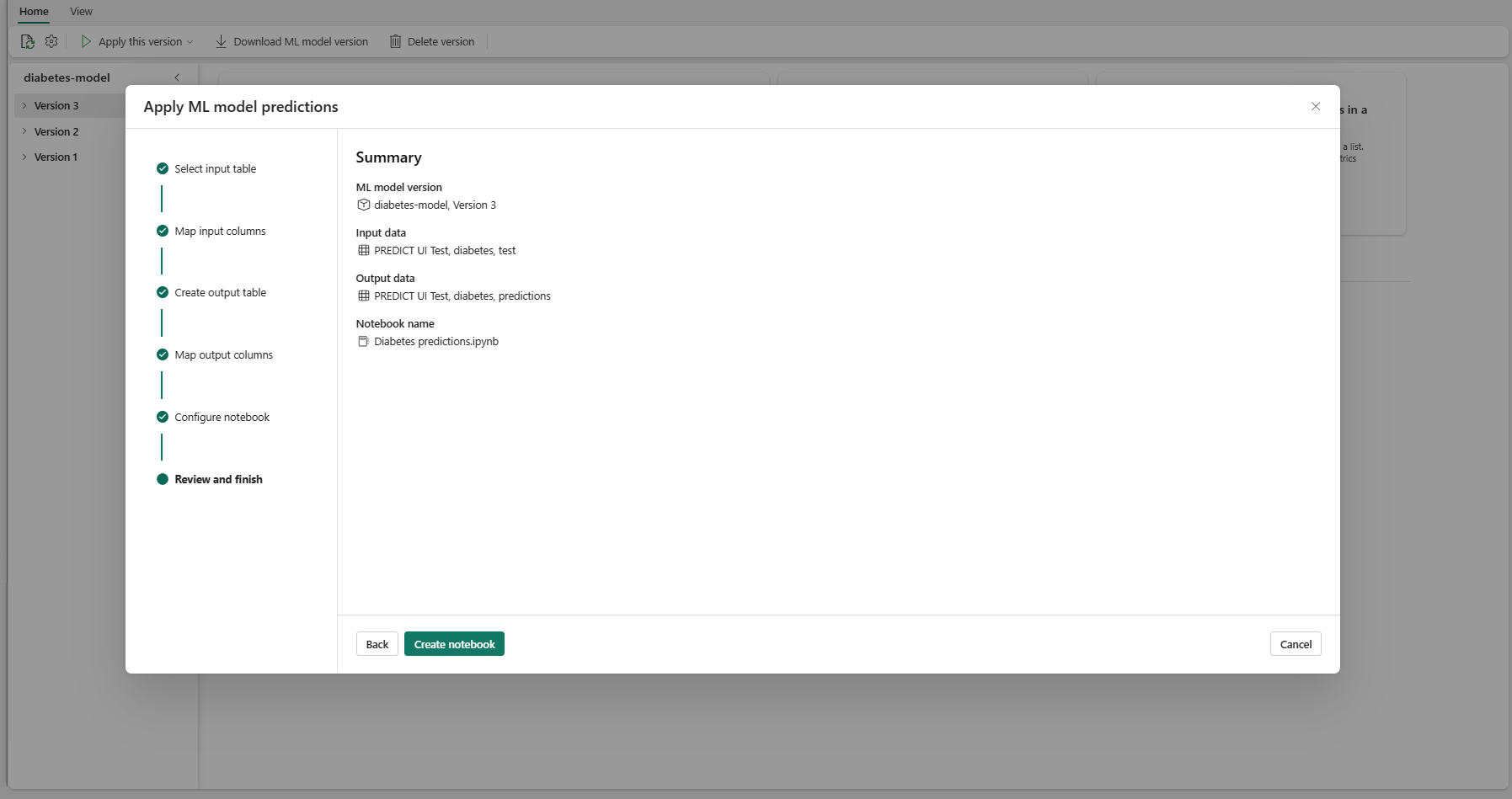
다음을 선택하여 "검토 및 완료" 단계로 이동합니다.
요약 페이지에서 세부 정보를 검토하고 Notebook 만들기를 선택하여 생성된 코드를 포함한 새 Notebook을 작업 영역에 추가합니다. 해당 Notebook으로 직접 이동하여 코드를 실행하여 예측을 생성하고 저장할 수 있습니다.







사용자 지정 가능한 코드 템플릿 사용
일괄 처리 예측을 생성하기 위해 코드 템플릿을 사용하려면 다음을 수행합니다.
- 지정된 ML 모델 버전의 항목 페이지로 이동합니다.
- 이 버전 적용 드롭다운에서 적용할 코드 복사를 선택합니다. 선택 영역은 사용자 지정 가능한 코드 템플릿을 복사합니다.
이 코드 템플릿을 Notebook에 붙여넣어 ML 모델을 사용하여 일괄 처리 예측을 생성할 수 있습니다. 코드 템플릿을 성공적으로 실행하려면 다음 값을 수동으로 바꿉다.
-
<INPUT_TABLE>: ML 모델에 대한 입력을 제공하는 테이블의 파일 경로입니다. -
<INPUT_COLS>: 입력 테이블에서 ML 모델에 피드할 열 이름의 배열입니다. -
<OUTPUT_COLS>: 예측을 저장하는 출력 테이블의 새 열 이름입니다. -
<MODEL_NAME>: 예측을 생성하는 데 사용할 ML 모델의 이름입니다. -
<MODEL_VERSION>: 예측을 생성하는 데 사용할 ML 모델의 버전입니다. -
<OUTPUT_TABLE>: 예측을 저장하는 테이블의 파일 경로입니다.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)
관련 콘텐츠
- 사기 감지 모델을 사용하는 엔드투엔드 예측 예제
Microsoft Fabric