이 자습서에서는 Fabric 데이터베이스의 기존 Cosmos DB에서 Fabric 미러된 데이터베이스를 쿼리합니다. 데이터베이스에서 미러링을 사용하도록 설정하고, 미러링 상태를 확인한 다음, 원본 데이터와 미러된 데이터를 분석에 모두 사용하는 방법을 알아봅니다.
필수 조건
기존 패브릭 용량
- 패브릭 용량이 없는 경우 Fabric 평가판을 시작합니다.
패브릭의 기존 Cosmos DB 데이터베이스
- 아직 없는 경우 Fabric에서 새 Cosmos DB 데이터베이스를 만듭니다.
Fabric 데이터베이스에서 Cosmos DB 구성
먼저 Fabric 데이터베이스의 Cosmos DB가 제대로 구성되고 미러링에 대한 데이터가 포함되어 있는지 확인합니다.
Fabric 포털(https://app.fabric.microsoft.com)을 엽니다.
기존 Cosmos DB 데이터베이스로 이동합니다.
중요합니다
이 자습서에서는 기존 Cosmos DB 데이터베이스에 샘플 데이터 집합 이 이미 로드되어 있어야 합니다. 이 자습서의 나머지 단계에서는 이 데이터베이스에 대해 동일한 데이터 집합을 사용한다고 가정합니다.
데이터베이스에 데이터가 있는 컨테이너가 하나 이상 포함되어 있는지 확인합니다. 탐색 창에서 컨테이너를 확장하고 항목이 있는지 확인하여 이 확인을 수행합니다.
메뉴 모음에서 설정을 선택하여 데이터베이스 구성에 액세스합니다.
설정 대화 상자에서 미러링 섹션으로 이동하여 이 데이터베이스에 대해 미러링이 사용하도록 설정되어 있는지 확인합니다.
비고
Fabric의 모든 Cosmos DB 데이터베이스에 대해 미러링이 자동으로 사용하도록 설정됩니다. 이 기능에는 추가 구성이 필요하지 않으며 OneLake에서 데이터를 항상 분석할 수 있습니다.
원본 데이터베이스에 연결
다음으로, 원본 Cosmos DB 데이터베이스에 직접 연결하고 쿼리할 수 있는지 확인합니다.
패브릭 포털에서 기존 Cosmos DB 데이터베이스로 다시 이동합니다.
기존 컨테이너를 선택하고 확장하여 콘텐츠를 봅니다.
항목을 선택하여 데이터베이스에서 직접 데이터를 찾습니다.
컨테이너의 항목을 볼 수 있는지 확인합니다. 예를 들어 샘플 데이터 세트를 사용하는 경우,
name,category, 그리고countryOfOrigin와 같은 속성을 가진 항목이 표시됩니다.메뉴에서 새 쿼리 를 선택하여 NoSQL 쿼리 편집기를 엽니다.
테스트 쿼리를 실행하여 연결 및 데이터 가용성을 확인합니다.
SELECT COUNT(1) AS itemCount FROM container이 쿼리는 컨테이너의 총 항목 수를 반환해야 합니다.
미러된 데이터베이스에 연결
이제 SQL 분석 엔드포인트를 통해 미러된 버전의 데이터베이스에 액세스하여 T-SQL을 사용하여 동일한 데이터를 쿼리합니다.
메뉴 모음에서 Cosmos DB 목록을 선택한 다음 SQL 분석 엔드포인트 를 선택하여 미러된 데이터베이스 뷰로 전환합니다.
컨테이너가 SQL 분석 엔드포인트에서 테이블로 표시되는지 확인합니다. 테이블의 이름은 컨테이너와 같아야 합니다.
메뉴에서 새 SQL 쿼리 를 선택하여 T-SQL 쿼리 편집기를 엽니다.
테스트 쿼리를 실행하여 미러링이 제대로 작동하는지 확인합니다.
SELECT COUNT(*) AS itemCount FROM [dbo].[SampleData]비고
샘플 데이터 집합을 사용하지 않는 경우
[SampleData]를 컨테이너 이름으로 바꿉니다.쿼리는 NoSQL 쿼리와 동일한 개수를 반환하여 미러링이 데이터를 성공적으로 복제하고 있는지 확인해야 합니다.
패브릭에서 원본 데이터베이스 쿼리
패브릭 포털을 사용하여 Azure Cosmos DB 계정에 이미 있는 데이터를 탐색하고 원본 Cosmos DB 데이터베이스를 쿼리합니다.
패브릭 포털에서 미러된 데이터베이스로 이동합니다.
보기를 선택한 다음 원본 데이터베이스를 선택합니다. 이 작업을 수행하면 원본 데이터베이스의 읽기 전용 보기가 있는 Azure Cosmos DB 데이터 탐색기가 열립니다.
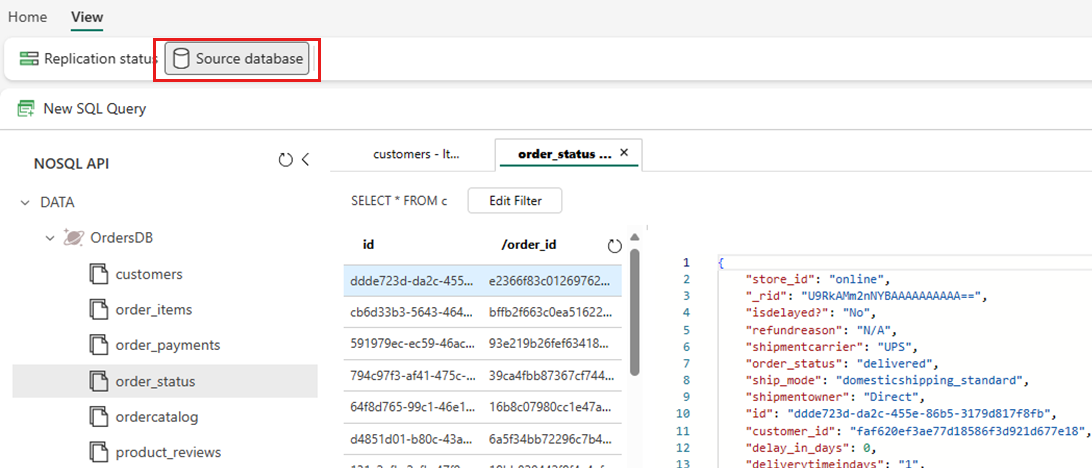
컨테이너를 선택한 다음 상황에 맞는 메뉴를 열고 새 SQL 쿼리를 선택합니다.
쿼리를 실행합니다. 예를 들어 컨테이너의 항목 수를 계산하는 데 사용합니다
SELECT COUNT(1) FROM container.비고
원본 데이터베이스의 모든 읽기는 Azure로 라우팅되고 계정에 할당된 RU(요청 단위)를 사용합니다.

대상 미러된 데이터베이스 분석
이제 T-SQL을 사용하여 이제 Fabric OneLake에 저장된 NoSQL 데이터를 쿼리합니다.
패브릭 포털에서 미러된 데이터베이스로 이동합니다.
미러된 Azure Cosmos DB에서 SQL 분석 엔드포인트로 전환합니다.
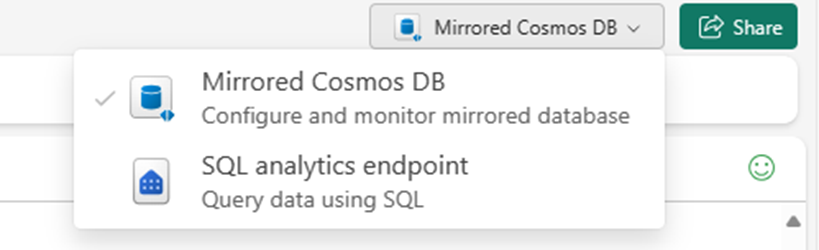
원본 데이터베이스의 각 컨테이너는 SQL 분석 엔드포인트에서 웨어하우스 테이블로 표현되어야 합니다.
테이블을 선택하고 상황에 맞는 메뉴를 연 다음 새 SQL 쿼리를 선택하고 마지막으로 상위 100개 선택 선택
쿼리는 선택한 테이블에서 100개의 레코드를 실행하고 반환합니다.
동일한 테이블에 대한 상황에 맞는 메뉴를 열고 새 SQL 쿼리를 선택합니다.
SUM,COUNT,MIN, 또는MAX와 같은 집계를 사용하는 예제 쿼리를 작성하십시오. 웨어하우스의 여러 테이블을 조인하여 여러 컨테이너에서 쿼리를 실행합니다.비고
예를 들어 이 쿼리는 여러 컨테이너에서 실행됩니다.
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]이 예제에서는 테이블 및 열의 이름을 가정합니다. SQL 쿼리를 작성할 때 사용자 고유의 테이블 및 열을 사용합니다.
쿼리를 선택한 다음 보기로 저장을 선택합니다. 보기에 고유한 이름을 지정합니다. 패브릭 포털에서 언제든지 이 보기에 액세스할 수 있습니다.
패브릭 포털에서 미러된 데이터베이스로 돌아갑니다.
새 시각적 쿼리를 선택합니다. 쿼리 편집기를 사용하여 복잡한 쿼리를 작성합니다.
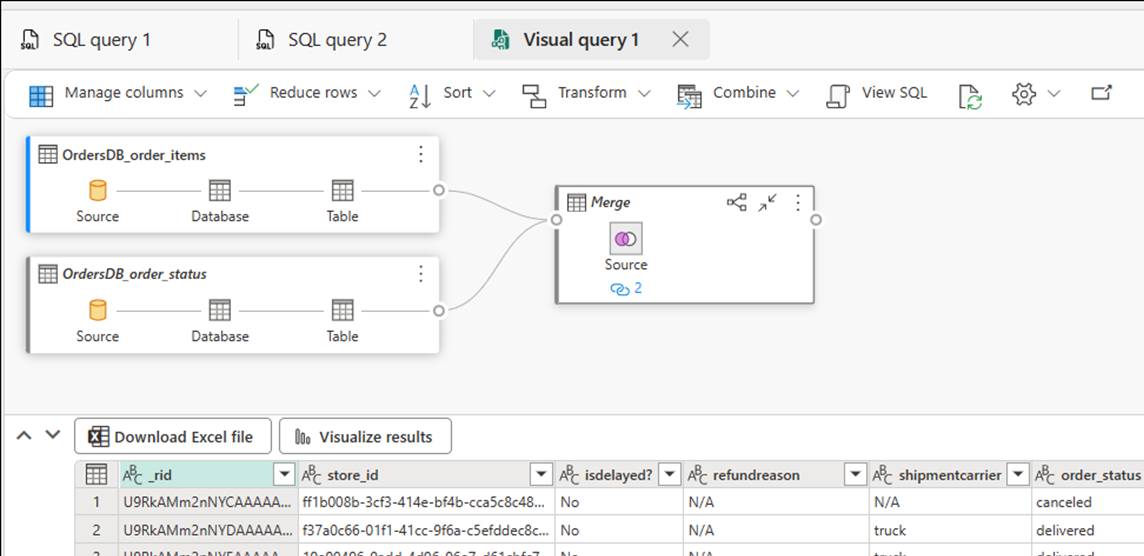


SQL 쿼리 또는 뷰에 대한 BI 보고서 빌드
- 쿼리 또는 보기를 선택한 다음 , 이 데이터 탐색(미리 보기)을 선택합니다. 이 작업은 OneLake 미러 데이터의 Direct Lake를 사용하여 Power BI에서 직접 쿼리를 탐색합니다.
- 필요에 따라 차트를 편집하고 보고서를 저장합니다.
팁 (조언)
추가 데이터 이동 없이 필요에 따라 Copilot 또는 기타 향상된 기능을 사용하여 대시보드 및 보고서를 빌드할 수도 있습니다.