Azure Synapse Analytics와 OneLake 통합
Azure Synapse는 엔터프라이즈 데이터 웨어하우징과 빅 데이터 분석을 함께 제공하는 무제한 분석 서비스입니다. 이 자습서에서는 Azure Synapse Analytics를 사용하여 OneLake에 연결하는 방법을 보여 줍니다.
Apache Spark를 사용하여 Synapse에서 데이터 쓰기
Apache Spark를 사용하여 Azure Synapse Analytics에서 OneLake에 샘플 데이터를 쓰려면 다음 단계를 수행합니다.
Synapse 작업 영역을 열고 기본 매개 변수를 사용하여 Apache Spark 풀을 만듭니다.

새 Apache Spark Notebook을 만듭니다.
Notebook을 열고 언어를 PySpark(Python)로 설정하고 새로 만든 Spark 풀에 연결합니다.
별도의 탭에서 Microsoft Fabric 레이크하우스로 이동하여 최상위 Tables 폴더를 찾습니다.
Tables 폴더를 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다.
속성 창에서 ABFS 경로를 복사합니다.
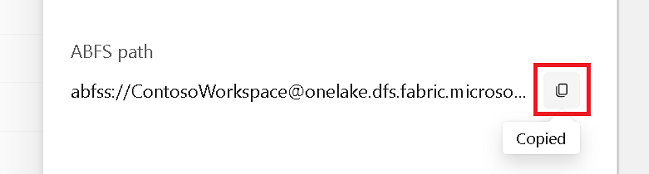
Azure Synapse Notebook으로 돌아가서 첫 번째 새 코드 셀에서 레이크하우스 경로를 제공합니다. 이 레이크하우스는 데이터가 나중에 기록되는 곳입니다. 셀을 실행합니다.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'새 코드 셀에서 Azure 열린 데이터 세트의 데이터를 데이터 프레임으로 로드합니다. 이 데이터 세트는 레이크하우스에 로드하는 데이터 세트입니다. 셀을 실행합니다.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))새 코드 셀에서 데이터를 필터링, 변환 또는 준비합니다. 이 시나리오에서는 더 빠른 로드를 위해 데이터 세트를 트리밍하거나 다른 데이터 세트와 조인하거나 특정 결과로 필터링할 수 있습니다. 셀을 실행합니다.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))새 코드 셀에서 OneLake 경로를 사용하여 Fabric 레이크하우스의 새 Delta-Parquet 테이블에 필터링된 데이터 프레임을 작성합니다. 셀을 실행합니다.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')마지막으로 새 코드 셀에서 OneLake에서 새로 로드된 파일을 읽어 데이터가 성공적으로 작성되었는지 테스트합니다. 셀을 실행합니다.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
축하합니다. 이제 Azure Synapse Analytics에서 Apache Spark를 사용하여 OneLake에서 데이터를 읽고 쓸 수 있습니다.
SQL을 사용하여 Synapse에서 데이터 읽기
다음 단계에 따라 SQL 서버리스를 사용하여 Azure Synapse Analytics에서 OneLake의 데이터를 읽습니다.
Fabric 레이크하우스를 열고 Synapse에서 쿼리하려는 테이블을 식별합니다.
테이블을 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다.
테이블의 ABFS 경로를 복사합니다.
Synapse Studio에서 Synapse 작업 영역을 엽니다.
새 SQL 스크립트를 만듭니다.
SQL 쿼리 편집기에서 다음 쿼리를 입력하고
ABFS_PATH_HERE를 앞에서 복사한 경로로 바꿉니다.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;쿼리를 실행하여 테이블의 상위 10개 행을 봅니다.
축하합니다. 이제 Azure Synapse Analytics에서 SQL 서버리스를 사용하여 OneLake에서 데이터를 읽을 수 있습니다.