실시간 분석 자습서 5부: 고급 KQL 쿼리 사용
참고 항목
이 자습서는 시리즈의 일부입니다. 이전 섹션에서는 자습서 4부: KQL 및 SQL을 사용하여 데이터 탐색을 참조하세요.
KQL 쿼리 세트 만들기
다음 단계에서는 Kusto 쿼리 언어 고급 데이터 분석 기능을 사용하여 데이터베이스에 수집한 두 테이블을 쿼리합니다.
NycTaxiDB라는 KQL 데이터베이스로 이동합니다.
새 관련 항목>KQL 쿼리 세트 선택
nyctaxiqs를 KQL 쿼리 세트 이름으로 입력 합니다 .
만들기를 실행합니다. KQL 쿼리 세트는 여러 개의 자동 채워진 예제 쿼리와 함께 열립니다.

쿼리 데이터
이 섹션에서는 KQL 쿼리 세트의 일부 쿼리 및 시각화 기능을 안내합니다. 쿼리를 복사하여 사용자 고유의 쿼리 편집기에서 붙여넣어 결과를 실행하고 시각화합니다.
다음 쿼리를 실행하여 뉴욕시에서 노란색 택시의 상위 10개 픽업 위치를 반환합니다.
nyctaxitrips | summarize Count=count() by PULocationID | top 10 by Count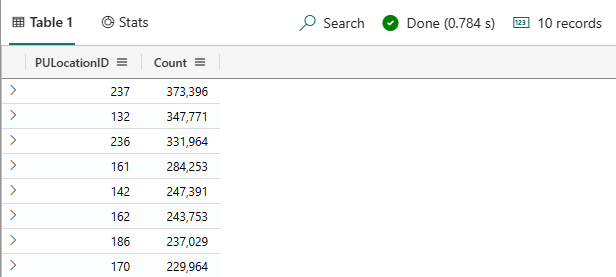
이 쿼리는 이전 쿼리에 단계를 추가합니다. 쿼리를 실행하여 위치 테이블을 사용하여 상위 10개 픽업 위치의 해당 영역을 조회합니다. 조회 연산자는 차원 테이블에서 조회된 값을 사용하여 팩트 테이블의 열을 확장합니다.
nyctaxitrips | lookup (Locations) on $left.PULocationID == $right.LocationID | summarize Count=count() by Zone | top 10 by Count | render columnchart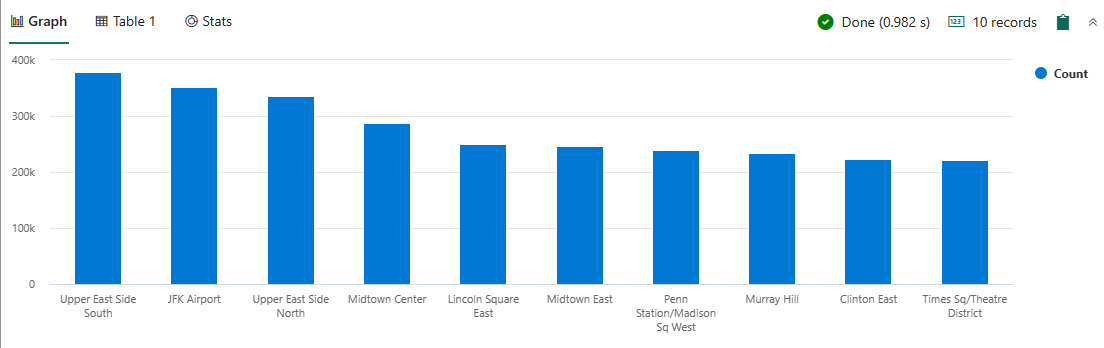
또한 KQL은 변칙을 검색하는 기계 학습 기능을 제공합니다. 다음 쿼리를 실행하여 맨해튼 자치구의 고객이 제공한 팁에 변칙을 검사. 이 쿼리는 series_decompose_anomalies 함수를 사용합니다.
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = avg(tip_amount) on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-04) step 1h | extend anomalies = series_decompose_anomalies(s1) | render anomalychart with (anomalycolumns=anomalies)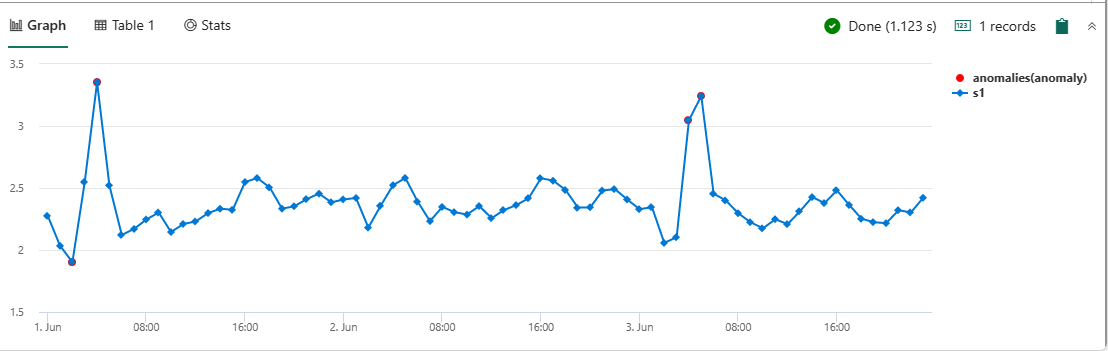
빨간색 점 위로 마우스를 가져가서 변칙 값을 확인합니다.
series_decompose_forecast 함수의 예측 기능을 사용할 수도 있습니다. 다음 쿼리를 실행하여 맨해튼 자치구에서 충분한 택시가 작동하는지 확인하고 시간당 필요한 택시 수를 예측합니다.
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = count() on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-08)+3d step 1h by PULocationID | extend forecast = series_decompose_forecast(s1, 24*3) | render timechart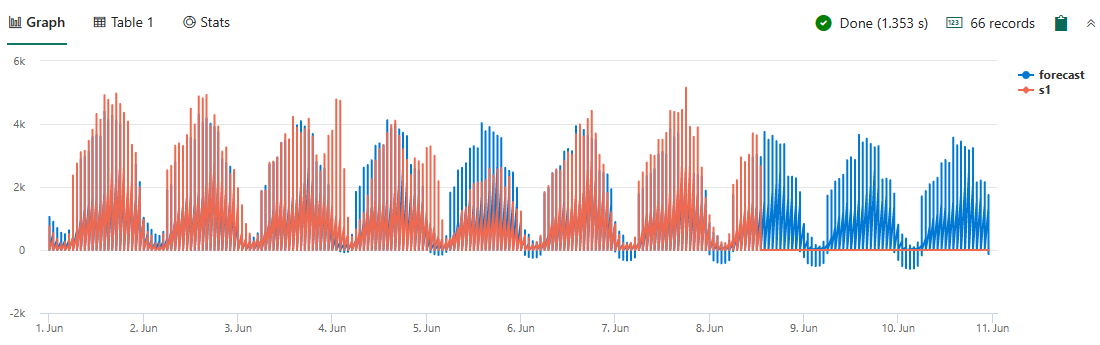



관련 콘텐츠
이 자습서에서 수행된 작업에 대한 자세한 내용은 다음을 참조하세요.
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기