클라우드 서비스 및 IoT 디바이스는 서비스 상태 모니터링, 물리적 프로덕션 프로세스 및 사용 추세와 같은 인사이트를 얻는 데 사용할 수 있는 원격 분석 데이터를 생성합니다. 시계열 분석을 수행하는 것은 일반적인 기준 패턴과 비교하여 이러한 메트릭의 패턴에서 편차를 식별하는 한 가지 방법입니다.
KQL(Kusto 쿼리 언어)에는 여러 시계열의 생성, 조작 및 분석에 대한 기본 지원이 포함되어 있습니다. 이 문서에서는 KQL을 사용하여 몇 초 만에 수천 개의 시계열을 만들고 분석하여 거의 실시간 모니터링 솔루션 및 워크플로를 사용하도록 설정하는 방법을 알아봅니다.
시계열 만들기
이 섹션에서는 연산자를 사용하여 make-series 간단하고 직관적으로 일반 시계열의 큰 집합을 만들고 필요에 따라 누락된 값을 채웁니다.
시계열 분석의 첫 번째 단계는 원래 원격 분석 테이블을 파티션하고 시계열 집합으로 변환하는 것입니다. 테이블에는 일반적으로 타임스탬프 열, 컨텍스트 차원 및 선택적 메트릭이 포함됩니다. 차원은 데이터를 분할하는 데 사용됩니다. 목표는 정기적으로 파티션당 수천 개의 시계열을 만드는 것입니다.
입력 테이블 demo_make_series1 임의 웹 서비스 트래픽의 600K 레코드를 포함합니다. 다음 명령을 사용하여 10가지 레코드를 샘플링합니다.
demo_make_series1 | take 10
결과 테이블에는 타임스탬프 열, 세 개의 컨텍스트 차원 열 및 메트릭이 포함되어 있지 않습니다.
| 타임 스탬프 | BrowserVer | OsVer | 국가/지역 |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | 영국 |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | 영국 |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Windows 10 | 영국 |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Windows 10 | 리투아니아 |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | 인도 |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Windows 10 | 영국 |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | 네덜란드 |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Windows 10 | 영국 |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Windows 10 | 인도 |
메트릭이 없으므로 다음 쿼리를 사용하여 OS로 분할된 트래픽 수 자체를 나타내는 시계열 집합만 빌드할 수 있습니다.
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
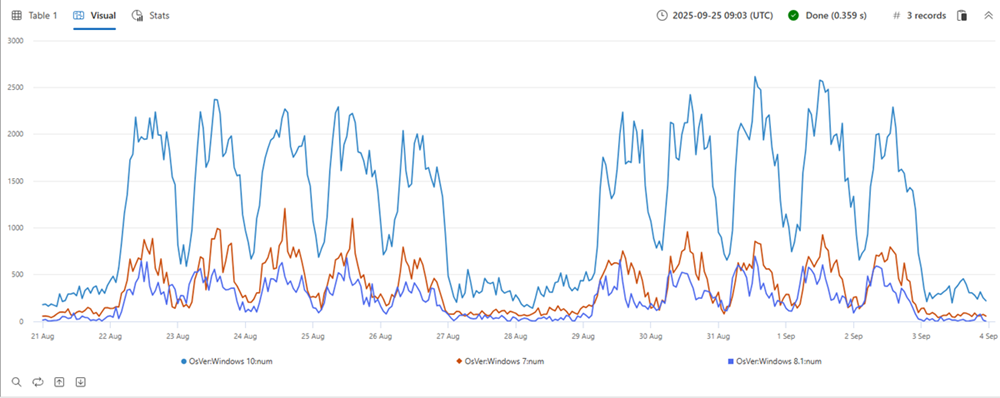
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
- 연산자를
make-series사용하여 다음 세 개의 시계열 집합을 만듭니다.-
num=count(): 트래픽의 시계열 -
from min_t to max_t step 1h: 시계열은 시간 범위(테이블 레코드의 가장 오래된 타임스탬프 및 최신 타임스탬프)에서 1시간 구간으로 생성됩니다. -
default=0: 누락된 bin에 대한 채우기 메서드를 지정하여 일반 시계열을 만듭니다. 또는 변경에series_fill_const(),series_fill_forward(),series_fill_backward()및series_fill_linear()을(를) 사용하십시오. -
by OsVer: OS별 파티션
-
- 실제 시계열 데이터 구조는 각 시간 bin당 집계된 값의 숫자 배열입니다. 시각화에 사용합니다
render timechart.
위의 표에는 세 개의 파티션이 있습니다. 그래프에 표시된 대로 각 OS 버전에 대해 Windows 10(빨간색), 7(파란색) 및 8.1(녹색)이라는 별도의 시계열을 만들 수 있습니다.
시계열 분석 함수
이 섹션에서는 일반적인 계열 처리 함수를 수행합니다. 시계열 집합이 만들어지면 KQL은 이를 처리하고 분석할 수 있는 점점 더 많은 함수 목록을 지원합니다. 시계열을 처리하고 분석하기 위한 몇 가지 대표적인 함수에 대해 설명합니다.
필터링
필터링은 신호 처리의 일반적인 사례이며 시계열 처리 작업(예: 노이즈 신호 부드러운 변경 감지)에 유용합니다.
- 다음과 같은 두 가지 제네릭 필터링 함수가 있습니다.
-
series_fir(): FIR 필터 적용 변경 검색을 위해 이동 평균 및 시계열의 구분을 간단하게 계산하는 데 사용됩니다. -
series_iir(): IIR 필터 적용 지수 평활화 및 누적 합계에 사용됩니다.
-
-
Extend쿼리에 5개의 bin 크기의 새로운 이동 평균 계열(명명된 ma_num)을 추가하여 설정한 시계열입니다.
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart

회귀 분석
분할된 선형 회귀 분석을 사용하여 시계열의 추세를 예측할 수 있습니다.
- series_fit_line()를 사용하여 일반적인 추세 감지를 위해 시계열에 가장 적합한 줄을 맞춥니다.
- series_fit_2lines()를 사용하여 모니터링 시나리오에 유용한 기준선을 기준으로 추세 변경을 검색합니다.
시계열 쿼리의 series_fit_line() 예제 및 series_fit_2lines() 함수:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)
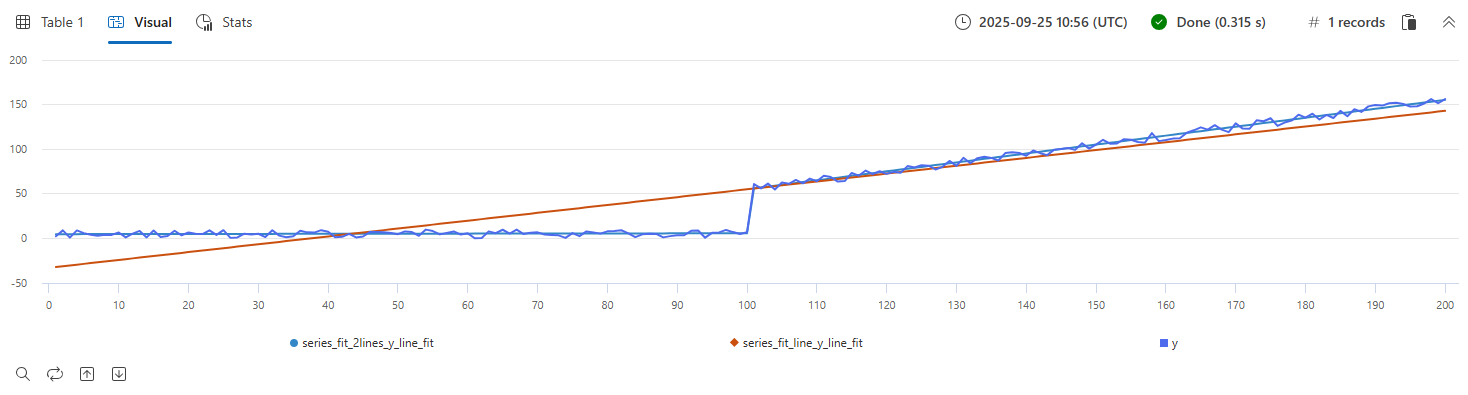
- 파랑: 원본 시계열
- 녹색: 장착 선
- 빨간색: 2개의 맞춤 선
비고
함수는 점프(수준 변경) 지점을 정확하게 감지했습니다.
계절성 감지
많은 메트릭은 계절적(주기적) 패턴을 따릅니다. 클라우드 서비스의 사용자 트래픽은 일반적으로 영업일 중 가장 높고 야간 및 주말에 가장 낮은 일별 및 주간 패턴을 포함합니다. IoT 센서는 주기적인 간격으로 측정합니다. 온도, 압력 또는 습도와 같은 물리적 측정은 계절적 동작도 표시할 수 있습니다.
다음 예제에서는 웹 서비스의 한 달 트래픽을 2시간 단위로 나누어 계절성을 탐지하는 방법을 적용합니다.
demo_series3
| render timechart

-
series_periods_detect()를 사용하여 시계열의 주기를 자동으로 탐지합니다.
-
num: 분석할 시계열 -
0.: 최소 기간 길이(0은 최소값 없음) -
14d/2h: 14일을 2시간 bin으로 나눈 최대 기간(일)입니다. -
2: 검색할 기간 수
-
- 메트릭에 특정 고유 기간이 있어야 하며 해당 기간이 있는지 확인하려는 경우 series_periods_validate() 를 사용합니다.
비고
특정 고유 기간이 없는 경우 이상입니다.
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| 기간 | 점수 | 일 |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
이 함수는 매일 및 매주 계절성을 검색합니다. 주말은 평일과 다르기 때문에 일일 점수는 주중보다 적습니다.
요소별 함수
시계열에서 산술 및 논리 연산을 수행할 수 있습니다. series_subtract()를 사용하여 잔차 시계열, 즉 원래 원시 메트릭과 부드러운 메트릭 간의 차이를 계산하고 잔차 신호에서 변칙을 찾을 수 있습니다.
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart
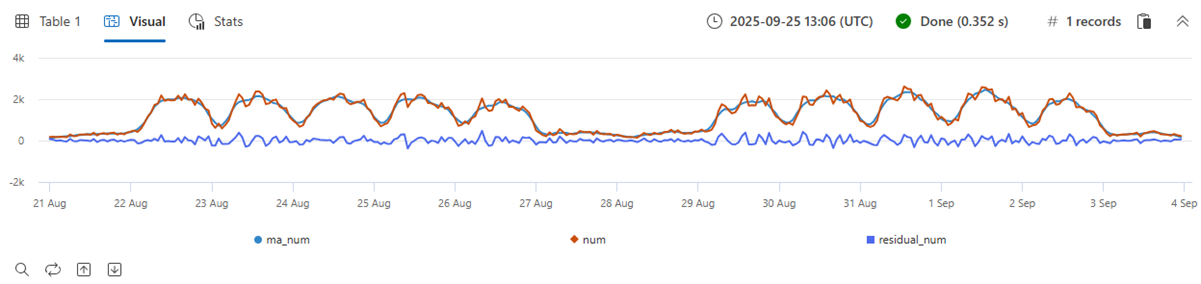
- 파랑: 원본 시계열
- 빨간색: 평활화된 시계열
- 녹색: 잔차 시계열
대규모 시계열 워크플로
아래 예제에서는 변칙 검색을 위해 이러한 함수를 몇 초 만에 수천 개의 시계열에서 대규모로 실행하는 방법을 보여 줍니다. 4일 동안 DB 서비스의 읽기 수 메트릭에 대한 몇 가지 샘플 원격 분석 레코드를 보려면 다음 쿼리를 실행합니다.
demo_many_series1
| take 4
| 타임 스탬프 | Loc(Loc) | Op(작업) | 데이터베이스 | 데이터읽기 |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
그리고 간단한 통계:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| 번호 | min_t | max_t |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
읽기 메트릭의 1시간 bin(총 4일 * 24시간 = 96포인트)으로 시계열을 작성하면 일반적인 패턴 변동이 발생합니다.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)
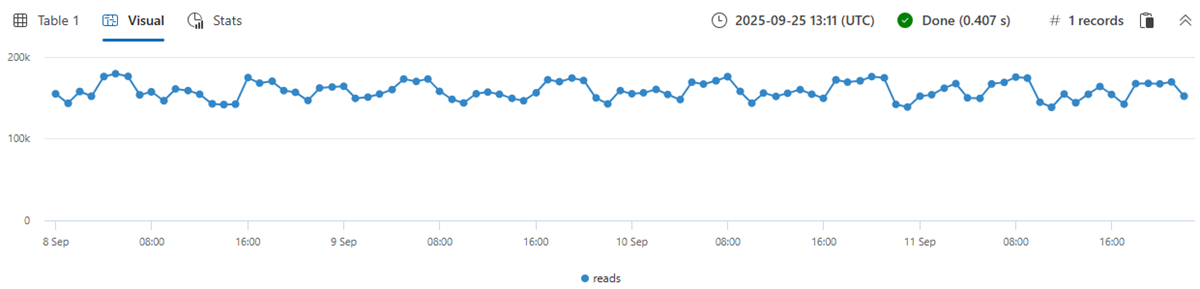
단일 표준 시계열은 비정상적인 패턴이 있을 수 있는 수천 개의 다른 인스턴스에서 집계되므로 위의 동작은 오해의 소지가 있습니다. 따라서 인스턴스당 시계열을 만듭니다. 인스턴스는 Loc(위치), Op(작업) 및 DB(특정 컴퓨터)로 정의됩니다.
얼마나 많은 시계열을 만들 수 있나요?
demo_many_series1
| summarize by Loc, Op, DB
| count
| 수량 |
|---|
| 18339 |
이제 읽기 개수 메트릭의 18339 시계열 집합을 만듭니다. 메이크 시리즈 문에 by 선형 회귀 절을 추가하고, 가장 중요한 감소 추세를 보인 상위 2개의 시계열을 선택합니다.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
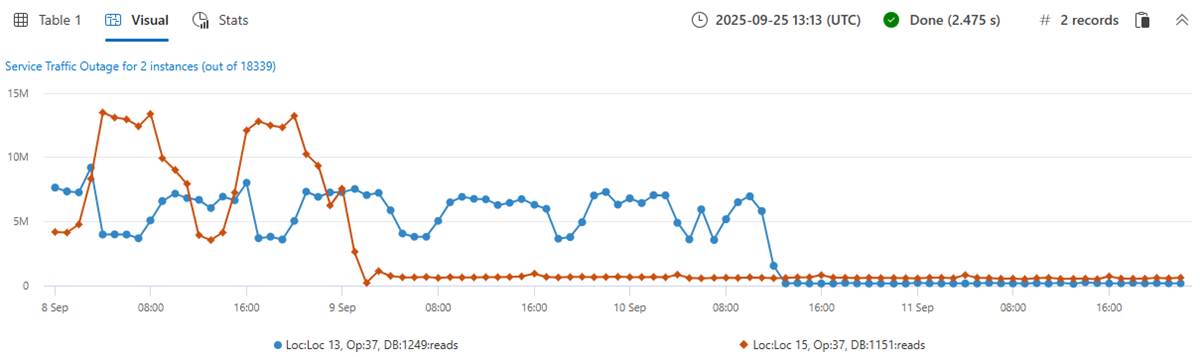
인스턴스를 표시합니다.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Loc(Loc) | Op(작업) | 데이터베이스 | 경사 |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -102743.910227889 |
| Loc 13 | 37 | 1249 | -86303.2334644601 |
2분 이내에 20,000개에 가까운 시계열이 분석되었고 읽기 수가 갑자기 삭제된 두 개의 비정상적인 시계열이 발견되었습니다.
빠른 성능과 결합된 이러한 고급 기능은 시계열 분석을 위한 독특하고 강력한 솔루션을 제공합니다.
관련 콘텐츠
- KQL 을 사용한 변칙 검색 및 예측에 대해 알아봅니다.
- KQL 을 사용한 기계 학습 기능에 대해 알아봅니다.