연습 - HDInsight Spark 클러스터에서 쿼리 실행
이 연습에서는 csv 파일에서 데이터 프레임을 만드는 방법과 Azure HDInsight의 Apache Spark 클러스터에 관해 대화형 Spark SQL 쿼리를 실행하는 방법을 알아봅니다. Spark에서 데이터 프레임은 명명된 열로 구성된 데이터의 분산된 컬렉션입니다. 데이터 프레임은 관계형 데이터베이스의 테이블이나 R/Python의 데이터 프레임과 개념적으로 동일합니다.
이 자습서에서는 다음 방법에 관해 알아봅니다.
- csv 파일에서 데이터 프레임 만들기
- 데이터 프레임에서 쿼리 실행
csv 파일에서 데이터 프레임 만들기
다음 샘플 csv 파일은 건물의 온도 정보를 포함하며 Spark 클러스터의 파일 시스템에 저장됩니다.
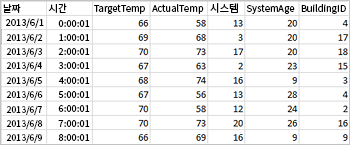
Jupyter Notebook의 빈 셀에 다음 코드를 붙여넣은 다음, Shift+Enter를 눌러 해당 코드를 실행합니다. 코드는 이 시나리오에 필요한 형식을 가져옵니다.
from pyspark.sql import * from pyspark.sql. types import *Jupyter에서 대화형 쿼리를 실행하면 웹 브라우저 창 또는 탭 캡션에 노트북 제목과 함께 (사용 중) 상태가 표시됩니다. 또한 오른쪽 위 모서리에 있는 PySpark 텍스트 옆에 단색 원이 표시됩니다. 작업이 완료되면 속이 빈 원으로 변경됩니다.
다음 코드를 실행하여 데이터 프레임 및 임시 테이블(hvac)을 만듭니다.
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
데이터 프레임에서 쿼리 실행
테이블이 만들어지면 데이터에 대한 대화형 쿼리를 실행할 수 있습니다.
노트북의 빈 셀에서 다음 코드를 실행합니다.
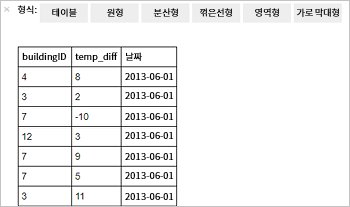
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"다음과 같은 테이블 형식 출력이 표시됩니다.
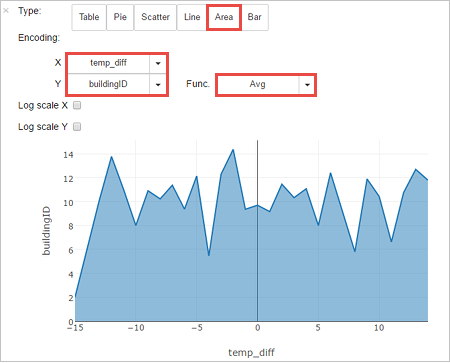
다른 시각화로 결과를 볼 수도 있습니다. 동일한 출력에 대한 영역형 그래프를 보려면 영역을 선택한 다음 표시된 것처럼 다른 값을 설정합니다.
노트북 메뉴 모음에서 파일 > 저장 및 검사점으로 이동합니다.
노트북을 종료하여 클러스터 리소스를 해제합니다. 노트북 메뉴 모음에서 파일 > 닫기 및 중지로 이동합니다.