흐름에서 변수를 생성할 때 Power Automate는 콘텐츠를 기반으로 특정 유형으로 변환합니다.
숫자와 같은 이러한 데이터 형식 중 일부는 애플리케이션 전체에서 널리 사용되는 반면 브라우저 인스턴스와 같은 다른 데이터 형식은 명시적 작업 또는 작업 그룹이 필요합니다.
간단한 데이터 형식
단순 데이터 형식은 텍스트 및 숫자와 같은 단일 값을 나타냅니다. 이러한 데이터 형식을 독립적으로 사용하거나 이를 사용하여 목록 및 데이터 테이블과 같은 더 복잡한 데이터 구조를 생성할 수 있습니다.
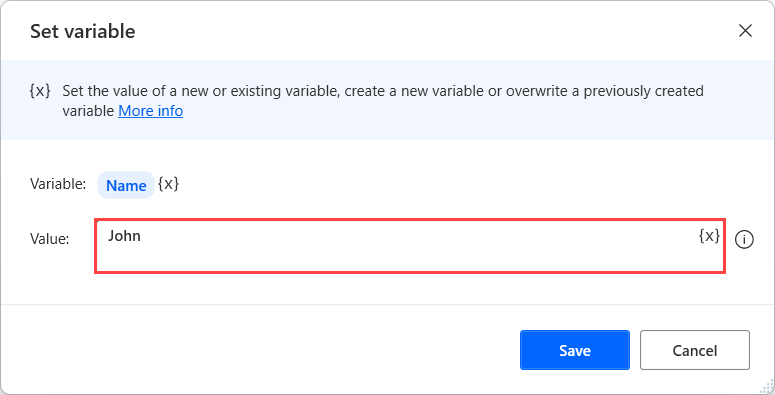
텍스트 값
이것은 이메일 주소에서 .txt 파일의 텍스트 내용에 이르기까지 모든 종류의 텍스트입니다.
텍스트 값 변수를 만들려면 변수 설정 작업을 사용하고 입력 매개 변수를 표기 없이 원하는 텍스트로 채웁니다.
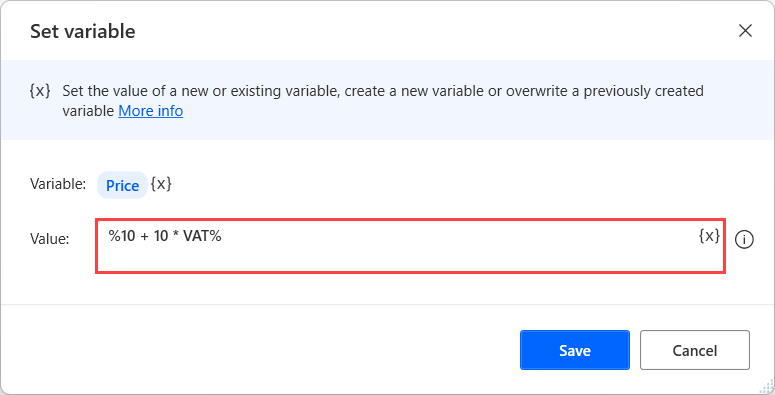
숫자 값
숫자는 숫자에 적용되는 유형입니다. 이 데이터 형식만 수학 연산에 사용할 수 있습니다.
숫자 값 변수를 만들려면 변수 설정 작업을 사용하고 입력 매개 변수를 표기 없이 숫자로 채웁니다.
하드코딩된 숫자 값을 제외하고 백분율 표시 내의 변수를 통한 수학 식을 사용할 수 있습니다. 수학 식에 대한 자세한 정보는 변수 및 % 표기법 사용을 참고하십시오.
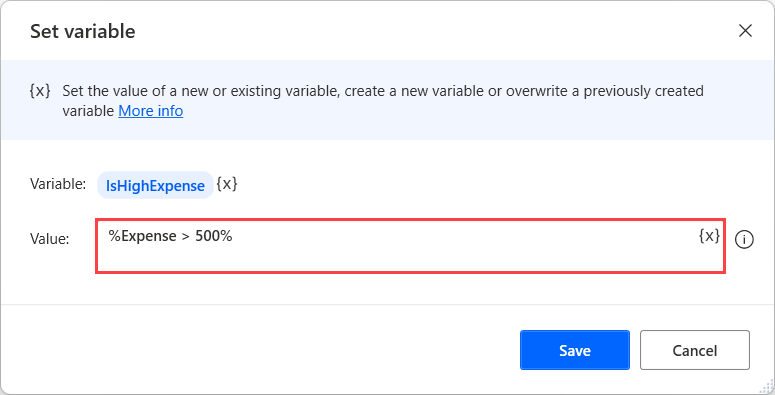
부울 값
값은 True 또는 False 중 하나일 수 있습니다.
부울 값 변수를 만들려면 변수 설정 작업을 사용하고 %True% 또는 %False% 식으로 입력 매개 변수를 채웁니다.
또한 논리 연산자, 변수 및 백분율 표기법을 사용하여 복잡한 식을 만들 수 있습니다. 논리 식에 대한 자세한 정보는 변수 및 % 표기법 사용을 참고하십시오.
고급 데이터 형식
고급 데이터 형식은 복잡한 데이터 구조를 나타냅니다. 이들은 하나의 엔터티로 액세스할 수 있는 다른 데이터 형식의 컬렉션으로 작동합니다.
List
목록은 항목 모음입니다. 개별 목록 항목의 형식에 따라 텍스트 값 목록, 숫자 값 목록 등이 있을 수 있습니다. 목록 데이터 형식은 프로그래밍 용어로 단일 차원 배열과 동일합니다.
새 목록 만들기 작업을 통해 목록을 만들고 목록에 항목 추가 작업을 통해 해당 목록에 항목을 추가할 수 있습니다.
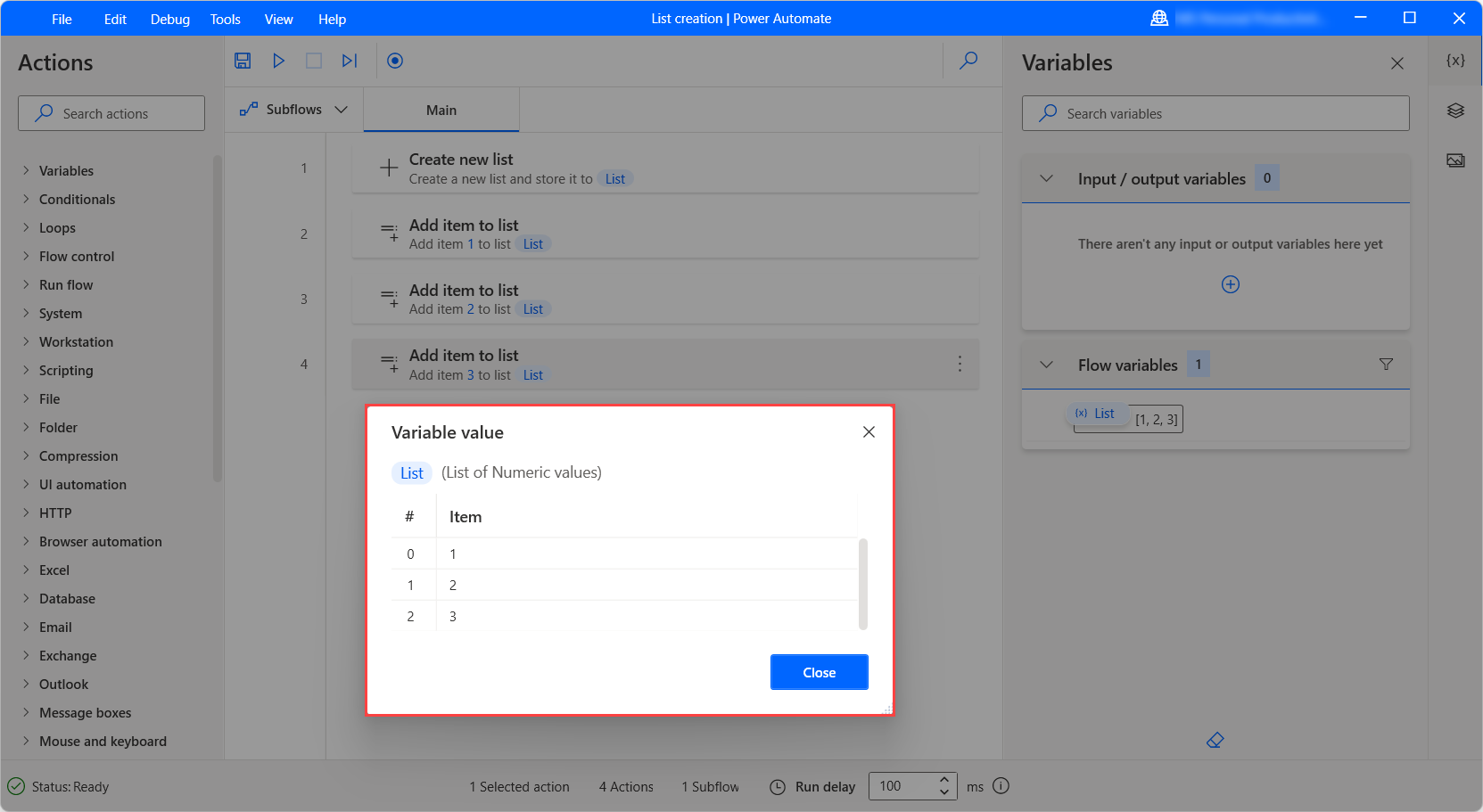
목록을 출력으로 생성하는 작업을 통해 목록을 만들 수도 있습니다. 예를 들어 파일에서 텍스트 읽기 작업은 텍스트 값 목록을 반환할 수 있고 폴더에서 파일 가져 오기 작업은 파일 목록을 반환합니다.
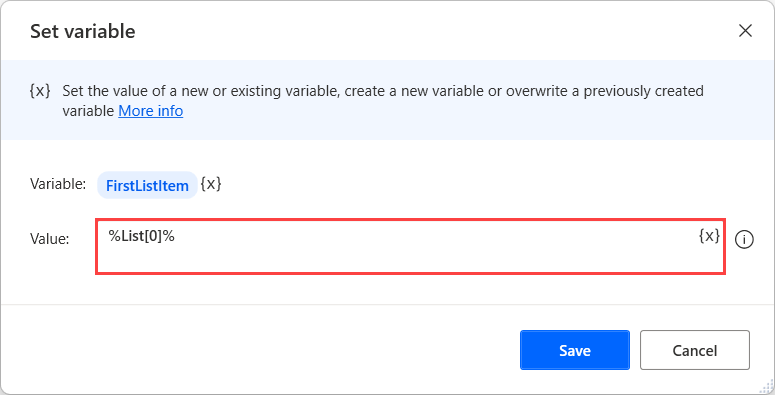
목록에서 특정 항목을 검색하려면 %VariableName[ItemNumber]% 표기법을 사용하세요
다음 예에서 흐름은 이전에 표시된 목록의 첫 번째 번호를 새 변수에 저장합니다. 목록의 첫 번째 항목에 대한 색인은 0이어야합니다.
일반적인 관행은 각각 작업을 사용하여 목록 항목을 반복하는 것입니다.
목록의 특정 부분에만 액세스해야 하는 경우 %VariableName[StartIndex:StopIndex]% 표기법을 사용합니다. 예를 들어, %List[2:4]% 표현식은 목록의 세 번째 및 네 번째 항목을 검색합니다. StopIndex 위치에 있는 항목은 슬라이싱의 경계이며 검색되지 않습니다.
목록을 처음부터 특정 항목으로 분할하려면 StartIndex 값, 예를 들어 %List[:4]%를 설정해서는 안 됩니다. 목록을 특정 색인에서 끝까지 분할하려면 StopIndex 값, 예를 들어 %List[2:]%를 설정해서는 안 됩니다.
데이터 테이블
데이터 테이블은 테이블 형식의 데이터를 포함하며 프로그래밍 용어로 2차원 배열과 동일합니다.
데이터 테이블에는 각 항목의 위치를 고유하게 설명하는 행과 열이 포함됩니다. 데이터 테이블은 데이터 행을 항목으로 포함하는 목록으로 간주할 수 있습니다.
Power Automate은 새 데이터 테이블 생성 작업을 제공하여 새 데이터 테이블을 생성합니다. 작업을 배포한 후 시각적 빌더를 사용하여 값을 채우고 열 머리글의 이름을 바꿀 수 있습니다.
새 데이터 테이블 만들기 작업 외에도 Excel 워크시트에서 읽기, SQL 문 실행 및 웹 페이지에서 데이터 추출 작업의 세 가지 작업이 추출된 데이터를 저장하기 위해 데이터 테이블을 생성합니다.
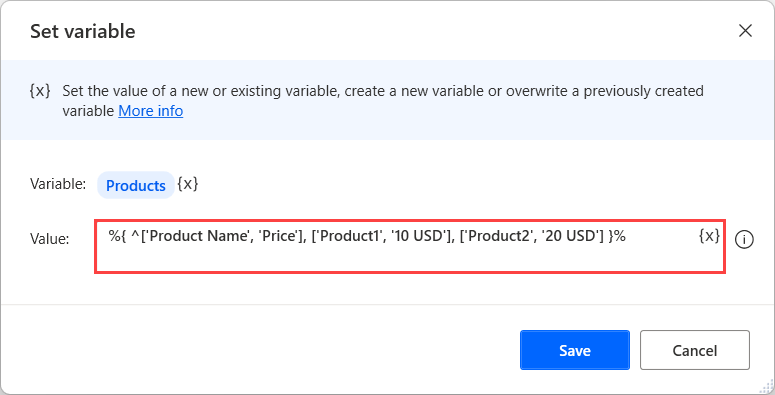
또한 변수 설정 작업과 프로그래밍 배열 표기법을 사용하여 데이터 테이블을 만들 수 있습니다. 이 표기법은 쉼표로 구분되고 중괄호로 묶인 여러 단일 차원 배열로 구성됩니다. 최종 식은 다음 형식이어야 합니다: %{['Product1', '10 USD'], ['Product2', '20 USD']}%.
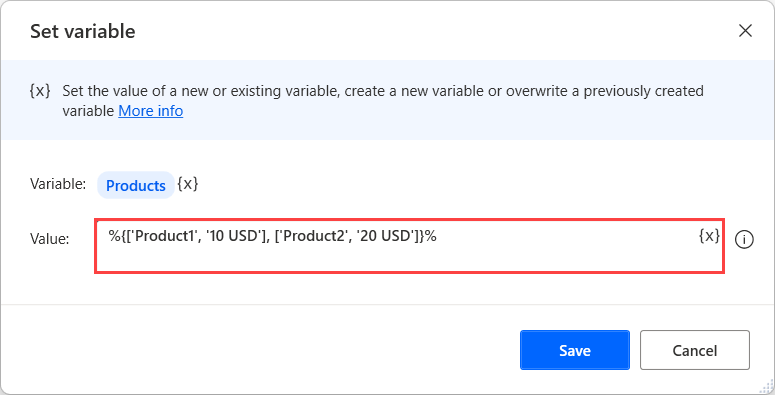
배열 표기법을 사용하여 새 데이터 테이블을 생성하는 동안 열 머리글을 추가하려면 첫 번째 행에 ^['ColumnName1', 'ColumnName2'] 식을 사용합니다.
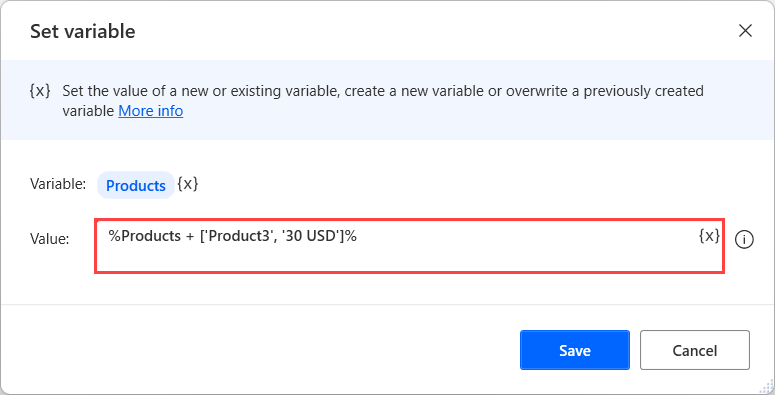
기존 테이블에 새 행을 추가하려면 데이터 테이블에 행 삽입 작업을 사용하세요. 또는 데이터 테이블의 변수 이름, 더하기 문자(+) 및 대괄호 안에 추가하려는 값을 포함하는 표현식을 만듭니다.
데이터 테이블에 행을 삽입하는 것 외에도 데스크톱 흐름은 데이터 테이블을 조작하는 다양한 작업을 제공합니다. 변수 작업 참조에서 이러한 작업이 포함된 전체 목록을 찾을 수 있습니다.
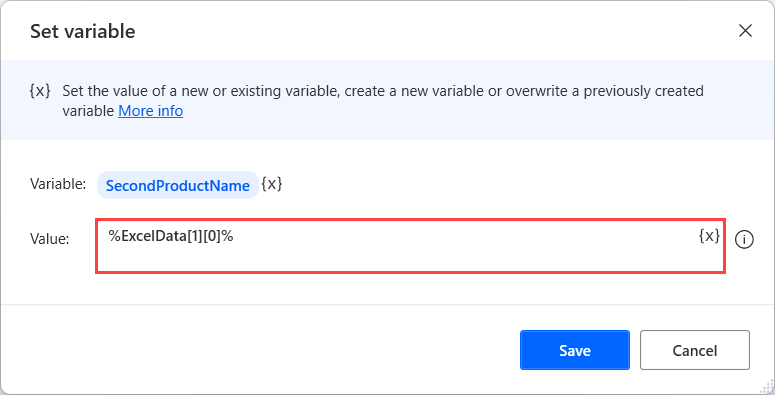
데이터 테이블에서 특정 항목을 검색하려면 %VariableName[RowNumber][ColumnNumber]% 표기법을 사용합니다. RowNumber 및 ColumnNumber는 첫 번째 항목(행 또는 열)에 대해 0이어야 합니다.
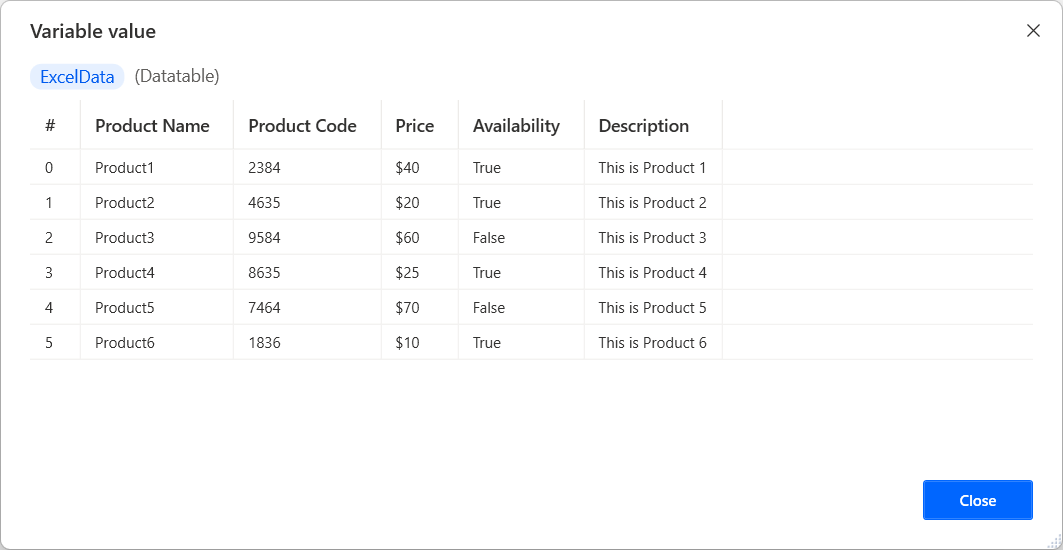
예를 들어 흐름이 Excel 워크시트의 콘텐츠를 검색하여 ExcelData 변수에 저장한다고 가정합니다. 검색된 테이블의 두 번째 행에 있는 첫 번째 셀에 액세스하려면 아래 표시된 식을 사용하십시오.
노트
ExcelData 변수에는 Excel 워크 시트에서 읽기 작업을 사용하여 Excel 워크시트에서 추출한 값의 테이블이 포함됩니다. 여기에는 전체 Excel 파일이 아닌 특정 워크시트의 일부 값이 포함됩니다.
열 헤더를 포함하는 데이터 테이블의 특정 열에 액세스하려면 %ExcelData[rowNumber]['ColumnName']% 표기법을 사용하세요.
For Each 작업으로 데이터 테이블을 반복하는 경우 현재 반복의 데이터를 포함할 변수는 데이터 행으로 간주됩니다.
목록과 유사하게 %VariableName[StartRow:StopRow]% 표기법을 사용하여 데이터 테이블의 특정 부분에 액세스합니다. 표현식은 두 색인에 의해 정의된 행만 검색하지만 StopRow 위치는 슬라이싱의 경계이며 검색되지 않습니다.
첫 번째 행에서 특정 행까지 데이터 테이블을 분할하려면 StartRow 값, 예를 들어 %Datatable[:4]%를 사용해서는 안 됩니다. 마찬가지로 특정 행에서 끝까지 데이터 테이블을 분할하려면 StopRow 값, 예를 들어 %Datatable[2:]%를 사용해서는 안 됩니다.
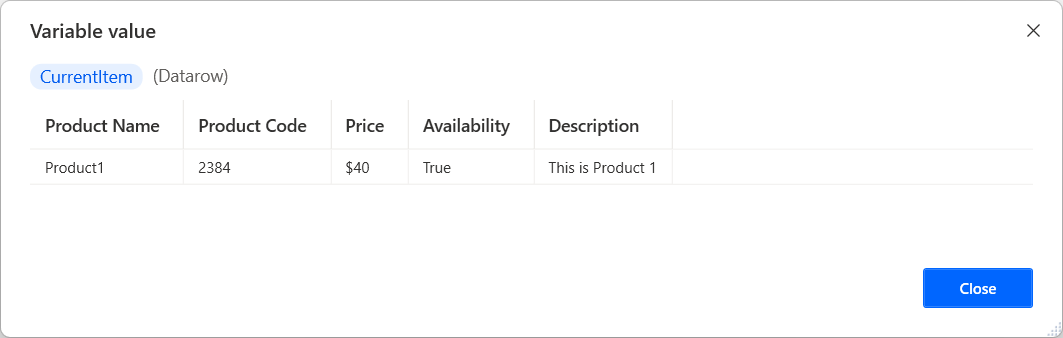
데이터 행
데이터 행에는 데이터 테이블의 단일 행 값이 포함됩니다. For Each 작업으로 데이터 테이블을 반복하는 경우 현재 반복의 데이터를 포함하는 변수는 데이터 행입니다.
데이터 행에서 특정 항목을 검색하려면 %VariableName[ItemNumber]% 표기법을 사용합니다.
또는 %VariableName['ColumnName']% 표기법을 사용할 수 있습니다. 각 열의 이름은 데이터 행을 검색한 데이터 테이블에 의해 정의됩니다.
Custom object
JSON 형식으로 쉽게 변환할 수 있는 속성 및 값 쌍을 포함합니다.
빈 사용자 지정 개체를 새로 만들려면 변수 설정 작업을 사용하고 %{{ }}% 식을 채우세요. 사용자 지정 개체를 만들고 속성 및 값으로 초기화하려면 %{ 'Property1': 'Value1', 'Property2': 'Value2', 'Property3': 'Value2' }% 구조의 식을 사용합니다.
중요
예약된 키워드는 사용자 지정 개체 속성으로 사용할 수 없습니다. 예약된 키워드의 전체 목록을 보려면 데스크톱 흐름의 예약된 키워드로 이동하세요.
기존 속성의 값을 업데이트하거나 새 속성을 추가하려면 변수 설정 작업을 배포하고 설정 필드에 속성 이름을 채우고 대상 필드 값을 입력합니다.
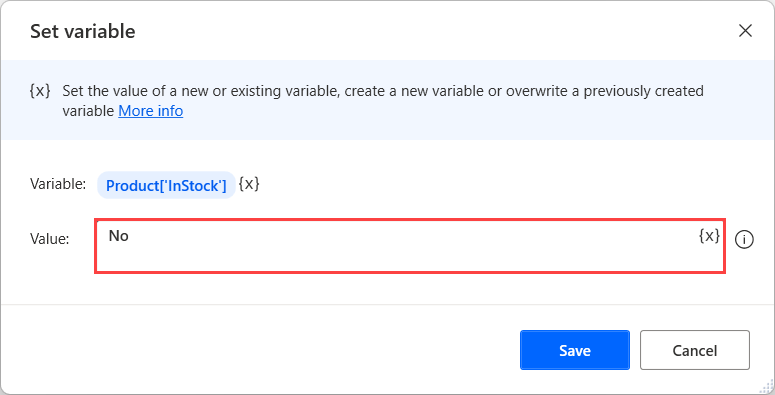
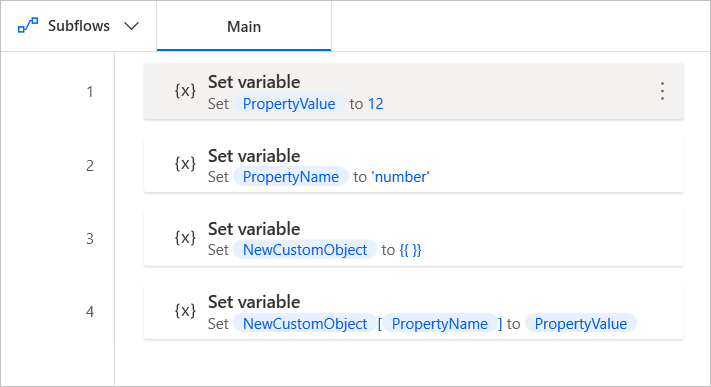
리터럴 값 외에도 변수를 사용하여 사용자 지정 개체의 속성과 값을 동적으로 설정할 수 있습니다. 예를 들어 다음 흐름은 두 개의 변수를 사용하여 비어 있는 새 사용자 지정 개체에 새 속성을 추가합니다.
커넥터 개체
커넥터 개체는 클라우드 커넥터의 정보를 저장하고 사용자 지정 개체와 유사하게 작동합니다. 해당 속성에는 일반적으로 다른 커넥터 개체 목록이 포함됩니다. 값에 액세스하는 것은 사용자 지정 개체에서처럼 작동하지만, 중첩된 값에 액세스하려면 더 복잡한 표현식이 필요할 수 있습니다.

PDF 테이블 정보 목록
이 데이터 형식의 변수는 PDF에서 테이블 추출 작업을 통해서만 생성할 수 있습니다.
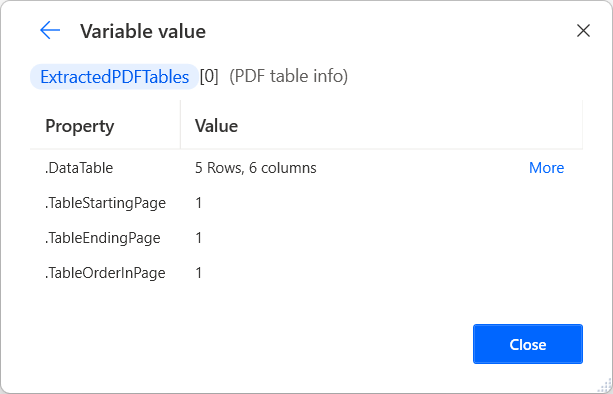
목록의 각 항목은 추출된 테이블을 설명하고 이에 대한 모든 필수 정보를 제공합니다. 특정 데이터 테이블 정보 항목에 액세스하려면 %VariableName[ItemNumber]% 표기법을 사용하세요.
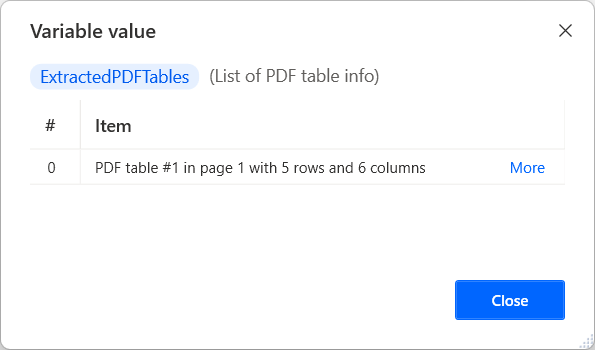
모든 목록 항목은 특정 세부 정보를 독립적으로 가져올 수 있는 네 가지 속성을 제공합니다. 사용 가능한 속성은 다음과 같습니다.
- DataTable – 추출된 테이블을 반환합니다.
- TableStartingPage – 테이블의 시작을 포함하는 파일 페이지의 인덱스를 반환합니다.
- TableEndingPage – 테이블의 끝을 포함하는 파일 페이지의 인덱스를 반환합니다.
- TableOrderInPage – 페이지에서 테이블의 순서를 반환합니다.
변수 데이터 형식 속성에서 이 데이터 유형의 속성에 대한 자세한 정보를 찾을 수 있습니다.
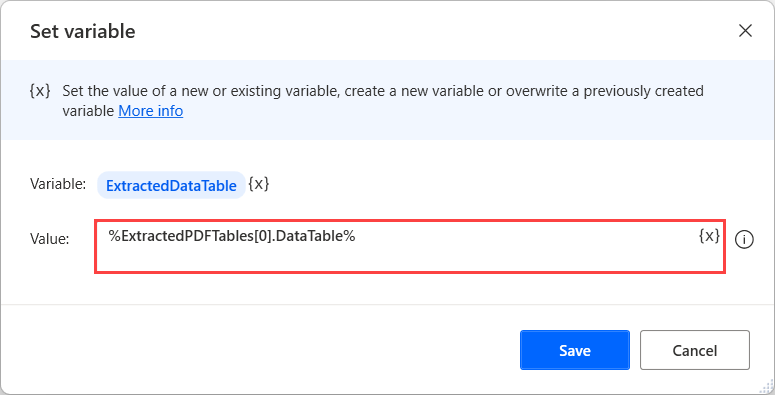
특정 속성의 값에 액세스하려면 %VariableName[ItemNumber].PropertyName% 표기법을 사용하세요. 예를 들어 다음 식은 ExtractedPDFTables 변수의 첫 번째 항목에 대한 데이터 테이블 값을 반환합니다.
알려진 문제 및 제한 사항
- 문제: 데이터 테이블 또는 데이터 행 셀에 여러 줄 엔터티가 포함된 경우 변수 뷰어는 항목의 첫 번째 줄만 표시합니다.
- 해결 방법: 없음.
인스턴스
웹 브라우저 인스턴스 – 새 Internet Explorer 시작 또는 기타 브라우저 시작 작업을 통해 만든 브라우저 인스턴스를 포함합니다.
창 인스턴스 – 창 가져 오기 작업을 통해 만든 창 인스턴스를 포함합니다.
Excel 인스턴스 – Excel 시작 작업을 통해 만든 Excel 인스턴스를 포함합니다.
Outlook 인스턴스 – Outlook 시작 작업을 통해 만든 Outlook 인스턴스를 포함합니다.
연결
SQL 연결 – SQL 연결 열기 작업을 통해 설정된 SQL 데이터베이스에 대한 연결을 포함합니다.
Exchange 연결 – Exchange server에 연결 작업을 통해 설정된 Exchange server에 대한 연결을 포함합니다.
FTP 연결 – FTP 연결 열기 및 보안 FTP 연결 열기 작업을 통해 만든 FTP 연결을 포함합니다.
기타
이 섹션에는 이전 범주에 속하지 않는 사용 가능한 모든 데이터 유형이 표시됩니다.
일반 값
- 일반 가치 – 이 데이터 형식은 Power Automate가 변수 또는 입력 매개 변수의 데이터 형식을 정의할 수 없는 디자인 타임에 사용됩니다. 일반 값은 해당 데이터를 기반으로 런타임 중에 다른 데이터 형식으로 변환됩니다.
Active Directory
- Active Directory 항목 – 서버에 연결 작업을 통해 설정된 Active Directory 서버에 대한 연결을 포함합니다.
- 그룹 정보 – 이름, 표시 이름, 설명 및 지정된 Active Directory 그룹의 구성원을 포함합니다.
- 그룹 멤버 – 지정된 Active Directory 그룹의 구성원을 나타냅니다.
- 사용자 정보 – 이름 및 성, 이니셜 및 고유 이름, 작업 세부 정보(회사, 부서 및 직위), 연락처 정보(전화 번호, 내선 번호 및 이메일) 및 위치(국가/지역, 도시, 주, 거리 주소 및 우편 번호)와 같은 지정된 Active Directory 사용자에 대한 정보를 포함합니다.
Amazon Web Services (AWS)
- EC2 클라이언트 – EC2 세션 만들기 작업을 통해 만든 EC2 세션을 포함합니다.
- EC2 인스턴스 – 검색된 EC2 인스턴스를 나타냅니다.
- EC2 인스턴스 정보 – EC2 인스턴스에 대한 정보를 포함합니다.
- 인스턴스 상태 변경 – 시작 또는 중지된 EC2 인스턴스에 대한 정보를 포함합니다.
- EBS 스냅숏 – EBS 스냅숏을 나타냅니다.
- EBS 볼륨 – EBS 볼륨을 나타냅니다.
Azure
- Azure 클라이언트 – 세션 만들기 작업을 통해 만든 Azure 세션을 포함합니다.
- Azure 리소스 그룹 – 검색된 Azure 리소스 그룹을 나타냅니다.
- Azure 관리 디스크 – 검색된 Azure 디스크를 나타냅니다.
- Azure 스냅숏 – Azure 스냅샷을 나타냅니다.
- Azure 가상 컴퓨터 – 검색된 Azure 가상 컴퓨터를 나타냅니다.
- Azure 가상 컴퓨터 정보 – Azure 가상 컴퓨터에 대한 정보를 포함합니다.
- Azure 구독 – 검색된 Azure 구독을 나타냅니다.
CMD
- CMD 세션 – CMD 세션 열기 작업을 통해 만든 CMD 세션을 포함합니다.
자격 증명
- 자격 증명 – 자격 증명 가져오기(프리뷰) 작업을 통해 검색된 자격 증명을 포함합니다.
날짜 및 시간
날짜/시간 – 날짜 및 시간 정보를 포함합니다. 변수 설정 작업을 통해 날짜/시간 변수를 만들려면 입력 매개 변수를 %d"yyyy-MM-dd HH:mm:ss.ff+zzz"%로 채웁니다.
표기법 설명 yyyy 연도 MM 월 dd 요일 HH 시간 mm 분 ss 초 ff 밀리초 zzz UTC 오프셋 예를 들어 %d"2022-03-25"%는 2022년 3월 25일 날짜를 대상 변수에 할당합니다.
- 메일 메시지 – 이메일 메시지를 나타냅니다. 이메일 검색 작업은 이러한 변수를 채웁니다.
Exchange
- Exchange 메일 메시지 – Exchange server에서 검색된 이메일 메시지를 나타냅니다. Exchange 이메일 메시지 검색 작업은 이러한 변수를 채웁니다.
파일 및 폴더
- 파일 – 파일을 나타냅니다.
- 폴더 – 폴더를 나타냅니다.
- FileSystemObject – 폴더 또는 파일을 나타냅니다. 이 데이터 형식은 폴더 및 파일을 허용하는 입력 매개 변수에 사용됩니다.
FTP
- FTP 파일 – FTP 파일을 나타냅니다.
- FTP 디렉터리 – FTP 디렉터리를 나타냅니다
OCR
- OCR 엔진 – OCR 엔진 만들기 작업을 통해 만든 OCR 엔진을 포함합니다.
Outlook
- Outlook 메일 메시지 – 이메일 Outlook 메시지를 나타냅니다. Outlook에서 이메일 메시지 검색 작업은 이러한 변수를 채웁니다.
터미널
- 터미널 세션 – 터미널 세션 열기 작업을 통해 만든 터미널 세션을 포함합니다.
XML
- XML 노드 – XML 문서의 내용을 포함합니다. 파일에서 XML 읽기 작업은 이러한 변수를 채웁니다.
Error
- 오류 – 데스크톱 흐름에서 마지막으로 발생한 오류에 대한 정보를 포함합니다. 마지막 오류 가져오기 작업은 이러한 유형의 변수를 생성합니다.