Power Automate의 프로세스 마이닝 기능을 효과적으로 사용하려면 먼저 다음을 이해해야 합니다.
다음은 프로세스 마이닝 기능과 함께 사용할 데이터를 업로드하는 방법에 대한 짧은 비디오입니다.
데이터 요구 사항
이벤트 로그 및 활동 로그는 이벤트 또는 활동이 발생하는 시점을 기록하는 레코드 시스템에 저장되는 테이블입니다. 예를 들어 CRM(고객 관계 관리) 앱에서 수행하는 활동은 CRM 앱에 이벤트 로그로 저장됩니다. 프로세스 마이닝이 이벤트 로그를 분석하려면 다음 필드가 필요합니다.
케이스 ID
케이스 ID는 프로세스의 인스턴스를 나타내야 하며 종종 프로세스가 작동하는 개체입니다. 입원 환자 체크인 프로세스의 경우 "환자 ID", 주문 제출 프로세스의 경우 "주문 ID" 또는 승인 프로세스의 경우 "요청 ID"일 수 있습니다. 이 ID는 로그의 모든 활동에 대해 있어야 합니다.
활동 이름
활동은 프로세스의 단계이며 활동 이름은 각 단계를 설명합니다. 일반적인 승인 프로세스에서는 "요청 제출", "요청 승인됨", "요청 거부됨", "요청 변경"과 같은 활동 이름을 사용할 수 있습니다.
시작 타임스탬프 및 종료 타임스탬프
타임스탬프는 이벤트 또는 활동이 발생한 정확한 시간을 나타냅니다. 이벤트 로그에는 타임스탬프가 하나만 있습니다. 시스템에서 이벤트 또는 활동이 발생한 시간을 나타냅니다. 활동 로그에는 시작 타임스탬프와 종료 타임스탬프의 두 가지 타임스탬프가 있습니다. 각 이벤트 또는 활동의 시작과 끝을 나타냅니다.
선택적 특성 유형을 수집하여 분석을 확장할 수도 있습니다.
리소스
특정 이벤트를 실행하는 인적 또는 기술 리소스입니다.
이벤트 수준 특성
이벤트별로 값이 다른 추가 분석 특성(예: 활동을 수행하는 부서)입니다.
케이스 수준 특성(첫 번째 이벤트)
케이스 레벨 특성은 분석 관점에서 케이스당 단일 값(예: USD로 표시된 송장 금액)을 갖는 것으로 간주되는 추가 특성입니다. 그러나 수집되는 이벤트 로그는 이벤트 로그의 모든 이벤트에 대해 특정 특성에 대해 동일한 값을 가짐으로써 반드시 일관성을 준수할 필요는 없습니다. 예를 들어 증분 데이터 새로 고침이 사용되는 경우에는 이를 보장하지 못할 수도 있습니다. Power Automate Process Mining은 데이터를 있는 그대로 수집하여 이벤트 로그에 제공된 모든 값을 저장하지만 소위 케이스 수준 특성 해석 메커니즘을 사용하여 케이스 수준의 특성을 처리합니다.
즉, 이벤트 수준 값(예: 이벤트 수준 필터링)이 필요한 특정 기능에 특성이 사용될 때마다 제품은 이벤트 수준 값을 사용합니다. 케이스 수준 값이 필요할 때마다(예: 케이스 수준 필터, 근본 원인 분석) 케이스의 시간순으로 첫 번째 이벤트에서 가져온 해석된 값을 사용합니다.
케이스 수준 특성(마지막 이벤트)
케이스 수준 특성(첫 번째 이벤트)과 동일하지만 케이스 수준에서 해석되는 경우 케이스의 시간순으로 마지막 이벤트에서 값을 가져옵니다.
이벤트별 재무
수행된 활동에 따라 변경되는 고정 비용/수익/숫자 값(예: 택배 서비스 비용)입니다. 재무적 값은 각 이벤트별 재무적 값의 합(평균, 최소, 최대)으로 계산됩니다.
케이스당 재무(첫 번째 이벤트)
케이스당 재무 특성은 분석 관점에서 서비스 케이스당 단일 값(예: USD의 송장 금액)을 갖는 것으로 간주되는 추가 숫자 특성입니다. 그러나 수집되는 이벤트 로그는 이벤트 로그의 모든 이벤트에 대해 특정 특성에 대해 동일한 값을 가짐으로써 반드시 일관성을 준수할 필요는 없습니다. 예를 들어 증분 데이터 새로 고침이 사용되는 경우에는 이를 보장하지 못할 수도 있습니다. Power Automate Process Mining은 데이터를 있는 그대로 수집하여 이벤트 로그에 제공된 모든 값을 저장합니다. 그러나 소위 케이스 수준 특성 해석 메커니즘을 사용하여 케이스 수준의 특성을 작업합니다.
즉, 이벤트 수준 값(예: 이벤트 수준 필터링)이 필요한 특정 기능에 특성이 사용될 때마다 제품은 이벤트 수준 값을 사용합니다. 케이스 수준 값이 필요할 때마다(예: 케이스 수준 필터, 근본 원인 분석) 케이스의 시간순으로 첫 번째 이벤트에서 가져온 해석된 값을 사용합니다.
케이스당 재무(마지막 이벤트)
케이스당 재무(첫 번째 이벤트)과 동일하지만 케이스 수준에서 해석되는 경우 케이스의 시간순으로 마지막 이벤트에서 값을 가져옵니다.
애플리케이션에서 로그 데이터를 가져올 위치
프로세스 마이닝 기능에는 프로세스 마이닝을 수행하기 위한 이벤트 로그 데이터가 필요합니다. 애플리케이션의 데이터베이스에 있는 많은 테이블에는 데이터의 현재 상태가 포함되어 있지만 필요한 이벤트 로그 형식인 발생한 이벤트에 대한 기록 레코드는 포함하지 않을 수 있습니다. 다행스럽게도 많은 대규모 애플리케이션에서 이 기록 레코드 또는 로그는 종종 특정 테이블에 저장됩니다. 예를 들어 많은 Dynamics 응용 프로그램은 이 레코드를 활동 테이블에 보관합니다. SAP 또는 Salesforce와 같은 다른 애플리케이션은 유사한 개념을 가지고 있지만 이름은 다를 수 있습니다.
기록 레코드를 기록하는 이러한 테이블에서 데이터 구조는 복잡할 수 있습니다. 특정 ID 또는 이름을 얻으려면 로그 테이블을 애플리케이션 데이터베이스의 다른 테이블과 조인해야 할 수 있습니다. 또한 관심 있는 모든 이벤트가 기록되는 것은 아닙니다. 유지하거나 필터링해야 하는 이벤트를 결정해야 할 수 있습니다. 도움이 필요하면 이 애플리케이션을 관리하는 IT 팀에 문의하여 자세히 알아보세요.
데이터 원본에 연결
데이터베이스에 직접 연결하면 데이터 원본의 최신 데이터로 프로세스 보고서를 최신 상태로 유지할 수 있다는 이점이 있습니다.
Power Query는 프로세스 마이닝 기능이 해당 데이터 원본에서 데이터를 연결하고 가져올 수 있는 방법을 제공하는 다양한 커넥터를 지원합니다. 일반적인 커넥터에는 Text/CSV, Microsoft Dataverse 및 SQL 서버 데이터베이스가 있습니다. SAP 또는 Salesforce와 같은 응용 프로그램을 사용하는 경우 커넥터를 통해 해당 데이터 원본에 직접 연결할 수 있습니다. 지원되는 커넥터 및 사용 방법에 대한 정보는 Power Query의 커넥터로 이동하세요.
Text/CSV 커넥터로 프로세스 마이닝 기능을 사용해 보세요
데이터 원본의 위치에 관계 없이 프로세스 마이닝 기능을 시험해 볼 수 있는 한 가지 쉬운 방법은 Text/CSV 커넥터를 사용하는 것입니다. 이벤트 로그의 작은 샘플을 CSV 파일로 내보내려면 데이터베이스 관리자와 협력해야 할 수 있습니다. CSV 파일이 있으면 데이터 원본 선택 화면에서 다음 단계를 사용하여 프로세스 마이닝 기능으로 가져올 수 있습니다.
노트
텍스트/CSV 커넥터를 사용하려면 비즈니스용 OneDrive가 있어야 합니다. 비즈니스용 OneDrive가 없으면 위해 다음 3단계에서와 같이 텍스트/CSV 대신 빈 테이블 사용을 고려하세요. 빈 테이블에서 많은 레코드를 가져올 수 없습니다.
프로세스 마이닝 홈페이지에서 여기에서 시작을 선택하여 프로세스를 생성합니다.
프로세스 이름을 입력하고 만들기를 선택합니다.
데이터 원본 선택 화면에서 모든 범주>텍스트/CSV를 선택합니다.
OneDrive 찾아보기를 선택합니다. 인증이 필요할 수 있습니다.
오른쪽 상단에서 업로드 아이콘을 선택한 다음 파일을 선택합니다.
이벤트 로그를 업로드하고 목록에서 파일을 선택한 다음 열기를 선택하여 해당 파일을 사용합니다.
데이터 흐름 커넥터 사용
데이터 흐름 커넥터는 Microsoft Power Platform에서 지원되지 않습니다. 기존 데이터 흐름은 Power Automate Process Mining의 데이터 원본으로 사용할 수 없습니다.
Dataverse 커넥터 사용
Dataverse 커넥터는 Microsoft Power Platform에서 지원되지 않습니다. 몇 단계를 더 거쳐야 하는 OData 커넥터를 사용하여 연결해야 합니다.
Dataverse 환경에 액세스 권한이 있는지 확인합니다.
연결하려는 Dataverse 환경의 환경 URL이 필요합니다. 일반적으로 다음과 같습니다.
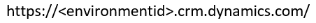
URL을 찾는 방법을 알아보려면 Dataverse 환경 URL 찾기로 이동하세요.
Power Query - 데이터 원본 선택 화면에서 OData를 선택하세요.
URL 텍스트 상자에 URL 끝에 api/data/v9.2를 입력하며 다음과 같이 표시됩니다.
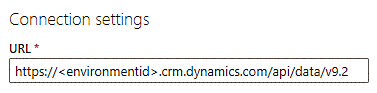
연결 자격 증명 아래 인증 종류 필드에서 조직 계정을 선택합니다.
로그인을 선택하고 자격 증명을 입력합니다.
다음을 선택합니다.
OData 폴더를 펼칩니다. 해당 환경의 Dataverse 테이블이 모두 표시됩니다. 예를 들어, 활동 테이블은 activitypointers라고 불립니다.
가져올 테이블 옆의 확인란을 선택하고 다음을 선택하세요.