통계학자, 데이터 과학자 및 데이터 분석가가 널리 사용하는 프로그래밍 언어인 Python을 Power BI Desktop 파워 쿼리 편집기에서 사용할 수 있습니다. Python을 파워 쿼리 편집기에 통합하면 Python을 사용하여 데이터 정리를 수행하고 누락된 데이터, 예측 및 클러스터링 완료를 포함하여 데이터 세트의 고급 데이터 셰이핑 및 분석을 수행할 수 있습니다. Python은 강력한 언어이며 파워 쿼리 편집기 에서 데이터 모델을 준비하고 보고서를 만드는 데 사용할 수 있습니다.
필수 조건
시작하기 전에 Python 및 pandas를 설치해야 합니다.
Python 설치 - Power BI Desktop의 파워 쿼리 편집기에서 Python을 사용하려면 로컬 컴퓨터에 Python을 설치해야 합니다. 공식 Python 다운로드 페이지 및 Anaconda를 포함하여 많은 위치에서 무료로 Python을 다운로드하고 설치할 수 있습니다.
pandas 설치 - 파워 쿼리 편집기에서 Python을 사용하려면 pandas도 설치해야 합니다. Pandas는 Power BI와 Python 환경 간에 데이터를 이동하는 데 사용됩니다.
파워 쿼리 편집기에서 Python 사용
파워 쿼리 편집기에서 Python을 사용하는 방법을 보여 주려면 여기에서 다운로드하여 팔로우할 수 있는 CSV 파일을 기반으로 주식 시장 데이터 세트에서 이 예제를 사용합니다. 이 예제의 단계는 다음과 같습니다.
먼저 Power BI Desktop에 데이터를 로드합니다. 이 예제에서는 EuStockMarkets_NA.csv 파일을 로드하고 Power BI Desktop의 > 리본에서 데이터텍스트/CSV 가져오기를 선택합니다.
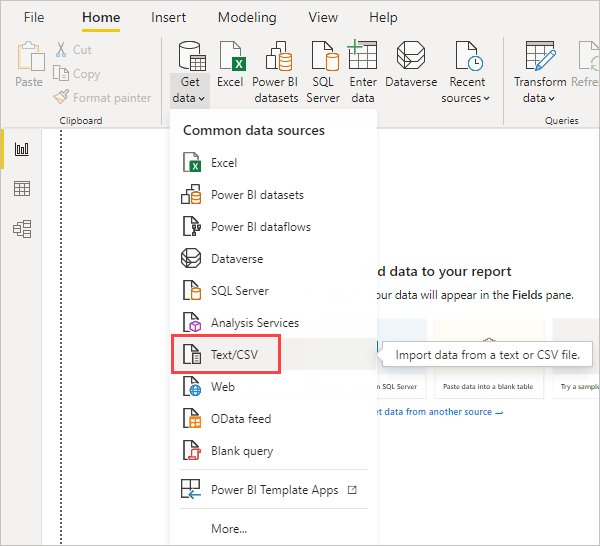
파일을 선택하고 열기를 선택하면 CSV 파일 대화 상자에 CSV 가 표시됩니다.
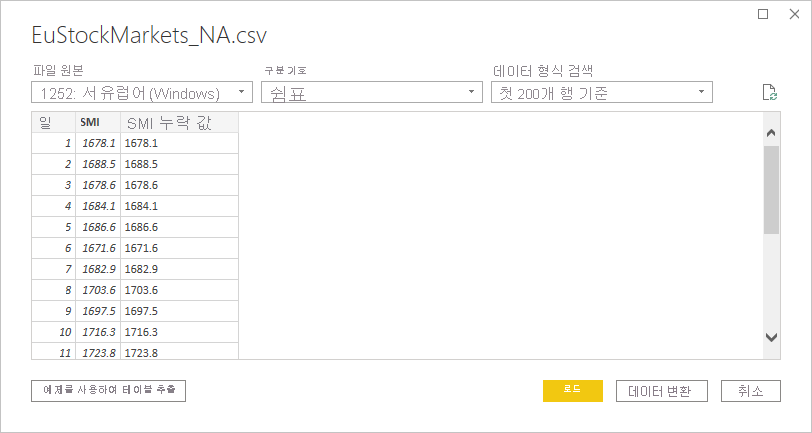
데이터가 로드되면 Power BI Desktop의 필드 창에 표시됩니다.
Power BI Desktop의 홈 탭에서 데이터 변환을 선택하여 파워 쿼리 편집기를 엽니다.
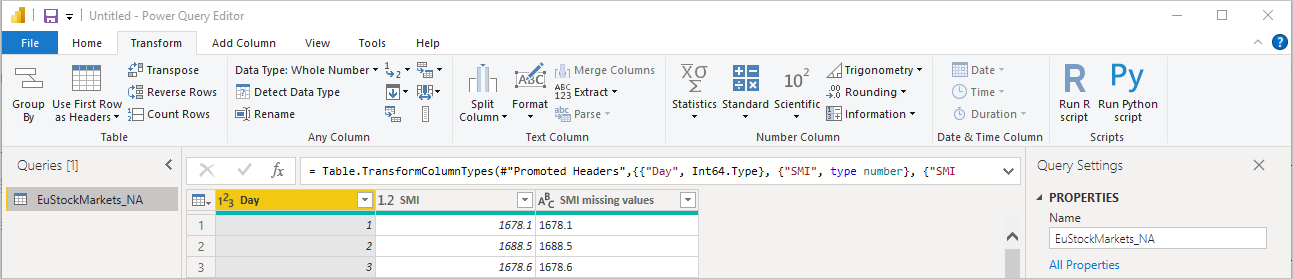
변환 탭에서 Python 스크립트 실행을 선택하면 다음 단계와 같이 Python 스크립트 실행 편집기가 나타납니다. 행 15 및 20은 다음 이미지에서 볼 수 없는 다른 행과 마찬가지로 누락된 데이터로 인해 어려움을 겪습니다. 다음 단계에서는 Python이 이러한 행을 완료하는 방법을 보여 줍니다.
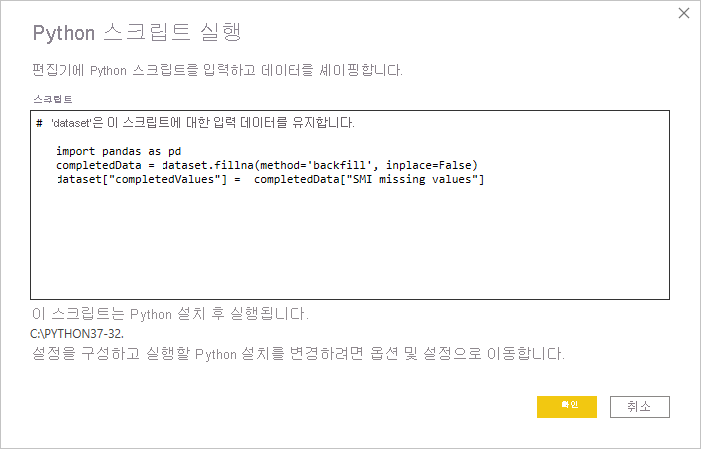
이 예제에서는 다음 스크립트 코드를 입력합니다.
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]비고
이전 스크립트 코드가 제대로 작동하려면 Python 환경에 pandas 라이브러리를 설치해야 합니다. pandas를 설치하려면 Python 설치에서 다음 명령을 실행합니다.
pip install pandasPython 스크립트 실행 대화 상자에 넣으면 코드는 다음 예제와 같습니다.
확인을 선택하면 파워 쿼리 편집기에서 데이터 개인 정보 보호에 대한 경고가 표시됩니다.
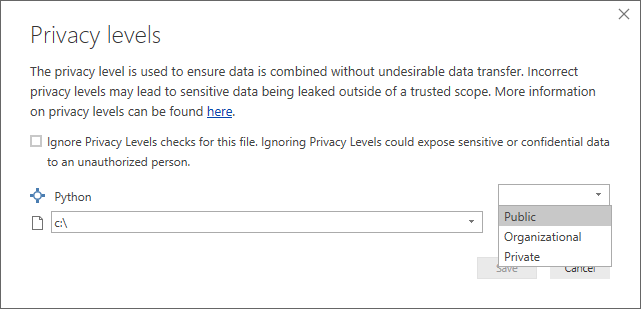
Python 스크립트가 Power BI 서비스에서 제대로 작동하려면 모든 데이터 원본을 공용으로 설정해야 합니다. 개인 정보 설정 및 해당 의미에 대한 자세한 내용은 개인 정보 수준을 참조하세요.
필드 창에서 completedValues라는 새 열을 확인합니다. 행 15 및 18과 같은 몇 가지 누락된 데이터 요소가 있습니다. 다음 섹션에서 Python이 이를 처리하는 방법을 살펴봅니다.
Python 스크립트의 세 줄만 사용하여 파워 쿼리 편집기 에서 누락된 값을 예측 모델로 채웠습니다.
Python 스크립트 데이터에서 시각적 개체 만들기
이제 pandas 라이브러리를 사용하는 Python 스크립트 코드가 누락된 값을 채운 방법을 다음 이미지와 같이 시각적 자료로 확인할 수 있습니다.
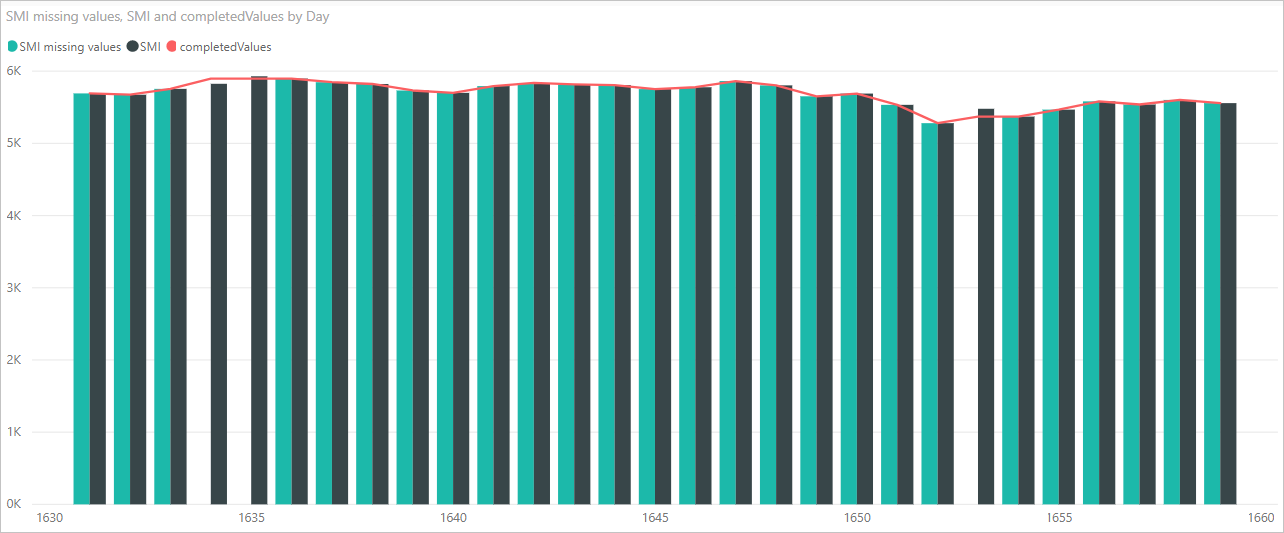
시각적 개체가 완료되고 Power BI Desktop을 사용하여 만들려는 다른 시각적 개체가 있으면 Power BI Desktop 파일을 저장할 수 있습니다. Power BI Desktop 파일은 .pbix 파일 이름 확장명을 사용하여 저장합니다. 그런 다음, Power BI 서비스에서 데이터 모델에 포함된 Python 스크립트를 포함하여 데이터 모델을 사용합니다.
비고
이러한 단계가 완료된 완료된 .pbix 파일을 보고 싶으신가요? 당신은 행운에있어. 이 예제에 사용된 완성된 Power BI Desktop 파일을 바로 여기에서 다운로드할 수 있습니다.
.pbix 파일을 Power BI 서비스에 업로드하면 서비스에서 데이터를 새로 고치고 서비스에서 시각적 개체를 업데이트할 수 있도록 하기 위해 몇 가지 단계가 더 필요합니다. 데이터를 업데이트된 시각화에 엑세스하려면 Python에 액세스 권한이 필요합니다. 다른 단계는 다음과 같습니다.
- 데이터 세트에 대해 예약된 새로 고침을 사용하도록 설정합니다. Python 스크립트를 사용하여 데이터 세트를 포함하는 통합 문서에 예약된 새로 고침을 사용하도록 설정하려면 개인 게이트웨이에 대한 정보도 포함하는 예약된 새로 고침 구성을 참조하세요.
- 개인 게이트웨이를 설치합니다. 파일이 있는 컴퓨터와 Python이 설치된 컴퓨터에 개인 게이트웨이 가 설치되어 있어야 합니다. Power BI 서비스는 해당 통합 문서에 액세스하고 업데이트된 시각적 개체를 다시 렌더링해야 합니다. 자세한 내용은 Personal Gateway 설치 및 구성을 참조하세요.
고려사항 및 제한사항
파워 쿼리 편집기에서 만든 Python 스크립트를 포함하는 쿼리에는 몇 가지 제한 사항이 있습니다.
모든 Python 데이터 원본 설정을 공용으로 설정해야 하며 파워 쿼리 편집기 에서 만든 쿼리의 다른 모든 단계도 public이어야 합니다. 데이터 원본 설정에 연결하려면 Power BI Desktop 에서 파일 > 옵션 및 설정 > 데이터 원본 설정을 선택합니다.
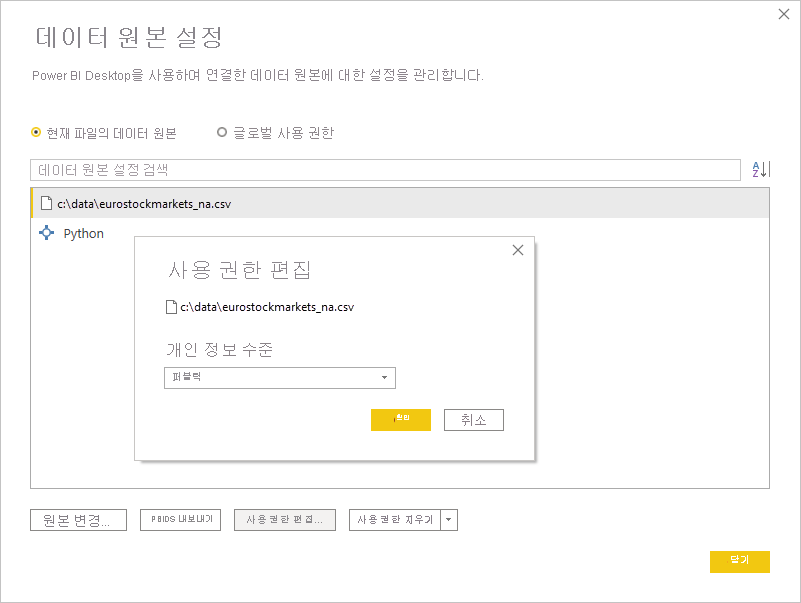
데이터 원본 설정 대화 상자에서 데이터 원본을 선택한 다음, 사용 권한 편집을 선택하고 개인 정보 수준이공용으로 설정되어 있는지 확인합니다.
Python 시각적 개체 또는 데이터 세트의 예약된 새로 고침을 사용하도록 설정하려면 예약된 새로 고침 을 사용하도록 설정하고 통합 문서 및 Python 설치가 있는 컴퓨터에 개인 게이트웨이를 설치해야 합니다. 둘 다에 대한 자세한 내용은 이 문서의 이전 섹션을 참조하세요. 이 섹션에서는 각각에 대해 자세히 알아볼 수 있는 링크를 제공합니다.
여러 테이블로 구성된 중첩 테이블은 현재 지원되지 않습니다.
Python 및 사용자 지정 쿼리를 사용하여 수행할 수 있는 모든 종류의 작업을 수행할 수 있으므로 원하는 방식으로 데이터를 탐색하고 셰이프합니다.