자동 집계 구성
자동 집계 구성에는 지원되는 DirectQuery 의미 체계 모델에 대한 학습 활성화 및 하나 이상의 예약된 새로 고침 구성이 포함됩니다. 학습 및 새로 고침 작업의 반복이 여러 차례 실행되면 의미 체계 모델 설정으로 돌아가서 메모리 내 집계 캐시를 사용하는 보고서 쿼리의 비율을 미세 조정할 수 있습니다. 이러한 단계를 수행하기 전에 자동 집계에서 설명하는 기능과 제한 사항을 숙지하세요.
Enable
자동 집계를 사용하도록 설정하려면 의미 체계 모델 소유자 권한이 있어야 합니다. 작업 영역 관리자는 모델 소유자 권한을 인계 받을 수 있습니다.
의미 체계 모델 설정에서 예약된 새로 고침 및 성능 최적화를 확장합니다.
자동 집계 학습을 켬으로 전환합니다. 스위치가 회색으로 표시되는 경우 데이터 원본 자격 증명이 구성 및 로그인되어 있는지 확인하세요.

새로 고침 일정에서 새로 고침 빈도와 표준 시간대를 지정합니다. 새로 고침 일정 컨트롤이 비활성화된 경우 게이트웨이 연결(필요한 경우) 및 데이터 원본 자격 증명을 포함하는 데이터 소스 구성을 확인하세요.
다른 시간 추가를 선택하고 하나 이상의 새로 고침을 지정합니다.
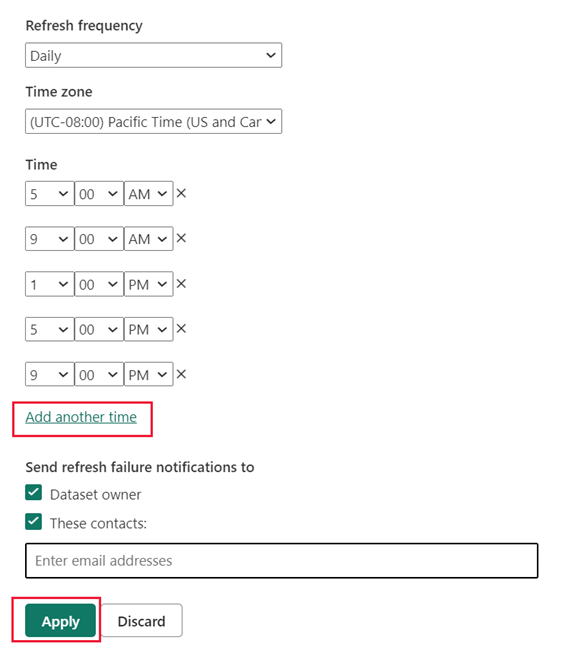
새로 고침은 하나 이상 예약해야 합니다. 선택한 빈도의 첫 번째 새로 고침은 학습 작업과 새로 고침(메모리 내 캐시에 새로운 집계와 업데이트된 집계를 로드하는 작업)을 포함합니다. 집계 캐시에 로드되는 보고서 쿼리가 백 엔드 데이터 원본과 가장 동기화된 결과를 얻을 수 있도록 더 많은 새로 고침을 예약합니다. 자세한 내용은 새로 고침 작업을 참조하세요.
적용을 선택합니다.
주문형 학습 및 새로 고침
선택한 빈도에 대한 첫 번째 예약된 새로 고침 작업에는 학습 작업이 포함됩니다. 해당 학습 작업이 60분 시간 제한 내에 완료되지 않으면 후속 새로 고침 작업은 캐시의 집계를 로드하거나 업데이트하지 않습니다. 다음 학습 작업은 선택한 빈도의 첫 번째 새로 고침 작업까지 실행되지 않습니다.
이러한 경우 하나 이상의 주문형 학습 및 새로 고침 작업을 수동으로 실행하여 학습을 완전히 완료하고 캐시에서 집계를 로드하거나 새로 고칠 수 있습니다. 예를 들어 새로 고침 기록을 확인할 때 날짜(빈도)에 대한 첫 번째 예약된 학습 및 새로 고침 작업이 시간 제한 내에서 완료되지 않고 학습 작업이 실행되는 다음 날의 예약된 새로 고침을 기다리지 않으려는 경우 하나 이상의 주문형 학습 및 새로 고침 작업을 실행하여 데이터 쿼리 로그(학습)를 완전히 처리하고 집계를 캐시에 로드(새로 고침)할 수 있습니다.
주문형 학습 및 새로 고침 작업을 실행하려면 지금 학습 및 새로 고침을 선택합니다. 주문형 학습 작업이 성공적으로 완료되도록 새로 고침 기록을 주시해야 합니다. 그렇지 않은 경우 학습이 성공적으로 완료되고 집계가 캐시에 로드되거나 새로 고칠 때까지 다른 학습 및 새로 고침 작업을 실행합니다.
지금 학습 및 새로 고침을 실행하면 메모리 내 캐시에서 집계를 사용할 보고서 쿼리의 백분율을 미세 조정할 때 유용할 수 있습니다. 주문형 학습을 실행하고 지금 새로 고침 작업을 실행하면 새 백분율 설정을 통해 시간 제한 내에서 학습 작업을 완료할 수 있는지 보다 신속하게 확인할 수 있습니다.
예약된 작업이든 주문형이든 관계없이 학습 및 새로 고침 작업은 데이터 원본과 Power BI 모두에 대해 프로세스 및 리소스 집약적입니다. 리소스에 영향을 거의 미치지 않는 시간을 선택합니다.
미세 조정
사용자 정의 집계 테이블과 시스템 생성 집계 테이블은 모두 의미 체계 모델의 일부이고, 모델의 크기에 영향을 주며, 기존 Power BI 모델 크기 제약 조건이 적용됩니다. 집계 처리는 또한 리소스를 소비하고 모델 새로 고침 기간에 영향을 줍니다. 최적의 구성은 메모리 내 집계 캐시에서 가장 자주 사용되는 보고서 쿼리에 대한 미리 집계된 결과를 제공하는 것과 빠른 학습 및 새로 고침 시간과 시스템 리소스 부담 감소를 위해 이상값 및 임시 쿼리에 대한 느린 결과를 허용하는 것 사이의 적절한 균형을 이룹니다.
백분율 조정
메모리 내 캐시의 집계를 사용할 보고서 쿼리의 백분율을 정하는 집계 캐시 설정은 기본적으로 75%입니다. 백분율을 늘리면 더 많은 수의 보고서 쿼리가 더 높은 순위로 지정되어 해당 쿼리의 집계가 메모리 내 집계 캐시에 포함되게 됩니다. 백분율을 높게 설정하면 메모리 내 캐시에서 더 많은 쿼리가 답변되지만 학습 및 새로 고침 시간이 길어집니다. 반면에 백분율을 낮게 설정하면 학습 및 새로 고침 시간이 짧아지고 리소스 사용률이 줄어들지만 보고서 쿼리가 데이터 원본까지 왕복해야 하므로 메모리 내 집계 캐시에 의해 답변되는 보고서 쿼리의 개수가 줄어들어서 보고서 시각화 성능이 저하될 수 있습니다.
시스템이 캐시에 포함할 최적의 집계를 정하려면 먼저 가장 자주 사용되는 보고서 쿼리 패턴을 알아야 합니다. 학습/새로 고침 작업의 반복이 여러 차례 완료된 후에 집계 캐시를 사용할 쿼리의 백분율을 조정하세요. 이렇게 하면 학습 알고리즘이 긴 기간 동안 보고서 쿼리를 분석하여 그에 맞게 자체 조정할 수 있는 시간을 갖게 됩니다. 예를 들어, 새로 고침이 하루 한 번 실행되도록 예약했다면 일주일을 기다리는 것이 좋습니다. 요일별로 사용자 보고 패턴이 다르게 나타날 수 있기 때문입니다.
백분율을 조정하려면
의미 체계 모델 설정에서 예약된 새로 고침 및 성능 최적화를 확장합니다.
쿼리 적용 범위에서 집계된 캐시를 사용할 쿼리의 백분율 조정 슬라이더를 사용하여 백분율을 원하는 값으로 늘리거나 줄입니다. 백분율을 조정하면 쿼리 성능 영향 리프트 차트에 추정된 쿼리 응답 시간이 표시됩니다.
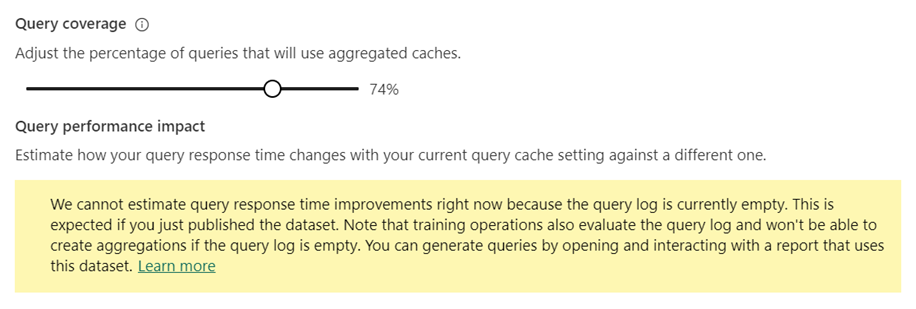
지금 학습 및 새로 고침 또는 적용을 선택합니다.
쿼리 성능 영향 추정
쿼리 성능 영향 리프트 차트는 캐싱된 집계를 사용할 쿼리의 백분율에 대한 함수로서 추정된 보고서 쿼리 실행 시간을 제공합니다. 차트는 하나 이상의 학습/새로 고침 작업이 수행되기 전까지 모든 메트릭에 관해 0.0을 표시합니다. 첫 번째 학습/새로 고침 작업이 완료된 후에는 차트를 보고 메모리 내 집계 캐시를 사용하는 쿼리의 백분율을 조정하는 것이 쿼리 응답을 개선하는 데 도움이 될지를 확인할 수 있습니다.
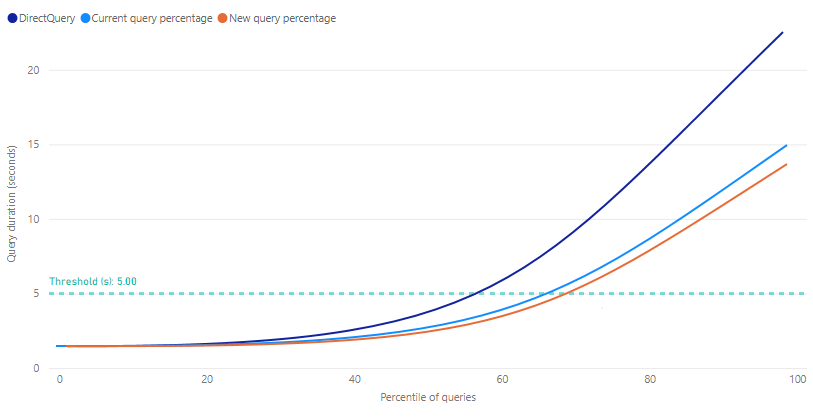
리프트 차트에 마커 선으로 표시되는 임계값은 보고서의 목표 쿼리 응답 시간을 나타냅니다. 집계 캐시를 사용할 쿼리의 백분율을 미세 조정하여 원하는 임계값을 충족하는 새 쿼리 백분율을 정할 수 있습니다.
메트릭
DirectQuery - DirectQuery를 사용하여 데이터 원본으로 전송되고 데이터 원본에서 반환되는 보고서 쿼리의 추정된 기간(초)입니다. 메모리 내 집계 캐시에 의해 답변될 수 없는 쿼리는 보통 이 추정값에 포함됩니다.
현재 쿼리 백분율 - 가장 최근 학습/새로 고침 작업의 백분율 설정을 기반으로 메모리 내 집계 캐시에서 답변된 보고서 쿼리의 추정된 기간(초)입니다.
새 쿼리 백분율 - 새로 선택한 백분율에 관해 메모리 내 집계 캐시에서 답변된 보고서 쿼리의 추정된 기간(초)입니다. 백분율 슬라이더를 변경하면 이 메트릭이 잠재적인 변경 사항을 반영합니다.
사용 안 함
자동 집계를 사용하지 않도록 설정하려면 모델 소유자 권한이 있어야 합니다. 작업 영역 관리자는 모델 소유자 권한을 인계 받을 수 있습니다.
사용하지 않도록 설정하려면 자동 집계 학습을 끔으로 전환합니다.
학습을 사용하지 않도록 설정하면 자동 집계 테이블을 삭제하는 옵션이 표시됩니다.
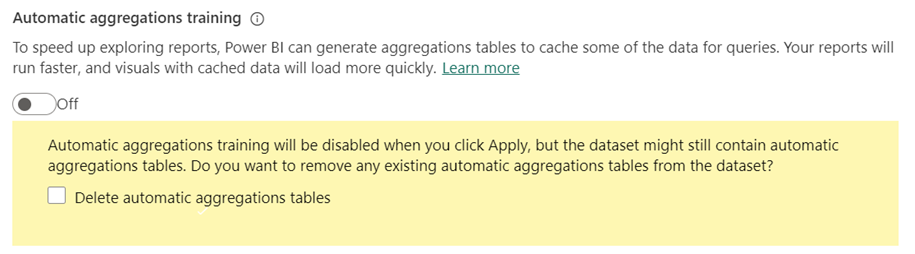
기존 자동 집계 테이블을 삭제하지 않도록 선택하면 테이블이 모델에 유지되고 계속 새로 고쳐집니다. 그러나 학습이 사용하지 않도록 설정되었으므로 새 집계가 추가되지 않습니다. Power BI는 가능한 경우 기존 테이블을 계속 사용하여 집계된 쿼리 결과를 가져옵니다.
테이블을 삭제하도록 선택하면 모델이 자동 집계 없이 원래 상태로 되돌아갑니다.
적용을 선택합니다.