개발 중인 데이터 흐름이 점점 더 커지고 복잡해지는 경우 원래 디자인을 개선하기 위해 수행할 수 있는 몇 가지 작업은 다음과 같습니다.
여러 데이터 흐름으로 나누기
하나의 데이터 흐름에서 모든 작업을 수행하지 마세요. 복잡한 단일 데이터 흐름으로 인해 데이터 변환 프로세스가 더 길어질 뿐만 아니라 데이터 흐름을 이해하고 다시 사용하는 것이 더 어려워집니다. 여러 데이터 흐름의 테이블을 구분하거나 하나의 테이블을 여러 데이터 흐름으로 구분하여 데이터 흐름을 여러 데이터 흐름으로 분할할 수 있습니다. 계산 테이블 또는 연결된 테이블의 개념을 사용하여 변환의 일부를 한 데이터 흐름에서 빌드하고 다른 데이터 흐름에서 다시 사용할 수 있습니다.
준비/추출 데이터 흐름에서 데이터 변환 흐름을 분할합니다.
데이터 추출(즉, 준비 데이터 흐름)을 위한 데이터 흐름과 데이터 변환을 위한 데이터 흐름이 있으면 다중 계층 아키텍처를 만드는 데 도움이 될 뿐만 아니라 데이터 흐름의 복잡성을 줄이는 데도 도움이 됩니다. 데이터 가져오기, 탐색 및 데이터 형식 변경과 같은 일부 단계에서는 데이터 원본에서 데이터를 추출하기만 하면 됩니다. 스테이징 데이터 흐름 및 변환 데이터 흐름을 구분하여 데이터 흐름을 더 간단하게 개발할 수 있습니다.
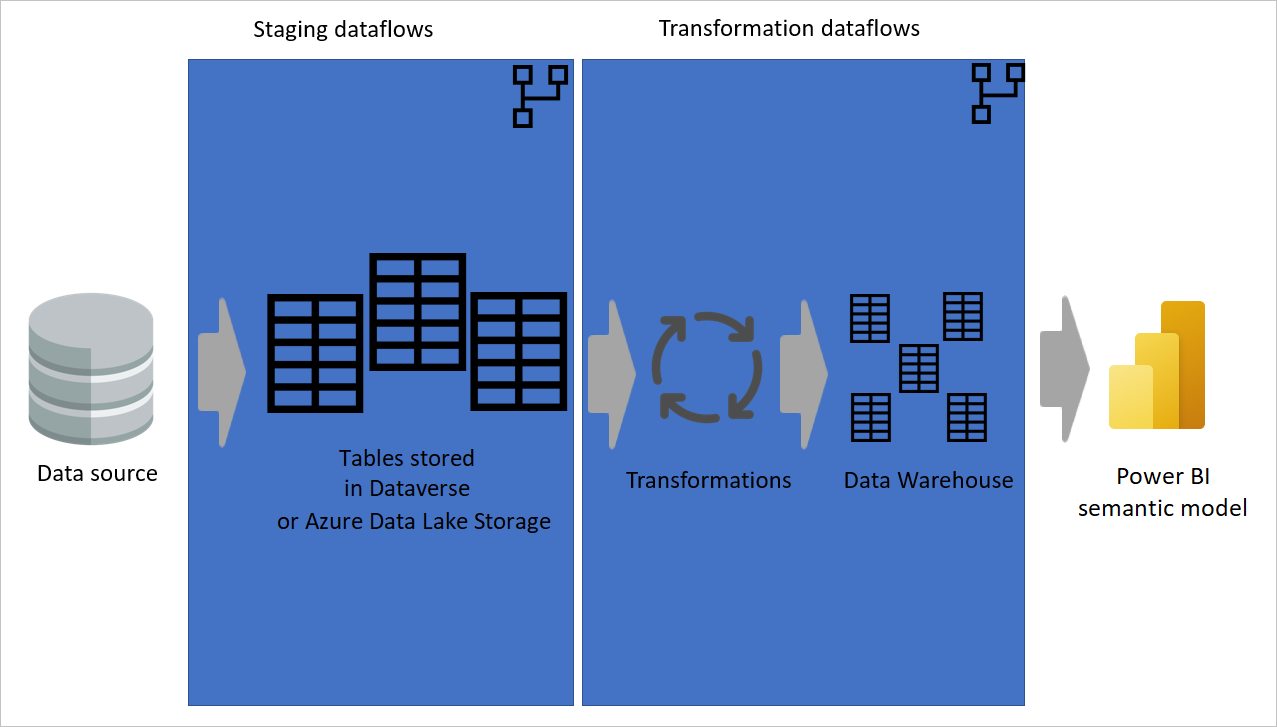
테이블이 Dataverse 또는 Azure Data Lake Storage에 저장되는 데이터 원본에서 준비 데이터 흐름으로 추출되는 데이터를 보여 주는 이미지입니다. 그런 다음 데이터가 변환 흐름으로 이동하여 데이터 웨어하우스 구조로 변환됩니다. 그런 다음, 데이터가 의미 체계 모델로 이동됩니다.
사용자 지정 함수 사용
사용자 지정 함수는 여러 소스의 여러 쿼리에 대해 특정 수의 단계를 수행해야 하는 시나리오에서 유용합니다. 사용자 지정 함수는 파워 쿼리 편집기에서 그래픽 인터페이스를 통해 또는 M 스크립트를 사용하여 개발할 수 있습니다. 함수는 필요에 따라 많은 테이블의 데이터 흐름에서 다시 사용할 수 있습니다.
사용자 지정 함수를 사용하면 소스 코드의 단일 버전만 있으면 도움이 되므로 코드를 복제할 필요가 없습니다. 따라서 파워 쿼리 변환 논리와 전체 데이터 흐름을 유지하는 것이 훨씬 쉽습니다. 자세한 내용은 다음 블로그 게시물로 이동하세요. Power BI Desktop에서 간편하게 만든 사용자 지정 함수입니다.
비고
경우에 따라 사용자 지정 함수를 사용하여 데이터 흐름을 새로 고치는 데 프리미엄 용량이 필요하다는 알림을 받을 수 있습니다. 이 메시지를 무시하고 데이터 흐름 편집기를 다시 열 수 있습니다. 함수가 "부하 사용" 쿼리를 참조하지 않는 한 일반적으로 문제를 해결합니다.
폴더에 쿼리 배치
쿼리에 폴더를 사용하면 관련 쿼리를 함께 그룹화할 수 있습니다. 데이터 흐름을 개발할 때는 의미 있는 폴더에서 쿼리를 정렬하는 데 좀 더 많은 시간을 할애합니다. 이 방법을 사용하면 나중에 쿼리를 더 쉽게 찾을 수 있으며 코드 유지 관리가 훨씬 쉽습니다.
계산 테이블 사용
계산 테이블은 데이터 흐름을 더 쉽게 이해할 수 있을 뿐만 아니라 더 나은 성능을 제공합니다. 계산 테이블을 사용하는 경우 해당 테이블에서 참조된 다른 테이블은 "이미 처리 및 저장" 테이블에서 데이터를 가져옵니다. 변환은 훨씬 더 간단하고 빠릅니다.
향상된 컴퓨팅 엔진 활용
Power BI 관리 포털에서 개발된 데이터 흐름의 경우 다른 유형의 변환을 수행하기 전에 먼저 계산 테이블에서 조인 및 필터 변환을 수행하여 향상된 컴퓨팅 엔진을 사용해야 합니다.
여러 단계를 여러 쿼리로 나누기
한 테이블에서 많은 수의 단계를 추적하기는 어렵습니다. 대신 많은 단계를 여러 테이블로 분할해야 합니다. 다른 쿼리에 대해 로드를 사용하도록 설정하고 중간 쿼리인 경우 사용하지 않도록 설정하고 데이터 흐름을 통해 최종 테이블만 로드할 수 있습니다. 각각에 단계가 더 작은 여러 쿼리가 있는 경우 한 쿼리에서 수백 개의 단계를 파헤치기보다는 종속성 다이어그램을 사용하고 추가 조사를 위해 각 쿼리를 추적하는 것이 더 쉽습니다.
쿼리 및 단계에 대한 속성 추가
설명서는 유지 관리하기 쉬운 코드를 보유하는 데 핵심적인 기능입니다. 파워 쿼리에서 테이블 및 단계에 속성을 추가할 수 있습니다. 속성에 추가하는 텍스트는 해당 쿼리 또는 단계를 마우스로 가리키면 도구 설명으로 표시됩니다. 이 설명서는 나중에 모델을 유지 관리하는 데 도움이 됩니다. 테이블 또는 단계를 한눈에 살펴보면 해당 단계에서 수행한 작업을 재고하고 기억하기보다는 그곳에서 무슨 일이 일어나고 있는지 이해할 수 있습니다.
용량이 동일한 지역에 있는지 확인
데이터 흐름은 현재 여러 국가 또는 지역을 지원하지 않습니다. 프리미엄 용량은 Power BI 테넌트와 동일한 지역에 있어야 합니다.
클라우드 원본과 온-프레미스 원본 분리
온-프레미스, 클라우드, SQL Server, Spark 및 Dynamics 365와 같은 각 원본 유형에 대해 별도의 데이터 흐름을 만드는 것이 좋습니다. 데이터 흐름을 원본 유형으로 구분하면 빠른 문제 해결이 가능하며 데이터 흐름을 새로 고칠 때 내부 제한을 방지할 수 있습니다.
테이블에 필요한 예약된 새로 고침에 따라 별도의 데이터 흐름
1시간마다 원본 시스템에서 업데이트되는 판매 트랜잭션 테이블이 있고 매주 업데이트되는 제품 매핑 테이블이 있는 경우 이 두 테이블을 서로 다른 데이터 새로 고침 일정으로 두 개의 데이터 흐름으로 분할합니다.
동일한 작업 영역에서 연결된 테이블에 대한 새로 고침 예약을 방지합니다.
연결된 테이블을 포함하는 데이터 흐름에서 정기적으로 잠겨 있는 경우 데이터 흐름 새로 고침 중에 잠긴 동일한 작업 영역의 해당 종속 데이터 흐름으로 인해 발생할 수 있습니다. 이러한 잠금은 트랜잭션 정확도를 제공하고 두 데이터 흐름이 모두 성공적으로 새로 고쳐지도록 하지만 편집을 차단할 수 있습니다.
연결된 데이터 흐름에 대해 별도의 일정을 설정하는 경우 데이터 흐름을 불필요하게 새로 고치고 데이터 흐름 편집을 차단할 수 있습니다. 이 문제를 방지하기 위한 두 가지 권장 사항이 있습니다.
- 원본 데이터 흐름과 동일한 작업 영역에서 연결된 데이터 흐름에 대한 새로 고침 일정을 설정하지 마세요.
- 새로 고침 일정을 별도로 구성하고 잠금 동작을 방지하려면 데이터 흐름을 별도의 작업 영역으로 이동합니다.