데이터 흐름 구현의 모범 사례 중 하나는 데이터 흐름의 책임을 데이터 수집 및 데이터 변환의 두 계층으로 분리하는 것입니다. 이 패턴은 한 데이터 흐름에서 느린 데이터 원본의 여러 쿼리를 처리하거나 동일한 데이터 원본을 쿼리하는 여러 데이터 흐름을 처리할 때 특히 유용합니다. 각 쿼리에 대해 느린 데이터 원본에서 데이터를 가져오는 대신 데이터 수집 프로세스를 한 번 수행할 수 있으며 해당 프로세스 위에 변환을 수행할 수 있습니다. 이 문서에서는 프로세스를 설명합니다.
온-프레미스 데이터 원본
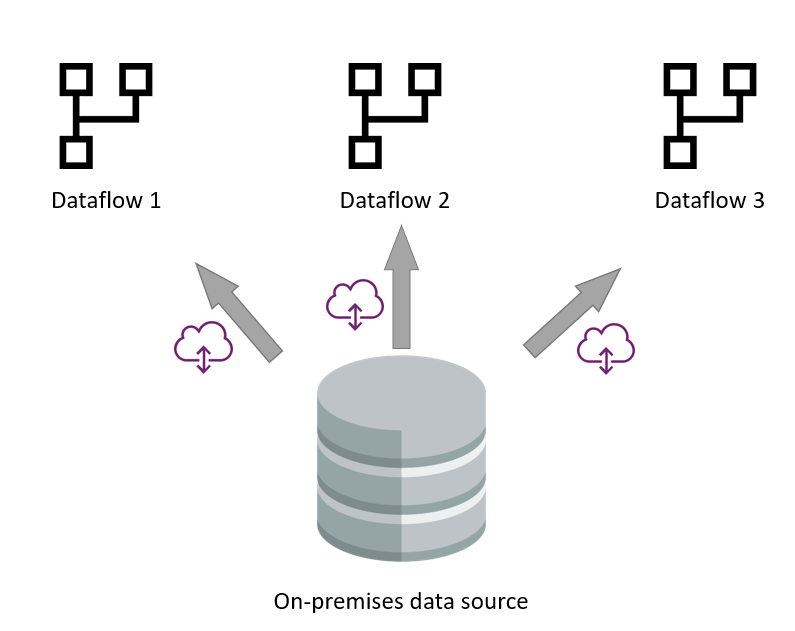
많은 시나리오에서 온-프레미스 데이터 원본은 느린 데이터 원본입니다. 특히 게이트웨이가 데이터 흐름과 데이터 원본 간의 중간 계층으로 존재한다는 점을 고려합니다.
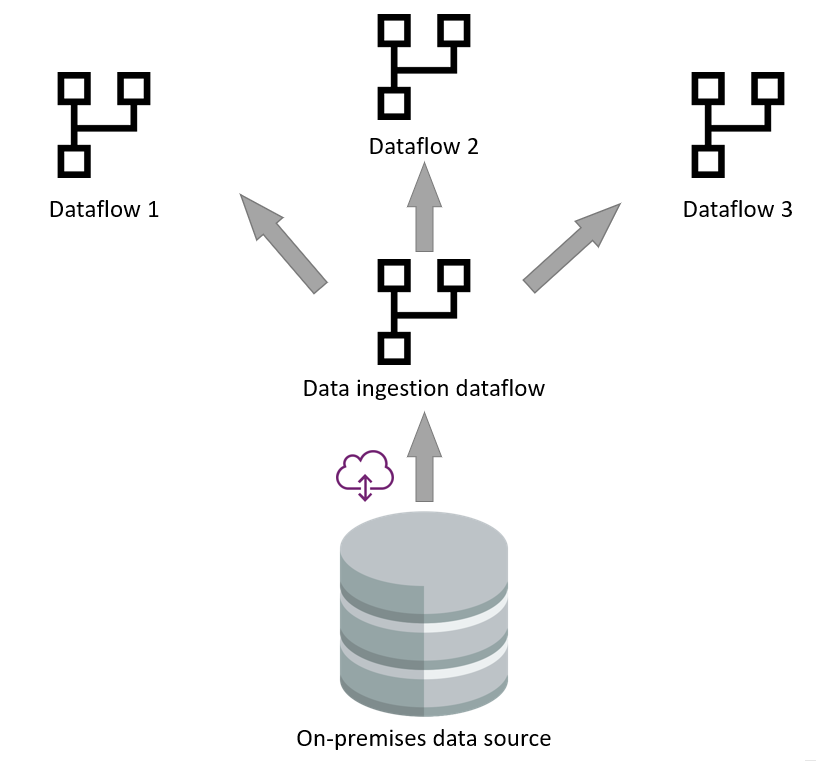
데이터 수집에 분석 데이터 흐름을 사용하면 원본에서 데이터 가져오기 프로세스가 최소화되고 Azure Data Lake Storage로 데이터를 로드하는 데 중점을 둡니다. 스토리지에 있으면 수집 데이터 흐름의 출력을 활용하는 다른 데이터 흐름을 만들 수 있습니다. 데이터 흐름 엔진은 원본 데이터 원본 또는 게이트웨이에 연결하지 않고도 데이터를 읽고 데이터 레이크에서 직접 변환을 수행할 수 있습니다.
느린 데이터 원본
데이터 원본이 느린 경우에도 동일한 프로세스가 유효합니다. 일부 SaaS(Software as a Service) 데이터 원본은 API 호출의 제한 사항으로 인해 느리게 수행됩니다.
데이터 수집 및 데이터 변환 데이터 흐름 분리
데이터 수집 및 변환이라는 두 계층의 분리는 데이터 원본이 느린 시나리오에서 유용합니다. 데이터 원본과의 상호 작용을 최소화하는 데 도움이 됩니다.
이 분리는 성능 향상으로 인해 유용할 뿐만 아니라 이전 레거시 데이터 원본 시스템이 새 시스템으로 마이그레이션된 시나리오에도 유용합니다. 이러한 경우 데이터 수집 데이터 흐름만 변경해야 합니다. 데이터 변환 데이터 흐름은 이러한 유형의 변경에 대해 그대로 기본.
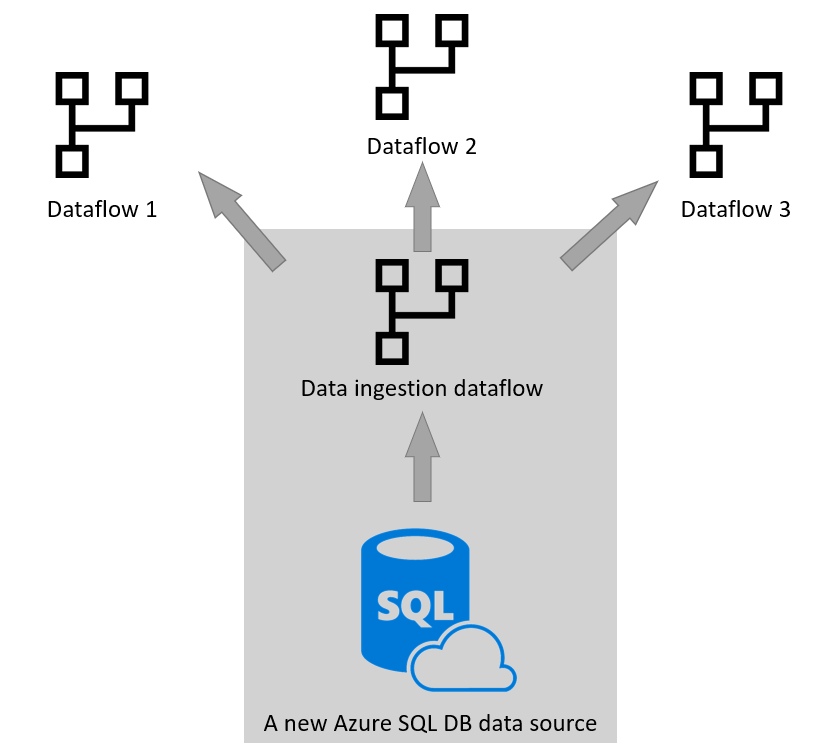
다른 도구 및 서비스에서 다시 사용
데이터 수집 데이터 흐름을 데이터 변환 데이터 흐름과 분리하는 것은 많은 시나리오에서 유용합니다. 이 패턴의 또 다른 사용 사례 시나리오는 다른 도구 및 서비스에서 이 데이터를 사용하려는 경우입니다. 이를 위해 분석 데이터 흐름을 사용하고 사용자 고유의 Data Lake Storage를 스토리지 엔진으로 사용하는 것이 좋습니다. 추가 정보: 분석 데이터 흐름
데이터 수집 데이터 흐름 최적화
가능하면 데이터 수집 데이터 흐름을 최적화하는 것이 좋습니다. 예를 들어 원본의 모든 데이터가 필요하지 않고 데이터 원본이 쿼리 폴딩을 지원하는 경우 데이터를 필터링하고 필요한 하위 집합만 가져오는 것이 좋습니다. 쿼리 폴딩에 대해 자세히 알아보려면 파워 쿼리에서 쿼리 평가 및 쿼리 폴딩 개요로 이동합니다.
분석 데이터 흐름으로 데이터 수집 데이터 흐름 만들기
데이터 수집 데이터 흐름을 분석 데이터 흐름으로 만드는 것이 좋습니다. 특히 다른 서비스 및 애플리케이션에서 이 데이터를 사용하는 데 도움이 됩니다. 이렇게 하면 데이터 변환 데이터 흐름이 분석 수집 데이터 흐름에서 데이터를 쉽게 가져올 수 있습니다. 자세히 알아보려면 분석 데이터 흐름으로 이동합니다.