적용 대상: Machine Learning Studio(클래식)
Machine Learning Studio(클래식)  Azure Machine Learning
Azure Machine Learning
중요한
Machine Learning Studio(클래식)에 대한 지원은 2024년 8월 31일에 종료됩니다. 해당 날짜까지 Azure Machine Learning으로 전환하는 것이 좋습니다.
2021년 12월 1일부터 새로운 Machine Learning Studio(클래식) 리소스를 만들 수 없습니다. 2024년 8월 31일까지는 기존 Machine Learning Studio(클래식) 리소스를 계속 사용할 수 있습니다.
- ML Studio(클래식)에서 Azure Machine Learning으로 기계 학습 프로젝트 이동에 대한 정보를 참조하세요.
- Azure Machine Learning에 대해 자세히 알아보세요.
ML Studio(클래식) 설명서는 사용 중지되며 나중에 업데이트되지 않을 수 있습니다.
이 항목에서는 Machine Learning Studio(클래식)에서 예측 결과를 시각화하고 해석하는 방법을 설명합니다. 모델을 학습하고 그 위에 예측을 수행한 후("모델 점수 매기기") 예측 결과를 이해하고 해석해야 합니다.
Machine Learning Studio(클래식)에는 4가지 주요 기계 학습 모델이 있습니다.
- 분류
- 클러스터링
- 회귀
- 추천 시스템
이러한 모델을 기반으로 예측에 사용되는 모듈은 다음과 같습니다.
- 분류 및 회귀에 대한 모델 점수 매기기 모듈
- 클러스터링을 위한 클러스터에 할당 모듈
- 추천 시스템에 대한 Matchbox 추천 점수 매기기
ML Studio(클래식)에서 알고리즘을 최적화하기 위해 매개 변수를 선택하는 방법을 알아봅니다.
모델을 평가하는 방법에 대한 자세한 내용은 모델 성능을 평가하는 방법을 참조하세요.
ML 스튜디오(클래식)을 처음 접하는 경우 간단한 실험을 만드는 방법을 알아보세요.
분류
분류 문제의 하위 범주는 다음 두 가지가 있습니다.
- 두 클래스의 문제(2클래스 또는 이진 분류)
- 두 개 이상의 클래스 문제(다중 클래스 분류)
Machine Learning Studio(클래식)에는 각 분류 유형을 처리하는 다양한 모듈이 있지만 예측 결과를 해석하는 방법은 비슷합니다.
2클래스 분류
예제 실험
2클래스 분류 문제의 예로는 홍채 꽃 분류가 있습니다. 이 작업은 특징에 따라 홍채 꽃을 분류하는 것입니다. Machine Learning Studio(클래식)에서 제공되는 아이리스 데이터 세트는 꽃 종 2개(클래스 0 및 1)의 인스턴스를 포함하는 인기 있는 아이리스 데이터 집합 의 하위 집합입니다. 각 꽃에 대한 네 가지 기능이 있습니다 (세팔 길이, 서팔 너비, 꽃잎 길이, 꽃잎 너비).
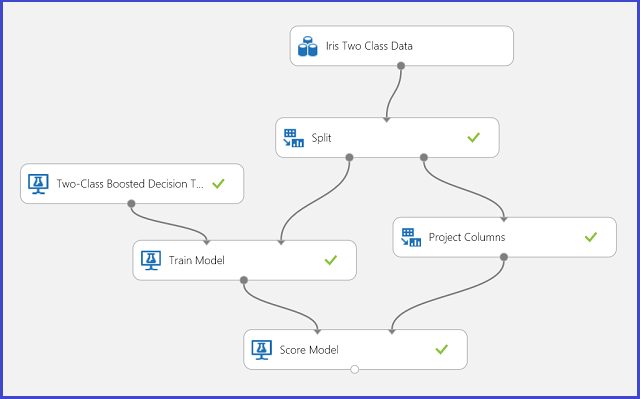
그림 1 붓꽃 2클래스 분류 문제 실험
그림 1에 표시된 대로 이 문제를 해결하기 위해 실험을 수행했습니다. 2클래스의 향상된 의사 결정 트리 모델이 학습되어 점수가 지정되었습니다. 이제 점수 매기기 모듈의 출력 포트를 클릭하고 나서 시각화를 클릭하여 예측 결과를 시각화할 수 있습니다.
그러면 그림 2에 표시된 대로 점수 매기기 결과가 표시됩니다.
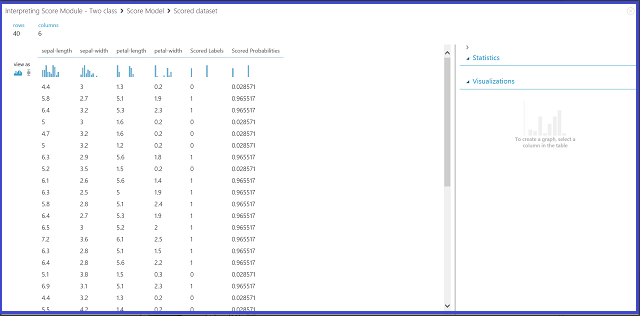
그림 2. 2클래스 분류에서 점수 모델 결과 시각화
결과 해석
결과 테이블에는 6개의 열이 있습니다. 왼쪽 네 개의 열은 네 가지 기능입니다. 오른쪽 두 열인 점수가 매겨진 레이블과 점수가 매겨진 확률이 예측 결과입니다. 점수 확률 열은 꽃이 양성 클래스(클래스 1)에 속할 확률을 보여줍니다. 예를 들어 열의 첫 번째 숫자(0.028571)는 첫 번째 꽃이 클래스 1에 속할 확률이 0.028571임을 나타냅니다. 점수가 매표된 레이블 열에는 각 꽃에 대한 예측 클래스가 표시됩니다. 점수가 매기된 확률 열에 따라 달라집니다. 꽃의 확률 점수가 0.5보다 크면 1번 클래스로 예측됩니다. 그렇지 않으면 클래스 0으로 예측됩니다.
웹 서비스 게시
예측 결과를 이해하고 판단한 후 실험을 웹 서비스로 게시하여 다양한 애플리케이션에 배포하고 호출하여 새 홍채 꽃에 대한 클래스 예측을 얻을 수 있습니다. 학습 실험을 점수 매기기 실험으로 변경하고 웹 서비스로 게시하는 방법을 알아보려면 자습서 3: 신용 위험 모델 배포를 참조하세요. 이 절차는 그림 3과 같이 점수 매기기 실험을 제공합니다.
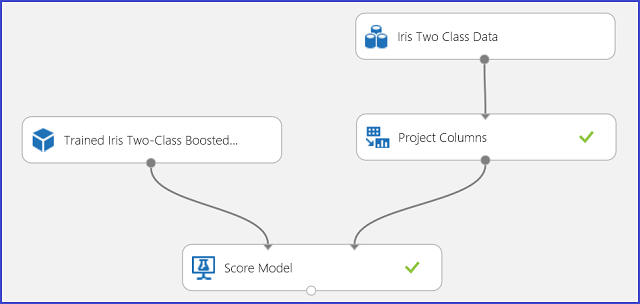
그림 3. 홍채 2가지 클래스 분류 문제 실험 점수 매기기
이제 웹 서비스의 입력 및 출력을 설정해야 합니다. 입력은 Iris 붓꽃의 특징 입력을 위한 Score Model의 오른쪽 입력 포트입니다. 출력 선택은 예측 클래스(점수가 매칭된 레이블), 점수가 매칭된 확률 또는 둘 다에 관심이 있는지 여부에 따라 달라집니다. 이 예에서는 둘 다에 관심이 있다고 가정합니다. 원하는 출력 열을 선택하려면 데이터 집합 모듈에서 열 선택 모듈을 사용합니다. 데이터 집합의 열 선택 모듈을 클릭하고, 열 선택기 시작을 클릭한 다음 점수가 매겨진 레이블 및 점수가 매겨진 확률을 선택합니다. 데이터 집합에서 열 선택의 출력 포트를 설정하고 다시 실행한 후에는 웹 서비스 게시를 클릭하여 점수 매기기 실험을 웹 서비스로 게시할 준비가 된 것입니다. 최종 실험은 그림 4와 같습니다.
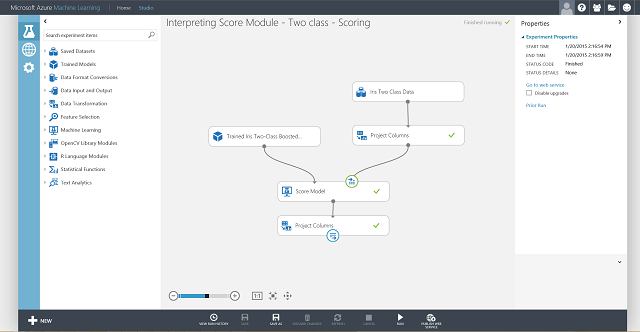
그림 4. 홍채 2클래스 분류 문제의 최종 점수 매기기 실험
웹 서비스를 실행하고 테스트 인스턴스의 특징 값을 입력하면 결과에 두 숫자가 반환됩니다. 첫 번째 숫자는 점수가 매겨진 레이블이고, 두 번째는 점수가 매겨진 확률입니다. 이 꽃은 0.9655 확률을 가진 클래스 1로 예측됩니다.
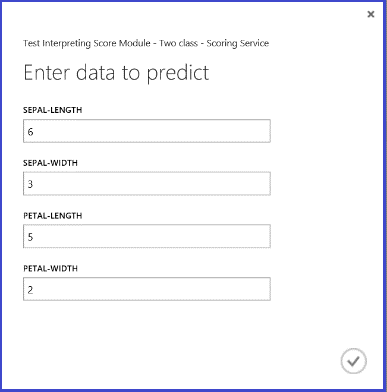

그림 5. 홍채 두 범주 분류의 웹 서비스 결과
다중 클래스 분류
예제 실험
이 실험에서는 다중 클래스 분류의 예로 문자 인식 작업을 수행합니다. 분류자는 손으로 쓴 이미지에서 추출된 일부 손으로 쓴 특성 값을 기반으로 특정 문자 %28class%29를 예측하려고 시도합니다.
학습 데이터에는 손으로 쓴 편지 이미지에서 추출된 16가지 기능이 있습니다. 26개 문자가 26개 클래스를 형성합니다. 그림 6에서는 문자 인식에 대한 다중 클래스 분류 모델을 학습시키고 테스트 데이터 집합에서 동일한 기능 집합을 예측하는 실험을 보여줍니다.
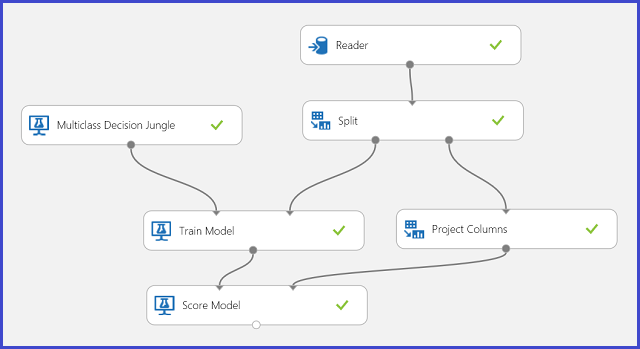
그림 6. 문자 인식 다중 클래스 분류 문제 실험
모델 점수 매기기 모듈의 출력 포트를 클릭한 다음 시각화를 클릭하여 모델 점수 매기기 모듈의 결과를 시각화하면 그림 7과 같이 콘텐츠가 표시됩니다.
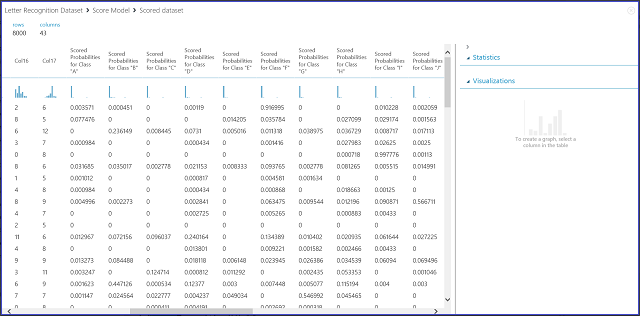
그림 7. 다중 클래스 분류에서 점수 모델 결과 시각화
결과 해석
왼쪽에 있는 16개의 열이 테스트 집합의 기능 값을 나타냅니다. 클래스 『XX』의 점수가 매겨진 확률이라는 이름의 열은 이중 클래스 경우에서 점수가 매겨진 확률 열과 같습니다. 해당 항목이 특정 클래스에 속할 확률을 보여줍니다. 예를 들어 첫 번째 항목의 경우, "A"일 확률은 0.003571이고, "B"일 확률은 0.000451입니다. 마지막 열(점수가 매기된 레이블)은 2클래스 사례에서 채점된 레이블과 동일합니다. 점수가 가장 큰 확률을 가진 클래스를 해당 항목의 예측 클래스로 선택합니다. 예를 들어, 첫 번째 항목에서 가장 큰 확률은 “F”(0.916995)이므로 점수가 매겨진 레이블은 “F”입니다.
웹 서비스 게시
각 항목에 대해 점수가 매표된 레이블과 점수가 매표된 레이블의 확률을 가져올 수도 있습니다. 기본 논리는 점수가 매기된 모든 확률 중에서 가장 큰 확률을 찾는 것입니다. 이렇게 하려면 R 스크립트 실행 모듈을 사용해야 합니다. R 코드는 그림 8에 표시되고 실험 결과는 그림 9에 표시됩니다.

그림 8. 점수가 매겨진 레이블 및 레이블의 관련 확률을 추출하기 위한 R 코드
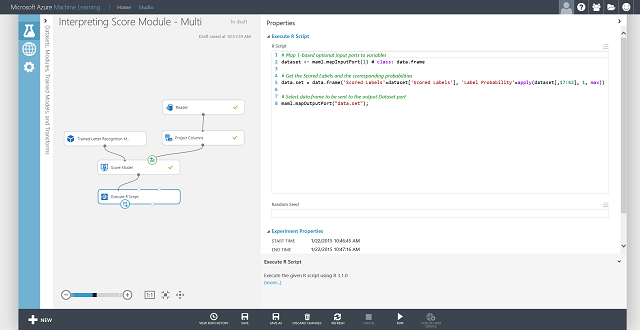
그림 9. 문자 인식 다중 클래스 분류 문제의 최종 점수 매기기 실험
웹 서비스를 게시하고 실행하고 일부 입력 기능 값을 입력하면 반환된 결과는 그림 10과 같습니다. 16개의 기능이 추출된 이 필기 문자는 0.9715 확률로 “T”인 것으로 예측됩니다.
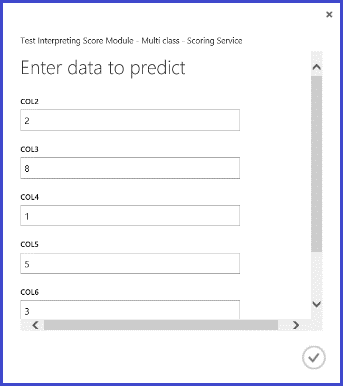

그림 10. 다중 클래스 분류의 웹 서비스 결과
회귀
회귀 문제는 분류 문제와 다릅니다. 분류 문제에서는 홍채 꽃이 속한 클래스와 같은 불연속 클래스를 예측하려고 합니다. 하지만 회귀 문제에서는 다음 예에서 볼 수 있듯이, 자동차 가격과 같은 연속 변수에 대해 예측하려고 합니다.
예제 실험
회귀를 위한 예로 자동차 가격 예측을 사용합니다. 메이크, 연료 유형, 차체 유형 및 드라이브 휠을 포함한 기능에 따라 자동차 가격을 예측하려고 합니다. 실험은 그림 11에 나와 있습니다.
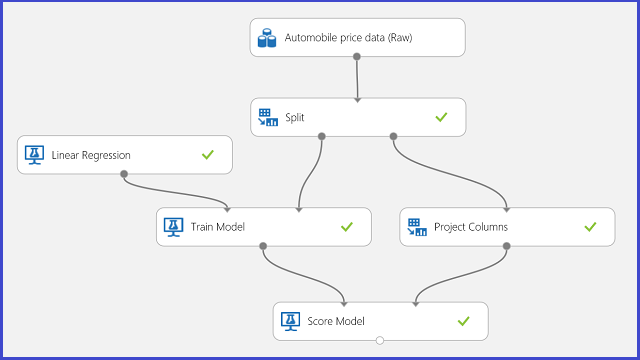
그림 11. 자동차 가격 회귀 문제 실험
모델 점수 매기기 모듈을 시각화하면 결과는 그림 12와 같습니다.
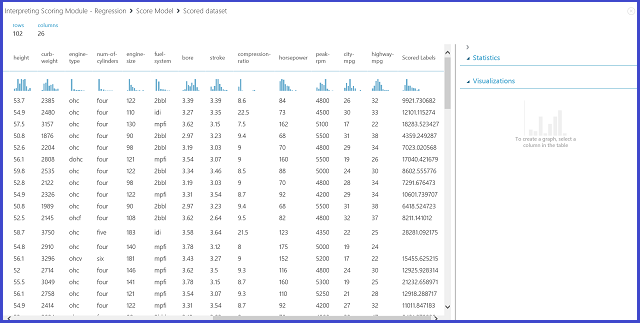
그림 12. 자동차 가격 예측 문제에 대한 점수 매기기 결과
결과 해석
이 채점 결과에서 채점된 레이블이 결과 열입니다. 숫자는 각 자동차의 예상 가격입니다.
웹 서비스 게시
회귀 실험을 웹 서비스에 게시하고 2클래스 분류 사용 사례와 동일한 방식으로 자동차 가격 예측을 호출할 수 있습니다.
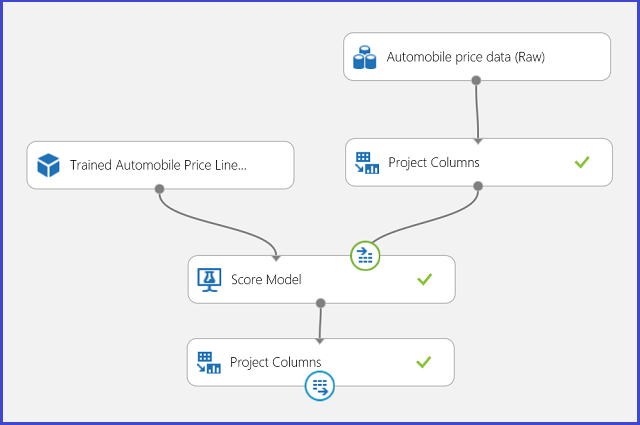
그림 13. 자동차 가격 회귀 문제의 점수 매기기 실험
웹 서비스를 실행하면 반환된 결과는 그림 14와 같습니다. 이 자동차의 예상 가격은 $15,085.52입니다.
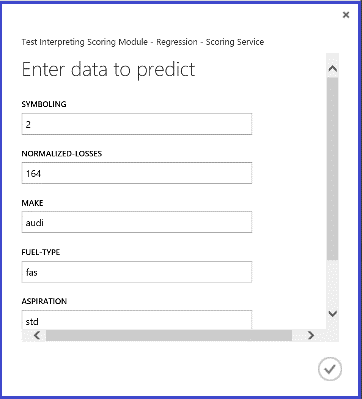

그림 14. 자동차 가격 회귀 문제의 웹 서비스 결과
클러스터링
예제 실험
다시 Iris 데이터 세트를 사용하여 클러스터링 실험을 구축해 보겠습니다. 여기서는 기능만 있고 클러스터링에 사용할 수 있도록 데이터 집합의 클래스 레이블을 필터링할 수 있습니다. 이 붓꽃 사용 사례에서는 학습 프로세스 중에 클러스터의 수를 2로 지정합니다. 즉, 꽃을 2클래스로 클러스터링합니다. 실험은 그림 15에 표시됩니다.
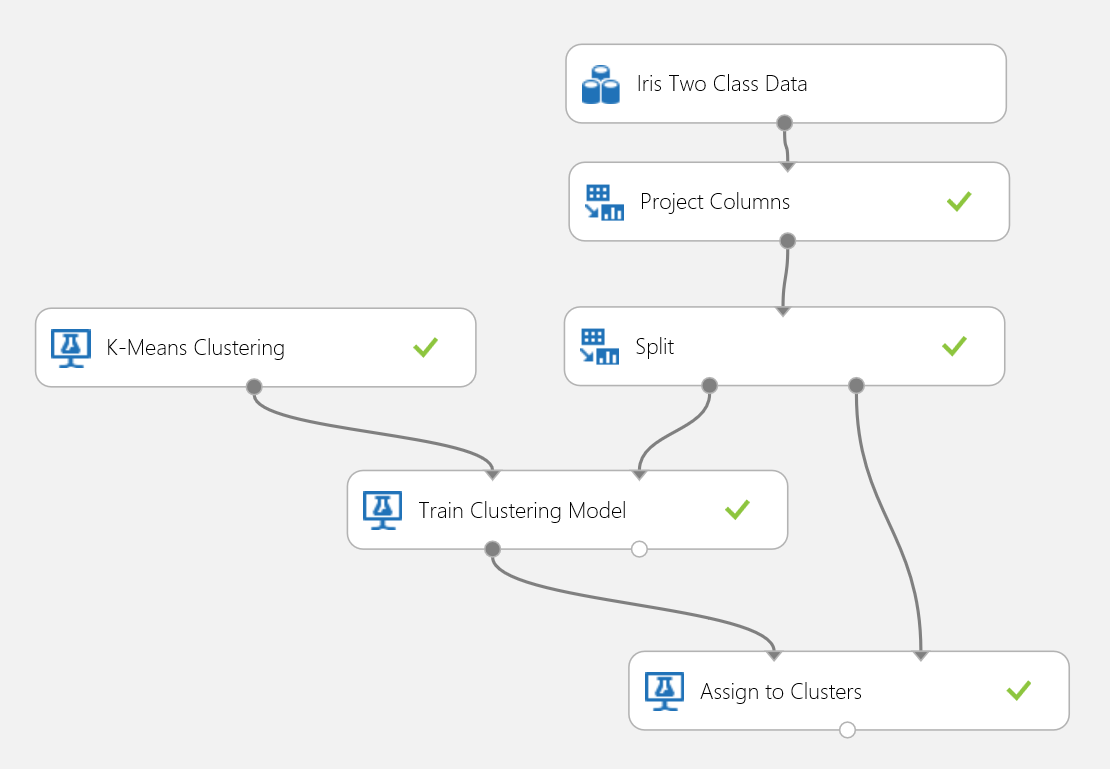
그림 15. 아이리스 클러스터링 문제 실험
클러스터링은 학습 데이터 집합에 정답 레이블이 없다는 점에서 분류와 다릅니다. 클러스터링에서는 학습 데이터 집합 인스턴스를 고유한 클러스터로 그룹화합니다. 학습 프로세스 중에 모델에서 해당 특징 사이의 차이점을 학습하여 항목의 레이블을 지정합니다. 그런 다음 학습된 모델을 사용하여 향후 항목을 추가로 분류할 수 있습니다. 클러스터링 문제 내에서 관심 있는 결과의 두 부분이 있습니다. 첫 번째 부분은 학습 데이터 집합에 레이블을 지정하고, 두 번째 부분은 학습된 모델을 사용하여 새 데이터 집합을 분류하는 것입니다.
결과의 첫 번째 부분은 클러스터링 모델 학습 모듈의 왼쪽 출력 포트를 클릭하고 시각화를 클릭하여 시각화할 수 있습니다. 시각화는 그림 16에 나와 있습니다.
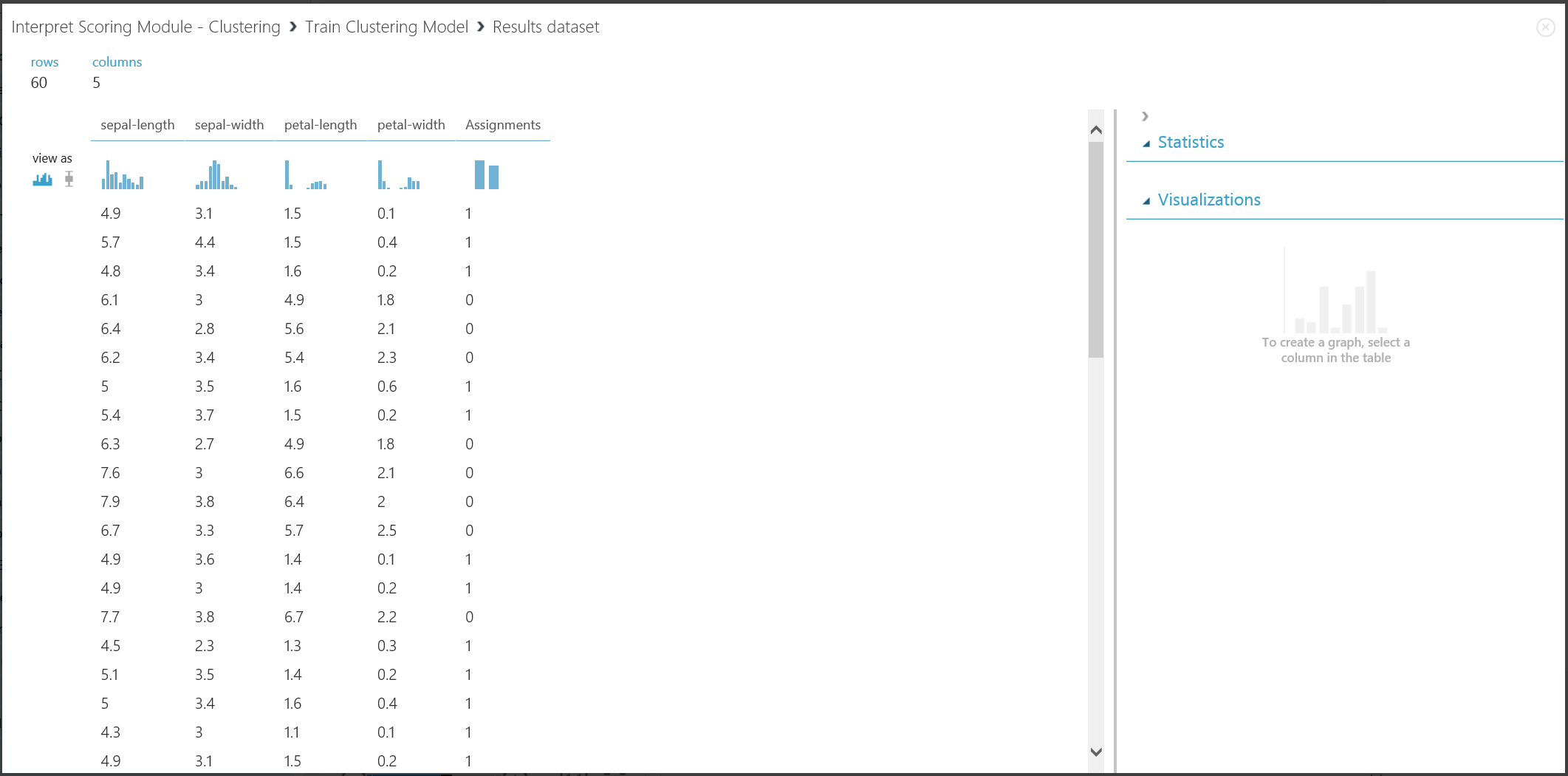
그림 16. 학습 데이터 집합의 클러스터링 결과 시각화
학습된 클러스터링 모델을 사용하여 새 항목을 클러스터링하는 두 번째 부분의 결과는 그림 17에 나와 있습니다.
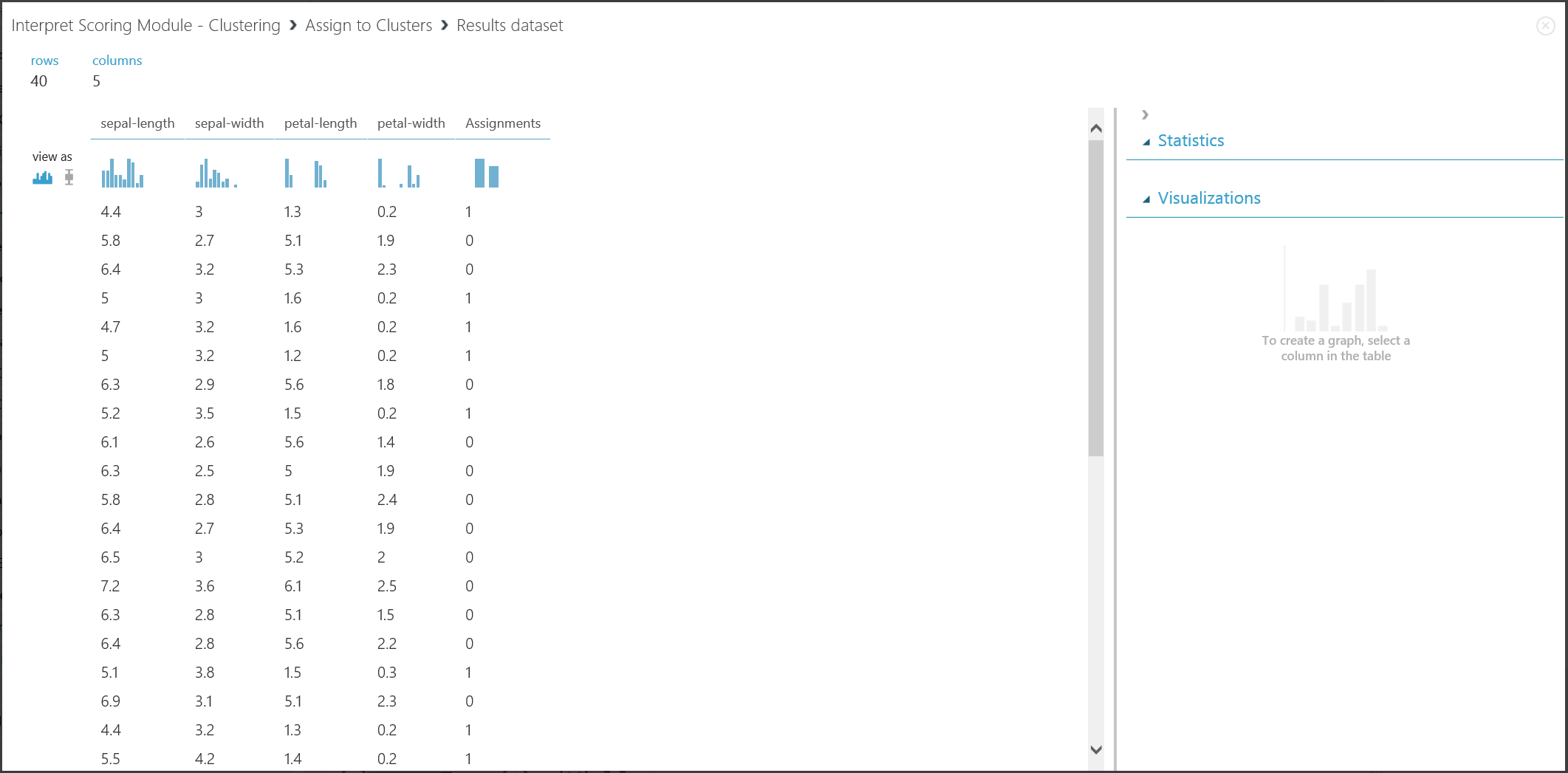
그림 17. 새 데이터 집합에서 클러스터링 결과 시각화
결과 해석
두 부분의 결과는 서로 다른 실험 단계에서 비롯되지만 동일하게 보이고 동일한 방식으로 해석됩니다. 처음 네 개의 열은 특징입니다. 마지막 열인 '할당'은 예측의 결과입니다. 동일한 번호가 할당된 항목은 동일한 클러스터에 있을 것으로 예측됩니다. 즉, 어떤 식으로든 유사성을 공유합니다(이 실험에서는 기본 유클리드 거리 메트릭을 사용). 클러스터 수를 2로 지정했기 때문에 할당의 항목은 0 또는 1로 레이블이 지정됩니다.
웹 서비스 게시
클러스터링 실험을 웹 서비스에 게시하고 2클래스 분류 사용 사례와 동일한 방식으로 클러스터링 예측을 호출할 수 있습니다.
그림 18. 아이리스 군집화 문제 채점 실험
웹 서비스를 실행한 후 반환된 결과는 그림 19와 같습니다. 이 꽃은 클러스터 0에 있을 것으로 예측됩니다.
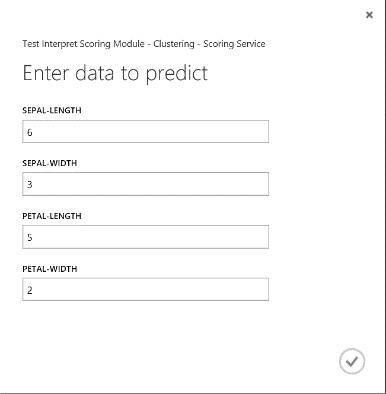

그림 19. 홍채 두 범주 분류의 웹 서비스 결과
추천 시스템
예제 실험
추천 시스템의 경우 식당 추천 문제를 예로 사용할 수 있습니다. 등급 기록을 기반으로 고객에게 레스토랑을 추천할 수 있습니다. 입력 데이터는 다음 세 부분으로 구성됩니다.
- 고객이 평가한 음식점 등급
- 고객 기능 데이터
- 음식점 기능 데이터
Machine Learning Studio(클래식)에서 매치박스 추천자 학습 모듈을 통해 할 수 있는 몇 가지 작업은 다음과 같습니다.
- 지정된 사용자 및 항목에 대한 등급 예측
- 지정된 사용자에게 항목 추천
- 지정된 사용자와 관련된 사용자 찾기
- 지정된 항목과 관련된 항목 찾기
추천 예측 종류 메뉴의 네 가지 옵션 중에서 선택하여 수행할 작업을 선택할 수 있습니다. 여기서는 네 가지 시나리오를 모두 연습할 수 있습니다.
추천 시스템에 대한 일반적인 Machine Learning Studio(클래식) 실험은 그림 20과 같습니다. 이러한 추천 시스템 모듈을 사용하는 방법에 대한 정보는 매치박스 추천 학습 및 매치박스 추천 점수 매기기를 참조하세요.
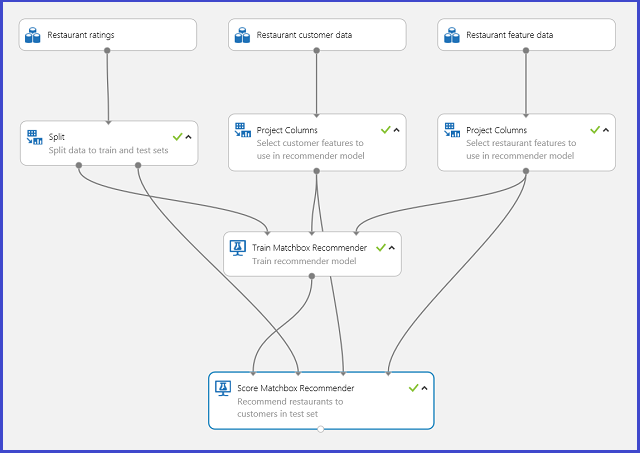
그림 20. 추천 시스템 실험
결과 해석
지정된 사용자 및 항목에 대한 등급 예측
추천 예측 종류에서 등급 예측을 선택하면 추천 시스템에 지정된 사용자 및 항목에 대한 등급을 예측하도록 요청합니다. 매치박스 추천 점수 매기기 출력의 시각화는 그림 21과 같습니다.
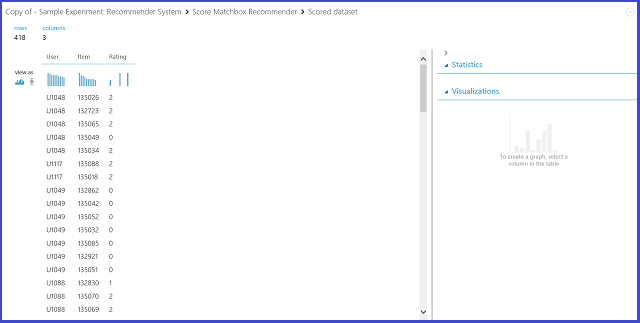
그림 21. 추천 시스템 - 등급 예측의 점수 매기기 결과 시각화
처음 두 열은 입력 데이터에서 제공하는 사용자 항목 쌍입니다. 세 번째 열은 특정 항목에 대한 사용자의 예측 등급입니다. 예를 들어, 첫 번째 행에서 U1048 고객은 135026 음식점의 등급을 2로 지정할 것으로 예측됩니다.
지정된 사용자에게 항목 추천
추천 예측 종류에서 항목 권장 사항을 선택하면 추천 시스템에 지정된 사용자에게 항목을 추천하도록 요청합니다. 이 시나리오에서 선택할 마지막 매개 변수는 추천 항목 선택입니다. 옵션 "정격 항목에서 (모델 평가용)"은 학습 과정에서 주로 모델 평가를 위해 사용됩니다. 이 예측 단계에서는 모든 항목에서 선택합니다. 점수 매치박스 추천기의 출력 시각화는 그림 22와 같습니다.
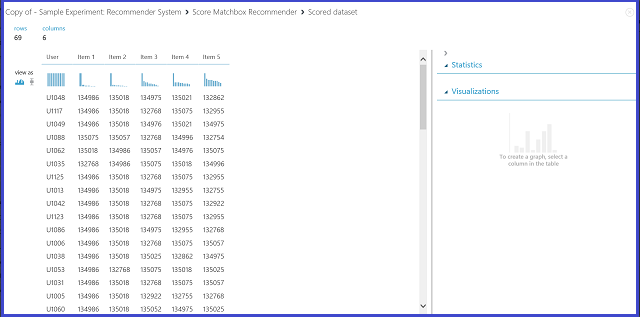
그림 22. 추천 시스템-항목 권장 사항의 점수 결과 시각화
6개 열 중 첫 번째 열은 입력 데이터에서 제공한 항목을 추천받도록 지정된 사용자 ID를 나타냅니다. 나머지 5개 열은 사용자에게 추천할 항목을 나타내며 관련성에 따라 내림차순으로 정렬됩니다. 예를 들어 첫 번째 행에서 U1048 고객에게 가장 추천되는 레스토랑은 134986, 135018, 134975, 135021 및 132862.
지정된 사용자와 관련된 사용자 찾기
추천 예측 종류에서 관련 사용자를 선택하면 추천 시스템에 지정된 사용자와 관련된 사용자를 찾도록 요청합니다. 관련 사용자는 비슷한 기본 설정을 가진 사용자입니다. 이 시나리오에서 선택할 마지막 매개 변수는 관련 사용자 선택입니다. 사용자가 항목에 평가를 매긴 내역 (모델 평가용) 에서의 옵션은 주로 학습 과정에서 모델 평가를 위해 사용됩니다. 이 예측 단계에 대해 모든 사용자 중에서 선택합니다. Score Matchbox Recommender 출력의 시각화는 그림 23과 같습니다.
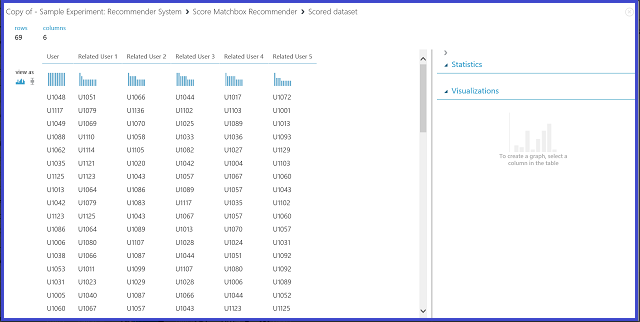
그림 23. 추천 시스템-관련 사용자의 점수 결과 시각화
6개 열 중 첫 번째 열은 입력 데이터에서 제공한 관련 사용자를 찾는 데 필요한 특정 사용자 ID를 나타냅니다. 나머지 5개 열은 사용자의 예측된 관련 사용자를 관련성의 내림차순으로 저장합니다. 예를 들어 첫 번째 행에서 고객 U1048에 가장 관련성이 있는 고객은 U1051이고 U1066, U1044, U1017 및 U1072가 그 뒤를 잇습니다.
지정된 항목과 관련된 항목 찾기
추천 예측 종류에서 관련 항목을 선택하면 추천 시스템에 지정된 항목에 대한 관련 항목을 찾도록 요청합니다. 관련 항목은 동일한 사용자가 좋아할 가능성이 가장 큰 항목입니다. 이 시나리오에서 선택할 마지막 매개 변수는 관련 항목 선택입니다. 정격 항목에서 (모델 평가용) 옵션은 주로 학습 프로세스 중 모델 평가를 위한 것입니다. 우리는 이 예측 단계에서 '모든 항목에서'를 선택합니다. 매치박스 추천 점수 매기기 출력의 시각화는 그림 24와 같습니다.
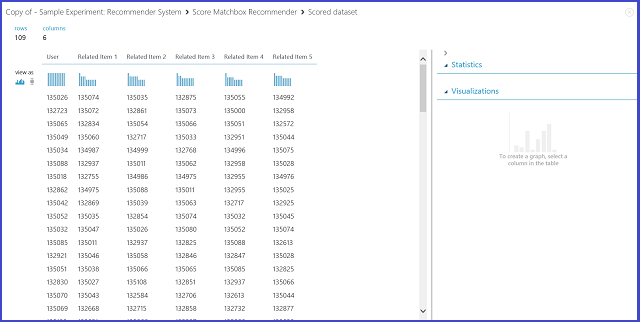
그림 24. 추천 시스템-관련 항목의 점수 결과 시각화
6개 열 중 첫 번째 열은 입력 데이터에서 제공하는 대로 관련 항목을 찾는 데 필요한 지정된 항목 ID를 나타냅니다. 나머지 5개 열은 항목의 예측된 관련 항목을 관련성 측면에서 내림차순으로 저장합니다. 예를 들어 첫 번째 행에서 135026 항목의 가장 관련성이 높은 항목은 135074이고, 그 다음은 135035, 132875, 135055 및 134992 순입니다.
웹 서비스 게시
이러한 실험을 웹 서비스로 게시하여 예측을 얻는 프로세스는 네 개의 각 시나리오와 비슷합니다. 여기서는 두 번째 시나리오(지정된 사용자에게 항목 추천)를 예로 들 수 있습니다. 다른 세 가지와 동일한 절차를 따를 수 있습니다.
학습된 추천 시스템을 학습된 모델로 저장하고 요청된 대로 입력 데이터를 단일 사용자 ID 열로 필터링하면 그림 25와 같이 실험을 연결하고 웹 서비스로 게시할 수 있습니다.
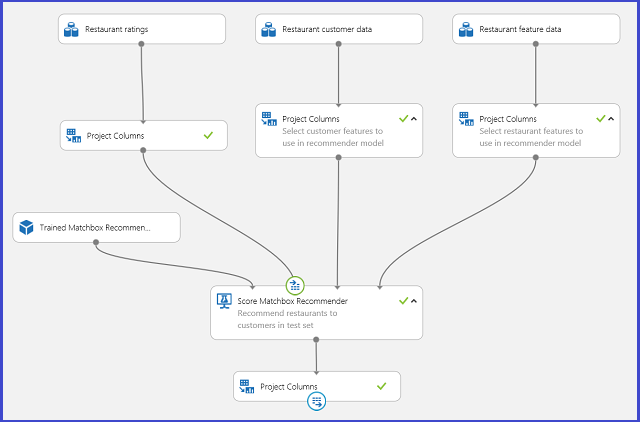
그림 25. 음식점 추천 문제의 점수 매기기 실험
웹 서비스를 실행하면 반환된 결과는 그림 26과 같습니다. U1048 사용자에게 추천되는 5개의 레스토랑은 134986, 135018, 134975, 135021 및 132862.
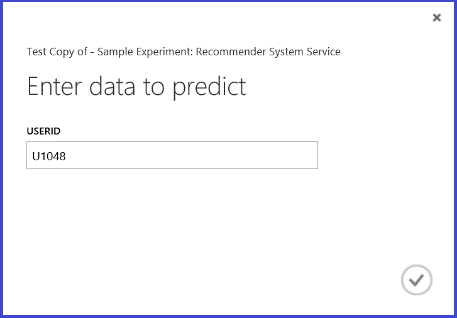

그림 26. 식당 추천 문제의 웹 서비스 결과