학습 가능한 분류자
이 분류 방법은 수동 또는 자동화된 패턴 일치 메서드를 사용하여 쉽게 식별할 수 없는 콘텐츠에 적합합니다. 분류자는 검색하려는 콘텐츠의 수백 가지 예제를 확인하여 콘텐츠 형식을 식별하는 방법을 알아봅니다.
참고
미리 보기에서: 필터 패널에서 학습 가능한 분류자를 확장하여 콘텐츠 탐색기에서 학습 가능한 분류자를 볼 수 있습니다. 학습 가능한 분류자는 레이블 지정 없이 SharePoint 및 Teams에서 발견된 인시던트 수를 자동으로 표시합니다. 이 기능을 사용하지 않으려면 Microsoft 지원 요청을 제출해야 합니다. 이 요청은 콘텐츠 Explorer 내의 레이블 지정 정책에 사용되지 않는 중요한 데이터의 표시를 사용하지 않도록 설정합니다. 데이터 검사도 사용하지 않도록 설정할 수 있습니다. 검사가 꺼져 있으면 해당 분류자를 사용하는 민감도 레이블 지정 및 DLP 정책이 작동하지 않습니다.
분류자를 사용할 수 있는 위치
분류자를 다음의 조건으로 사용합니다.
- 민감도 레이블을 사용하여 Office 파일 자동 레이블 지정
- 조건에 따라 보존 레이블 정책 자동 적용
- 통신 규정 준수 는 Microsoft에서 제공하는 학습 가능한 분류자만 지원합니다.
- 민감도 레이블 조건. ( Microsoft 365 데이터에 민감도 레이블 자동 적용 참조)
- 데이터 손실 방지
중요
분류자는 암호화되지 않은 항목에서만 작동합니다.
분류자 유형
-
Microsoft에서 미리 학습된 분류자 제공 - Microsoft는 학습 없이 사용할 수 있는 여러 분류자를 만들고 미리 학습했습니다. 이러한 분류자는 의
Ready to use상태 함께 표시됩니다. 이러한 분류자는 지원되는 언어 열에 나열된 모든 언어로 항목을 평가합니다. - 사용자 지정 학습 가능한 분류자 - 미리 학습된 분류자가 다루는 것 이상으로 콘텐츠를 식별하고 분류해야 하는 경우 고유한 분류자를 만들고 학습시킬 수 있습니다.
미리 학습된 모든 분류자의 전체 목록은 학습 가능한 분류자 정의를 참조하세요.
사용자 지정 분류자
중요
언어 제한 사항: 사용자 지정 분류자 지원은 영어로 제한됩니다.
Microsoft에서 미리 학습된 분류자가 요구 사항을 충족하지 않는 경우 고유한 분류자를 만들고 학습할 수 있습니다. 직접 만드는 작업에는 더 많은 작업이 있지만 organization 요구에 더 잘 맞습니다.
학습 가능한 사용자 지정 분류자를 만들려면 먼저 범주에 확실히 있는 예제 집합과 범주에 없는 다른 예제 집합을 제공합니다. Microsoft Purview는 이러한 예제를 처리하고 분류자는 지정된 항목이 빌드 중인 범주에 속하는지 여부를 예측합니다. 그런 다음 결과를 확인하여 실제 긍정, 참 부정, 가양성 및 거짓 부정을 정렬하여 예측의 정확도를 높이는 데 도움이 됩니다.
분류자를 게시하면 SharePoint 및 Exchange와 같은 위치에서 항목을 정렬하고 콘텐츠를 분류합니다.
예를 들어 다음을 위한 학습 가능한 분류자를 만들 수 있습니다.
- 법률 문서 - 변호사 클라이언트 권한, 닫는 세트, 작업 명세서와 같은
- 전략적 비즈니스 문서 - 보도 자료, 합병 및 인수, 거래, 비즈니스 또는 마케팅 계획, 지적 재산권, 특허, 디자인 문서와 같은
- 가격 정보 - 청구서, 가격 견적, 작업 주문, 입찰 문서 등
- 재무 정보 - 조직 투자, 분기별 또는 연간 결과와 같은
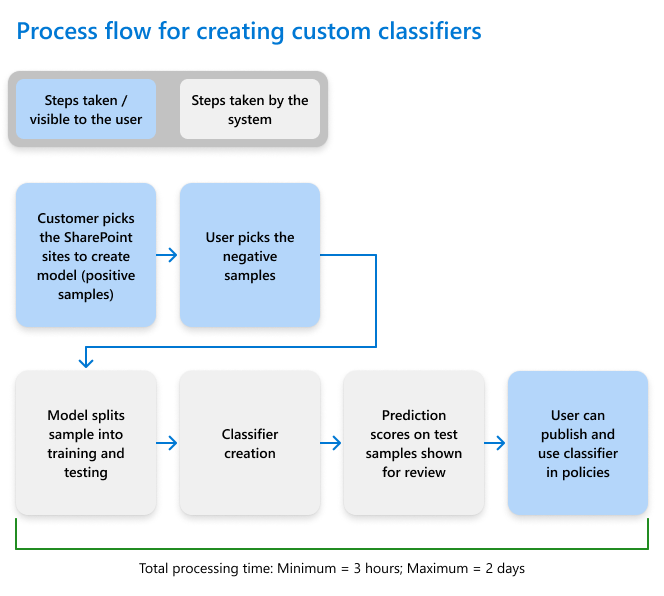
사용자 지정 분류자를 만들기 위한 프로세스 흐름
다음 흐름 다이어그램은 보존 정책 및 통신 감독과 같은 규정 준수 솔루션에서 사용할 분류자를 만들고 게시하는 프로세스를 보여 줍니다. 사용자 지정 학습 가능 분류자를 만드는 방법에 대한 자세한 내용은 학습 가능한 분류자 시작을 참조하세요.
팁
시드 데이터에 대한 새 SharePoint 사이트 및 폴더를 만드는 경우 해당 시드 데이터를 사용하는 학습 가능한 분류자를 만들기 전에 해당 위치의 인덱싱을 1시간 이상 허용합니다.
분류자 재학습
게시된 사용자 지정 분류자 재학습은 지원되지 않습니다. 게시한 학습 가능한 분류자의 정확도를 개선해야 하는 경우 분류자를 제거하고 더 큰 샘플 집합으로 다시 시작합니다.
게시되지 않은 분류자의 정확도를 향상하려면 테스트 결과를 검토하고, 추가 데이터로 데이터 집합을 업데이트하고, 학습을 다시 시작합니다.