| 마야나 페레이라 | 스콧 크리스티안슨 |
|---|---|
| CELA 데이터 과학 | 고객 보안 및 신뢰 |
| Microsoft | Microsoft |
추상 - SBR(보안 버그 보고서) 식별은 소프트웨어 개발 수명 주기에서 중요한 단계입니다. 감독되는 기계 학습 기반 접근 방식에서 전체 버그 보고서를 학습에 사용할 수 있고 레이블이 노이즈가 없는 것으로 가정하는 것이 일반적입니다. 이 연구는 타이틀만 사용할 수 있고 레이블 노이즈가 있는 경우에도 SBR에 대해 정확한 레이블 예측이 가능하다는 것을 보여주는 첫 번째 연구입니다.
인덱스 용어 — Machine Learning, 잘못된 레이블 지정, 노이즈, 보안 버그 보고서, 버그 리포지토리
나는. 소개
보고된 버그 중 보안 관련 문제를 식별하는 것은 소프트웨어 개발 팀 사이에서 절박한 요구 사항입니다. 이러한 문제는 규정 준수 요구 사항을 충족하고 소프트웨어 및 고객 데이터의 무결성을 보장하기 위해 보다 신속한 수정을 요구합니다.
기계 학습 및 인공 지능 도구는 소프트웨어 개발을 더 빠르고 민첩하며 올바르게 만들 것을 약속합니다. 몇몇 연구자들은 보안 버그를 식별하는 문제에 기계 학습을 적용했습니다 [2], [7], [8], [18]. 이전에 발표된 연구에서는 전체 버그 보고서를 기계 학습 모델 학습 및 채점에 사용할 수 있다고 가정했습니다. 반드시 그렇지는 않습니다. 전체 버그 보고서를 사용할 수 없는 상황이 있습니다. 예를 들어 버그 보고서에는 암호, PII(개인 식별 정보) 또는 기타 종류의 중요한 데이터가 포함될 수 있습니다( 현재 Microsoft에서 직면하고 있는 경우). 따라서 버그 보고서의 제목만 사용할 수 있는 경우와 같이 더 적은 정보를 사용하여 보안 버그 식별을 얼마나 잘 수행할 수 있는지를 설정하는 것이 중요합니다.
또한 버그 리포지토리에는 종종 잘못된 레이블이 지정된 항목 [7]이 포함됩니다. 보안 관련으로 분류된 비보안 버그 보고서와 그 반대의 경우도 마찬가지입니다. 개발 팀의 보안 전문 지식 부족부터 특정 문제의 유사성에 이르기까지 잘못된 레이블이 발생하는 데는 여러 가지 이유가 있습니다. 예를 들어 비보안 버그가 간접적으로 악용되어 보안에 영향을 줄 수 있습니다. SBR의 레이블이 잘못 지정되면 보안 전문가가 비용이 많이 들고 시간이 많이 걸리는 작업으로 버그 데이터베이스를 수동으로 검토해야 하기 때문에 심각한 문제입니다. 노이즈가 다양한 분류자에게 미치는 영향과 다양한 종류의 노이즈로 오염된 데이터 세트가 있을 때 다른 기계 학습 기술이 얼마나 강력한지 이해하는 것은 소프트웨어 엔지니어링의 관행으로 자동 분류를 가져오기 위해 해결해야 하는 문제입니다.
예비 작업은 버그 리포지토리가 본질적으로 시끄럽고 노이즈가 성능 기계 학습 분류자 [7]에 부정적인 영향을 미칠 수 있다고 주장합니다. 그러나 다양한 수준의 노이즈 유형이 SRB(보안 버그 보고서)를 식별하는 문제에 대해 감독된 다양한 기계 학습 알고리즘의 성능에 어떤 영향을 미치는지에 대한 체계적이고 정량적인 연구는 없습니다.
이 연구에서는 타이틀만 학습 및 채점에 사용할 수 있는 경우에도 버그 보고서의 분류를 수행할 수 있음을 보여줍니다. 우리가 아는 한, 이것이 그렇게 하는 최초의 작업입니다. 또한 버그 보고서 분류에서 노이즈가 미치는 영향에 대한 첫 번째 체계적인 연구를 제공합니다. 우리는 클래스 독립적 인 소음에 대한 세 가지 기계 학습 기술 (로지스틱 회귀, 순진한 베이즈와 AdaBoost)의 견고성에 대한 비교 연구를합니다.
몇 가지 간단한 분류자 [5], [6]에 대한 노이즈에 대한 일반적인 영향을 캡처하는 몇 가지 분석 모델이 있지만 이러한 결과는 정밀도에 대한 노이즈 효과에 대한 엄격한 범위를 제공하지 않으며 특정 기계 학습 기술에만 유효합니다. 기계 학습 모델의 노이즈 효과에 대한 정확한 분석은 일반적으로 계산 실험을 실행하여 수행됩니다. 이러한 분석은 소프트웨어 측정 데이터 [4]에서 위성 이미지 분류 [13] 및 의료 데이터 [12]에 이르기까지 여러 시나리오에 대해 수행되었습니다. 그러나 이러한 결과는 데이터 세트의 특성과 기본 분류 문제에 대한 높은 종속성으로 인해 특정 문제로 변환될 수 없습니다. 우리가 아는 한, 특히 보안 버그 보고서 분류에 노이즈 데이터 세트가 미치는 영향에 대한 게시된 결과는 없습니다.
연구 기여:
보고서 제목만을 기반으로 SBR(보안 버그 보고서) 식별을 위한 분류자를 학습시킵니다. 우리가 아는 한, 이것이 그 작업을 수행하는 첫 번째 작업입니다. 이전 작업은 전체 버그 보고서를 사용하거나 추가 보완 기능을 사용하여 버그 보고서를 향상시켰습니다. 타일에만 기반한 버그 분류는 개인 정보 보호 문제로 인해 전체 버그 보고서를 사용할 수 없는 경우에 특히 관련이 있습니다. 예를 들어 암호 및 기타 중요한 데이터가 포함된 버그 보고서의 경우는 악명이 높습니다.
또한 SBR의 자동 분류에 사용되는 다양한 기계 학습 모델 및 기술의 레이블 노이즈 허용 오차에 대한 첫 번째 체계적인 연구를 제공합니다. 클래스 종속 및 클래스 독립적 노이즈에 대한 세 가지 고유한 기계 학습 기술(로지스틱 회귀, 순진한 Bayes 및 AdaBoost)의 견고성에 대한 비교 연구를 합니다.
나머지 논문은 다음과 같이 제시됩니다: 섹션 II에서는 문학의 이전 작품 중 일부를 제시합니다. III 섹션에서는 데이터 집합 및 데이터가 사전 처리되는 방법에 대해 설명합니다. 방법론은 섹션 IV 및 섹션 V에서 분석된 실험의 결과에 설명되어 있습니다. 마지막으로, 우리의 결론과 미래의 작품은 VI에 제시됩니다.
제2장 이전 작업
버그 리포지토리에 대한 기계 학습 애플리케이션.
버그 리포지토리에 텍스트 마이닝, 자연어 처리 및 기계 학습을 적용하여 보안 버그 탐지 [2], [7], [8], [18], 버그 중복 식별 [3], 버그 분류 [1], [11] 등과 같은 수작업이 많이 필요한 작업을 자동화하려는 광범위한 문헌이 있습니다. 이상적으로 ML(기계 학습) 및 자연어 처리의 결합은 잠재적으로 버그 데이터베이스를 큐레이팅하는 데 필요한 수동 작업을 줄이고 이러한 작업을 수행하는 데 필요한 시간을 단축하며 결과의 안정성을 높일 수 있습니다.
[7]에서 작성자는 버그 설명에 따라 SBR의 분류를 자동화하는 자연어 모델을 제안합니다. 작성자는 학습 데이터 집합의 모든 버그 설명에서 어휘를 추출하고 관련 단어, 중지 단어(분류와 관련이 없는 일반적인 단어) 및 동의어의 세 가지 단어 목록으로 수동으로 큐레이팅합니다. 보안 엔지니어가 모두 평가한 데이터에 대해 학습된 보안 버그 분류자의 성능과 일반적으로 버그 기자가 레이블을 지정한 데이터에 대해 학습된 분류자를 비교합니다. 해당 모델은 보안 엔지니어가 검토한 데이터를 학습할 때 분명히 더 효과적이지만, 제안된 모델은 수동으로 파생된 어휘를 기반으로 하므로 사용자 큐레이션에 종속됩니다. 또한 다양한 수준의 노이즈가 모델에 미치는 영향, 다양한 분류자에서 노이즈에 어떻게 반응하는지, 두 클래스의 노이즈가 성능에 다른 영향을 미치는지에 대한 분석은 없습니다.
Zou et. al [18]은 버그 보고서의 텍스트가 아닌 필드(예: 시간, 심각도 및 우선 순위)와 버그 보고서의 텍스트 콘텐츠(텍스트 기능, 즉 요약 필드의 텍스트)를 포함하는 버그 보고서에 포함된 여러 유형의 정보를 사용합니다. 이러한 기능을 기반으로 자연어 처리 및 기계 학습 기술을 통해 SBR을 자동으로 식별하는 모델을 빌드합니다. [8]에서 저자는 비슷한 분석을 수행하지만, 또한 감독 및 감독되지 않은 기계 학습 기술의 성능을 비교하고 모델을 학습시키는 데 필요한 데이터의 양을 연구합니다.
[2]에서 작성자는 설명에 따라 버그를 SBR 또는 NSBR(비보안 버그 보고서)으로 분류하는 다양한 기계 학습 기술을 살펴봅니다. TFIDF를 기반으로 데이터 처리 및 모델 학습을 위한 파이프라인을 제안합니다. 제안된 파이프라인을 단어 모음과 순진한 Bayes를 기반으로 하는 모델과 비교합니다. Wijayasekara 외. [16]에서는 텍스트 마이닝 기술을 사용하여 잦은 단어를 기반으로 각 버그 보고서의 기능 벡터를 생성하여 HIB(Hidden Impact Bugs)를 식별했습니다. Yang et al. [17]은 TF(용어 빈도)와 순진한 베이즈(Bayes)의 도움으로 영향력이 높은 버그 보고서(예: SBR)를 식별했다고 주장했습니다. [9]에서 작성자는 버그의 심각도를 예측하는 모델을 제안합니다.
레이블 노이즈
레이블 노이즈를 사용하여 데이터 세트를 처리하는 문제는 광범위하게 연구되었습니다. Frenay와 Verleysen은 다양한 유형의 시끄러운 레이블을 구분하기 위해 [6]에서 레이블 노이즈 분류를 제안합니다. 작성자는 세 가지 다른 유형의 노이즈를 제안합니다: 첫째, 실제 클래스와 인스턴스의 특징 값과는 독립적으로 발생하는 레이블 노이즈, 둘째, 오직 실제 라벨에만 의존하는 레이블 노이즈, 셋째, 잘못된 라벨링 확률이 특징 값에도 영향을 받는 레이블 노이즈입니다. 이 작업에서는 처음 두 가지 유형의 노이즈를 연구합니다. 이론적 관점에서 레이블 노이즈는 일반적으로 특정 사례 [14]를 제외하고 모델의 성능 [10]을 감소합니다. 일반적으로 강력한 메서드는 과적합 방지를 사용하여 레이블 노이즈 [15]를 처리합니다. 분류의 노이즈 효과에 대한 연구는 위성 이미지 분류 [13], 소프트웨어 품질 분류 [4] 및 의료 도메인 분류 [12]와 같은 많은 분야에서 이전에 수행되었습니다. 우리가 아는 한, SBR 분류 문제에서 시끄러운 레이블의 효과의 정확한 정량화를 연구하는 출판 된 작품은 없습니다. 이 시나리오에서는 노이즈 수준, 노이즈 유형 및 성능 저하 간의 정확한 관계가 설정되지 않았습니다. 또한 소음이 있을 때 다양한 분류자의 동작 방식을 이해하는 것이 좋습니다. 더 일반적으로, 우리는 소프트웨어 버그 보고서의 컨텍스트에서 다른 기계 학습 알고리즘의 성능에 시끄러운 데이터 세트의 효과를 체계적으로 연구하는 작업을 인식하지 못합니다.
III. 데이터 세트 설명
데이터 세트는 1,073,149개의 버그 타이틀로 구성되며, 그 중 552,073개는 SBR에 해당하고 NSBR에는 521,076개입니다. 이 데이터는 2015년, 2016년, 2017년 및 2018년 동안 Microsoft의 다양한 팀에서 수집되었습니다. 모든 레이블은 서명 기반 버그 확인 시스템을 통해 획득되었거나 사람에 의해 라벨이 지정되었습니다. 데이터 세트의 버그 제목은 문제의 개요와 함께 약 10개의 단어를 포함하는 매우 짧은 텍스트입니다.
A. 데이터 사전 처리 각 버그 제목을 빈 공백으로 구문 분석하여 토큰 목록을 만듭니다. 각 토큰 목록은 다음과 같이 처리합니다.
파일 경로인 모든 토큰 제거
다음 기호가 있는 분할 토큰: { , (, ), -, }, {, [, ], }
중지 단어, 숫자 문자로만 구성된 토큰 및 전체 모음에서 5회 미만으로 표시되는 토큰을 제거합니다.
IV. 방법론
기계 학습 모델 학습 프로세스는 데이터를 기능 벡터로 인코딩하고 감독되는 기계 학습 분류자를 학습시키는 두 가지 주요 단계로 구성됩니다.
A. 기능 벡터와 기계 학습 기법
첫 번째 부분에서는 [2]에 사용된 것과 같이 frequencyinverse 문서 빈도 알고리즘(TF-IDF)을 사용하여 데이터를 기능 벡터로 인코딩하는 작업이 포함됩니다. TF-IDF은 용어 빈도(TF)와 역 문서 빈도(IDF)를 활용하여 정보 검색의 가중치를 부여하는 기술입니다. 각 단어 또는 용어에는 해당 TF 및 IDF 점수가 있습니다. TF-IDF 알고리즘은 문서에 표시되는 횟수에 따라 해당 단어에 중요도를 할당하며, 더 중요한 것은 키워드가 데이터 집합의 제목 컬렉션 전체에서 얼마나 관련성이 있는지 확인하는 것입니다. 순진한 베이즈(NB), 향상된 의사 결정 트리(AdaBoost) 및 LR(로지스틱 회귀)의 세 가지 분류 기술을 학습하고 비교했습니다. 이러한 기술은 문헌의 전체 보고서를 기반으로 보안 버그 보고서를 식별하는 관련 작업에 대해 성능이 우수한 것으로 표시되었기 때문에 이러한 기술을 선택했습니다. 이러한 결과는 이 세 분류자가 지원 벡터 머신 및 임의 포리스트를 능가하는 예비 분석에서 확인되었습니다. 실험에서는 인코딩 및 모델 학습을 위해 scikit-learn 라이브러리를 활용합니다.
B. 노이즈 유형
이 작업에서 학습된 노이즈는 학습 데이터의 클래스 레이블에서 노이즈를 나타냅니다. 이러한 노이즈가 있으면 학습 프로세스 및 결과 모델이 잘못 레이블이 지정된 예제로 인해 손상됩니다. 클래스 정보에 적용되는 다양한 노이즈 수준의 영향을 분석합니다. 레이블 노이즈 유형은 이전에 문헌에서 다양한 용어를 사용하여 논의되었습니다. 이 작업에서는 분류기에서 두 가지 유형의 레이블 노이즈, 즉 클래스 독립적 레이블 노이즈와 클래스 종속적 레이블 노이즈가 미치는 영향을 분석합니다. 클래스 독립적 레이블 노이즈는 인스턴스를 임의로 선택하고 레이블을 바꿔서 발생하며, 클래스 종속적 노이즈는 각 클래스가 노이즈를 가질 가능성이 다르게 나타나는 경우입니다.
a) 클래스 독립적 노이즈: 클래스 독립적 노이즈는 인스턴스의 실제 클래스와 독립적으로 발생하는 노이즈를 나타냅니다. 이러한 유형의 노이즈에서 pbr 레이블이 잘못 지정되는 확률은 데이터 집합의 모든 인스턴스에 대해 동일합니다. 데이터 집합에서 클래스와 무관하게 각 레이블을 확률 pbr의 확률로 임의로 변경하여 노이즈를 추가합니다.
b) 클래스 종속 노이즈: 클래스 종속 노이즈는 인스턴스의 실제 클래스에 따라 달라지는 노이즈를 나타냅니다. 이러한 유형의 노이즈에서 클래스 SBR의 레이블이 잘못 지정되는 확률은 psbr 클래스 NSBR의 레이블이 잘못 지정되는 확률은 pnsbr. 데이터 집합에 클래스 종속 노이즈를 도입하기 위해, 실제 레이블이 SBR인 데이터 집합의 각 항목을 확률 psbr의 확률로 뒤집습니다. 마찬가지로 NSBR 인스턴스의 클래스 레이블을 확률 pnsbr에 따라 뒤집습니다.
c) 단일 클래스 노이즈: 단일 클래스 노이즈는 클래스 종속 노이즈의 특수한 경우입니다. 여기서 pnsbr = 0 및 psbr> 0입니다. 클래스 독립적 노이즈에 대해 주의할 점은 psbr = pnsbr = pbr입니다.
C. 노이즈 생성
실험에서는 SBR 분류자 학습에서 다양한 노이즈 유형 및 수준의 영향을 조사합니다. 실험에서는 데이터 집합의 25개% 테스트 데이터로 설정하고, 10개는 유효성 검사로, 65개는 학습 데이터로%% 설정했습니다.
다양한 수준의 pbr, psbr 및 pnsbr 대한 학습 및 유효성 검사 데이터 집합에 노이즈를 추가합니다. 테스트 데이터 집합은 수정하지 않습니다. 사용되는 다양한 노이즈 수준은 P = {0.05 × i|0 < i < 10}입니다.
클래스 독립적 노이즈 실험에서 pbr ∈ P의 경우 다음을 수행합니다.
학습 및 유효성 검사 데이터 집합에 대한 노이즈를 생성합니다.
학습 데이터 집합(노이즈가 포함된)을 사용하여 로지스틱 회귀, 나이브 베이즈, AdaBoost 모델을 학습합니다; 유효성 검사 데이터 집합(노이즈가 포함된)을 사용하여 모델을 조정합니다.
테스트 데이터 집합을 사용하여 모델을 테스트합니다(노이즈리스).
클래스 종속 노이즈 실험에서 psbr ∈ P 및 pnsbr ∈ P의 경우 psbr 및 pnsbr모든 조합에 대해 다음을 수행합니다.
학습 및 유효성 검사 데이터 집합에 대한 노이즈를 생성합니다.
학습 데이터 집합(노이즈가 있는)을 사용하여 로지스틱 회귀, 나이브 베이즈 및 AdaBoost 모델을 학습시킵니다.
유효성 검사 데이터 셋(노이즈 포함)을 사용하여 모델을 조정하십시오.
테스트 데이터 집합을 사용하여 모델을 테스트합니다(노이즈리스).
V. 실험적 결과
이 섹션에서는 IV 섹션에 설명된 방법론에 따라 수행된 실험의 결과를 분석합니다.
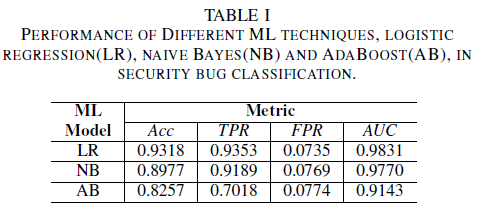
a) 학습 데이터 집합노이즈가 없는 모델 성능: 이 문서의 기여 중 하나는 버그의 제목만 의사 결정을 위한 데이터로 사용하여 보안 버그를 식별하는 기계 학습 모델의 제안입니다. 이렇게 하면 개발 팀이 중요한 데이터의 존재로 인해 버그 보고서를 완전히 공유하지 않으려는 경우에도 기계 학습 모델을 학습할 수 있습니다. 버그 타이틀만 사용하여 학습할 때의 세 가지 기계 학습 모델의 성능을 비교합니다.
로지스틱 회귀 모델은 가장 성능이 뛰어난 분류자입니다. AUC 값이 0.9826이고 FPR 값이 0.0735일 때, 재현율이 0.9353인 가장 높은 성능을 보이는 분류기입니다. 순진한 Bayes 분류자는 0.9779의 AUC와 0.0769의 FPR에 대한 0.9189의 리콜과 함께 로지스틱 회귀 분류자보다 약간 낮은 성능을 제공합니다. AdaBoost 분류자는 이전에 언급한 두 분류자에 비해 성능이 열등합니다. AUC 0.9143을 달성하고, FPR 0.0774에서 재현율 0.7018을 기록합니다. AUC(ROC 곡선) 아래의 영역은 TPR과 FPR 관계의 단일 값으로 요약되므로 여러 모델의 성능을 비교하는 데 좋은 메트릭입니다. 후속 분석에서는 비교 분석을 AUC 값으로 제한합니다.
A. 클래스 노이즈: 단일 클래스
기본적으로 모든 버그가 클래스 NSBR에 할당되고 버그 리포지토리를 검토하는 보안 전문가가 있는 경우에만 클래스 SBR에 버그가 할당되는 시나리오를 상상할 수 있습니다. 이 시나리오는 pnsbr = 0 및 0 < psbr< 0.5라고 가정하는 단일 클래스 실험적 설정에 표시됩니다.
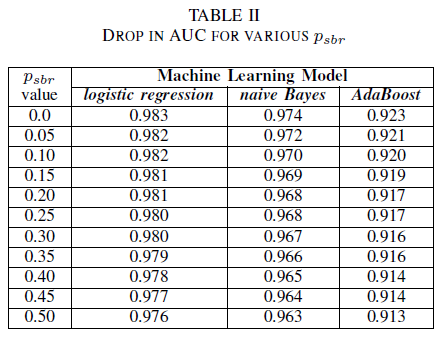
테이블 II에서 세 분류자 모두에 대해 AUC에 매우 작은 영향을 관찰합니다. psbr = 0에서 학습된 모델의 AUC-ROC과 psbr = 0.25인 모델의 AUC-ROC는 로지스틱 회귀에서는 0.003, 나이브 베이즈에서는 0.006, 그리고 AdaBoost에서는 0.006의 차이를 보입니다. psbr = 0.50의 경우 각 모델에 대해 측정된 AUC는 로지스틱 회귀의 경우, psbr = 0으로 학습된 모델보다 0.007, 나이브 베이즈의 경우 0.011, AdaBoost의 경우 0.010 차이가 있습니다. 단일 클래스 노이즈가 있는 상태에서 학습된 로지스틱 회귀 분류자는 AUC 메트릭에서의 변동폭이 가장 작으며, 즉 나이브 베이즈 및 AdaBoost 분류자와 비교할 때 더 강력한 성능을 보입니다.
B. 클래스 노이즈: 클래스에 독립적
클래스 독립적 노이즈로 인해 학습 집합이 손상된 경우의 세 분류자의 성능을 비교합니다. 학습 데이터에서 pbr의 다양한 수준으로 학습된 각 모델의 AUC를 측정합니다.
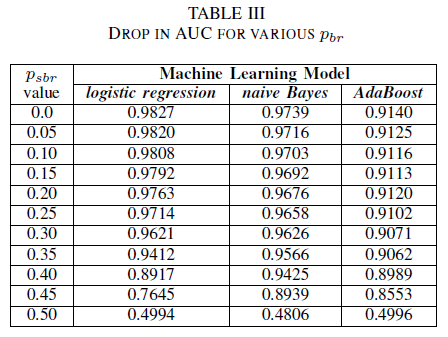
Table III에서는 실험에서 각 노이즈 증가에 대해 AUC-ROC가 감소하는 것을 관찰할 수 있습니다. pbr = 0.25를 사용하여 클래스 독립적 노이즈로 학습된 모델의 AUC-ROC과 비교할 때, 노이즈 없는 데이터로 학습된 모델에서 측정된 AUC-ROC는 로지스틱 회귀의 경우 0.011, 나이브 베이즈의 경우 0.008, AdaBoost의 경우 0.0038 차이가 있습니다. 노이즈 수준이%40보다 낮을 때 레이블 노이즈가 순진한 Bayes 및 AdaBoost 분류자의 AUC에 크게 영향을 미치지 않는 것을 관찰합니다. 반면, 로지스틱 회귀 분류기는 레이블 노이즈 수준이 30%를 넘으면 AUC 측정값에 영향을 경험합니다%.
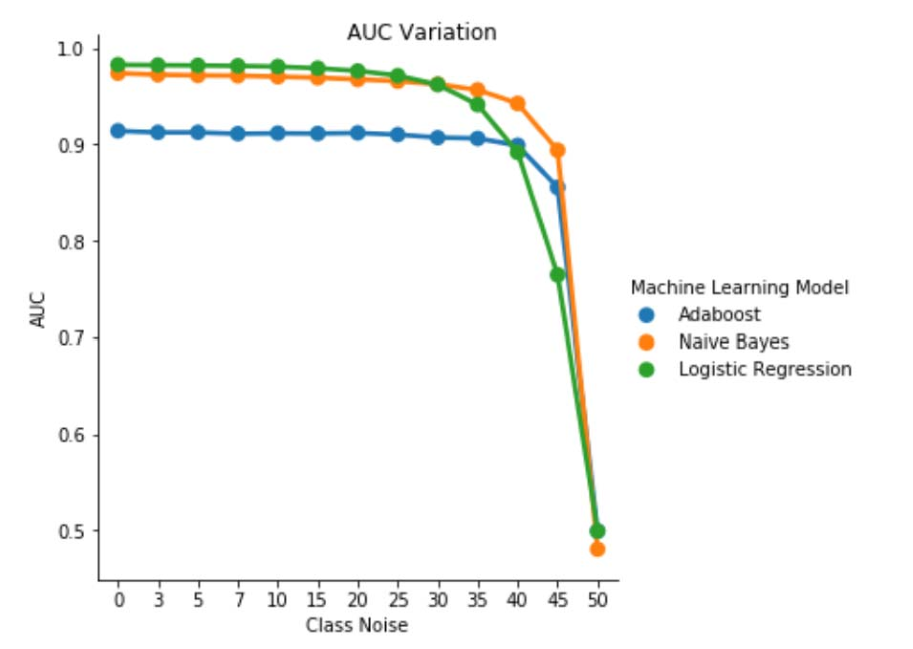
그림 1. 클래스 독립적 노이즈에서의 AUC-ROC 변화 노이즈 수준 pbr =0.5의 경우 분류자는 임의 분류자(예: AUC≈0.5)처럼 작동합니다. 그러나 낮은 노이즈 수준(pbr ≤0.30)의 경우 로지스틱 회귀 학습자가 다른 두 모델에 비해 더 나은 성능을 제공하는 것을 관찰할 수 있습니다. 그러나 0.35≤ pbr ≤0.45 순진한 Bayes 학습자는 더 나은 AUCROC 메트릭을 제공합니다.
C. 클래스 노이즈: 클래스에 의존적
실험의 최종 집합에서는 서로 다른 클래스에 서로 다른 노이즈 수준이 포함된 시나리오를 고려합니다. 즉, psbr ≠ pnsbr. 학습 데이터에서 psbr 및 pnsbr 독립적으로 0.05씩 체계적으로 증가시키고 세 분류자의 동작 변화를 관찰합니다.
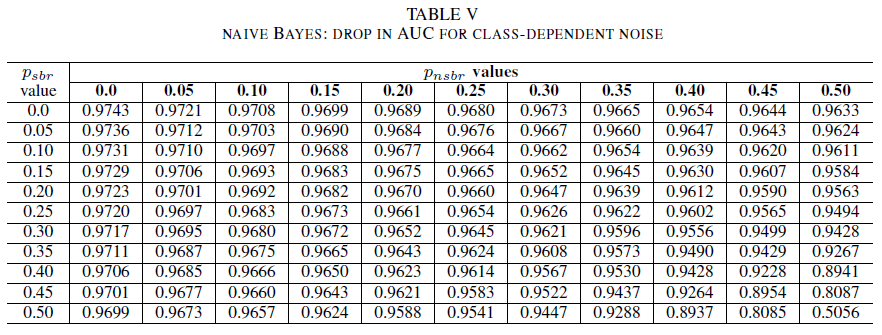
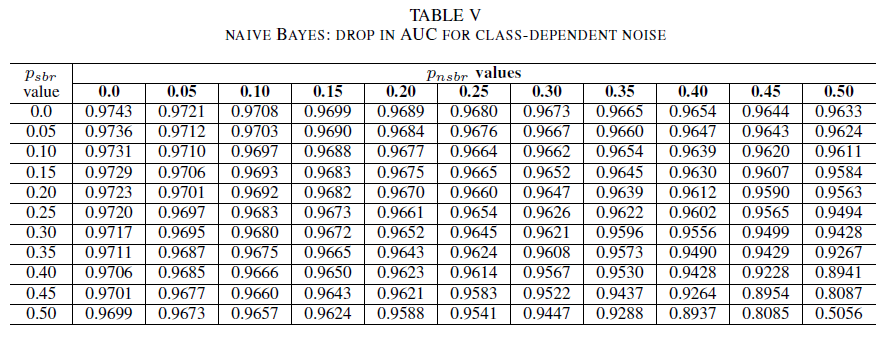
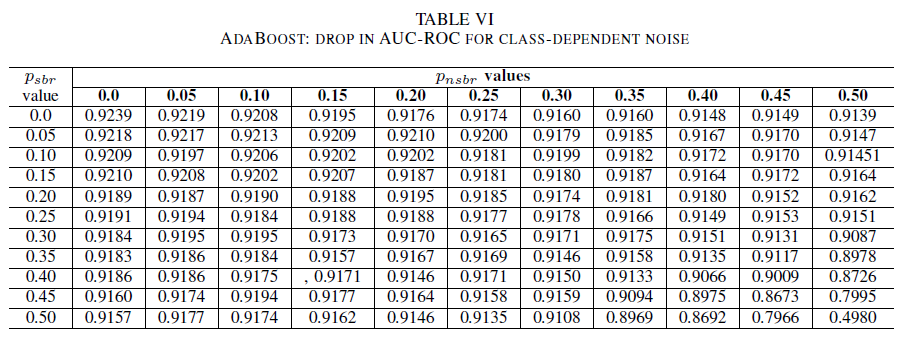
테이블 IV, V, VI는 Table IV의 로지스틱 회귀, Table V의 순진한 Bayes 및 Table VI의 AdaBoost에 대해 각 클래스의 다른 수준에서 노이즈가 증가함에 따라 AUC의 변형을 보여 줍니다. 모든 분류기에서 두 클래스 모두 잡음 수준이 30% 이상일 때 AUC 메트릭에 영향을 미친다는 것을 알 수 있습니다%. 나이브 베이즈는 더 강력하게 작동합니다. 음수 클래스에 시끄러운 레이블이 30% 이하인 경우, 양수 클래스의 50% 레이블이 뒤집히더라도 AUC에 미치는 영향은 매우 작습니다. 이 경우 AUC의 감소는 0.03입니다. AdaBoost는 세 분류자 모두의 가장 강력한 동작을 제시했습니다. AUC의 중요한 변화는 두 클래스에서 노이즈 수준이 45% 이상일 때에만 발생합니다. 이 경우 0.02보다 큰 AUC 감쇠를 관찰하기 시작합니다.
D. 원래 데이터 집합의 잔차 노이즈가 있는 경우
데이터 세트는 서명 기반 자동화 시스템과 사용자 전문가에 의해 레이블이 지정되었습니다. 또한 모든 버그 보고서는 인간 전문가에 의해 추가로 검토되고 폐쇄되었습니다. 데이터 집합의 노이즈 양이 최소화되고 통계적으로 유의하지 않을 것으로 예상하지만, 잔차 노이즈가 존재해도 결론이 무효화되지는 않습니다. 사실적인 예를 위해, 원본 데이터 세트가 모든 항목에 대해 0< p < 1/2로 독립적이고 동일하게 분포된(i.i.d) 클래스 독립적 노이즈에 의해 손상되었다고 가정합니다.
원래 노이즈 위에 확률 pbr i.i.d를 사용하여 클래스 독립적 노이즈를 추가하면 항목당 결과 노이즈는 p∗ = p(1 - pbr )+(1 - p)pbr. 0 < p,pbr< 1/2의 경우 레이블당 실제 노이즈 p∗는 데이터 세트에 인위적으로 추가하는 노이즈 pbr보다 엄격히 큽니다. 따라서 분류자의 성능은 처음에 완전히 노이즈리스 데이터 집합(p = 0)으로 학습된 경우 더 좋을 것입니다. 요약하자면, 실제 데이터 집합에 잔차 노이즈가 있다는 것은 분류자의 노이즈에 대한 복원력이 여기에 제시된 결과보다 더 낫다는 것을 의미합니다. 또한 데이터 집합의 잔차 노이즈가 통계적으로 관련된 경우 분류자의 AUC는 0.5 미만의 노이즈 수준에 대해 0.5(임의 추측)가 됩니다. 우리는 결과에서 그러한 행동을 관찰하지 않습니다.
VI. 결론 및 미래 작업
이 논문에서 우리의 기여는 두 가지입니다.
먼저 버그 보고서 제목만을 기반으로 보안 버그 보고서 분류의 타당성을 보여 줬습니다. 이는 개인 정보 제약 조건으로 인해 전체 버그 보고서를 사용할 수 없는 시나리오에서 특히 관련이 있습니다. 예를 들어 이 경우 버그 보고서에는 암호 및 암호화 키와 같은 개인 정보가 포함되어 있으며 분류자를 학습하는 데 사용할 수 없었습니다. 결과에서는 보고서 제목만 사용할 수 있는 경우에도 SBR 식별을 높은 정확도로 수행할 수 있음을 보여 줍니다. TF-IDF 및 로지스틱 회귀의 조합을 활용하는 분류 모델은 AUC 0.9831에서 수행됩니다.
둘째, 레이블이 잘못된 학습 및 유효성 검사 데이터의 효과를 분석했습니다. 다양한 노이즈 유형 및 노이즈 수준에 대한 견고성 측면에서 잘 알려진 세 가지 기계 학습 분류 기술(순진한 베이즈, 로지스틱 회귀 및 AdaBoost)을 비교했습니다. 세 분류자는 모두 단일 클래스 노이즈에 강력합니다. 학습 데이터의 노이즈는 결과 분류자에서 큰 영향을 미치지 않습니다. AUC의 감소는 50%노이즈 수준에 대해 매우 작습니다 (0.01). 두 클래스에 모두 존재하고 클래스에 독립적인 노이즈가 있을 때 나이브 베이즈와 AdaBoost 모델은 노이즈 수준이 40%보다 큰 데이터 세트로 학습된 경우에만 AUC에서 상당한 변동을 보입니다.
마지막으로 클래스 종속 노이즈는 두 클래스에 35개 이상의% 노이즈가 있는 경우에만 AUC에 크게 영향을 줍니다. AdaBoost는 가장 견고함을 보였습니다. 음수 클래스에 시끄러운 레이블이 % 45개 이하인 경우 긍정 클래스에 50개의% 레이블이 시끄러운 경우에도 AUC의 영향은 매우 작습니다. 이 경우 AUC의 감소는 0.03보다 작습니다. 가장 잘 아는 것은 보안 버그 보고서 식별을 위한 시끄러운 데이터 세트의 효과에 대한 첫 번째 체계적인 연구입니다.
미래 작업
이 문서에서는 보안 버그 식별을 위한 기계 학습 분류자의 성능에 노이즈가 미치는 영향에 대한 체계적인 연구를 시작했습니다. 이 작업에는 다음과 같은 몇 가지 흥미로운 속편이 있습니다. 보안 버그의 심각도 수준을 결정할 때 시끄러운 데이터 세트의 효과 검사; 클래스 불균형이 노이즈에 대해 학습된 모델의 복원력에 미치는 영향을 이해합니다. 데이터 집합에 적대적으로 도입된 노이즈가 미치는 영향을 이해합니다.
참조
[1] 존 안빅, 린든 히우, 게일 C 머피. 누가 이 버그를 수정해야 하나요? 소프트웨어 엔지니어링제28회 국제 컨퍼런스의 절차에서 361-370페이지. ACM, 2006.
[2] 딕샤 벨, 사힐 한다, 아누자 아로라. 순진한 베이와 tf-idf를 사용하여 보안 버그를 식별하고 분석하는 버그 마이닝 도구입니다. ICROIT(최적화, 신뢰성 및 정보 기술), 2014년 국제 학술대회의 294-299페이지. IEEE, 2014.
[3] 니콜라스 베텐부르크, 라훌 프렘라지, 토마스 짐머만, 김성훈. 중복 버그 보고서는 정말 유해한 것으로 간주? 소프트웨어 유지 관리, 2008. ICSM 2008.IEEE 국제 회의, 페이지 337-345. IEEE, 2008.
[4] 안드레스 폴레코, 타기 M 코슈고프타어, 제이슨 반 훌스, 로프턴 불라드. 약한 데이터에 강한 학습자를 식별하기 정보 재사용 및 통합, 2008. IRI 2008. IEEE 국제 회의, 190-195쪽. IEEE, 2008.
[5] Benoıt Frenay.' 기계 학습불확실성 및 레이블 노이즈. 2013년 벨기에 루베인 라뇌브 루베인 가톨릭 대학교 박사 논문.
[6] 베노이트 프레네이와 미셸 벌리슨. 레이블 노이즈가 있는 분류: 설문 조사. 신경망 및 학습 시스템의 IEEE 트랜잭션, 25(5):845-869, 2014.
[7] 마이클 게직, 피트 로텔라, 타오 시. 텍스트 마이닝을 통한 보안 버그 보고서 식별: 산업 사례 연구. 마이닝 MSR(소프트웨어 리포지토리),2010년 제7회 IEEE 실무 회의, 11-20페이지. IEEE, 2010.
[8] 카테리나 Goseva-Popstojanova 제이콥 타요. 감독 및 감독되지 않은 분류를 사용하여 텍스트 마이닝으로 보안 관련 버그 보고서를 식별합니다. 소프트웨어 품질, 신뢰성 및 보안에 관한 2018 IEEE 국제 회의 (QRS), 페이지 344-355, 2018.
[9] 아메드 람칸피, 세르주 데마이어, 에마누엘 기거, 바트 괴탈스. 보고된 버그의 심각도 예측 마이닝 소프트웨어 리포지토리(MSR), IEEE 2010년 제7회작업 회의, 1–10페이지. IEEE, 2010.
[10] 나레쉬 만와니와 PS 사스트리. 위험 최소화 내 소음 허용 범위. IEEE 사이버네틱스 트랜잭션, 43(3):1146–1151, 2013.
[11] G 머피와 D 쿠브라닉. 텍스트 분류를 사용하는 자동 버그 심사 소프트웨어 엔지니어링 & 지식 엔지니어링 16번째 국제 회의의절차. Citeseer, 2004.
[12] 미콜라 페체니츠키, 알렉세이 심발, 세포 푸우로넨, 올렉산드르 페체니즈키. 의료 분야에서 클래스 노이즈와 지도 학습: 특징 추출의 효과. null708-713페이지에서. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre 및 Gerard Dedieu. 위성 이미지 시계열을 사용한 지표면 피복 매핑에서 훈련 클래스 레이블 노이즈가 분류 성능에 미치는 영향. 원격 감지, 9(2): 173, 2017.
[14] PS Sastry, GD Nagendra 및 Naresh Manwani. 반공간에 대한 노이즈 내성 학습을 위한 연속 작업 학습 자동화 팀입니다. 시스템, Man 및 Cybernetics에 대한 IEEE 트랜잭션을 B부(Cybernetics), 40(1):19-28, 2010.
[15] Choh-Man 텅. 노이즈 처리 기술의 비교입니다. FLAIRS 컨퍼런스, 2001년 269-273페이지.
[16] 두미두 위자야세카라, 밀로스 매닉, 마일스 맥퀸. 텍스트 마이닝 버그 데이터베이스를 통한 취약성 식별 및 분류 산업 전자 학회, IECON 2014-제40회 IEEE 연례 회의, 페이지 3612-3618. IEEE, 2014.
[17] 신리 양, 데이비드 로, 차오 황, 신샤, 젠링 선. 불균형 학습 전략을 활용하는 높은 영향 버그 보고서의 자동화된 식별입니다. IEEE 제40회 연례 ,컴퓨터 소프트웨어 및 응용 프로그램 콘퍼런스(COMPSAC), 제1권, 227–232페이지, 2016. IEEE, 2016.
[18] 데칭주, 지준 덩, 젠리, 하이진. 다중 유형 기능 분석을 통해 보안 버그 보고서를 자동으로 식별합니다. 오스트랄라시아 정보 보안 및 개인정보 보호 컨퍼런스, 619-633페이지. 스프링어, 2018.