SQL Server 빅 데이터 클러스터의 스토리지 풀 소개
적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
이 문서에서는 SQL Server 빅 데이터 클러스터에서 SQL Server 스토리지 풀의 역할을 설명합니다. 다음 섹션에서는 스토리지 풀의 아키텍처 및 기능을 설명합니다.
Important
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
스토리지 풀 아키텍처
스토리지 풀은 SQL Server 빅 데이터 클러스터의 로컬 HDFS(Hadoop) 클러스터입니다. 구조화되지 않은 데이터 및 반구조화된 데이터의 영구 스토리지를 제공합니다. Parquet 또는 구분된 텍스트 등의 데이터 파일은 스토리지 풀에 저장할 수 있습니다. 스토리지를 유지하기 위해 풀의 각 Pod에 영구적 볼륨이 연결되어 있습니다. 스토리지 풀 파일은 SQL Server를 통하거나 Apache Knox 게이트웨이를 사용하여 PolyBase를 통해 직접 액세스할 수 있습니다.
기존의 HDFS 설정은 스토리지가 연결된 상용 하드웨어 컴퓨터의 집합으로 구성됩니다. 데이터는 내결함성 및 병렬 처리 활용을 위해 노드 전체에 블록으로 분산됩니다. 클러스터의 노드 중 하나는 이름 노드로 작동하며, 데이터 노드에 있는 파일에 대한 메타데이터 정보를 포함합니다.
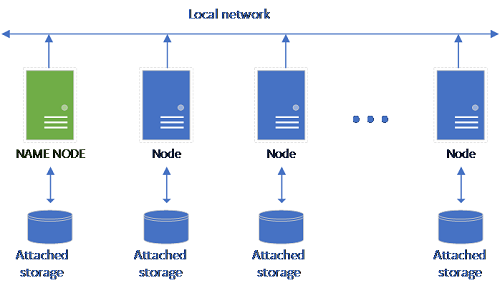
스토리지 풀은 HDFS 클러스터의 멤버인 스토리지 노드로 구성됩니다. 또한 다음 컨테이너를 호스팅하는 각 Pod와 함께 하나 이상의 Kubernetes Pod를 실행합니다.
- 영구 볼륨(스토리지)에 연결된 Hadoop 컨테이너입니다. 이 형식의 모든 컨테이너는 함께 Hadoop 클러스터를 형성합니다. Hadoop 컨테이너 내에는 주문형 Apache Spark 작업자 프로세스를 만들 수 있는 YARN 노드 관리자 프로세스가 있습니다. Spark 헤드 노드는 Hive 메타스토어, Spark 기록 및 YARN 작업 기록 컨테이너를 호스트합니다.
- OpenRowSet 기술을 사용하여 HDFS에서 데이터를 읽는 SQL Server 인스턴스.
- 메트릭 데이터를 수집하기 위한
collectd. - 로그 데이터 수집을 위한
fluentbit.
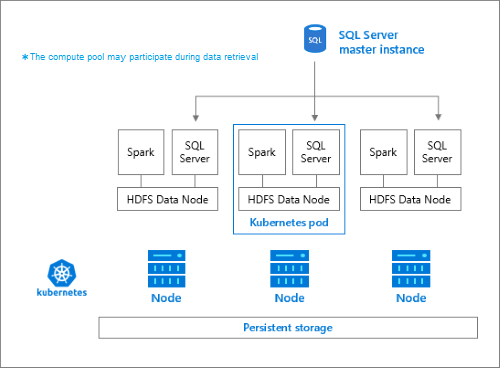
책임
스토리지 노드에서 담당하는 작업은 다음과 같습니다.
- Apache Spark를 통한 데이터 수집.
- HDFS의 데이터 스토리지(Parquet 및 구분된 텍스트 형식). HDFS 데이터는 SQL BDC의 모든 스토리지 노드에 분산되기 때문에 HDFS는 데이터 지속성도 제공합니다.
- HDFS 및 SQL Server 엔드포인트를 통한 데이터 액세스.
데이터 액세스
스토리지 풀의 데이터에 액세스하는 주요 방법은 다음과 같습니다.
- Spark 작업.
- SQL Server 외부 테이블을 활용하면 PolyBase 컴퓨팅 노드 및 HDFS 노드에서 실행되는 SQL Server 인스턴스를 사용하여 데이터를 쿼리할 수 있습니다.
다음을 사용하여 HDFS와 상호 작용할 수도 있습니다.
- Azure Data Studio.
- Azure Data CLI(
azdata). - kubectl을 사용하여 Hadoop 컨테이너에 명령을 실행합니다.
- HDFS http 게이트웨이.
다음 단계
SQL Server 빅 데이터 클러스터에 대한 자세한 내용은 다음 리소스를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기