Spark 기록 서버에서SQL Server 빅 데이터 클러스터의 Spark 애플리케이션 디버그 및 진단
적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
이 문서에서는 확장된 Spark 기록 서버를 사용하여 SQL Server 빅 데이터 클러스터에서 Spark 애플리케이션을 디버그하고 진단하는 방법에 대한 지침을 제공합니다. 이러한 디버그 및 진단 기능은 Spark 기록 서버에 기본 제공되며 Microsoft에서 제공합니다. 확장에는 데이터 탭, 그래프 탭, 진단 탭이 포함되어 있습니다. 데이터 탭에서는 Spark 작업의 입력 및 출력 데이터를 확인할 수 있습니다. 그래프 탭에서는 데이터 흐름을 확인하고 작업 그래프를 다시 재생할 수 있습니다. 진단 탭에서는 데이터 기울이기, 시간 기울이기 및 실행기 사용 현황 분석을 참조할 수 있습니다.
Spark 기록 서버에 대한 액세스 권한 얻기
오픈 소스의 Spark 기록 서버 사용자 환경이 작업 그래프의 작업별 데이터 및 대화형 시각화와 빅 데이터 클러스터의 데이터 흐름을 포함하는 정보를 사용하여 향상되었습니다.
URL을 통해 Spark 기록 서버 웹 UI 열기
다음 URL로 이동하여 Spark 기록 서버를 열고 <Ipaddress> 및 <Port>를 빅 데이터 클러스터 관련 정보로 바꿉니다. SQL Server 2019 CU 5 이전에 배포된 클러스터에서 기본 인증(사용자 이름/비밀번호) 빅 데이터 클러스터를 설정한 경우 게이트웨이(Knox) 엔드포인트에 로그인하라는 메시지가 표시되면 사용자 루트 를 제공해야 합니다. SQL Server 빅 데이터 클러스터 배포를 참조하세요. SQL Server 2019(15.x) CU 5부터 기본 인증을 사용하여 새 클러스터를 배포하는 경우 게이트웨이를 비롯한 모든 엔드포인트는 AZDATA_USERNAME 및 AZDATA_PASSWORD를 사용합니다. CU 5로 업그레이드된 클러스터의 엔드포인트는 게이트웨이 엔드포인트에 연결하기 위해 사용자 이름으로 root를 계속 사용합니다. 이 변경 내용은 Active Directory 인증을 사용하는 배포에는 적용되지 않습니다. 릴리스 정보에서 게이트웨이 엔드포인트를 통해 서비스에 액세스하기 위한 자격 증명을 참조하세요.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Spark 기록 서버 웹 UI는 다음과 같습니다.
Spark 기록 서버의 데이터 탭
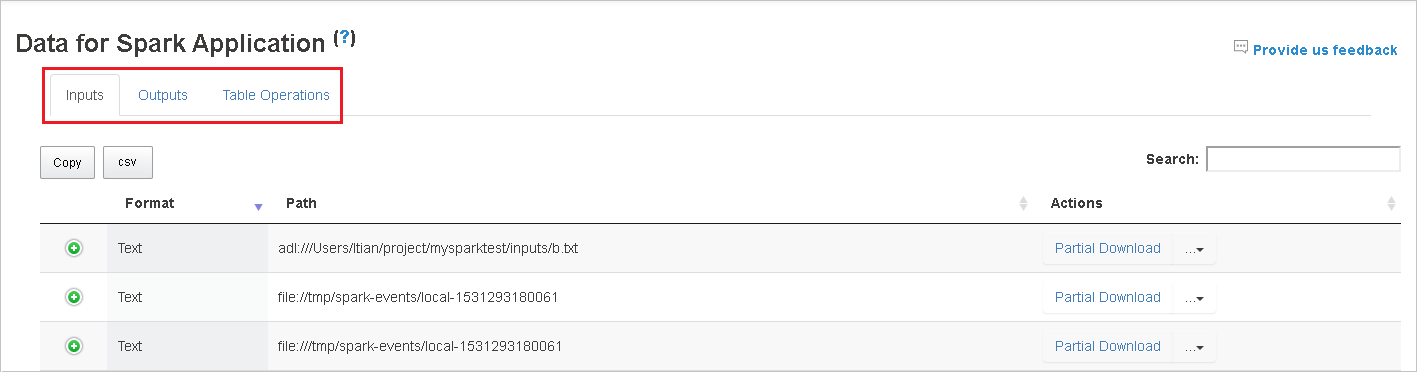
작업 ID를 선택하고 도구 메뉴에서 데이터를 선택하여 데이터 뷰를 표시합니다.
탭을 따로 선택하여 입력, 출력 및 테이블 작업을 확인합니다.
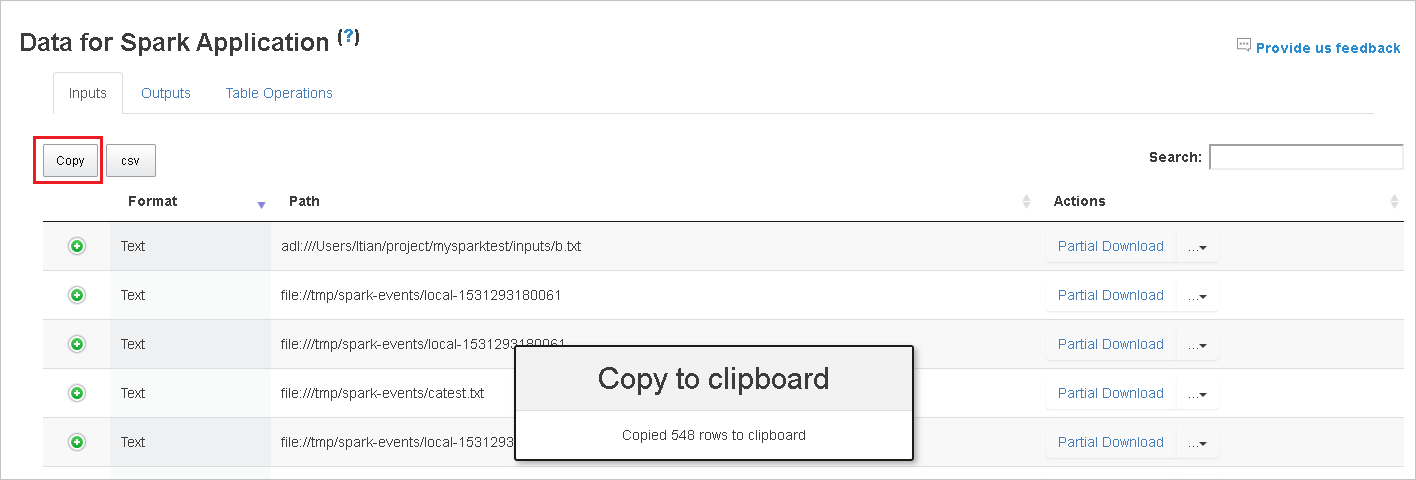
복사 버튼을 클릭하여 모든 행을 복사합니다.
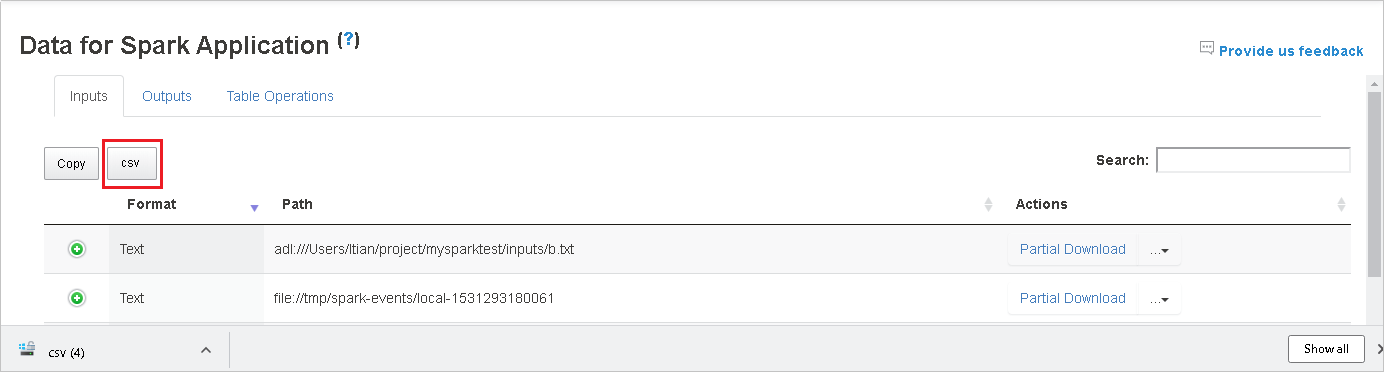
csv 버튼을 클릭하여 모든 데이터를 CSV 파일로 저장합니다.
검색 필드에 키워드를 입력하여 검색하면 검색 결과가 즉시 표시됩니다.
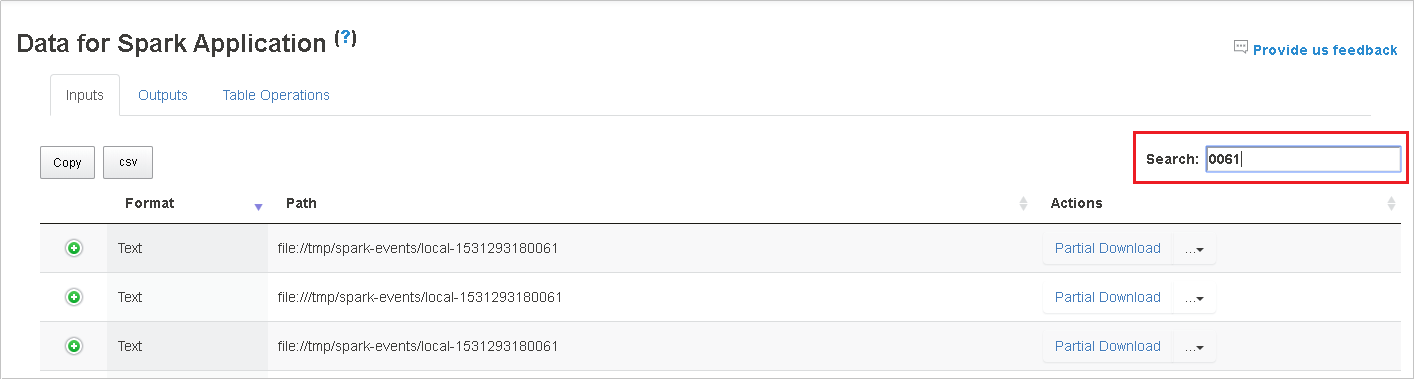
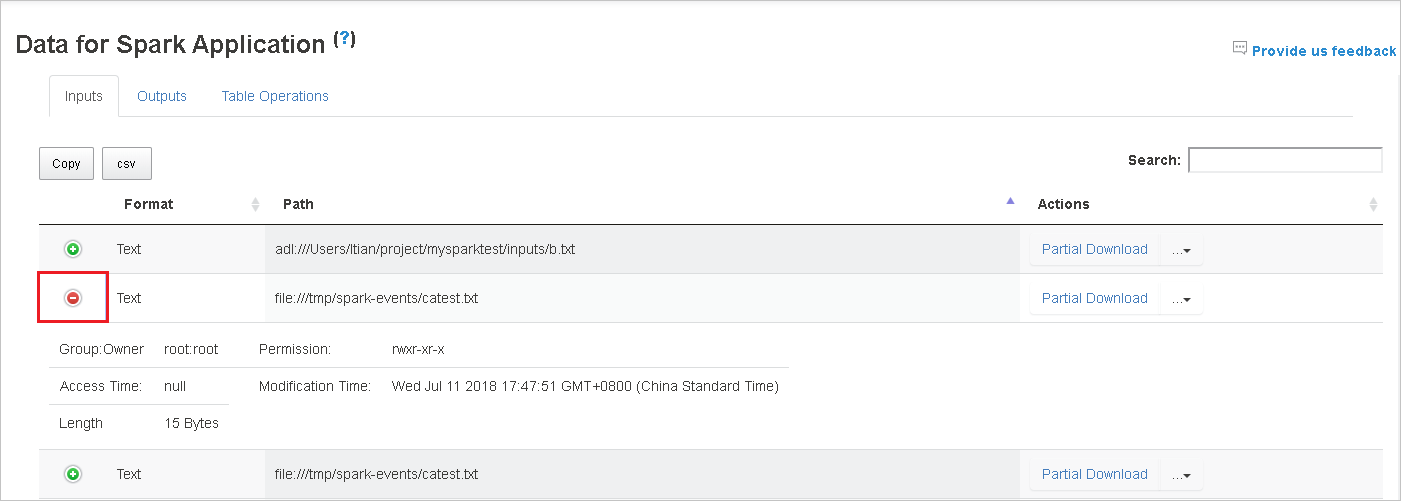
열 머리글을 클릭하여 표를 정렬하고 더하기 기호를 클릭하여 행을 펼쳐 자세한 내용을 표시하거나 빼기 기호를 클릭하여 행을 접습니다.
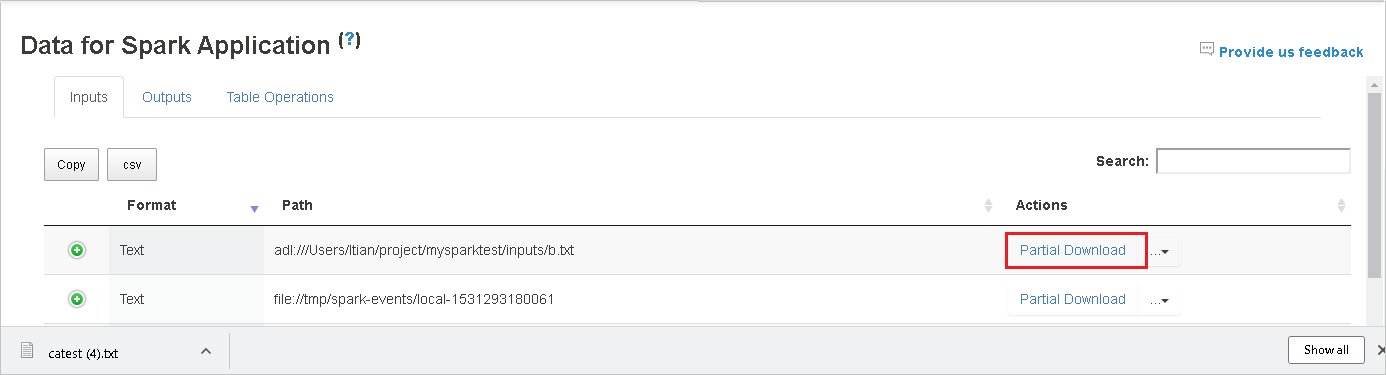
오른쪽에 있는 부분 다운로드 버튼을 클릭하여 하나의 파일을 다운로드하면 선택한 파일을 로컬 위치에 다운로드합니다. 파일이 더 이상 없는 경우 새 탭이 열리고 오류 메시지가 표시됩니다.
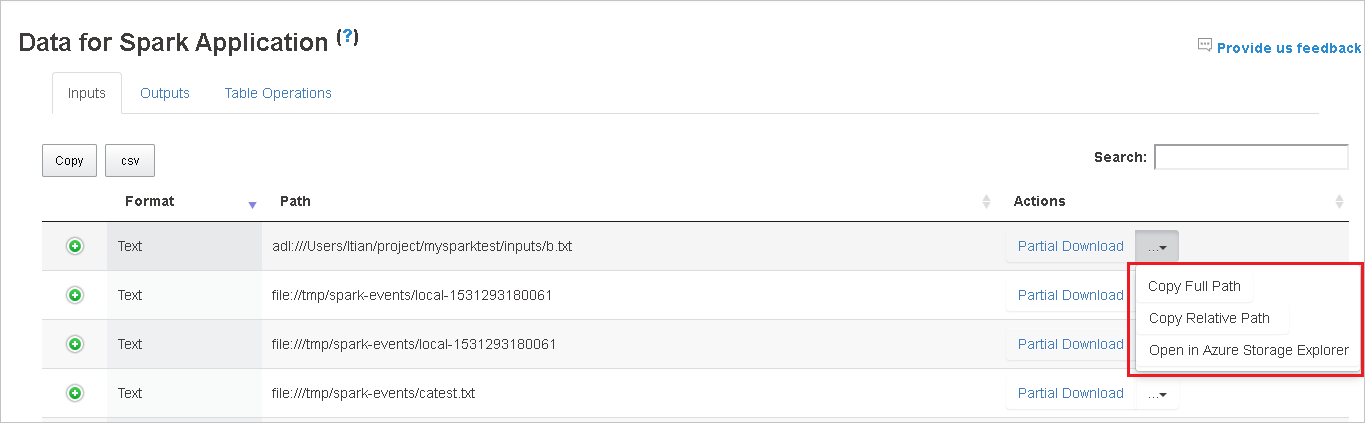
다운로드 메뉴에서 펼쳐지는 전체 경로 복사 또는 상대 경로 복사를 선택하여 전체 경로 또는 상대 경로를 복사합니다. Azure Data Lake Storage 파일의 경우 Azure Storage Explorer에서 열기는 Azure Storage Explorer를 시작합니다. 그리고 로그인할 때 정확한 폴더를 찾습니다.
한 페이지에 표시할 행이 너무 많으면 표 아래의 숫자를 클릭하여 페이지를 탐색합니다.

데이터 옆에 있는 물음표를 마우스로 가리켜 도구 설명을 표시하거나, 물음표를 클릭하여 추가 정보를 가져옵니다.
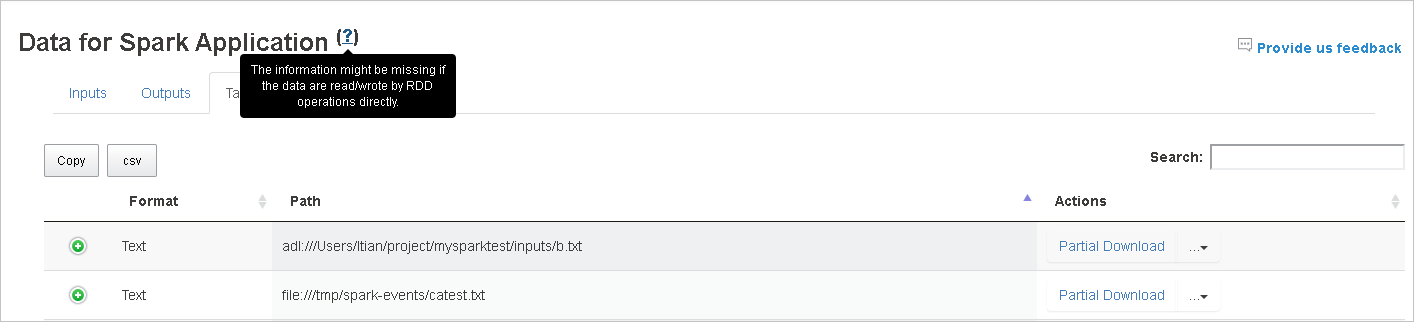
피드백 보내기를 클릭하여 문제에 관한 피드백을 보냅니다.
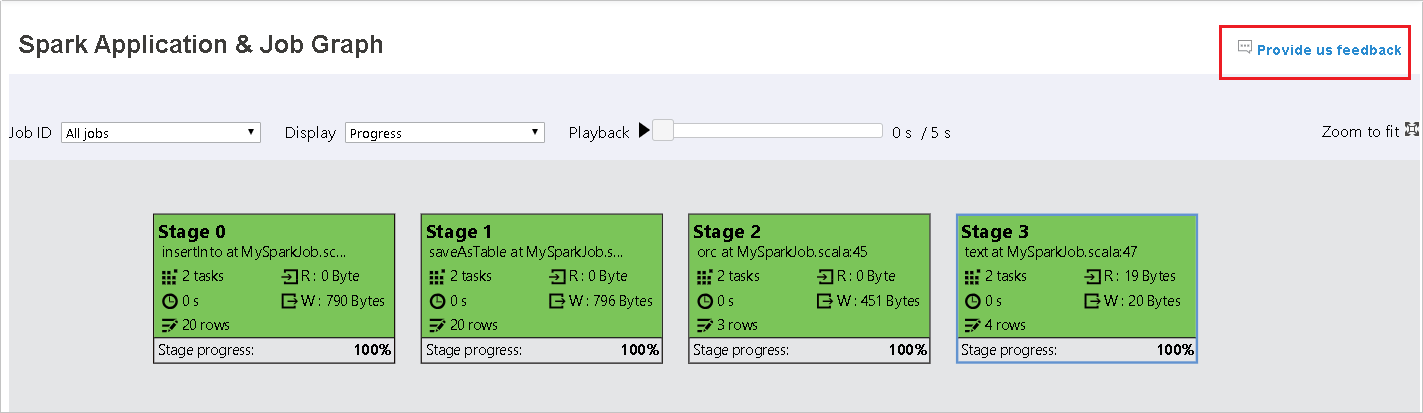
Spark 기록 서버의 그래프 탭
작업 ID를 선택하고 도구 메뉴에서 그래프를 선택하여 작업 그래프 뷰를 표시합니다.
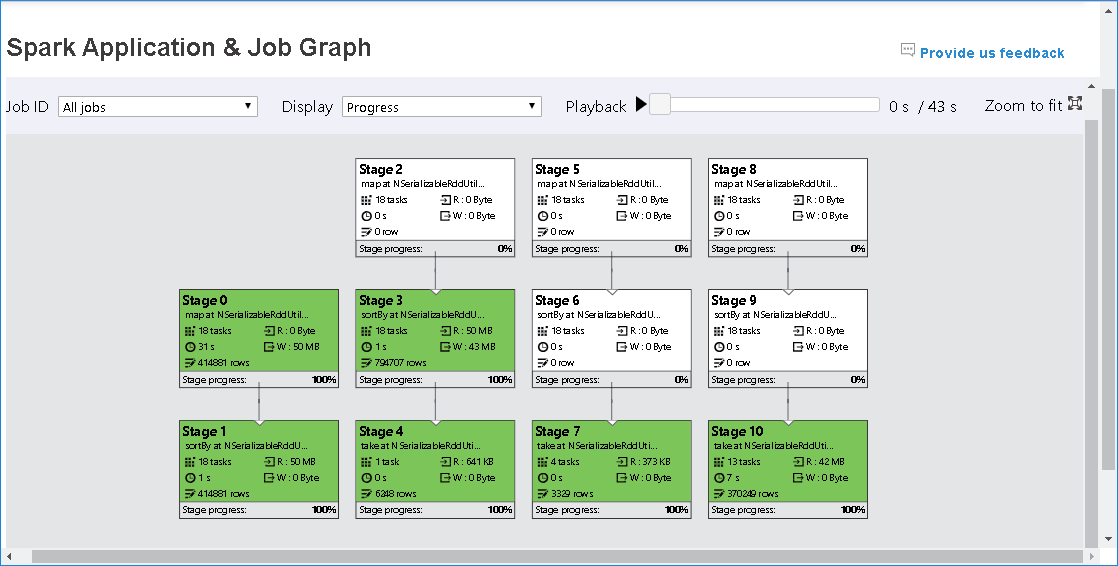
생성된 작업 그래프를 통해 작업의 개요를 확인합니다.
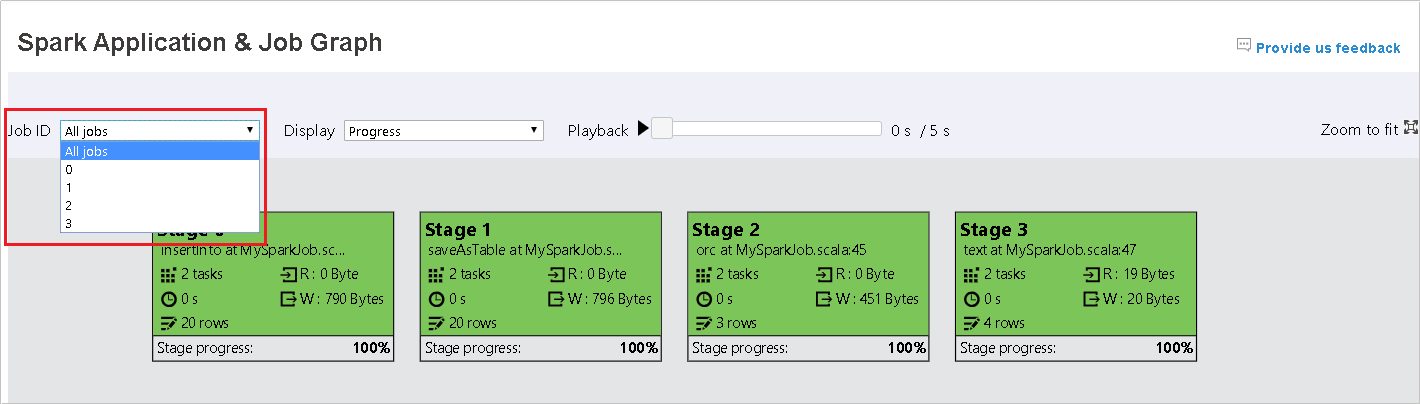
기본적으로 모든 작업이 표시되며, 작업 ID를 기준으로 필터링할 수 있습니다.
진행률을 기본값으로 둡니다. 사용자는 표시 드롭다운 목록에서 읽기 또는 작성을 선택하여 데이터 흐름을 확인할 수 있습니다.
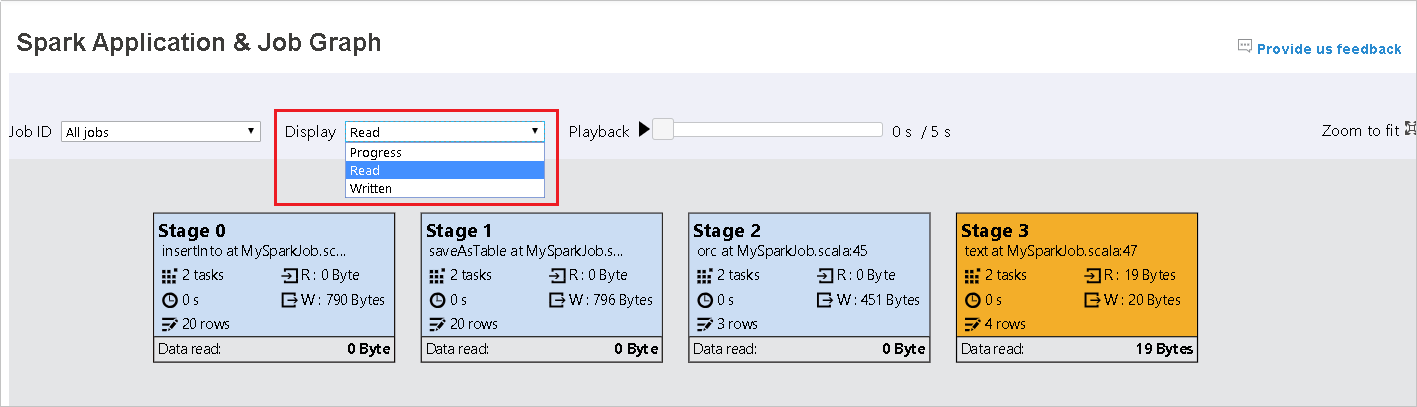
그래프 노드는 열 지도를 보여 주는 색으로 표시됩니다.

재생 버튼을 클릭하여 작업을 재생하고 중지 버튼을 클릭하여 언제든지 중지합니다. 작업은 재생 시 다양한 상태를 표시하기 위해 색상으로 표시됩니다.
- 성공의 경우 녹색: 작업이 성공적으로 완료되었습니다.
- 다시 시도의 경우 주황색: 실패했지만 작업의 최종 결과에는 영향을 미치지 않는 작업의 인스턴스입니다. 해당 작업에는 중복 또는 다시 시도 인스턴스가 있었으며, 나중에 성공할 수 있습니다.
- 실행 중의 경우 파란색: 작업이 실행 중입니다.
- 대기 중 또는 건너뜀의 경우 흰색: 작업이 실행을 위해 대기 중이거나 단계를 건너뛰었습니다.
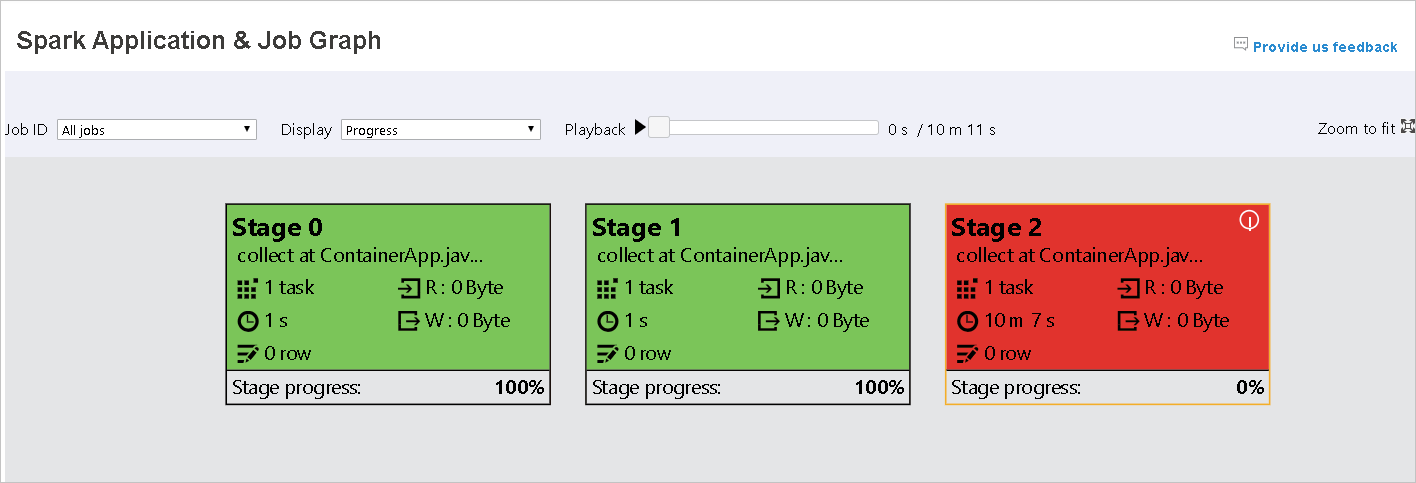
- 실패의 경우 빨간색: 작업이 실패했습니다.
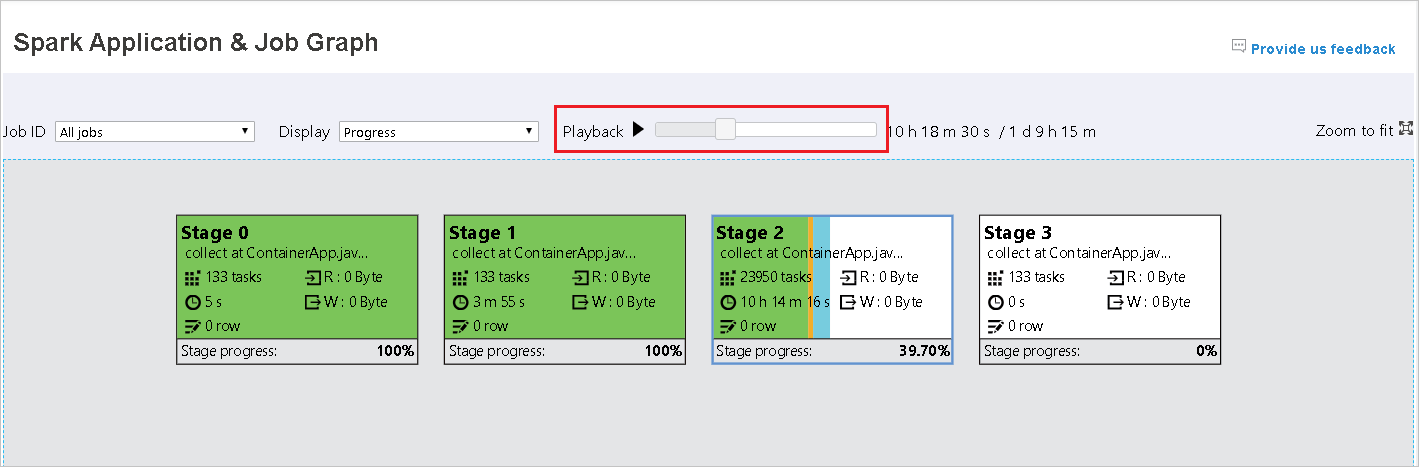
건너뛴 단계는 흰색으로 표시됩니다.
참고 항목
각 작업을 재생할 수 있습니다. 완료되지 않은 작업에는 재생이 지원되지 않습니다.
마우스를 스크롤하여 작업 그래프를 확대 및 축소하거나 크기에 맞게를 선택하여 화면에 맞게 조정합니다.
실패한 작업이 있는 경우 그래프 노드에 커서를 올려 도구 설명을 확인하고 단계를 클릭하여 단계 페이지를 엽니다.
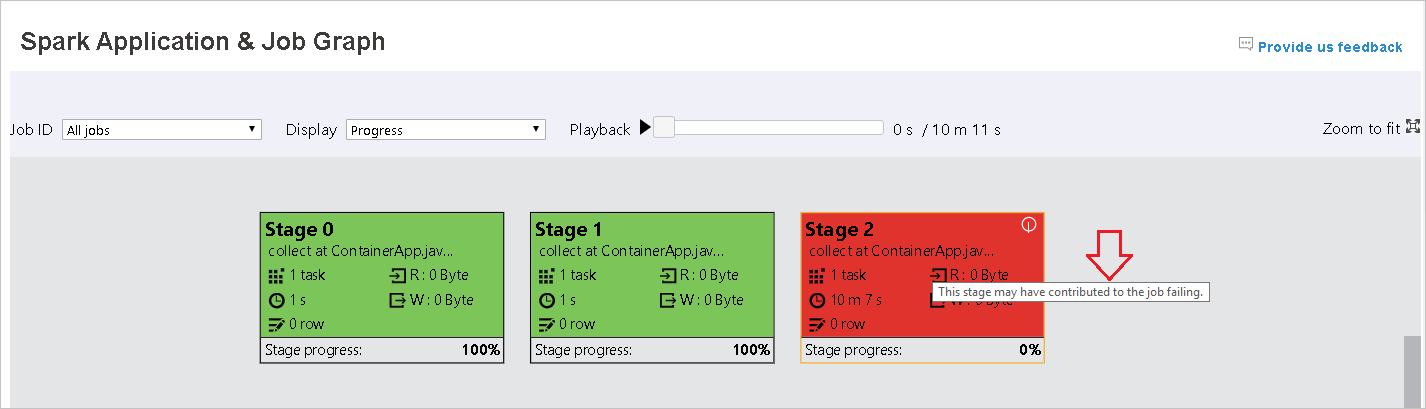
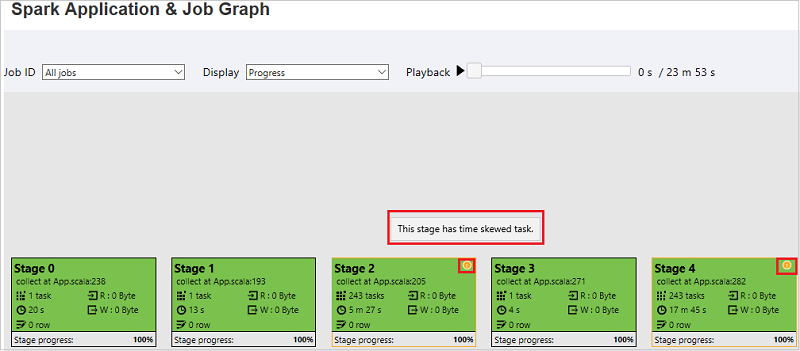
작업 그래프 탭에서 아래 조건을 충족하는 작업이 있을 경우 단계에 도구 설명 및 작은 아이콘이 표시됩니다.
- 데이터 기울이기: 데이터 읽기 크기 > 이 단계에 속한 모든 작업의 평균 데이터 읽기 크기 * 2 및 데이터 읽기 크기 > 10MB
- 시간 기울이기: 실행 시간 > 이 단계에 속한 모든 작업의 평균 실행 시간 * 2 및 실행 시간 > 2분
작업 그래프 노드에는 각 단계에 대한 다음 정보가 표시됩니다.
- ID.
- 이름 또는 설명
- 총 작업 수
- 읽은 데이터: 입력 크기 및 랜덤 보기 읽기 크기의 합계
- 데이터 쓰기: 출력 크기와 무작위 쓰기 크기의 합계
- 실행 시간: 첫 번째 시도 시작 시간과 마지막 시도 완료 시간 사이의 시간
- 행 개수: 입력 레코드, 출력 레코드, 무작위 읽기 레코드 및 무작위 쓰기 레코드의 합계
- 진행률
참고 항목
기본적으로 작업 그래프 노드에는 각 단계의 마지막 시도 정보(단계 실행 시간 제외)가 표시되지만 재생 중에는 그래프 노드에 각 시도의 정보가 표시됩니다.
참고 항목
읽기 및 쓰기 데이터 크기에는 1MB = 1000KB = 1000 * 1000바이트를 사용합니다.
피드백 보내기를 클릭하여 문제에 관한 피드백을 보냅니다.
Spark 기록 서버의 진단 탭
작업 ID를 선택하고 도구 메뉴에서 진단을 클릭하여 작업 진단 뷰를 표시합니다. 진단 탭에는 데이터 기울이기, 시간 기울이기 및 실행기 사용량 분석이 포함되어 있습니다.
각 탭을 선택하여 데이터 기울이기, 시간 기울이기 및 실행기 사용량 분석을 확인합니다.
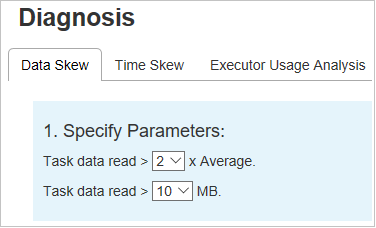
데이터 기울이기
데이터 기울이기 탭을 클릭하면 지정한 매개 변수에 따라 해당 기울이기 작업이 표시됩니다.
매개 변수 지정 - 첫 번째 섹션에는 데이터 기울이기를 검색하는 데 사용되는 매개 변수가 표시됩니다. 기본 제공 규칙은 읽은 작업 데이터가 읽은 작업 데이터 평균의 3배보다 크고 읽은 작업 데이터가 10MB를 초과하는 것입니다. 기울어진 작업에 대한 고유한 규칙을 정의하려면 매개 변수를 선택하면 됩니다. 기울어진 단계 및 기울이기 문자 섹션이 그에 따라 새로 고쳐집니다.
기울어진 단계 - 두 번째 섹션에는 위에 지정된 조건을 충족하는 기울어진 작업이 있는 단계가 표시됩니다. 단계에 기울어진 작업이 두 개 이상 있는 경우 기울어진 단계 테이블에는 가장 많이 기울어진 작업(예: 데이터 기울이기 데이터가 가장 큰 작업)만 표시됩니다.
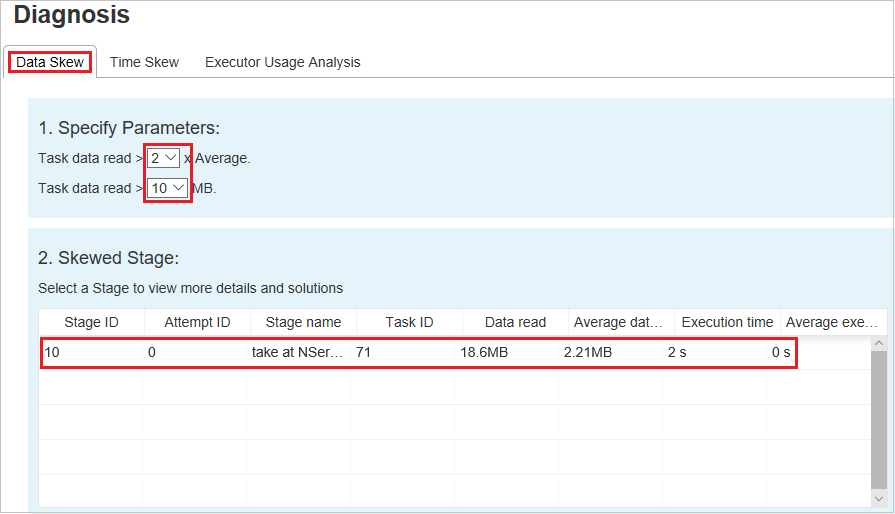
기울이기 차트 - 기울이기 단계 테이블에서 행을 선택하면 기울이기 차트에 데이터 읽기 및 실행 시간을 기준으로 더 많은 작업 분포 정보가 표시됩니다. 기울어진 작업은 빨간색으로 표시되고 일반 작업은 파란색으로 표시됩니다. 성능을 고려하여 차트에는 최대 100개의 샘플 작업만 표시됩니다. 작업 정보는 오른쪽 아래 패널에 표시됩니다.
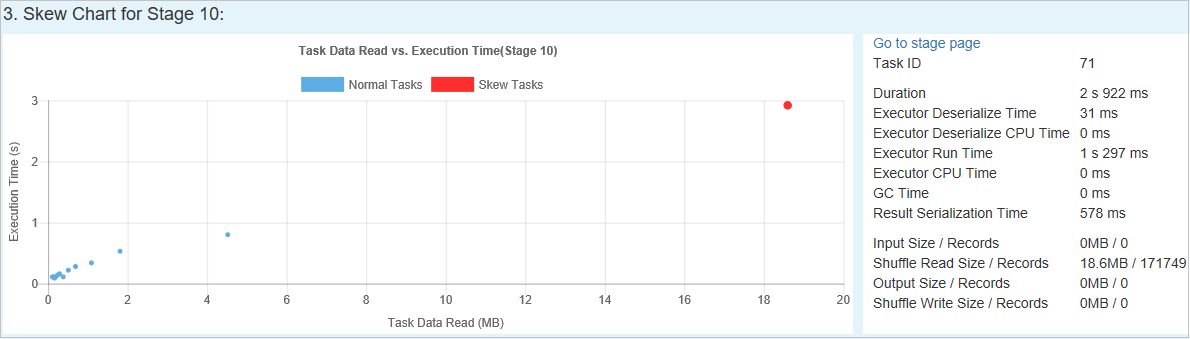
시간 기울이기
시간 기울이기 탭에는 작업 실행 시간을 기준으로 기울어진 작업이 표시됩니다.
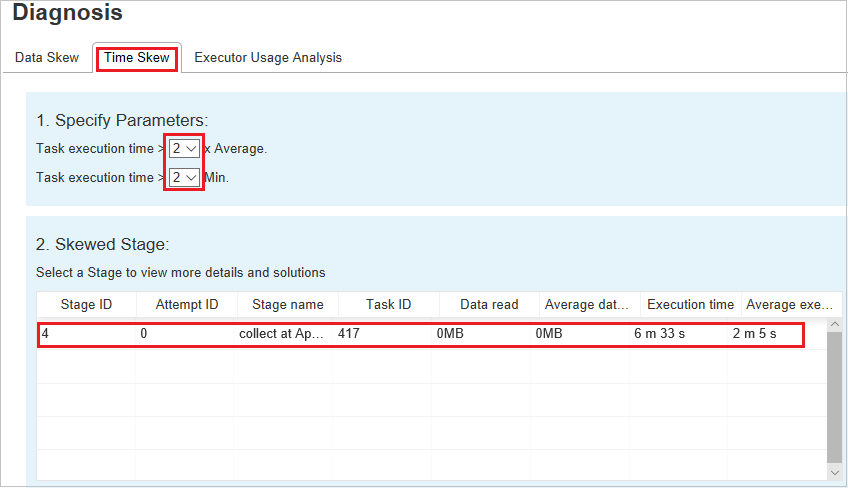
매개 변수 지정 - 첫 번째 섹션에는 시간 기울이기를 검색하는 데 사용되는 매개 변수가 표시됩니다. 시간 기울이기를 검색하는 기본 기준은 작업 실행 시간이 평균 실행 시간의 3배보다 크고 작업 실행 시간이 30초를 초과하는 것입니다. 필요에 따라 매개 변수를 변경할 수 있습니다. 기울어진 작업 및 기울이기 차트에는 위의 데이터 기울이기 탭과 마찬가지로 해당 단계 및 작업 정보가 표시됩니다.
시간 기울이기를 클릭하면 매개 변수 지정 섹션에 설정된 매개 변수에 따라 필터링된 결과가 기울어진 단계 섹션에 표시됩니다. 기울어진 단계 섹션에서 한 항목을 클릭하면 해당 차트가 section3에 초안으로 작성되고 작업 정보가 오른쪽 아래 패널에 표시됩니다.
실행기 사용량 분석
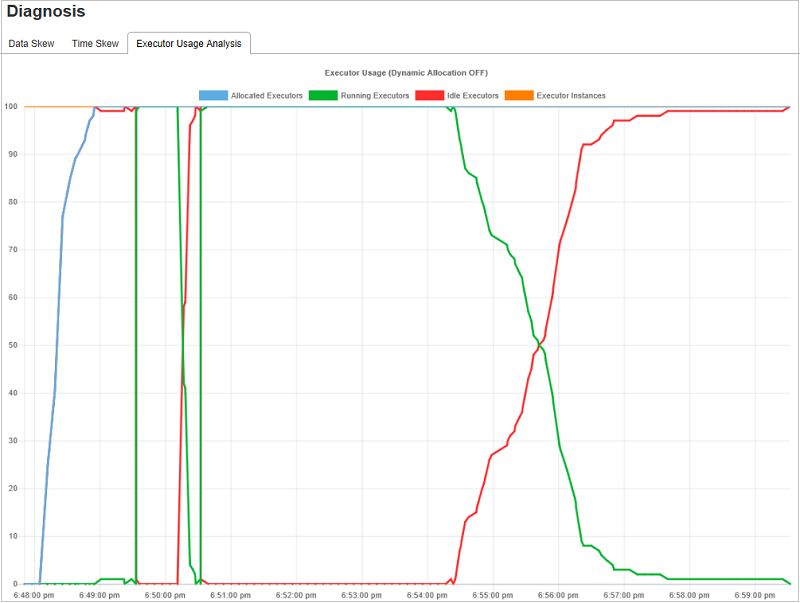
실행기 사용량 그래프는 Spark 작업 실제 실행기 할당 및 실행 상태를 시각화합니다.
실행기 사용량 분석을 클릭한 다음, 실행기 사용량에 대한 네 가지 유형 곡선의 초안을 작성합니다. 여기에는 할당된 실행기, 실행 중인 실행기, 유휴 실행기 및 최대 실행기 인스턴스가 포함됩니다. 할당된 실행기와 관련하여 각 “실행기 추가됨” 또는 “실행기 제거됨” 이벤트는 할당된 실행기를 늘리거나 줄입니다. 자세한 비교를 위해 “작업” 탭에서 “이벤트 타임라인”을 확인할 수 있습니다.
색상 아이콘을 클릭하여 모든 초안에서 해당 콘텐츠를 선택하거나 선택 취소합니다.
Spark/Yarn 로그
Spark 기록 서버 외에도 Spark 및 Yarn에 대한 로그를 다음에서 각각 찾을 수 있습니다.
- Spark 이벤트 로그: hdfs:///system/spark-events
- Yarn 로그: hdfs:///tmp/logs/root/logs-tfile
참고: 두 로그의 기본 보존 기간은 7일입니다. 보존 기간을 변경하려면 Apache Spark 및 Apache Hadoop 구성 페이지를 참조하세요. 위치는 변경할 수 없습니다.
알려진 문제
Spark 기록 서버에는 다음과 같은 알려진 문제가 있습니다.
현재는 Spark 3.1 클러스터(CU13+) 및 Spark 2.4(CU12-)에 대해서만 작동합니다.
RDD를 사용하는 입출력 데이터는 데이터 탭에 표시되지 않습니다.
다음 단계
- SQL Server 빅 데이터 클러스터 시작
- Spark 설정 구성
- Spark 설정 구성
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기