pyspark Notebook 문제 해결
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
이 문서에서는 실패하는 pyspark Notebook 문제를 해결하는 방법을 보여 줍니다.
Azure Data Studio에서 PySpark 작업의 아키텍처
Azure Data Studio는 SQL Server 빅 데이터 클러스터의 livy 끝점과 통신합니다.
livy 끝점은 빅 데이터 클러스터 내에서 spark-submit 명령을 실행합니다. 각 spark-submit 명령에는 YARN을 클러스터 리소스 관리자로 지정하는 매개 변수가 있습니다.
PySpark 세션의 문제를 효율적으로 해결하려면 각 계층(Livy, YARN 및 Spark) 내에서 로그를 수집하고 검토합니다.
이 문제 해결 단계를 수행하려면 다음이 필요합니다.
- Azure Data CLI(
azdata)가 설치되고 구성이 사용자의 클러스터로 올바르게 설정되었습니다. - Linux 명령 실행 및 일부 로그 문제 해결 기술에 익숙해져야 합니다.
문제 해결 단계
pyspark에서 스택 및 오류 메시지를 검토합니다.Notebook의 첫 번째 셀에서 애플리케이션 ID를 가져옵니다. 이 애플리케이션 ID를 사용하여
livy, YARN 및 Spark 로그를 조사합니다.SparkContext는 이 YARN 애플리케이션 ID를 사용합니다.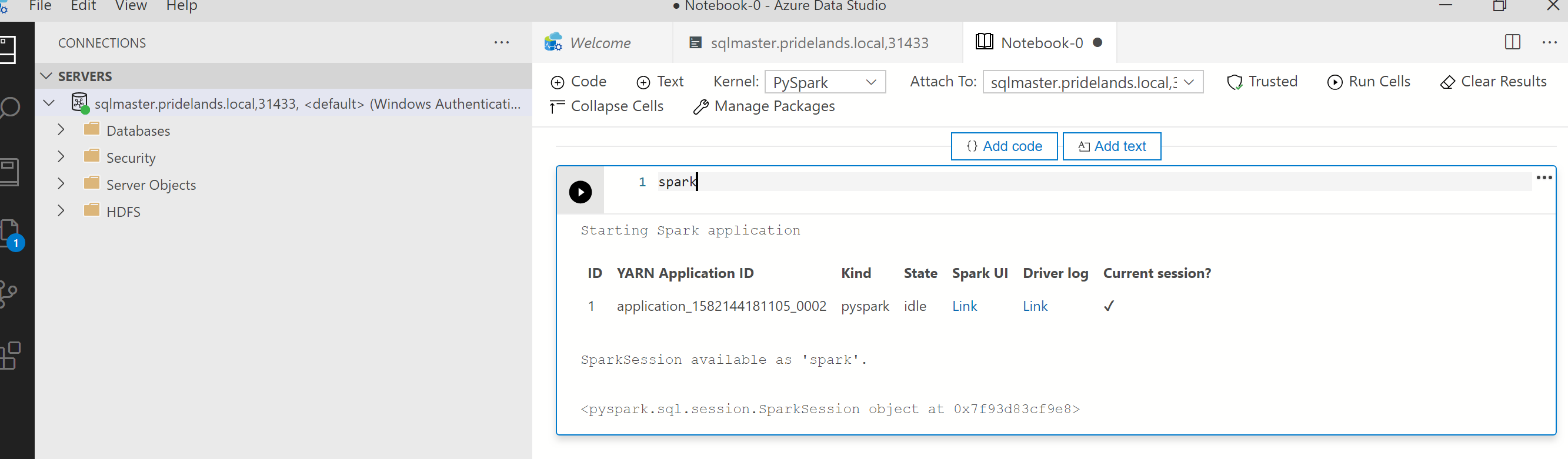
로그를 가져옵니다.
azdata bdc debug copy-logs를 사용하여 조사다음 예제에서는 빅 데이터 클러스터 끝점을 연결하여 로그를 복사합니다. 실행하기 전에 예제에서 다음 값을 업데이트합니다.
<ip_address>: 빅 데이터 클러스터 끝점<username>: 빅 데이터 클러스터 사용자 이름<namespace>: 클러스터의 Kubernetes 네임스페이스<folder_to_copy_logs>: 로그를 복사할 로컬 폴더 경로
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>예제 출력
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.Livy 로그를 검토합니다. Livy 로그는
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log에 있습니다.- pyspark Notebook 첫 번째 셀에서 YARN 애플리케이션 ID를 검색합니다.
ERR상태를 검색합니다.
YARN ACCEPTED상태인 Livy 로그의 예입니다. Livy는 yarn 애플리케이션을 제출했습니다.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>YARN UI 검토
Azure Data Studio 빅 데이터 클러스터 관리 대시보드에서 YARN 엔드포인트 URL을 가져오거나
azdata bdc endpoint list –o table을 실행합니다.예시:
azdata bdc endpoint list -o table반품
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy https애플리케이션 ID와 개별 application_master 및 컨테이너 로그를 확인합니다.
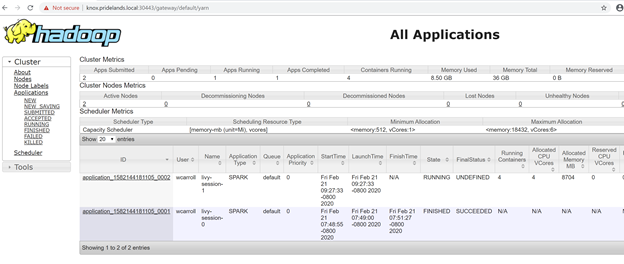
YARN 애플리케이션 로그를 검토합니다.
앱의 애플리케이션 로그를 가져옵니다. 예를 들어
sparkhead-0Pod에 연결하는 데kubectl를 사용합니다.kubectl exec -it sparkhead-0 -- /bin/bash그런 다음, 오른쪽
application_id를 사용하여 해당 셸 내에서 이 명령을 실행합니다.yarn logs -applicationId application_<application_id>오류 또는 스택을 검색합니다.
hdfs에 대한 사용 권한 오류의 예시입니다. Java 스택에서
Caused by:를 찾습니다YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xSPARK UI를 검토합니다.
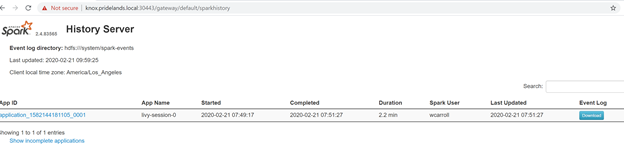
단계 작업을 드릴다운하여 오류를 찾습니다.
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기