자습서: SQL Server 빅 데이터 클러스터에서 HDFS 쿼리
적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
이 자습서에서는 SQL Server 2019 빅 데이터 클러스터에 HDFS 데이터를 쿼리하는 방법을 보여줍니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 빅 데이터 클러스터에서 HDFS 데이터를 가리키는 외부 테이블을 만듭니다.
- 해당 데이터를 마스터 인스턴스의 고가치 데이터와 조인합니다.
팁
원하는 경우 이 자습서의 명령에 대한 스크립트를 다운로드하고 실행할 수 있습니다. 자세한 내용은 GitHub에서 데이터 시각화 샘플을 참조하세요.
이 7분 분량의 동영상에서는 빅 데이터 클러스터에서 HDFS 데이터를 쿼리하는 단계를 안내하고 있습니다.
필수 조건
- 빅 데이터 도구
- kubectl
- Azure Data Studio
- SQL Server 2019 확장
- SQL Server 빅 데이터 클러스터에 샘플 데이터 로드
HDFS에 외부 테이블 만들기
저장소 풀에는 HDFS에 저장된 CSV 파일의 웹 클릭스트림 데이터가 포함됩니다. 다음 단계에 따라 해당 파일의 데이터에 액세스할 수 있는 외부 테이블을 정의합니다.
Azure Data Studio에서 사용자의 빅 데이터 클러스터의 SQL Server 마스터 인스턴스에 연결합니다. 자세한 내용은 SQL Server 마스터 인스턴스에 연결을 참조하세요.
서버 창에서 연결을 두 번 클릭하여 SQL Server 마스터 인스턴스의 서버 대시보드를 표시합니다. 새 쿼리를 선택합니다.
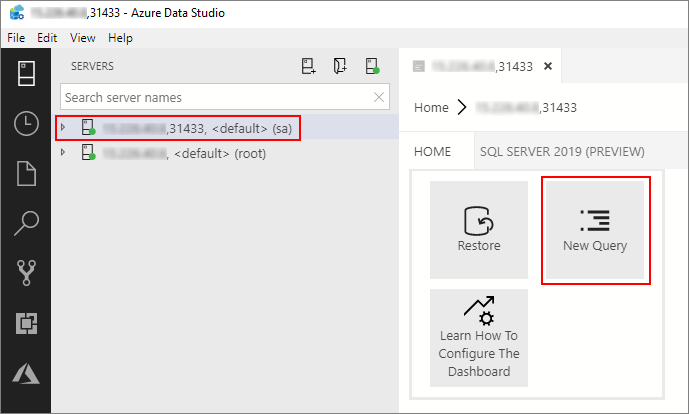
다음 Transact-SQL 명령을 실행하여 마스터 인스턴스의 Sales 데이터베이스로 컨텍스트를 변경합니다.
USE Sales GOHDFS에서 읽을 CSV 파일의 형식을 정의합니다. F5 키를 눌러 문(statement)을 실행합니다.
CREATE EXTERNAL FILE FORMAT csv_file WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2, USE_TYPE_DEFAULT = TRUE) );저장소 풀에 외부 데이터 원본이 아직 없는 경우, 생성합니다.
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool') BEGIN CREATE EXTERNAL DATA SOURCE SqlStoragePool WITH (LOCATION = 'sqlhdfs://controller-svc/default'); END저장소 풀에서
/clickstream_data를 읽을 수 있는 외부 테이블을 만듭니다. SQLStoragePool은 빅 데이터 클러스터의 마스터 인스턴스에서 액세스할 수 있습니다.CREATE EXTERNAL TABLE [web_clickstreams_hdfs] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlStoragePool, LOCATION = '/clickstream_data', FILE_FORMAT = csv_file ); GO
데이터 쿼리
다음 쿼리를 실행하여 web_clickstream_hdfs 외부 테이블의 HDFS 데이터를, 데이터를 로컬 Sales 데이터베이스의 관계형 데이터와 조인합니다.
SELECT
wcs_user_sk,
SUM( CASE WHEN i_category = 'Books' THEN 1 ELSE 0 END) AS book_category_clicks,
SUM( CASE WHEN i_category_id = 1 THEN 1 ELSE 0 END) AS [Home & Kitchen],
SUM( CASE WHEN i_category_id = 2 THEN 1 ELSE 0 END) AS [Music],
SUM( CASE WHEN i_category_id = 3 THEN 1 ELSE 0 END) AS [Books],
SUM( CASE WHEN i_category_id = 4 THEN 1 ELSE 0 END) AS [Clothing & Accessories],
SUM( CASE WHEN i_category_id = 5 THEN 1 ELSE 0 END) AS [Electronics],
SUM( CASE WHEN i_category_id = 6 THEN 1 ELSE 0 END) AS [Tools & Home Improvement],
SUM( CASE WHEN i_category_id = 7 THEN 1 ELSE 0 END) AS [Toys & Games],
SUM( CASE WHEN i_category_id = 8 THEN 1 ELSE 0 END) AS [Movies & TV],
SUM( CASE WHEN i_category_id = 9 THEN 1 ELSE 0 END) AS [Sports & Outdoors]
FROM [dbo].[web_clickstreams_hdfs]
INNER JOIN item it ON (wcs_item_sk = i_item_sk
AND wcs_user_sk IS NOT NULL)
GROUP BY wcs_user_sk;
GO
정리
다음 명령을 사용하여 이 자습서에서 사용되는 외부 테이블을 제거합니다.
DROP EXTERNAL TABLE [dbo].[web_clickstreams_hdfs];
GO
다음 단계
다음 문서로 이동하여 빅 데이터 클러스터에서 Oracle을 쿼리하는 방법을 알아봅니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기