Always On 가용성 그룹의 임대, 클러스터 및 상태 확인 제한 시간의 메커니즘 및 지침
하드웨어, 소프트웨어 및 클러스터 구성의 차이점과 가동 시간 및 성능에 대한 다양한 애플리케이션 요구 사항으로 인하여 임대, 클러스터 및 상태 검사 시간제한값에 대한 특정 구성이 필요합니다. 특정 애플리케이션 및 워크로드에는 하드 오류 이후 가동 중지 시간을 제한하려고 보다 적극적인 모니터링을 해야 합니다. 다른 경우에는 일시적인 네트워크 문제에 대해 더 많은 허용 오차를 있어야 하며 리소스 사용량이 많음으로 인하여 대기하는 경우 장애 조치(failover) 속도가 느려집니다.
각 노드의 여러 서비스가 작동되어 오류를 감지합니다. 클러스터 서비스는 쿼럼 손실을 검색할 수 있습니다. 리소스 DLL은 Always On 상태 검색에서 발생한 문제를 검색할 수 있습니다. 또는 수동 장애 조치(failover)는 주 인스턴스에서 직접 시작할 수 있습니다. 클러스터 서비스, 리소스 호스트 및 SQL Server 인스턴스는 RPC, 공유 메모리 및 T-SQL을 통해서 서로 동기화됩니다. 대부분의 시나리오에서는 이러한 서비스는 성공적으로 통신이 이루어 지지만 이 통신은 동일한 컴퓨터의 서비스 사이에서도 완벽하게 신뢰할 수는 없습니다. 또한 AG(가용성 그룹)는 네트워크 및 디스크 오류처럼 시스템 전체 이벤트를 견딜 수 있어야 하며, 이로 인해 통신 방해 또는 기능 중단이 발생할 수 있습니다. 많은 오류 사례와 서비스 사이에서 완전히 신뢰할 수 있는 통신이 없는 AG는 다양한 장애 조치(failover) 검색 메커니즘으로 인하여 서로 독립적으로 오류를 감지하면서 응답하기 때문에 클러스터 상태는 항상 모든 노드에 대해 일치합니다.
클러스터 노드 및 리소스 검색
클러스터의 각 노드는 장애 조치 클러스터를 작동하고 모든 클러스터 리소스를 모니터링하는 단일 클러스터 서비스를 실행합니다. 리소스 호스트는 별도 프로세스로 작동하는 클러스터 서비스와 클러스터 리소스 간의 인터페이스입니다. 리소스 호스트가 클러스터 서비스에서 호출이 될 때 클러스터 리소스에 대한 작업을 실행합니다. SQL Server와 같은 클러스터 인식 애플리케이션은 리소스 DLL을 통해서 리소스 모니터에 사용자 지정 인터페이스를 제공합니다. 리소스 DLL은 사용자 지정 리소스에 대한 온라인 및 오프라인 작업 및 상태 모니터링을 구현합니다. 리소스 호스트는 클러스터 서비스의 자식 프로세스이고 클러스터 서비스가 종료될 때마다 종료됩니다.
SQL Server의 경우 AG 리소스 DLL은 AG 임대 메커니즘 및 Always On 상태 검색에 따른 AG의 상태를 결정합니다. AG 리소스 DLL은 IsAlive 작업을 통해 리소스 상태를 노출합니다. 리소스 모니터는 클러스터 하트비트 간격으로 IsAlive폴링되고, 이 간격은 CrossSubnetDelay클러스터 전체의 값SameSubnetDelay으로 설정됩니다. 주 노드에서 리소스 DLL에 대한 IsAlive 호출이 AG가 상태가 정상적이지 않다고 반환할 때마다 클러스터 서비스는 장애 조치(failover)를 시작합니다.
클러스터 서비스는 클러스터의 다른 노드에 하트비트를 전송하고 해당 노드에서 수신된 하트비트를 승인합니다. 노드가 일련의 승인되지 않은 하트비트에서 통신 오류를 감지할 때 연결할 수 있는 모든 노드가 클러스터 노드 상태에 대한 보기를 조정하게 하는 메시지를 브로드캐스트합니다. 재그룹 이벤트라고 불리는 이 이벤트는 노드 간에 클러스터 상태의 일관성을 유지합니다. 재그룹 이벤트 후에 쿼럼이 손실될 경우 이 파티션의 AG를 포함한 모든 클러스터 리소스가 오프라인으로 전환됩니다. 이 파티션의 모든 노드는 확인 상태로 전환됩니다. 쿼럼이 있는 파티션이 있는 경우 AG는 파티션의 한 노드에 할당되어 주 복제본이 되고 다른 모든 노드는 보조 복제본이 됩니다.
Always On 상태 검색
Always On AG 리소스 DLL은 내부 SQL Server 구성 요소의 상태를 모니터링합니다. sp_server_diagnostics은 HealthCheckTimeout로 제어되는 간격으로 이러한 구성 요소 SQL Server의 상태를 보고합니다. 시스템, 리소스, 쿼리 처리, io 하위 시스템 및 이벤트 등 5가지의 인스턴스 수준 구성 요소의 상태를 sp_server_diagnostics보고합니다. 또한 각 AG의 상태도 보고합니다. 각각 업데이트 할 때마다 리소스 DLL은 AG의 오류 수준에 따라 AG 리소스의 상태를 업데이트합니다. sp_server_diagnostics에 의하여 데이터가 반환될 때, 각 구성 요소는 구성 요소의 상태를 설명하는 일부 XML 데이터와 함께 클린, 경고, 오류 또는 알 수 없는 상태로 표시됩니다. 상태 검색은 구성 요소가 오류 상태인 경우 작업을 실행합니다.
상태 검색이 여러 간격 동안 리소스 DLL에 대한 업데이트를 보고하지 못하는 경우 AG는 비정상적으로 확인되어서 IsAlive호출에서 오류를 보고합니다.
임대 메커니즘
다른 장애 조치 메커니즘과 달리 SQL Server 인스턴스는 임대 메커니즘에서 활성 역할을 수행합니다. 임대 메커니즘은 클러스터 리소스 호스트와 SQL Server 프로세스 간에 Looks-Alive 유효성 검사로 사용됩니다. 메커니즘은 서로의 상태를 확인하고 궁극적으로 분리 장애(split-brain) 시나리오를 방지하여 양쪽(클러스터 서비스 및 SQL Server 서비스)이 자주 접촉하는 상태에 있는지 확인하는 데 사용됩니다. AG를 기본 복제본(replica)으로서 온라인 상태로 전환할 때 SQL Server 인스턴스는 AG에 대한 전용 임대 작업자 스레드를 생성합니다. 임대 작업자는 임대 갱신 및 임대 중지 이벤트를 포함하는 리소스 호스트와 함께 작은 메모리 영역을 공유합니다. 임대 작업자 및 리소스 호스트는 순환 방식으로 작업해서 각 임대 갱신 이벤트를 신호로 표시한 후에, 상대방이 자체 임대 갱신 이벤트 중지 또는 중지 이벤트 신호를 보낼 때까지 대기합니다. 리소스 호스트와 SQL Server 임대 스레드 모두 TTL(Time to Live)값을 유지 및 관리하며, 이 값은 스레드가 다른 스레드의 신호를 수신한 후에 스레드가 절전 모드에서 해제될 때마다 업데이트됩니다. 신호를 기다리는 동안 TTL(Time to Live)에 도달하는 경우 임대가 만료된 다음 복제본(replica)이 해당 특정 AG에 대한 확인 상태로 전환됩니다. 임대 중지 이벤트가 신호를 받는 경우 복제본(replica)은 해결 역할로 전환됩니다.
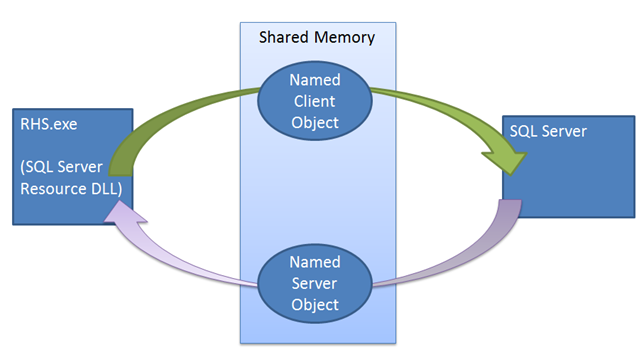
임대 메커니즘은 SQL Server와 Windows Server 장애 조치(failover) 클러스터 사이에서 동기화를 적용합니다. 장애 조치(failover) 명령이 실행되었을 때 클러스터 서비스는 현재 주 복제본의 리소스 DLL에 대한 Offline 호출을 수행합니다. 먼저 리소스 DLL은 저장 프로시저를 사용하여 AG를 오프라인으로 전환하려고 합니다. 이 저장 프로시저가 실패하거나 시간 제한을 초과하는 경우 클러스터 서비스로 오류가 다시 보고되고 종료 명령을 실행합니다. 종료는 동일한 저장 프로시저를 다시 실행하려고 시도하겠지만 이번에는 클러스터가 새 복제본(replica)에서 AG를 온라인 상태로 만들기 이전에 리소스 DLL이 성공 또는 실패를 보고할 때까지 기다려주지 않습니다. 이 두 번째 프로시저 호출이 실패할 경우 리소스 호스트는 임대 메커니즘을 사용하여 인스턴스를 오프라인으로 전환해야만 합니다. AG를 오프라인으로 전환하기 위하여 리소스 DLL이 호출될 때 리소스 DLL은 임대 중지 이벤트를 알리며 SQL Server 임대 작업자 스레드를 해제하여 AG를 오프라인으로 전환합니다. 이 중지 이벤트가 신호를 받지 않는다고 해도 임대가 만료되어 복제본(replica)이 확인 상태로 전환됩니다.
임대는 주로 주 인스턴스와 클러스터 사이에서 동기화 메커니즘이기는 하지만 장애 조치(failover)가 필요로 하지 않는 오류 조건을 만들 수도 있습니다. 예를 들어 높은 CPU, 메모리 부족 상태(가상 메모리 부족, 프로세스 페이징), 메모리 덤프를 생성하는 동안 응답하지 않는 SQL 프로세스, 시스템 응답 없음, 쿼럼 손실 등으로 인해 오프라인으로 전환된 클러스터(WSFC)는 SQL 인스턴스에서 임대 갱신을 방지하고 다시 시작이나 장애 조치(failover)를 발생시킬 수 있습니다.
클러스터 시간제한값에 대한 지침
상충 관계를 신중하게 고려하고 SQL Server 클러스터에 대한 덜 적극적인 모니터링을 사용할 경우의 결과를 이해합니다. 클러스터 제한 시간 값이 증가하면 일시적인 네트워크 문제에 대한 허용 오차가 증가하지만 심각한 오류에 대한 반응이 느려집니다. 리소스 압력 또는 대규모 지리적 대기 시간을 처리하기 위해 시간 제한을 늘리면 하드 또는 복구 불가능한 오류에서 복구하는 시간도 더 늘어나게 됩니다. 이는 많은 애플리케이션에서 허용되지만, 모든 경우에 이상적이지는 않습니다.
기본값 설정은 하드 오류의 증상에 신속히 대응하고 가동 중지 시간을 제한하기 위해 최적화되어 있지만 이러한 설정은 특정 작업 및 구성에 대해 지나치게 공격적일 수도 있습니다. LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold 또는HealthCheckTimeout 중에서 어느 것도 기본값보다 낮추지 않는 것이 좋습니다. 올바른 설정은 각 배포마다 다르고 검색하는 데 미세 조정 기간이 더 오래 걸릴 수 있습니다. 이 값 중 하나를 변경하는 경우 이러한 값 간의 관계 및 종속성을 고려하여 점진적으로 수행합니다.
클러스터 시간제한과 임대 시간제한 사이의 관계
임대 메커니즘의 기본 기능은 클러스터 서비스가 다른 노드로 장애 조치(failover)를 처리하는 동안 인스턴스와 통신할 수 없는 경우 SQL Server 리소스를 오프라인으로 전환하는 것입니다. 클러스터가 AG 클러스터 리소스에서 오프라인 작업을 실시할 때 클러스터 서비스는 리소스를 오프라인으로 전환하기 위한 rhs.exe 대한 RPC 호출을 수행합니다. 리소스 DLL은 저장 프로시저를 사용하여 SQL Server에 AG를 오프라인으로 전환하라고 지시하지만 이 저장 프로시저가 실패하거나 시간이 초과될 수 있습니다. 리소스 호스트는 오프라인 호출 중에 자체 임대 갱신 스레드도 중지합니다. 최악의 경우 SQL Server에서 임대가 ½ * LeaseTimeout에 만료되고 인스턴스를 확인 상태로 전환하게 됩니다. 장애 조치(failover)는 여러 다른 당사자가 시작할 수는 있지만 클러스터 상태 보기가 클러스터 전체와 SQL Server 인스턴스의 전체에서 일관되게 보이는 것이 매우 중요합니다. 예를 들어 기본 인스턴스가 나머지 클러스터와 연결이 끊어진 시나리오를 가정해 보세요. 클러스터의 각 노드는 클러스터 시간 제한 값 때문에 비슷한 시간에 오류를 결정하지만, 주 노드만 주 SQL Server 인스턴스와 상호 작용하여 주 역할을 강제로 포기할 수도 있습니다.
주 노드의 관점에서 클러스터 서비스는 쿼럼이 손실되며 서비스가 자체적으로 종료되기 시작합니다. 클러스터 서비스는 프로세스를 종료하기 위해 리소스 호스트에 대한 RPC 호출을 실행합니다. 이 종료 호출은 SQL Server 인스턴스에서 AG를 오프라인으로 전환하는 역할을 담당합니다. 이 오프라인 호출은 T-SQL을 통해 수행되지만, SQL과 리소스 DLL 간 연결이 성공적으로 설정된다고 보장할 수는 없습니다.
나머지 클러스터의 관점에서 현재 주 복제본이 없으므로 클러스터는 클러스터의 나머지 노드에 대해 단일 새 주 복제본을 투표하고 설정합니다. 리소스 DLL에서 호출된 저장 프로시저가 실패하거나 시간 제한을 초과한 경우 클러스터는 분리 뇌 시나리오에 취약할 수 있습니다.
임대 시간제한은 통신 오류에 직면하여 분할 브레인 시나리오를 방지합니다. 모든 통신이 실패했음에도 불구하고 리소스 DLL 프로세스가 종료되고 임대를 업데이트할 수가 없습니다. 임대가 만료되면 AG가 자체적으로 오프라인으로 전환합니다. SQL Server 인스턴스는 클러스터가 새 복제본(replica) 설정하기 이전에 주 복제본(replica)이 더 이상 호스트하지 않는다는 점을 알고 있어야만 합니다. 새로운 주 복제본을 선택하는 나머지 클러스터에 현재 주 복제본과 조정할 방법이 없기 때문에 시간 제한 값은 현재 주 복제본이 오프라인 상태로 전환되기 전에 새로운 주 복제본을 설정하지 않도록 합니다.
클러스터가 장애 조치할 때 새로운 주 복제본이 온라인 상태가 되기 전에 이전의 주 복제본을 호스트하는 SQL Server의 인스턴스는 확인 상태로 전환되어야 합니다. 언제든지 SQL Server 임대 스레드에는 ½ * LeaseTimeout의 남은 TTL(time-to-live)이 있습니다. 임대가 갱신될 때마다 새로운 TTL(time-to-live)이 LeaseInterval 또는 ½ * LeaseTimeout으로 업데이트되기 때문입니다. 클러스터 서비스 또는 리소스 호스트가 임대 중지 이벤트를 알리지 않은 채로 중단되거나 종료되는 경우 클러스터는 SameSubnetThreshold\ SameSubnetDelay밀리초 후에 주 노드가 중단되었다고 선언합니다. 이 시간 안에, 임대가 만료가 되어야만, 주 복제본이 오프라인 상태를 보장합니다. 임대 시간 제한에 대한 최대 TTL(Time To Live)은 ½ * LeaseTimeout이기 때문에, ½ * LeaseTimeout은 SameSubnetThreshold * SameSubnetDelay보다 작아야 합니다.
SameSubnetThreshold \<= CrossSubnetThreshold 및 SameSubnetDelay \<= CrossSubnetDelay는 모든 SQL Server 클러스터에 true여야 합니다.
상태 검사 시간제한 작업
다른 장애 조치 메커니즘이 직접 종속되어 있으므로 상태 확인 제한 시간은 보다 유연합니다. 기본값인 30초는 sp_server_diagnostics 간격을 10초로 설정하며, 시간 제한의 경우 최소값은 15초, 간격은 5초입니다. 보다 일반적으로 sp_server_diagnostics 업데이트 간격은 항상 1/3 * HealthCheckTimeout입니다. 리소스 DLL이 간격에서 새로운 일련의 상태 데이터를 수신하지 못하면 계속 이전 간격에서 상태 데이터를 사용하여 현재 AG 및 인스턴스 상태를 확인합니다. 상태 확인 시간 제한 값을 늘리면 주 복제본이 CPU 압력을 더 많이 견딜 수 있게 되어 sp_server_diagnostics에서 간격마다 새 데이터를 제공하지 못할 수 있지만 오래된 데이터 상태 확인에 더 오래 의존하게 됩니다. 시간 제한 값에 상관없이 복제본(replica)이 정상적이지 않음을 나타내는 데이터가 수신되는 경우 다음 IsAlive 호출은 인스턴스가 정상적이지 않음을 반환하고 클러스터 서비스가 장애 조치(failover)를 시작합니다.
AG의 실패 조건 수준은 상태 검사에 대한 오류 조건을 변경합니다. 오류 수준의 경우 sp_server_diagnostics에서 AG 요소가 비정상이라고 보고할 경우 상태 확인에 실패합니다. 각 수준은 그 아래 수준에서 모든 오류 조건을 상속합니다.
| 수준 | 인스턴스가 데드로 간주되는 조건 |
|---|---|
| 1: OnServerDown | AG 외에 리소스가 실패하는 경우 상태 검사는 아무런 조치도 취하지 않습니다. AG 데이터가 5개 간격 또는 5/3 * HealthCheckTimeout 내에서 수신되지 않는 경우 |
| 2: OnServerUnresponsive | sp_server_diagnostics에서 HealthCheckTimeout에 대한 데이터가 수신되지 않은 경우 |
| 3: OnCriticalServerError | (기본값) 시스템 구성 요소가 오류를 보고하는 경우 |
| 4: OnModerateServerError | 리소스 구성 요소가 오류를 보고하는 경우 |
| 5: OnAnyQualifiedFailureConitions | 쿼리 처리 컴포넌트가 오류를 보고하는 경우 |
클러스터 및 Always On 시간 제한 값 업데이트
클러스터 값
WSFC 구성에는 클러스터 시간 제한 값을 결정하는 네 가지 값이 있습니다
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
지연 값은 클러스터 서비스에서 하트비트 간 대기 시간을 결정하며, 임계값은 클러스터에서 개체가 데드로 선언되기 전 대상 노드 또는 리소스에서 승인을 수신할 수 없는 하트비트의 수를 설정합니다. SameSubnetDelay \* SameSubnetThreshold밀리초 이상 동일한 서브넷의 노드 간에 성공적인 하트비트가 없는 경우 해당 노드는 데드로 결정됩니다. 서브넷 간 값을 사용하는 서브넷 통신 간에서도 마찬가지입니다.
현재의 모든 클러스터 값을 나열하기 위해서는 대상 클러스터의 노드에서 관리자 권한의 PowerShell 터미널을 엽니다. 다음 명령을 실행합니다:
Get-Cluster | fl *
이러한 값을 업데이트하기 위해서는 관리자 권한 PowerShell 터미널에서 다음 명령을 따라 해 보세요:
(Get-Cluster).<ValueName> = <NewValue>
지연 * 임계값 곱이 증가하여 클러스터 제한 시간이 길어지면 임계값을 증가시키기 전에 먼저 지연 값을 증가시키는 것이 더 효과적입니다. 지연을 늘림으로써 각 하트비트 사이에서의 시간은 길어집니다. 하트비트 간 시간이 길면 일시적인 네트워크 문제가 저절로 해결될 수 있는 시간이 길어지고 동일한 기간에 더 많은 하트비트를 보내는 것에 비해 네트워크 정체가 줄어듭니다.
임대 시간 제한
임대 메커니즘은 WSFC 클러스터의 각 AG와 관련된 단일 값으로 제어됩니다. 임대 시간 제한으로 인해 다음과 같은 오류가 발생할 수 있습니다.
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
임대 시간 제한 값을 수정하기 위해 장애 조치(failover) 클러스터 관리자를 사용하여 다음 단계를 수행합니다.
역할 탭에서 대상 AG 역할을 찾습니다. 대상 AG 역할을 선택합니다.
창 하단에서 AG 리소스를 마우스 오른쪽 단추로 클릭하여 속성을 선택합니다.
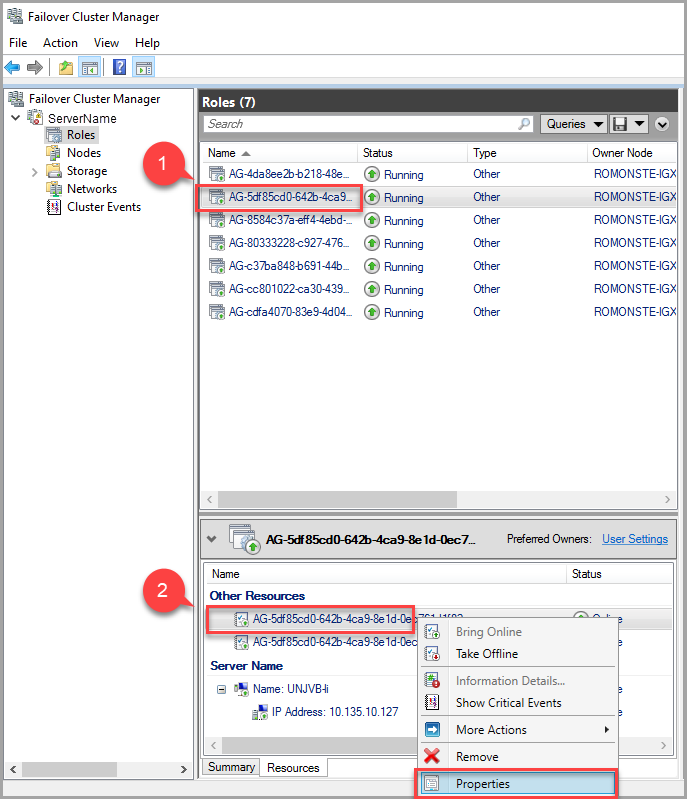
팝업 창에서 속성 탭으로 이동하여 이러한 AG와 관련된 값 목록을 확인합니다. LeaseTimeout 값을 선택하여 변경합니다.
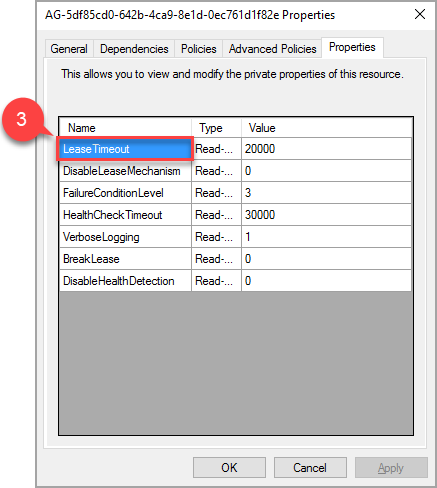
AG의 구성에 따라 수신기, 공유 디스크, 파일 공유 등에 관한 추가 리소스가 있을 수 있으며, 이러한 리소스에는 추가 구성이 필요하지 않습니다.
참고 항목
리소스가 오프라인 상태가 되었다가 다시 온라인 상태가 된 후 ‘LeaseTimeout’ 속성의 새 값이 적용됩니다.
상태 확인 값
Always On 상태 검사를 제어하는 두 가지의 값은: FailureConditionLevel 및 HealthCheckTimeout 입니다. FailureConditionLevel은 sp_server_diagnostics에서 보고한 특정한 오류 조건에 대한 허용 오차 수준을 나타내고 있으며 HealthCheckTimeout은 리소스 DLL이 업데이트sp_server_diagnostics를 수신하지 않고 이동할 수 있는 시간을 구성합니다. sp_server_diagnostics의 업데이트 간격은 항상 HealthCheckTimeout/3입니다.
장애 조치(failover) 상태 수준을 구성하려면 CREATE 또는 ALTER AVAILABILITY GROUP 문의 FAILURE_CONDITION_LEVEL = <n> 옵션을 사용합니다. 여기서 <n>은 1~5 사이의 정수입니다. 다음 명령은 AG 'AG 1'에 대한 오류 조건 수준을 1로 설정합니다:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
상태 검사 시간제한을 만들기 위해서는 CREATE 또는 ALTER AVAILABILITY GROUP문의 HEALTH_CHECK_TIMEOUT옵션을 사용합니다. 다음 명령은 AG AG1에 대한 상태 확인 시간 제한을 60,000밀리초로 설정합니다.
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
시간 제한 지침 요약
해당 기본값 아래로 제한 시간 값을 줄이지 않는 것이 좋습니다
임대 간격(½ * LeaseTimeout)은 다음보다 짧아야 합니다. SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| 시간 제한 설정 | 목적 | 다음 | 사용 | IsAlive & LooksAlive | 원인 | 결과 |
|---|---|---|---|---|---|---|
| 임대 시간 제한 기본값: 20000 |
분리 뇌 방지 | 주-클러스터 (HADR) |
Windows 이벤트 개체 | 둘 다에서 사용됨 | OS가 응답하지 않음, 가상 메모리 부족, 작업 집합 페이징, 덤프 생성, CPU 고정, WSFC 다운(쿼럼 손실) | AG 리소스 오프라인-온라인, 장애 조치(failover) |
| 세션 제한 시간 기본값: 10000 |
주 및 보조 사이에서의 통신 문제 알림 | 보조-주 (HADR) |
TCP 소켓(DBM 엔드포인트를 통해 전송된 메시지) | 둘 다에서 사용되지 않음 | 네트워크 통신 보조 문제 - 다운, OS 응답 없음, 리소스 경합 |
보조 - 연결 끊김 |
| HealthCheck 시간 제한 기본값: 30000 |
주 복제본(replica)의 상태를 확인하는 동안 시간제한을 표시합니다 | 클러스터-주 (FCI 및 HADR) |
T-SQL sp_server_진단 | 둘 다에서 사용됨 | 오류 조건 충족, OS가 응답하지 않음, 가상 메모리 부족, 작업 집합 트림, 덤프 생성, WSFC(쿼럼 손실), 스케줄러 문제(데드락 스케줄러) | AG 리소스 오프라인-온라인 또는 장애 조치(failover), FCI 다시 시작/장애 조치(failover) |
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기