적용 대상:![]() SQL Server
SQL Server
분산 가용성 그룹(AG)은 별도의 두 가용성 그룹에 걸쳐 있는 특별한 형식의 가용성 그룹입니다. 분산 가용성 그룹은 SQL Server 2016부터 사용할 수 있습니다.
이 문서에서는 분산형 가용성 그룹의 기능을 설명합니다. 분산 가용성 그룹을 구성하려면 분산 가용성 그룹 구성을 참조하세요.
개요
분산 가용성 그룹은 별도의 두 가용성 그룹에 걸쳐 있는 특별한 유형의 가용성 그룹입니다. 분산 가용성 그룹에 참여하는 가용성 그룹은 동일한 위치에 있을 필요는 없습니다. 실제, 가상, 온-프레미스, 퍼블릭 클라우드 또는 가용성 그룹 배포를 지원하는 모든 위치에 있을 수 있습니다. 여기에는 Linux에서 호스팅되는 가용성 그룹과 Windows에서 호스팅되는 가용성 그룹 사이 같이 도메인 간 및 플랫폼 간이 포함됩니다. 두 가용성 그룹이 통신할 수 있는 한 이러한 가용성 그룹을 포함한 분산 가용성 그룹을 구성할 수 있습니다.
기존의 가용성 그룹에는 WSFC(Windows Server 장애 조치(Failover) 클러스터) 또는 Pacemaker(Linux의 경우)에서 구성된 리소스가 있습니다. 분산된 가용성 그룹은 기본 클러스터(WSFC 또는 Pacemaker)에서 아무것도 구성하지 않습니다. 관련된 모든 항목은 SQL Server 내에서 유지 관리됩니다. 분산 가용성 그룹에 대한 정보를 확인하는 방법은 분산 가용성 그룹 정보 보기를 참조하세요.
분산 가용성 그룹의 경우 기본 가용성 그룹에 수신기가 있어야 합니다. 기존 가용성 그룹에서와 같이 독립 실행형 인스턴스에 대한 기본 서버 이름(또는 SQL Server FCI(장애 조치 클러스터 인스턴스)의 경우 네트워크 이름 리소스와 연결된 값)을 제공하는 대신, 매개 변수를 만들 때 ENDPOINT_URL 매개 변수를 사용하여 분산 가용성 그룹에 대해 구성된 수신기를 지정합니다. 분산 가용성 그룹의 기본 가용성 그룹마다 수신기가 있지만, 분산 가용성 그룹에는 수신기가 없습니다.
다음 그림에서는 각각 고유한 WSFC에 구성된 두 개의 가용성 그룹(AG 1 및 AG 2)에 걸친 분산 가용성 그룹의 고급 수준을 보여 줍니다. 분산 가용성 그룹에는 총 4개의 복제본이 있으며, 각 가용성 그룹에는 2개의 복제본이 있습니다. 각 가용성 그룹은 복제본의 최대 수를 지원할 수 있으므로 분산 가용성 그룹은 최대 18개의 총 복제본을 가질 수 있습니다.
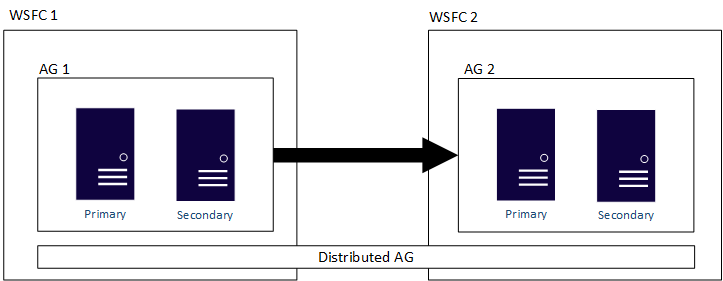
분산 가용성 그룹에서 데이터 이동을 동기 또는 비동기로 구성할 수 있습니다. 그러나 데이터 이동은 기존 가용성 그룹에 비해 분산 가용성 그룹 내에서 약간 다릅니다. 각 가용성 그룹에는 하나의 주 복제본이 있지만 삽입, 업데이트 및 삭제를 허용할 수 있는 분산 가용성 그룹에 참여하는 데이터베이스 복사본은 하나만 있습니다. 다음 그림에서 보여 주듯이 AG 1은 주 가용성 그룹입니다. 주 복제본은 AG 1의 보조 복제본과 AG 2의 주 복제본 모두로 트랜잭션을 보냅니다. AG 2의 주 복제본은 전달자라고도 합니다. 포워더는 분산된 가용성 그룹에서 보조 가용성 그룹 내의 주 복제본입니다. 전달자는 주 가용성 그룹의 주 복제본에서 트랜잭션을 받고 자체 가용성 그룹의 보조 복제본에 전달합니다. 그런 다음 전달자는 AG 2의 주 복제본을 계속 업데이트합니다.
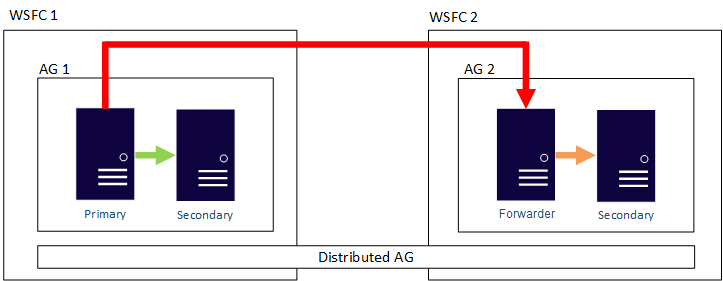
AG 2의 주 복제본에서 삽입, 업데이트 및 삭제할 수 있도록 하는 유일한 방법은 AG 1에서 분산 가용성 그룹을 수동으로 장애 조치하는 것입니다. 앞의 그림에서 AG 1에는 쓰기 가능한 데이터베이스 복사본이 있으므로, 장애 조치를 실행하면 AG 2는 삽입, 업데이트 및 삭제를 처리할 수 있는 가용성 그룹이 됩니다. 하나의 분산 가용성 그룹을 다른 그룹으로 전환하는 방법에 대한 자세한 내용은 보조 가용성 그룹으로의 장애 조치를 참조하세요.
참고
- SQL Server 2016의 분산 가용성 그룹은 옵션을
FORCE_FAILOVER_ALLOW_DATA_LOSS사용하여 한 가용성 그룹에서 다른 가용성 그룹으로만 장애 조치(failover)를 지원합니다. - 분산된 가용성 그룹에 트랜잭션 복제를 사용할 경우 전달자 복제본을 게시자로 구성할 수 없습니다.
SQL Server 2025 변경 내용
SQL Server 2025(17.x)에는 다음과 같은 변경 내용이 도입되었습니다.
분산 AG 동기화 개선
SQL Server 2025(17.x)에서는 전달자 복제본이 비동기 커밋 모드에 있을 때 네트워크 채도를 줄여 동기화 성능을 향상시키기 위해 분산 가용성 그룹에 대한 내부 동기화 메커니즘을 변경했습니다. 이 변경은 기본적으로 사용하도록 설정되며 구성이 필요하지 않습니다.
참고
두 기본 가용성 그룹의 가용성 모드가 일치하지 않는 분산 가용성 그룹을 구성하는 것은 권장되지 않으며 동기화 대기 시간이 발생할 수 있습니다. 최적의 성능과 동기화를 보장하려면 두 가용성 그룹을 동일한 가용성 모드(동기 또는 비동기)로 구성해야 합니다.
제한된 가용성 그룹 지원
SQL Server 2025(17.x)는 분산된 포함된 가용성 그룹에 대한 지원을 도입합니다. 포함된 AG를 분산 가용성 그룹의 전달자로 사용하려는 경우 AUTOSEEDING_SYSTEM_DATABASES 명령 옵션에 대한 WITH | CONTAINED 절을 사용하여 포함된 AG를 만들어야 합니다.
버전 및 에디션 요구 사항
SQL Server 2017 이상의 분산 가용성 그룹은 동일한 분산 가용성 그룹에 SQL Server의 주 버전을 혼합할 수 있습니다. 읽기/쓰기 기본을 포함하는 AG는 분산 AG에 참여하는 다른 AG와 같거나 낮은 버전일 수 있습니다. 다른 AG가 같은 버전이거나 더 높은 버전일 수 있습니다. 이 시나리오는 업그레이드 및 마이그레이션 시나리오를 대상으로 합니다. 예를 들어 읽기/쓰기 주 복제본을 포함하는 AG가 SQL Server 2016이지만 SQL Server 2017 이상으로 업그레이드/마이그레이션하려는 경우, 분산 AG에 참여하는 다른 AG는 SQL Server 2017로 구성될 수 있습니다.
SQL Server 2012 또는 2014에는 분산 가용성 그룹 기능이 없으므로 이러한 버전으로 만든 가용성 그룹은 분산 가용성 그룹에 참여할 수 없습니다.
참고
SQL Server 버전에 따라 Azure 서비스(예: Managed Instance link에 연결할 때 Standard 버전으로 분산 가용성 그룹을 구성하거나 Standard 및 Enterprise 버전을 혼합하여 구성할 수 있습니다. KB5016729를 검토하여 자세히 알아보세요.
별도의 두 개 가용성 그룹이 있으므로 분산 가용성 그룹에 참여하는 복제본에 서비스 팩 또는 누적 업데이트를 설치하는 프로세스는 기존 가용성 그룹과는 약간 다릅니다.
먼저 분산 가용성 그룹에서 두 번째 가용성 그룹의 복제본을 업데이트함으로써 시작합니다.
분산 가용성 그룹에서 주 가용성 그룹의 복제본을 패치합니다.
표준 가용성 그룹과 마찬가지로, 주 가용성 그룹을 자체 복제본 중 하나(보조 가용성 그룹의 주 가용성 그룹이 아님)로 장애 조치하고 패치합니다. 주 복제본 이외의 복제본이 없으면 두 번째 가용성 그룹으로의 수동 장애 조치가 필요합니다.
Windows Server 버전 및 분산 가용성 그룹
분산 가용성 그룹은 여러 가용성 그룹에 걸쳐 있고, 각각 고유한 기본 WSFC에 있으며, SQL Server 전용 구조입니다. 즉, 개별 가용성 그룹을 포함하는 WSFC에는 서로 다른 주요 버전의 Windows Server가 있을 수 있습니다. 이전 섹션에서 설명한 대로 SQL Server의 주요 버전은 동일해야 합니다. 다음 그림에서는 첫 번째 그림과 매우 비슷하게 분산 가용성 그룹에 참여하는 AG 1 및 AG 2를 보여 주지만, 각 WSFC는 서로 다른 버전의 Windows Server입니다.
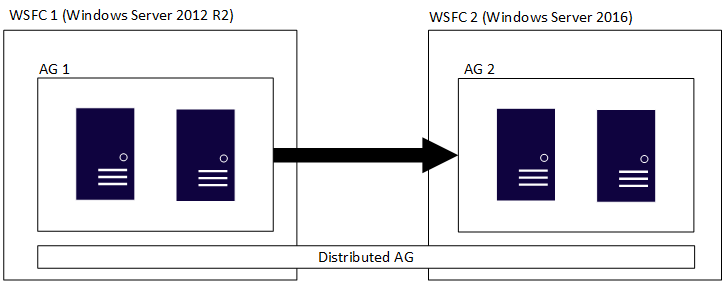
개별 WSFC와 해당 가용성 그룹은 기존 규칙을 따릅니다. 즉, 도메인에 조인되거나 조인되지 않을 수 있습니다(Windows Server 2016 이상). 서로 다른 두 가용성 그룹을 하나의 분산 가용성 그룹에 결합하는 경우 다음 네 가지 시나리오가 있습니다.
- 두 WSFC가 모두 동일한 도메인에 가입됩니다.
- 각 WSFC가 서로 다른 도메인에 가입됩니다.
- 한 WSFC는 도메인에 가입되고, 다른 WSFC는 도메인에 가입되지 않습니다.
- 두 WSFC가 모두 도메인에 가입되지 않습니다.
두 WSFC가 모두 동일한 도메인(트러스트된 도메인이 아님)에 가입된 경우 분산 가용성 그룹을 만들 때 별도의 작업을 수행할 필요가 없습니다. 동일한 도메인에 가입되지 않은 가용성 그룹 및 WSFC의 경우, 도메인 독립 가용성 그룹에 대한 가용성 그룹을 만드는 방식과 같이 인증서를 사용하여 분산 가용성 그룹을 작동하도록 합니다. 분산 가용성 그룹에 대한 인증서를 구성하는 방법을 알아보려면 도메인 독립 가용성 그룹 만들기의 3-13 단계를 수행합니다.
분산 가용성 그룹을 사용하는 경우 주 가용성 그룹 각각의 주 복제본에는 서로의 인증서가 있어야 합니다. 인증서를 사용하지 않는 엔드포인트가 이미 있는 경우 ALTER ENDPOINT를 사용하여 인증서 사용을 반영하도록 해당 엔드포인트를 재구성합니다.
사용 시나리오
분산 가용성 그룹을 사용하는 세 가지 주요 시나리오는 다음과 같습니다.
- 재해 복구 및 더 쉬운 다중 사이트 구성
- 새 하드웨어 또는 구성으로 마이그레이션(새 하드웨어 사용, 기본 운영 체제 변경 등)
- 여러 가용성 그룹을 확장하여 단일 가용성 그룹에서 읽기 가능한 복제본 수를 8개 이상으로 늘리는 경우
재해 복구 및 다중 사이트 시나리오
기존 가용성 그룹은 모든 서버가 동일한 WSFC에 포함되어야 하므로 여러 데이터 센터로 확장하기가 어렵습니다. 다음 그림에서는 데이터 흐름을 포함하여 기존 다중 사이트 가용성 그룹에 대한 아키텍처를 보여 줍니다. 모든 보조 복제본에 트랜잭션을 보내는 주 복제본이 하나만 있습니다. 이 구성은 몇 가지 방식에서 분산 가용성 그룹보다 더 작습니다. 예를 들어 Active Directory(적용 가능한 경우) 및 WSFC 쿼럼을 위한 감시자 같은 항목을 구현해야 합니다. 또한 노드 응답 변경과 같이 WSFC의 다른 측면을 고려해야 할 수도 있습니다.

분산 가용성 그룹은 여러 데이터 센터에 걸쳐 있는 가용성 그룹에 대해 더 유연한 배포 시나리오를 제공합니다. 이전에 재해 복구와 같은 시나리오에 로그 전달과 같은 기능을 사용한 분산 가용성 그룹도 사용할 수 있습니다. 그러나 로그 전달과 달리 분산 가용성 그룹은 트랜잭션 적용을 지연할 수 없습니다. 즉, 데이터를 잘못 업데이트하거나 삭제하는 사용자의 실수가 발생하는 경우 가용성 그룹 또는 분산 가용성 그룹에서 도움을 줄 수 없습니다.
분산 가용성 그룹은 느슨하게 결합되어 있으며, 이 경우 단일 WSFC가 필요하지 않으며 SQL Server에서 유지 관리됩니다. WSFC는 개별적으로 유지 관리되며 동기화는 주로 두 개의 가용성 그룹 간에 비동기이므로 다른 사이트에서 재해 복구를 구성하는 것이 더 쉽습니다. 각 가용성 그룹의 주 복제본은 자체의 보조 복제본을 동기화합니다.
- 분산 가용성 그룹에 대해서는 수동 장애 조치만 지원됩니다. 데이터 센터를 전환하는 재해 복구 상황에서는 자동 장애 조치를 구성하면 안됩니다(드문 경우는 제외).
- CrossSubnetThreshold와 같이 다중 사이트 또는 서브넷 WSFC에 대한 기존 항목 또는 매개 변수 중 일부를 설정할 필요는 거의 없지만, 데이터 전송을 위해 다른 계층의 네트워크 대기 시간은 여전히 확인해야 합니다. 차이점은 각 WSFC마다 자체의 가용성을 유지한다는 것입니다. 클러스터는 4개 노드로 구성된 하나의 큰 엔터티가 아닙니다. 앞의 그림과 같이 별도의 2개 노드 WSFC 두 개가 있습니다.
- 이 방법은 재난 복구를 위해 사용되므로 비동기 데이터 이동을 사용하는 것이 좋습니다.
- 주 복제본과 두 번째 가용성 그룹에 속한 보조 복제본 중 하나 이상의 복제본 간에 동기 데이터 이동을 구성하고 분산 가용성 그룹에서 동기 데이터 이동을 구성하는 경우, 분산 가용성 그룹은 모든 동기 복사본에서 해당 데이터를 가지고 있다고 승인할 때까지 대기합니다. 여러 분산 가용성 그룹이 데이지 체인(AG1 -> AG2 -> AG3) 구성이고 동기로 설정되어 있는 경우, 분산형 가용성 그룹은 마지막 가용성 그룹의 마지막 복제본이 업데이트될 때까지 대기합니다.
이주하다
분산 가용성 그룹은 서로 완전히 다른 두 가지 가용성 그룹 구성을 지원하므로 재해 복구 및 다중 사이트 시나리오뿐만 아니라 마이그레이션 시나리오도 사용할 수 있습니다. 새 하드웨어 또는 가상 컴퓨터(퍼블릭 클라우드의 온-프레미스 또는 IaaS)로 마이그레이션하는 경우, 분산 가용성 그룹을 구성하면 이전에 백업, 복사 및 복원 또는 로그 전달을 사용했던 마이그레이션이 발생할 수 있습니다.
마이그레이션 기능은 동일한 SQL Server 버전을 유지하면서 기본 OS를 변경하거나 업그레이드하는 시나리오에서 특히 유용합니다. Windows Server 2016은 동일한 하드웨어에서 Windows Server 2012 R2의 롤링 업그레이드를 허용하지만, 대부분의 사용자는 새 하드웨어 또는 가상 컴퓨터를 배포하도록 선택합니다.
새 구성으로의 마이그레이션을 완료하려면 프로세스가 완료되었을 때 원래 가용성 그룹에 대한 모든 데이터 트래픽을 중지하고 분산 가용성 그룹을 동기 데이터 이동으로 변경합니다. 이렇게 하면 두 번째 가용성 그룹의 주 복제본이 완전히 동기화되므로 데이터가 손실되지 않습니다. 동기화를 확인한 후, 분산 가용성 그룹을 보조 가용성 그룹으로 장애 조치합니다. 자세한 내용은 보조 가용성 그룹에 대한 장애 조치(failover)를 참조하세요.
마이그레이션 후에 이제 두 번째 가용성 그룹이 새로운 주 가용성 그룹인 경우 다음 단계 중 하나를 수행해야 할 수 있습니다.
- 보조 가용성 그룹의 수신기의 이름을 바꾸거나(원래 주 가용성 그룹에서 이전 이름을 삭제하거나 이름을 바꿀 수도 있음), 애플리케이션 및 사용자가 새 구성에 액세스할 수 있도록 원래 주 가용성 그룹의 수신기로 다시 만듭니다 .
- 이름 바꾸기 또는 다시 만들기가 불가능한 경우 애플리케이션 및 사용자를 두 번째 가용성 그룹의 수신기에 지정합니다.
상위 SQL Server 버전으로 마이그레이션
마이그레이션 시나리오에서는 데이터베이스를 원본보다 더 높은 버전의 SQL Server 대상으로 마이그레이션하도록 분산 AG를 구성할 수 있지만 몇 가지 제한 사항이 있습니다.
원본보다 높은 버전의 SQL Server 마이그레이션 대상으로 분산 AG를 구성하는 경우 자동 시딩이 지원되지 않으므로 시딩 모드를 MANUAL로 설정해야 합니다. AUTO-SEEDING을 사용하지 않도록 설정하지 않으면 마이그레이션이 실패하고 오류 946 "데이터베이스 'DistributionAG' 버전 xxx를 열 수 없습니다. 오류 로그에서 데이터베이스를 최신 버전”으로 업그레이드합니다. 시드 모드를 MANUAL로 설정하고 주 AG에서 원본 데이터베이스의 전체 및 트랜잭션 로그 백업을 수동으로 수행해야 합니다. 그런 다음 트랜잭션 로그와 함께 수동으로 보조 AG에 복원합니다. 자세히 알아보려면 분산 AG를 구성하는 수동 시딩 단계와 기본 AG에서 보조 AG로 데이터베이스를 백업해 복원하는 스크립트를 검토하세요.
보조 AG(AG2)가 마이그레이션 대상이고 기본 AG(AG1)보다 버전이 높으면 다음과 같은 제한 사항을 고려해야 합니다.
- 기본 AG가 더 낮은 버전인 경우에는 보조 AG의 모든 복제본 데이터베이스에 대한 읽기 권한이 없습니다.
- 이 시간 동안 업데이트는 기본 AG(AG1)에서 보조 AG(AG2)로 계속 전달되지만 보조 AG의 상태는 부분적으로 정상으로 표시되고 보조 AG(AG2)의 보조 복제본에 있는 데이터베이스는 동기화/복구 중으로 표시됩니다(AG가 동기화 커밋 상태인 경우에도).
- 분산 AG가 더 높은 버전(AG2)으로 장애 조치 후, AG2는 정상 상태가 되어야 합니다.
- 이 기간 동안 AG1이 더 낮은 버전이기 때문에 장애 복구가 불가능합니다.
- AG1의 버전이 낮기 때문에 장애 조치(failover) 후 AG2의 업데이트가 AG1로 복제되지 않습니다.
- 여기에서 원래 (기본) AG를 해제할 것인지 또는 AG1를 업그레이드하고 분산 AG를 유지 관리할 것인지를 선택합니다.
- AG1 서비스 해제를 선택하고 분산 AG에서 원래 기본 AG를 제거하면 프로세스가 완료됩니다.
- 분산 AG를 유지 관리하도록 선택한 경우 AG1의 SQL Server 버전을 AG2와 일치하도록 업그레이드합니다. AG1가 업그레이드되면 AG1이 정상 상태가 되고, 분산 AG가 정상 작동하며, 복제본이 동기화되어 장애 복구가 가능해집니다.
읽기 가능한 복제본 확장
단일 분산 가용성 그룹에는 필요에 따라 최대 16개의 보조 복제본이 포함될 수 있습니다. 따라서 다른 가용성 그룹의 두 개 주 복제본을 포함하여 최대 18개의 읽기용 복사본을 갖출 수 있습니다. 이 방법은 둘 이상의 사이트에서 다양한 애플리케이션에 보고하기 위해 거의 실시간으로 액세스할 수 있음을 의미합니다.
분산 가용성 그룹을 사용하면 단일 가용성 그룹에서만 가능한 규모 이상으로 읽기 전용 팜을 확장할 수 있습니다. 분산 가용성 그룹은 다음 두 가지 방법으로 읽기 가능한 복제본을 확장할 수 있습니다.
- 데이터베이스가 복구에 없더라도 분산 가용성 그룹에 있는 두 번째 가용성 그룹의 주 복제본을 사용하여 다른 분산 가용성 그룹을 만들 수 있습니다.
- 첫 번째 가용성 그룹의 주 복제본을 사용하여 다른 분산 가용성 그룹을 만들 수도 있습니다.
즉, 주 복제본은 서로 다른 분산 가용성 그룹에 참여할 수 있습니다. 다음 그림에서는 AG 1과 AG 2가 모두 분산 AG 1에 참여하고 있는 한편, AG 2와 AG 3은 분산 AG 2에 참여하고 있습니다. AG 2의 주 복제본(또는 전달자)은 분산된 AG 1의 보조 복제본과 분산된 AG 2의 주 복제본 모두입니다.
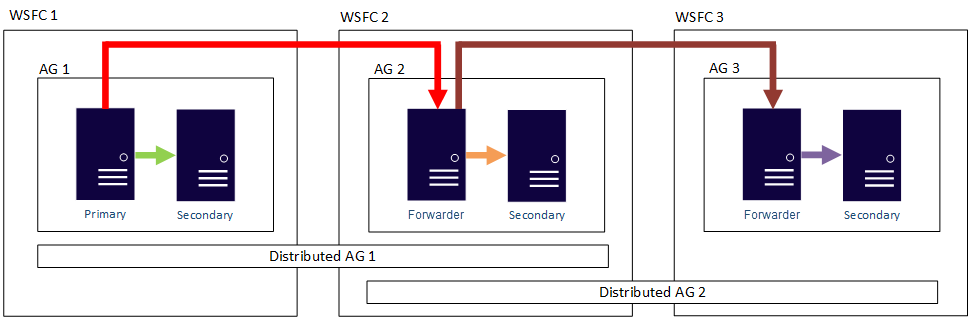
다음 그림에서는 서로 다른 두 가지 분산 가용성 그룹, 즉 분산 AG 1(AG 1과 AG 2로 구성)과 분산 AG 2(AG 1과 AG 3으로 구성)에 대한 주 복제본인 AG 1을 보여 줍니다.
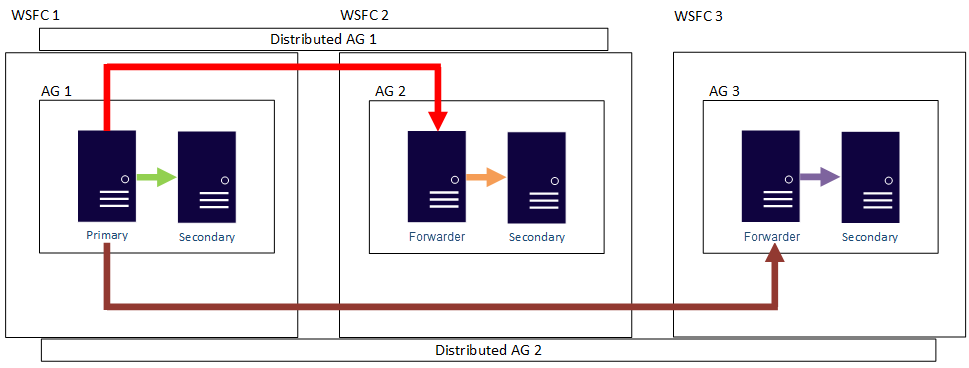
앞의 두 예제 모두에서는 세 개의 가용성 그룹에 최대 27개의 복제본이 있을 수 있습니다. 이러한 복제본은 모두 읽기 전용 쿼리에 사용할 수 있습니다.
읽기 전용 라우팅은 현재 분산 가용성 그룹에서 완벽하게 작동하지 않습니다. 더 구체적으로 살펴보면 다음과 같습니다.
- 읽기 전용 라우팅은 분산 가용성 그룹의 주 가용성 그룹에 구성할 수 있고 이 그룹에서 작동합니다.
- 읽기 전용 라우팅은 분산 가용성 그룹의 보조 가용성 그룹에 구성할 수 있지만 이 그룹에서 작동하지 않습니다. 수신기를 사용하여 보조 가용성 그룹에 연결하는 모든 쿼리는 보조 가용성 그룹의 주 복제본으로 이동합니다. 그렇지 않으면 모든 복제본을 보조 복제본으로 연결하고 직접 액세스할 수 있도록 각 복제본을 구성해야 합니다. 그러나 읽기 전용 라우팅은 보조 가용성 그룹이 장애 조치(failover) 후 주 가용성 그룹이 된 후에 작동합니다. 이 동작은 SQL Server 2016 또는 이후 버전의 SQL Server에 대한 업데이트에서 변경될 수 있습니다.
보조 가용성 그룹 초기화
분산 가용성 그룹은 두 번째 가용성 그룹의 주 복제본을 초기화하는 데 사용되는 중요한 방법인 자동 시드로 설계되었습니다. 다음을 수행하면 두 번째 가용성 그룹의 주 복제본에 대한 전체 데이터베이스 복원이 가능합니다.
- WITH NORECOVERY를 사용하여 데이터베이스 백업을 복원합니다.
- 필요한 경우 WITH NORECOVERY를 사용하여 적절한 트랜잭션 로그 백업을 복원합니다.
- 데이터베이스 이름을 지정하지 않고 SEEDING_MODE를 AUTOMATIC으로 설정된 두 번째 가용성 그룹을 만듭니다.
- 자동 시드를 사용하여 분산 가용성 그룹을 만듭니다.
두 번째 가용성 그룹의 주 복제본을 분산 가용성 그룹에 추가할 때, 이 복제본이 첫 번째 가용성 그룹의 주 데이터베이스와 비교하여 점검되고, 자동 시드를 사용하여 데이터베이스가 원본과 동일하게 업데이트됩니다. 몇 가지 주의 사항이 있습니다.
두 번째 가용성 그룹의 주 복제본에 있는
sys.dm_hadr_automatic_seeding에 표시된 출력에는 "Seeding Check Message Timeout(시드 중 확인 메시지 시간 초과)"라는 이유로current_state가 FAILED(실패)로 표시됩니다.두 번째 가용성 그룹의 기본 복제본(replica) 대한 현재 SQL Server 오류 로그는 자동 시드가 작동하고 LSNs이 동기화되었음을 보여 줍니다.
첫 번째 가용성 그룹의 주 복제본에 있는
sys.dm_hadr_automatic_seeding에 표시된 출력에는 current_state가 COMPLETED(완료)로 표시됩니다.자동 시드에는 분산 가용성 그룹과도 다른 동작이 있습니다. 두 번째 복제본의 자동 시드를 시작하려면 해당 복제본에서
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASE명령을 실행해야 합니다. 이 조건은 기본 가용성 그룹에 참여하는 모든 보조 복제본에 여전히 해당되지만, 두 번째 가용성 그룹의 기본 복제본은 분산 가용성 그룹에 추가된 후 자동 시딩을 시작할 수 있는 올바른 권한을 이미 보유하고 있습니다.
참고
- 보조 가용성 그룹은 동일한 데이터베이스 미러링 엔드포인트를 사용해야 합니다. 그렇지 않으면 로컬 장애 조치(failover) 후 복제가 중지됩니다.
- 기본 가용성 그룹은 동일한 가용성 모드에 있어야 합니다. 두 가용성 그룹이 모두 동기 커밋 모드이거나 둘 다 비동기 커밋 모드여야 합니다. 어떤 모드를 사용해야 할지 잘 모르는 경우, 장애 조치를 준비할 때까지 둘 다 비동기 커밋 모드를 설정하십시오.
상태 모니터링
분산 가용성 그룹은 SQL Server 전용 구문이며 기본 WSFC에는 표시되지 않습니다. 다음 코드 샘플에서는 각각 고유한 가용성 그룹이 있는 두 개의 서로 다른 WSFC(CLUSTER_A 및 CLUSTER_B)를 보여 줍니다. 여기서는 CLUSTER_A의 AG 1 및 CLUSTER_B의 AG 2에 대해서만 설명합니다.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
분산 가용성 그룹에 대한 자세한 정보는 모두 SQL Server, 특히 가용성 그룹 동적 관리 뷰에서 확인할 수 있습니다. 현재 분산 가용성 그룹에 대한 SQL Server Management Studio에 표시되는 유일한 정보는 가용성 그룹에 대한 주 복제본에서 확인할 수 있습니다. 다음 그림에서 확인할 수 있듯이 가용성 그룹 폴더의 SQL Server Management Studio에는 분산 가용성 그룹이 표시됩니다. 그림에서는 AG1이 분산 가용성 그룹이 아닌, 해당 인스턴스에 로컬로 존재하는 개별 가용성 그룹의 주 복제본으로 표시되었습니다.
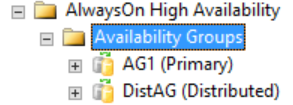
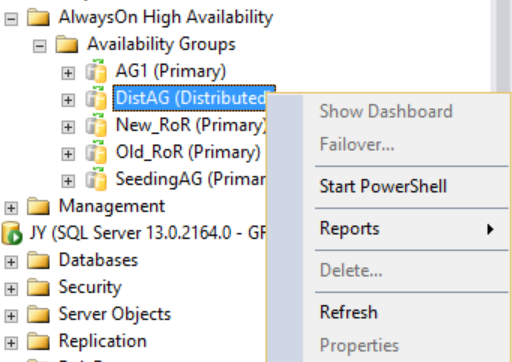
그러나 분산 가용성 그룹을 마우스 오른쪽 단추로 클릭할 경우 사용할 수 있는 옵션이 없으며(아래 그림 참조) 확장된 가용성 데이터베이스, 가용성 그룹 수신기 및 가용성 복제본 폴더가 모두 비어 있는 것을 확인할 수 있습니다. SQL Server Management Studio 16에서는 이러한 결과가 표시되지만 SQL Server Management Studio의 이후 버전에서 변경될 수 있습니다.
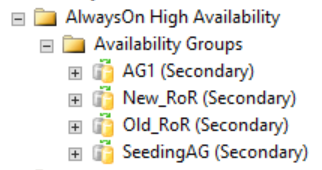
다음 그림에 표시된 것처럼 SQL Server Management Studio의 보조 복제본에는 분산 가용성 그룹과 관련된 항목이 아무것도 표시되지 않습니다. 이러한 가용성 그룹 이름은 이전 CLUSTER_A WSFC 이미지에 표시된 역할에 매핑합니다.
모든 가용성 복제본 이름을 나열하는 DMV
동적 관리 뷰를 사용하는 경우 동일한 개념이 적용됩니다. 다음 쿼리를 사용하여 모든 가용성 그룹(일반 및 분산) 및 그룹에 참여하는 노드를 확인할 수 있습니다. 이 결과는 분산 가용성 그룹에 참여하는 WSFC 중 하나에서 주 복제본을 쿼리할 경우에만 표시됩니다. 동적 관리 뷰 sys.availability_groups에는 이름이 is_distributed인 새 열이 표시되며 가용성 그룹이 분산 가용성 그룹인 경우 해당 열의 값은 1입니다. 이 열을 보려면:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
분산 가용성 그룹에 참여하는 두 번째 WSFC의 출력 예제가 다음 그림에 표시됩니다. SPAG1은 DENNIS와 JY라는 두 개의 복제본으로 구성되어 있습니다. 그러나 SPDistAG라는 이름의 분산 가용성 그룹에는 기존 가용성 그룹과 마찬가지로 인스턴스의 이름이 아닌 참여하는 가용성 그룹의 이름 2개(SPAG1 및 SPAG2)가 표시됩니다.
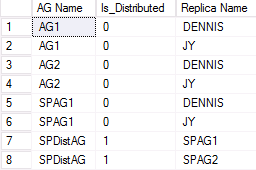
분산 AG 상태를 나열하는 DMV
SQL Server Management Studio에서 대시보드 및 다른 영역에 표시되는 모든 상태는 가용성 그룹 내의 로컬 동기화에만 해당됩니다. 분산 가용성 그룹의 상태를 표시하려면 동적 관리 뷰를 쿼리하세요. 다음 예제 쿼리는 이전 쿼리를 확장하고 구체화합니다.
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

기본 성능을 확인하는 DMV
이전 쿼리를 더 확장하기 위해 sys.dm_hadr_database_replicas_states를 추가하여 동적 관리 뷰를 통해 기본 성능을 확인할 수도 있습니다. 현재 동적 관리 뷰에는 보조 가용성 그룹에 대한 정보만 저장됩니다. 주 가용성 그룹에서 실행되는 다음 예제 쿼리는 아래에 표시된 샘플 출력을 생성합니다.
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

분산 AG에 대한 성능 카운터를 확인하는 DMV
아래 쿼리는 특정 분산 가용성 그룹과 연결된 성능 카운터를 표시합니다.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
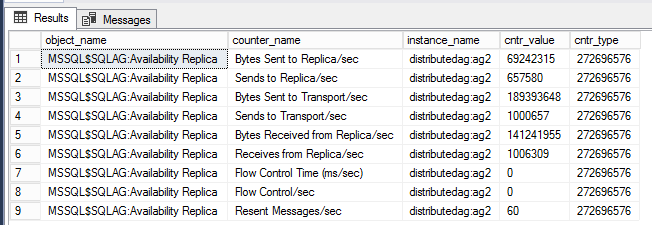
참고
LIKE 필터는 분산 가용성 그룹의 이름을 포함해야 합니다. 이 예제에서 분산 가용성 그룹의 이름은 'distributedag'입니다. 분산 가용성 그룹의 이름을 반영하도록 LIKE 한정자를 변경합니다.
AG와 분산 AG의 상태를 표시하는 DMV
아래 쿼리는 가용성 그룹과 분산 가용성 그룹의 상태에 대한 다양한 정보를 표시합니다. (Tracy Boggiano의 허가 하에 복제되었습니다.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

분산 AG의 메타데이터를 보려는 DMV
아래 쿼리는 분산 가용성 그룹을 비롯한 가용성 그룹에서 사용하는 엔드포인트 URL에 대한 정보를 표시합니다. (David Barbarin의 허락을 받아 복제되었습니다.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

시드의 현재 상태를 표시하는 DMV
아래 쿼리는 시드의 현재 상태에 대한 정보를 표시합니다. 복제본 간의 동기화 오류 문제를 해결하는 데 유용합니다. (David Barbarin의 허락을 받아 복제되었습니다.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
