Always On 가용성 그룹에 대한 성능 모니터링
적용 대상: ![]() SQL Server
SQL Server
Always On 가용성 그룹의 성능 측면은 중요 업무용 데이터베이스에 대한 SLA(서비스 수준 계약)를 유지하는 데 매우 중요합니다. 가용성 그룹이 로그를 보조 복제본(replica) 배포하는 방법을 이해한다면 가용성 구현의 RTO(복구 시간 목표) 및 RPO(복구 지점 목표)를 예측하며 성능이 저조한 가용성 그룹 또는 복제본(replica) 병목 상태를 식별하는 데 도움을 줄 수 있습니다. 이 문서에서는 동기화 프로세스를 설명하고, 일부 주요 메트릭을 계산하는 방법을 보여 주며, 일반적인 성능 문제 해결 시나리오에 대한 링크를 제공합니다.
데이터 동기화 프로세스
전체 동기화 시간을 예측하고 병목 상태를 식별하려면 동기화 프로세스를 이해해야 합니다. 성능 병목 상태는 프로세스의 어디에서나 발생할 수 있으며, 병목 상태를 찾는다면 기본 문제를 더 깊이 이해하는 데 도움이 될 수 있습니다. 다음 그림과 표에서 데이터 동기화 프로세스를 보여주고 있습니다:

| 순서 | 단계 설명 | 설명 | 유용한 메트릭 |
|---|---|---|---|
| 1 | 로그 생성 | 로그 데이터는 디스크에 플러시됩니다. 이 로그는 보조 복제본(replica)에 복제되어야 합니다. 로그 레코드는 송신 큐에 들어갑니다. | SQL Server:Database > Log bytes flushed\sec |
| 2 | 캡처 | 각 데이터베이스에 대한 로그가 캡처되어 해당 파트너 큐(데이터베이스 복제본(replica) 쌍당 하나)로 전송됩니다. 이 캡처 프로세스는 가용성 복제본(replica)이 연결되어 있으며 어떤 이유로든지 데이터 이동이 일시 중단되지 않는 한 계속 실행이 되므로 데이터베이스 복제본(replica) 쌍이 동기화 또는 동기화 중인 것으로 표시됩니다. 캡처 프로세스가 메시지를 아주 빠르게 검색하며 큐에 추가할 수 없는 경우 로그 송신 큐가 빌드됩니다. | SQL Server:Availability Replica > Bytes Sent to Replica\sec는 해당 가용성 복제본의 큐에 저장된 모든 데이터베이스 메시지의 합계를 집계한 것입니다. 기본 복제본(replica) log_send_queue_size (KB) 및 log_bytes_send_rate (KB/초)입니다. |
| 3 | 전송 | 각 데이터베이스 복제본(replica) 큐의 메시지는 큐에서 제거되고 유선을 통해 해당 보조 복제본(replica) 전송됩니다. | SQL Server:Availability Replica > Bytes sent to transport\sec |
| 4 | 수신 및 캐시 | 각 보조 복제본(replica) 메시지를 수신하며 캐시 합니다. | 성능 카운터 SQL Server:Availability Replica > Log Bytes Received/sec |
| 5 | 강화 | 강화를 위해서는 보조 복제본에서 로그가 플러시 됩니다. 로그가 플러시가 된 후 승인은 기본 복제본(replica)으로 다시 전송됩니다. 로그가 강화되면 데이터 손실은 방지됩니다. |
성능 카운터 SQL Swaierver:Database > Log Bytes Flushed/sec 대기 유형 HADR_LOGCAPTURE_SYNC |
| 6 | 다시 실행 | 보조 복제본(replica) 플러시된 페이지를 다시 실행합니다. 페이지가 다시 실행되기를 기다리고 있는 동안 다시 실행 큐에 유지됩니다. | SQL Server:Database Replica > Redone Bytes/sec redo_queue_size(KB) 및 redo_rate. 대기 유형 REDO_SYNC |
흐름 제어 게이트
가용성 그룹은 모든 가용성 복제본(replica) 네트워크 및 메모리 리소스와 같은 과도한 리소스 소비를 방지하기 위하여 주 복제본(replica) 흐름 제어 게이트를 사용하여 만들어졌습니다. 이러한 흐름 제어 게이트는 가용성 복제본의 동기화 상태에는 영향을 주지 않지만, RPO를 포함한 가용성 데이터베이스의 전체 성능에는 영향을 끼칠 수 있습니다.
기본 복제본(replica) 로그를 캡처한 후 두 가지 수준의 흐름 제어가 적용됩니다. 두 게이트의 메시지 임계값에 도달하면 로그 메시지는 특정 복제본(replica) 또는 특정 데이터베이스로 더 이상 전송되지 않습니다. 보낸 메시지에 대한 승인 메시지가 수신되면 메시지를 전송하여 보낸 메시지 수를 임계값 아래로 가져올 수 있습니다.
흐름 제어 게이트 이외에도 로그 메시지가 전송되지 않게 할 수 있는 또 다른 요소가 있습니다. 복제본(replica)을 동기화하면 메시지가 LSN(로그 시퀀스 번호)의 순서대로 전송되며 적용됩니다. 로그 메시지를 보내기 이전에 해당 LSN은 가장 낮은 승인된 LSN 번호를 확인하고 임계값 중 하나 미만인지를 확인합니다 (메시지 유형에 따라 다름). 두 LSN 숫자 사이의 간격이 임계값보다 큰 경우 메시지는 전송되지 않습니다. 간격이 다시 임계값보다 미만이 되면 메시지가 전송됩니다.
SQL Server 2022는 각 게이트에서 허용하는 메시지 수에 관한 제한을 증가시킵니다. 추적 플래그 12310을 사용하면 SQL Server 2019 CU9, SQL Server 2017 CU18 및 SQL Server 2016 SP1 CU16부터 SQL Server 버전에서도 증가된 제한을 사용할 수 있습니다.
다음 표에서는 예약된 메시지를 나열하고 있습니다:
추적 플래그 12310을 사용하도록 설정해 주는 SQL Server 2022 및 지원이 되는 SQL Server 버전(SQL Server 2019 CU9, SQL Server 2017 CU18 및 SQL Server 2016 SP1 CU16부터)은 다음 제한을 참조해 보세요:
| 수준 | 게이트 수 | 메시지 수 | 유용한 메트릭 |
|---|---|---|---|
| 전송 | 가용성 복제본(replica) 당 1 | 16384 | 확장 이벤트 hadron_database_flow_control_action |
| 데이터베이스 | 가용성 데이터베이스당 1개 | 7168 | DBMIRROR_SEND 확장 이벤트 hadron_database_flow_control_action |
두 가지 유용한 성능 카운터 SQL Server:Availability Replica > Flow control/sec 및 SQL Server:Availability Replica > Flow Control Time (ms/sec)은 마지막 초 이내에 흐름 제어가 활성화된 시간 및 흐름 제어를 하기 위해 대기하면서 소비한 시간도 보여 줍니다. 흐름 제어에 대한 대기 시간이 길어질수록 RPO가 높아집니다. 흐름 제어에서 높은 대기 시간을 초래할 수 있는 문제 유형에 관한 자세한 정보는 문제 해결: 가용성 그룹이 RPO를 초과함을 참조해 보세요.
장애 조치(failover) 시간 예측(RTO)
SLA의 RTO는 언제든지 Always On 구현의 장애 조치(failover) 시간에 따라 달라지고, 이는 다음 수식으로 표현할 수 있습니다:

중요
가용성 그룹이 가용성 데이터베이스를 두 개 이상 포함하는 경우 Tfailover가 가장 높은 가용성 데이터베이스가 RTO 준수를 위한 제한 값이 됩니다.
오류 감지 시간인 Tdetection은 시스템이 오류를 감지하는 데 걸리는 시간입니다. 이 시간은 클러스터 수준 설정에 따라 달라지며 개별 가용성 복제본에 의존하지 않습니다. 구성된 자동 장애 조치(failover) 조건에 따라 분리된 스핀 잠금처럼 중요한 SQL Server 내부 오류에 관한 즉각적인 응답으로 인해 장애 조치(failover)를 트리거할 수 있습니다. 이 경우 검색은 sp_server_diagnostics(Transact-SQL) 오류 보고서가 WSFC 클러스터로 전송되는 것만큼이나 빠르게 감지할 수 있습니다 (기본 간격은 상태 확인 시간 초과의 1/3). 클러스터 상태 확인 시간제한이 만료되었거나 (기본적으로 30초) 리소스 DLL과 SQL Server 인스턴스 간의 리스가 만료한(기본적으로 20초) 것과 같은 시간 제한 때문에 장애 조치(failover)가 트리거될 수도 있습니다. 이 경우에 있어서 검색 시간은 시간제한 간격만큼 깁니다. 자세한 내용은 가용성 그룹 자동 장애 조치(failover)에 대한 유연한 장애 조치 정책(SQL Server)을 참조해 주세요.
보조 복제본이 장애 조치(failover)를 위해 해야 할 유일한 작업은 로그의 끝까지 다시 실행하는 것 뿐입니다. 다시 실행 시간인 Tredo는 다음 공식을 사용해서 계산됩니다:

단, redo_queue는 redo_queue_size의 값이고 redo_rate는 redo_rate의 값입니다.
장애 조치(failover)오버헤드 시간인 Toverhead는 WSFC 클러스터를 장애 조치(failover)하고 데이터베이스를 온라인 상태로 전환하는 데 걸리는 시간을 포함합니다. 이 시간은 보통 짧고 일정합니다.
잠재적인 데이터 손실 예측(RPO)
SLA의 RPO는 언제든지 Always On 실행으로 발생할 수 있는 데이터 손실에 따라 달라집니다. 이러한 예상 데이터 손실은 다음 수식으로 나타낼 수 있습니다:

여기서, log_send_queue는 log_send_queue_size의 값이며 log generation rate는 SQL Server:Database > Log Bytes Flushed/sec의 값입니다.
경고
가용성 그룹이 가용성 데이터베이스를 두 개 이상 포함하는 경우 Tdata_loss가 가장 높은 가용성 데이터베이스가 RPO 준수를 하기 위한 제한값이 됩니다.
로그 전송 큐는 치명적인 오류로 인해 손실될 수 있는 모든 데이터를 나타냅니다. 처음에는 로그 생성 속도가 로그 전송 속도 대신 사용되는 것인지가 궁금합니다(log_send_rate 참조해 주세요). 그러나 로그 전송 속도를 사용하면 동기화할 시간만 제공이 되지만 RPO는 동기화 속도가 아니라 생성 속도에 따라 데이터 손실을 측정합니다.
Tdata_loss를 추정하는 간단한 방법은 last_commit_time 사용하는 것입니다. 기본 복제본(replica) DMV는 모든 복제본(replica)에 대해 이 값을 보고합니다. 주 복제본(replica) 값과 보조 복제본(replica) 값 간의 차이를 계산하여 보조 복제본(replica) 로그가 기본 복제본(replica)을 얼마나 빨리 따라잡는지 예측할 수 있습니다. 전에 말한 것처럼 이 계산은 로그가 생성되는 속도에 따라 잠재적인 데이터 손실을 알려주지는 않지만, 잠재적인 데이터 손실은 근사치가 되어야 합니다.
SSMS 대시보드를 사용하여 RTO 및 RPO 추정
Always On 가용성 그룹에서 RTO 및 RPO는 보조 복제본(replica) 호스트 되는 데이터베이스에 대해 계산되고 표시됩니다. 주 복제본(replica) 대시보드에서 RTO 및 RPO는 보조 복제본(replica)에 의해 그룹화됩니다.
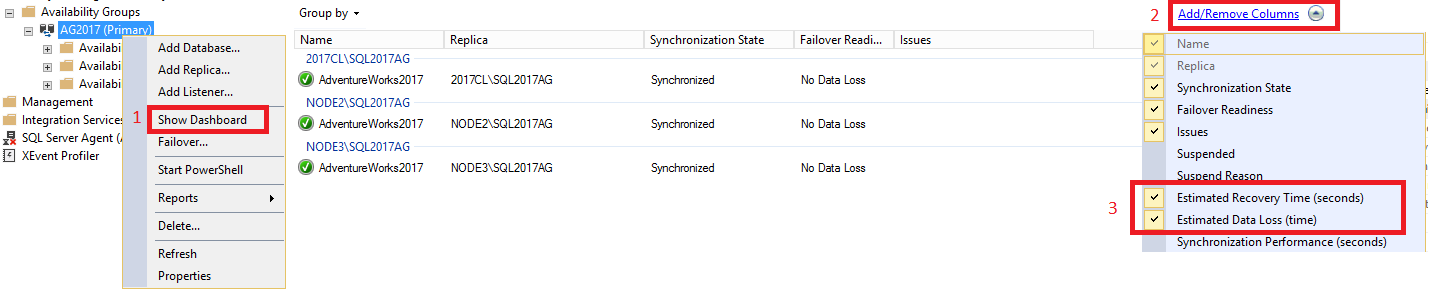
대시보드 내의 RTO 및 RPO를 보기 위하여 다음 사항을 따라 해 보세요:
SQL Server Management Studio에서 Always On 고가용성노드를 확장하고 가용성 그룹의 이름을 마우스 오른쪽 단추로 클릭한 후 대시보드 표시를 선택합니다.
그룹별 탭에서 열 추가/제거를 선택합니다. 예상 복구 시간(초)[RTO] 및 예상 데이터 손실(시간) [RPO]를 모두 확인합니다.
보조 데이터베이스 RTO 계산
복구 시간 계산은 장애 조치(failover) 발생 후 보조 데이터베이스를 복구하는 데 필요한 시간을 결정합니다. 장애 조치(failover) 시간은 보통 짧고 일정합니다. 검색 시간은 클러스터 개별 가용성 복제본이 아닌 클러스터 수준을 설정한 것에 따라 달라집니다.
보조 데이터베이스(DB_sec)의 경우 RTO의 계산 및 표시는 redo_queue_size 및 redo_rate 기반으로 합니다:
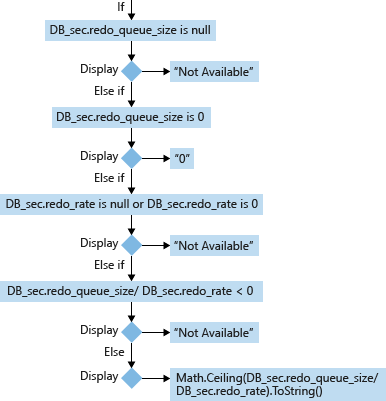
코너 사례를 제외하고는 보조 데이터베이스의 RTO를 계산하는 수식은 다음과 같습니다:
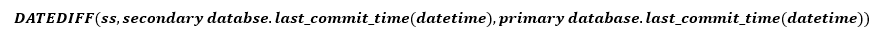
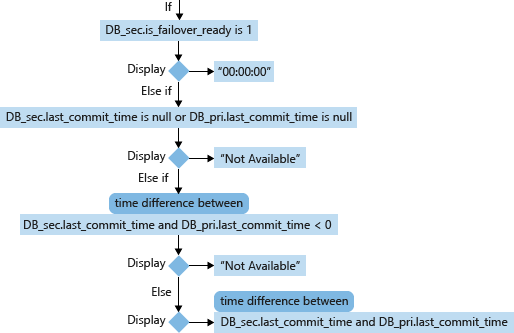
보조 데이터베이스 RPO 계산
DB_sec(보조 데이터베이스)의 경우 RPO의 계산 및 표시는 is_failover_ready, last_commit_time 및 상관관계가 있는 주 데이터베이스(DB_pri)의 last_commit_time 기반으로 합니다. 보조 database.is_failover_ready = 1이면 daa가 동기화되고 장애 조치(failover) 시 데이터 손실이 발생하지 않습니다. 그러나 이 값이 0이면 주 데이터베이스의 last_commit_time 보조 데이터베이스의 last_commit_time 사이에는 차이가 있습니다.
주 데이터베이스의 경우 last_commit_time은 최근에 트랜잭션이 커밋 된 시간입니다. 보조 데이터베이스의 경우 last_commit_time은 보조 데이터베이스에서도 성공적으로 강화된 주 데이터베이스의 트랜잭션에 대한 가장 최근의 커밋 시간입니다. 이 숫자는 주 데이터베이스와 보조 데이터베이스 모두에서 동일해야 합니다. 이 두 값 사이의 간격에는 보류 중인 트랜잭션이 보조 데이터베이스에서 강화되지 않은 기간이며 장애 조치(failover)가 발생할 경우 손실됩니다.
RTO/RPO 수식에 사용된 성능 카운터
- redo_queue_size (KB) [RTO에서 사용됨]: 다시 실행 큐 크기는 last_received_lsn 및 last_redone_lsn 사이의 트랜잭션 로그 크기입니다. last_received_lsn는 이 보조 데이터베이스를 호스팅하는 보조 복제본이 모든 로그 블록을 받은 지점을 식별하는 로그 블록 ID입니다. Last_redone_lsn는 보조 데이터베이스에서 다시 실행된 마지막 로그 레코드의 로그 시퀀스 번호입니다. 이 두 값을 기반으로 한 시작 로그 블록(last_received_lsn) 및 최종 로그 블록(last_redone_lsn)의 ID를 찾을 수 있습니다. 이 두 로그 블록 사이의 공간은 트랜잭션 로그 블록이 아직 다시 실행되지 않은 방법을 나타낼 수 있습니다. 이것은 KB(킬로바이트)로 측정됩니다.
- redo_rate(KB/초) [RTO에서 사용됨]: 경과된 시간 동안 보조 데이터베이스에서 다시 실행되었던 트랜잭션 로그(KB)의 양을 킬로바이트(KB)/escond 단위로 나타내고 있는 누적값입니다.
- last_commit_time (Datetime) [RPO에서 사용됨]: 주 데이터베이스의 경우 last_commit_time은 최근의 트랜잭션이 커밋된 시간입니다. 보조 데이터베이스의 경우 last_commit_time은 보조 데이터베이스에서도 성공적으로 강화된 주 데이터베이스의 트랜잭션에 대한 최근의 커밋 시간입니다. 보조 데이터베이스의 이 값은 주 데이터베이스의 동일한 값과 함께 동기화되어야 하므로 이 두 값 간의 간격은 RPO(데이터 손실)의 추정치입니다.
DMV를 사용한 RTO 및 RPO 예측
DMV sys.dm_hadr_database_복제본(replica)_states 쿼리하여 sys.dm_hadr_database_복제본(replica)_cluster_states 데이터베이스의 RPO 및 RTO를 예측할 수 있습니다. 다음 쿼리는 두 작업을 모두 실행하는 저장 프로시저를 만듭니다.
참고
RPO를 예측하기 위하여 저장 프로시저를 실행하는 데 필요한 값이므로 먼저 RTO를 예측하는 저장 프로시저를 만들고 실행해야 합니다.
RTO를 예측하기 위한 저장 프로시저 만들기
- 대상 보조 복제본(replica)에서 저장 프로시저 proc_calculate_RTO를 만듭니다. 이 저장 프로시저가 이미 있는 경우 먼저 삭제한 다음 다시 만듭니다.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- 대상 보조 데이터베이스의 이름으로 proc_calculate_RTO를 실행합니다:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
출력은 대상 보조 복제본(replica) 데이터베이스의 RTO 값을 표시합니다. RPO 추정 저장 프로시저에 사용할 group_id, replica_id 및 group_database_id를 저장합니다.
샘플 출력:
데이터베이스 DB_sec의 RTO는 0입니다
데이터베이스 DB4의 group_id는 F176DD65-C3EE-4240-BA23-EA615F965C9B입니다
데이터베이스 DB4의 복제본(replica)_id는 405554F6-3FDC-4593-A650-2067F5FABFFD입니다
데이터베이스 DB4의 group_database_id 는 39F7942F-7B5E-42C5-977D-02E7FFA6C392입니다
RPO를 예측하기 위한 저장 프로시저 만들기
- 기본 복제본(replica) 저장 프로시저 proc_calculate_RPO를 만듭니다. 이미 있는 경우 그것을 먼저 삭제한 다음 다시 만듭니다.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- 대상 보조 데이터베이스의 group_id, 복제본(replica)_id 및 group_database_id 사용하여 proc_calculate_RPO 실행합니다.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- 출력은 대상 보조 복제본(replica) 데이터베이스의 RPO 값을 표시합니다.
RTO 및 RPO에 대한 모니터링
이 섹션에서는 RTO 및 RPO 메트릭에 대한 가용성 그룹을 모니터링하는 방법을 설명합니다. 이 시연은 Always On 상태 모델, 2부: 상태 모델 확장에 제공된 GUI 자습서와 비슷합니다.
장애 조치(failover) 시간 예측(RTO) 및 RPO(잠재적인 데이터 손실 예측)의 장애 조치 시간 및 잠재적 데이터 손실 계산의 구성 요소는 정책 관리 패싯 데이터베이스 복제본 상태의 성능 메트릭으로 편리하게 제공됩니다(SQL Server 개체 의 정책 기반 관리 패싯 보기를 참조해 주세요). 일정에 따라 이러한 두 메트릭을 모니터링하고 메트릭이 RTO 및 RPO를 각각 초과하면 경고를 받을 수 있습니다.
시연된 스크립트는 다음과 같은 특징을 가지고 해당 일정에 따라서 실행되는 두 개의 시스템 정책을 만듭니다:
예상 장애 조치(failover) 시간이 10분을 초과할 때 실패하는 RTO 정책(5분마다 평가)
예상 데이터 손실이 1시간을 초과할 때 실패하는 RTO 정책이며, 이는 30분마다 평가됩니다
두 정책은 모든 가용성 복제본(replica)에 관하여 동일한 구성을 갖습니다
정책은 모든 서버에서 평가되지만 로컬 가용성 복제본이 주 복제본인 가용성 그룹에 대해서만 평가됩니다. 로컬 가용성 복제본이 주 복제본이 아닌 경우 정책은 평가되지 않습니다.
정책 오류는 기본 복제본(replica)에서 볼 때면 Always On 대시보드에 편리하게 표시됩니다.
정책을 만들기 위해서는 가용성 그룹에 참여하는 모든 서버 인스턴스에 대해 아래 지침을 따라 해 주세요:
SQL Server 에이전트 서비스를 아직 시작하지 않은 경우 SQL Server 에이전트 서비스를 시작합니다.
SQL Server Management Studio의 도구 메뉴에서 옵션을 클릭합니다.
SQL Server Always On 탭에서 사용자 정의 Always On 정책 사용을 선택하고 확인을 클릭합니다.
이 설정을 활성화하면 Always On 대시보드에 적절히 구성된 사용자 지정 정책을 표시할 수 있습니다.
다음 사양을 사용하여 정책 기반 관리 조건을 만듭니다:
이름:
RTO패싯: 데이터베이스 복제본 상태
필드:
Add(@EstimatedRecoveryTime, 60)연산자: <=
값:
600
장애 검색 및 장애 조치(failover)에 대한 60초의 오버헤드를 포함하여 잠재적인 장애 조치 시간이 10분을 초과할 때 이 조건은 실패합니다.
다음 사양을 사용하여 정책 기반 관리 조건을 만듭니다:
이름:
RPO패싯: 데이터베이스 복제본 상태
필드:
@EstimatedDataLoss연산자: <=
값:
3600
잠재적인 데이터 손실이 1시간을 초과할 때 이 조건은 실패합니다.
다음 사양을 사용하여 정책 기반 관리 조건을 만듭니다:
이름:
IsPrimaryReplica패싯: 가용성 그룹
필드:
@LocalReplicaRole연산자 :=
값:
Primary
이 조건은 지정된 가용성 그룹의 로컬 가용성 복제본(replica)이 기본 복제본(replica)인지 여부를 확인합니다.
다음 사양을 사용하여 정책 기반 관리 조건을 만듭니다:
일반 페이지:
이름:
CustomSecondaryDatabaseRTO상태 확인:
RTO대상에 대한: IsPrimaryReplica AvailabilityGroup의 모든 DatabaseReplicaState
이 설정을 사용하면 로컬 가용성 복제본이 주 복제본인 가용성 그룹에 관해서만 정책은 평가됩니다.
평가 모드: 일정에 따라
일정: CollectorSchedule_Every_5min
활성화됨: 선택됨
설명 페이지:
범주: 가용성 데이터베이스 경고
이 설정을 통해 정책 평가 결과가 Always On 대시보드에 표시될 수 있습니다.
설명: 현재 복제본(replica) 검색 및 장애 조치(failover)에 대한 오버헤드를 1분으로 가정할 때 10분을 초과하는 RTO가 있습니다. 해당 서버 인스턴스의 성능 문제를 즉시 조사해야 합니다.
표시할 텍스트: RTO 초과함!
다음 사양을 사용하여 정책 기반 관리 조건을 만듭니다:
일반 페이지:
이름:
CustomAvailabilityDatabaseRPO상태 확인:
RPO대상에 대한: IsPrimaryReplica AvailabilityGroup의 모든 DatabaseReplicaState
평가 모드: 일정에 따라
일정: CollectorSchedule_Every_30min
활성화됨: 선택됨
설명 페이지:
범주: 가용성 데이터베이스 경고
설명: 가용성 데이터베이스가 RPO를 1시간 초과했습니다. 가용성 복제본(replica)의 성능 문제를 즉시 조사해야 합니다.
표시할 텍스트: RPO 초과함!
작업이 완료됐을 때 각 정책 평가 일정에 대해 하나씩 두 개의 새 SQL Server 에이전트 작업이 만들어집니다. 이러한 작업에는 syspolicy_검사_schedule을 시작하는 이름이 있어야 합니다.
작업 기록을 보고 평가 결과를 검사할 수 있습니다. 평가 오류는 Windows 응용 프로그램(이벤트 뷰어의 경우)에도 이벤트 ID 34052로 기록됩니다. 정책 실패에 대한 경고를 보내기 위해 SQL Server 에이전트를 만들 수도 있습니다. 자세한 내용은 정책 관리자에게 정책 오류를 알리도록 경고 구성을 참조해 주세요.
성능 문제 해결 시나리오
다음 표에는 일반적인 성능 관련 문제 해결 시나리오가 나와 있습니다.
| 시나리오 | 설명 |
|---|---|
| 문제 해결: 가용성 그룹 초과 RTO | 데이터 손실 없이 자동 장애 조치(failover) 또는 계획된 수동 장애 조치 후 장애 조치 시간이 RTO를 초과합니다. 또는 동기 커밋 보조 복제본(예: 자동 장애 조치(failover) 파트너)의 장애 조치 시간을 예측할 때 RTO 초과를 발견할 수 있습니다. |
| 문제 해결: 가용성 그룹 초과 RPO | 강제 수동 장애 조치(failover)를 실행한 후 데이터 손실이 RPO보다 많습니다. 또는 비동기 커밋 보조 복제본의 잠재적 데이터 손실을 계산할 때 RPO 초과를 발견합니다. |
| 문제 해결: 보조 복제본에 반영되지 않은 주 복제본의 변경 내용 | 클라이언트 애플리케이션에서 주 복제본에 대한 업데이트를 성공적으로 완료하지만, 보조 복제본 쿼리는 변경 내용이 반영되지 않았다는 것을 보여줍니다. |
유용한 확장 이벤트
다음 확장 이벤트는 동기화 상태에서 복제본(replica) 문제를 해결할 때 유용합니다.
| 이벤트 이름 | 범주 | 채널 | 가용성 복제본(replica) |
|---|---|---|---|
| redo_caught_up | 트랜잭션 | 디버그 | 보조 |
| redo_worker_entry | 트랜잭션 | 디버그 | 보조 |
| hadr_transport_dump_message | alwayson |
디버그 | 기본 항목 |
| hadr_worker_pool_task | alwayson |
디버그 | 기본 항목 |
| hadr_dump_primary_progress | alwayson |
디버그 | 기본 항목 |
| hadr_dump_log_progress | alwayson |
디버그 | 기본 항목 |
| hadr_undo_of_redo_log_scan | alwayson |
Analytic | 보조 |
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기