적용 대상:![]() SQL Server on Linux
SQL Server on Linux
이 자습서에서는 온-프레미스 VM(가상 머신) 또는 Azure 기반 가상 머신에서 실행되는 Linux용 HPE Serviceguard를 사용하여 SQL Server 가용성 그룹을 구성하는 방법을 설명합니다.
HPE Serviceguard 클러스터에 대한 개요는 HPE Serviceguard 클러스터를 참조하세요.
참고
Microsoft에서는 데이터 이동, 가용성 그룹, SQL Server 구성 요소를 지원합니다. HPE Serviceguard 클러스터 및 쿼럼 관리 설명서와 관련된 지원은 HPE에 문의하세요.
이 자습서는 다음 작업으로 구성됩니다.
- 가용성 그룹에 포함하려는 세 VM 모두에 SQL Server를 설치합니다.
- VM에 HPE Serviceguard를 설치합니다.
- HPE Serviceguard 클러스터를 만듭니다.
- Azure Portal에서 부하 분산 장치를 만듭니다.
- 가용성 그룹을 만들고 가용성 그룹에 샘플 데이터베이스를 추가합니다.
- Serviceguard 클러스터 관리자를 통해 가용성 그룹에 SQL Server 워크로드를 배포합니다.
- 자동 장애 조치(failover)를 수행하고 노드를 클러스터에 다시 조인합니다.
사전 요구 사항
Azure에서 세 개의 Linux 기반 VM(Virtual Machines)을 만듭니다. Azure에서 Linux 기반 가상 머신을 만들려면 빠른 시작: Azure Portal에서 Linux 가상 머신 만들기 문서를 참고하세요. VM을 배포할 때는 HPE Serviceguard 지원 Linux 배포를 사용해야 합니다. 원하는 경우 온-프레미스 환경에서 로컬로 VM을 배포할 수도 있습니다.
지원되는 배포의 예는 Linux용 HPE Serviceguard를 참조하세요. 퍼블릭 클라우드 환경 지원에 대한 정보는 HPE에 문의하세요.
이 자습서의 지침은 Linux용 HPE Serviceguard에 대해 검증되었습니다. HPE에서 평가판 버전을 다운로드할 수 있습니다.
3개의 가상 머신 모두에 대한 LVM(논리 볼륨 탑재)의 SQL Server 데이터베이스 파일. HPE(Serviceguard Linux)에 대한 빠른 시작 가이드를 참조하세요.
VM에 OpenJDK Java 런타임이 설치되어 있는지 확인합니다. IBM Java SDK는 지원되지 않습니다.
SQL Server 설치
세 VM에서 이 자습서에 대해 선택한 Linux 배포판에 따라 다음 섹션의 단계 중 하나를 수행합니다. 이 단계에서는 SQL Server 및 도구를 설치합니다.
Red Hat Enterprise Linux(RHEL)
SLES(SUSE Linux Enterprise Server)
참고
SQL Server 2025(17.x)부터 SLES(SUSE Linux Enterprise Server)는 지원되지 않습니다.
이 단계를 완료하면 가용성 그룹에 참여할 세 VM 모두에 SQL Server 서비스 및 도구가 설치됩니다.
VM에 HPE Serviceguard 설치
이 단계에서는 3개의 VM 모두에 Linux용 HPE Serviceguard를 설치합니다. 다음 표에서는 각 서버가 클러스터에서 수행하는 역할에 대해 설명합니다.
| VM 수 | HPE Serviceguard 역할 | Microsoft SQL Server 가용성 그룹 복제본 역할 |
|---|---|---|
| 1 | HPE Serviceguard 클러스터 노드 | 주 복제본 |
| 1개 이상 | HPE Serviceguard 클러스터 노드 | 보조 복제본 |
| 1 | HPE Serviceguard 쿼럼 서버 | 구성 전용 복제본 |
참고
UI를 통해 HPE Serviceguard 클러스터를 설치하고 구성하는 방법을 설명하는 HPE의 이 비디오를 참조하세요.
Serviceguard를 설치하려면 cminstaller 메서드를 사용합니다. 아래 링크에서 특정 지침을 사용할 수 있습니다.
- 두 노드에 Linux용 Serviceguard를 설치합니다. Install_serviceguard_using_cminstaller 섹션을 참조하세요.
- 세 번째 노드에 Serviceguard 쿼럼 서버를 설치합니다. Install_QS_from_the_ISO 섹션을 참조하세요.
HPE Serviceguard 클러스터 설치를 완료한 후 주 복제본 노드의 TCP 포트 5522에서 클러스터 관리 포털을 사용하도록 설정할 수 있습니다. 다음 단계에서는 방화벽에 5522를 허용하는 규칙을 추가합니다. 다음 명령은 Red Hat Enterprise Linux(RHEL)를 위한 명령 입니다. 다른 배포에 대해 유사한 명령을 실행해야 합니다.
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
HPE Serviceguard 클러스터 만들기
이러한 지침에 따라 HPE Serviceguard 클러스터를 구성하고 만드세요. 이 단계에서는 쿼럼 서버도 구성합니다.
- 세 번째 노드에서 Serviceguard 쿼럼 서버를 구성합니다. Configure_QS 섹션을 참조하세요.
- 다른 두 노드에서 Serviceguard 클러스터를 구성하고 만듭니다. Configure_and_create_Cluster 섹션을 참조하세요.
참고
VM을 만들 때 Azure VM Marketplace에서 SGLX(Linux용 HPE Serviceguard) 확장을 추가하여 HPE Serviceguard 클러스터 및 쿼럼의 수동 설치를 무시할 수 있습니다.
가용성 그룹을 만들고 샘플 데이터베이스 추가
이 단계에서는 데이터 보호를 제공하고 고가용성을 제공할 수 있는 두 개 이상의 동기 복제본과 구성 전용 복제본이 있는 가용성 그룹을 만듭니다. 다음 다이어그램은 이 아키텍처를 나타냅니다.
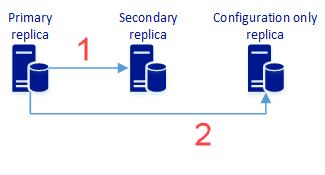
보조 복제본에 사용자 데이터 동기 복제. 가용성 그룹 구성 메타데이터도 포함합니다.
가용성 그룹 구성 메타데이터 동기 복제. 사용자 데이터는 포함하지 않습니다.
자세한 내용은 가용성 그룹 구성의 고가용성 및 데이터 보호를 참조하세요.
가용성 그룹을 만들려면 다음 단계를 수행합니다.
- 구성 전용 복제본을 포함한 모든 VM에서 가용성 그룹을 사용하도록 설정하고 mssql-server를 다시 시작합니다.
-
AlwaysOn_health이벤트 세션을 사용하도록 설정 (선택 사항) - 주 VM에서 인증서 만들기
- 보조 서버에서 인증서 만들기
- 복제본에서 데이터베이스 미러링 엔드포인트 만들기
- 가용성 그룹 만들기
- 보조 복제본 조인
- 가용성 그룹에 데이터베이스 추가
가용성 그룹 사용 설정 및 mssql-server 다시 시작
SQL Server 인스턴스를 호스트하는 모든 노드에서 가용성 그룹을 사용하도록 설정합니다. 그런 다음, mssql-server를 다시 시작합니다. 세 노드에서 모두 다음 스크립트를 실행합니다.
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
AlwaysOn_health 이벤트 세션을 사용하도록 설정 (선택 사항)
필요에 따라 가용성 그룹 문제를 해결할 때 근본 원인 진단에 도움이 되도록 Always On 가용성 그룹 확장 이벤트를 사용하도록 설정합니다. SQL Server의 각 인스턴스에서 다음 명령을 실행합니다.
ALTER EVENT SESSION AlwaysOn_health ON SERVER
WITH (STARTUP_STATE = ON);
GO
주 VM에서 인증서 만들기
다음 Transact-SQL 스크립트는 마스터 키와 인증서를 만듭니다. 그런 다음, 인증서를 백업하고 프라이빗 키로 파일을 보호합니다. 강력한 암호로 스크립트를 업데이트합니다. 주 SQL Server 인스턴스에 연결하고 다음 Transact-SQL 스크립트를 실행합니다.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<private-key-password>'
);
이제 주 SQL Server 복제본은 /var/opt/mssql/data/dbm_certificate.cer에 인증서, var/opt/mssql/data/dbm_certificate.pvk에 프라이빗 키를 가지고 있습니다. 이러한 두 파일을 가용성 복제본을 호스트하는 모든 서버의 동일한 위치로 복사합니다. 이 파일에 접근하려면 mssql 사용자를 이용하거나 mssql 사용자에게 권한을 부여하세요.
예를 들어 원본 서버에서 다음 명령은 파일을 대상 컴퓨터에 복사합니다.
node2 값을 보조 SQL Server 인스턴스를 실행하는 호스트의 이름으로 바꿉니다. 구성 전용 복제본에서 인증서를 복사하고 해당 노드에서 다음 명령을 실행합니다.
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
이제 보조 인스턴스를 실행하는 보조 VM 및 SQL Server의 구성 전용 복제본에서 사용자가 복사한 인증서를 소유할 수 있도록 mssql 다음 명령을 실행합니다.
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
보조 서버에서 인증서 만들기
다음 Transact-SQL 스크립트는 기본 SQL Server 복제본에 대해 만든 백업을 사용하여 마스터 키와 인증서를 만듭니다. 강력한 암호로 스크립트를 업데이트합니다. 암호 해독 암호는 이전 단계에서 파일을 만드는 .pvk 데 사용한 암호와 동일합니다. 인증서를 만들려면 구성 전용 복제본을 제외한 모든 보조 서버에서 다음 스크립트를 실행합니다.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<private-key-password>'
);
이전 예제에서는 주 복제본에서 인증서를 만들 때 사용한 것과 동일한 암호로 바꿉 <private-key-password> 다.
복제본에서 데이터베이스 미러링 엔드포인트 만들기
주 복제본과 보조 복제본에서 다음 명령을 실행하여 데이터베이스 미러링 엔드포인트를 만듭니다.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
참고
5022는 데이터베이스 미러링 엔드포인트에 사용되는 표준 포트이지만, 사용 가능한 다른 포트로 변경할 수 있습니다.
구성 전용 복제본에서 다음 명령을 사용하여 데이터베이스 미러링 엔드포인트를 만듭니다. 구성 전용 복제본에 필요한 역할인 WITNESS에 대한 값을 Role로 설정합니다.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
가용성 그룹 만들기
주 복제본 인스턴스에서 아래 명령을 실행합니다. 이러한 명령은 외부 ag1가 있는 cluster_type라는 가용성 그룹을 만들고 가용성 그룹에 데이터베이스 만들기 권한을 부여합니다.
다음 스크립트를 실행하기 전에, <node1>, <node2>, 및 <node3> (구성 전용 복제본) 자리 표시자를 이전 단계에서 만든 VM의 이름으로 바꾸십시오.
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
보조 복제본 연결
모든 보조 복제본에서 아래 명령을 실행합니다. 이러한 명령은 주 복제본이 있는 ag1 가용성 그룹에 보조 복제본을 조인하고, ag1 가용성 그룹에 데이터베이스 만들기 액세스 권한을 제공합니다.
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
가용성 그룹에 데이터베이스 추가
주 복제본에 연결하고 아래의 T-SQL 명령을 실행하여 다음을 수행합니다.
가용성 그룹에 추가할 샘플
db1데이터베이스를 만듭니다.CREATE DATABASE [db1]; GO데이터베이스의 복구 모델을 Full로 설정합니다. 가용성 그룹의 모든 데이터베이스에는 전체 복구 모델이 필요합니다.
ALTER DATABASE [db1] SET RECOVERY FULL;데이터베이스를 백업합니다. 데이터베이스를 가용성 그룹에 추가하려면 먼저 하나 이상의 전체 백업이 필요합니다.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';데이터베이스를 전체 복구 모델로 설정합니다.
ALTER DATABASE [db1] SET RECOVERY FULL;데이터베이스를 디스크에 백업합니다.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';가용성 그룹에 데이터베이스
db1를 추가합니다.ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
이전 단계를 완료하면 가용성 그룹이 표시됩니다 ag1 . 세 개의 VM은 하나의 주 복제본, 하나의 보조 복제본 및 하나의 구성 전용 복제본이 있는 복제본으로 추가됩니다.
ag1에는 하나의 데이터베이스가 포함됩니다.
SQL Server 가용성 그룹 워크로드 배포(HPE 클러스터 관리자)
HPE Serviceguard에서 Serviceguard 클러스터 관리자 UI를 통해 가용성 그룹에 SQL Server 워크로드를 배포합니다.
Serviceguard 관리자 그래픽 사용자 인터페이스를 사용하여 Serviceguard 클러스터를 통해 가용성 그룹 워크로드를 배포하고 HA(고가용성) 및 DR(재해 복구)을 사용하도록 설정합니다. Always On 가용성 그룹에 대한 Linux에서 Microsoft SQL Server 보호 섹션을 참조하세요.
Azure Portal에서 부하 분산 장치 만들기
Azure Cloud에서 배포하는 경우 Linux용 HPE Serviceguard에는 기존 IP 주소를 대체하기 위해 주 복제본과의 클라이언트 연결을 사용하도록 설정하는 부하 분산 장치가 필요합니다.
Azure 포털에서 Serviceguard 클러스터 노드 또는 가상 머신을 포함하는 리소스 그룹을 엽니다.
리소스 그룹에서 추가를 선택합니다.
“부하 분산” 장치를 검색한 후 검색 결과에서 Microsoft에서 게시하는 부하 분산 장치를 선택합니다.
부하 분산 장치 창에서 만들기를 선택합니다.
다음으로 부하 분산 장치를 구성합니다.
설정 값 이름 부하 분산 이름입니다. 예들 들어 SQLAvailabilityGroupLB입니다.형식 내부 SKU 기본 또는 표준 가상 네트워크 VM 복제본에 사용되는 가상 네트워크 서브넷 SQL Server 인스턴스가 호스트되는 서브넷 IP 주소 할당 정적 개인 IP 주소 서브넷 내에서 개인 IP 만들기 구독 관련 구독 선택 리소스 그룹 관련 리소스 그룹 선택 위치 SQL 노드와 동일한 위치 선택
백 엔드 풀 구성
백 엔드 풀은 Serviceguard 클러스터가 구성된 두 인스턴스의 주소입니다.
- 리소스 그룹에서 만든 부하 분산 장치를 클릭합니다.
- 설정>백 엔드 풀로 이동하고 추가를 선택하여 백 엔드 주소 풀을 만듭니다.
- 백 엔드 풀 추가에서 이름에 백 엔드 풀의 이름을 입력합니다.
- 다음에 연결됨에서 가상 머신을 선택합니다.
- 환경에서 가상 머신을 선택하고 각 선택 영역에 적절한 IP 주소를 연결합니다.
- 추가를 선택합니다.
프로브 만들기
프로브는 Azure가 주 복제본인 Serviceguard 클러스터 노드를 확인하는 방법을 정의합니다. Azure는 프로브를 만들 때 정의한 포트의 IP 주소를 기반으로 서비스를 프로브합니다.
부하 분산 설정 창에서 상태 프로브를 선택합니다.
상태 프로브 창에서 추가를 선택합니다.
다음 값을 사용하여 프로브를 구성합니다.
설정 값 이름 프로브를 나타내는 이름입니다. 예들 들어 SQLAGPrimaryReplicaProbe입니다.프로토콜 TCP 포트 사용 가능한 포트를 사용할 수 있습니다. 예를 들어 59999입니다. 간격 5 비정상 임계값 2 확인을 선택합니다.
모든 가상 머신에 로그인하고 다음 명령을 사용하여 프로브 포트를 엽니다.
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
Azure는 프로브를 만든 다음, 이를 사용하여 가용성 그룹의 주 복제본 인스턴스가 실행되고 있는 Serviceguard 노드를 테스트합니다. Serviceguard 클러스터에 AG를 배포하는 데 필요한 구성 포트(59999)를 기억하세요.
부하 분산 규칙 설정
부하 분산 규칙은 부하 분산 장치가 클러스터의 주 복제본인 Serviceguard 노드로 트래픽을 라우팅하는 방법을 구성합니다. Serviceguard 클러스터 노드 중 하나만 한 번에 주 복제본일 수 있으므로 이 부하 분산 장치의 경우 직접 서버 반환을 사용하도록 설정합니다.
부하 분산 장치 설정에서 부하 분산 규칙을 선택합니다.
부하 분산 규칙에서 추가를 선택합니다.
다음 설정을 사용하여 부하 분산 규칙을 구성합니다.
설정 값 이름 부하 분산 규칙을 나타내는 이름입니다. 예들 들어 SQLAGPrimaryReplicaListener입니다.프로토콜 TCP 포트 1433 백 엔드 포트 1433. 이 규칙은 부동 IP를 사용하므로 이 값은 무시됩니다. 프로브 이 부하 분산 장치에 대해 만든 프로브의 이름을 사용합니다. 세션 지속성 없음 유휴 제한 시간(분) 4 부동 IP 사용 확인을 선택합니다.
Azure에서 부하 분산 규칙이 구성됩니다. 이제 부하 분산 장치는 클러스터의 주 복제본 인스턴스인 Serviceguard 노드로 트래픽을 라우팅하도록 구성됩니다.
Serviceguard 클러스터에 AG를 배포해야 하는 부하 분산 장치의 프런트 엔드 IP 주소 LbReadWriteIP를 기록해 둡니다.
현재 리소스 그룹에는 모든 Serviceguard 노드에 연결되는 부하 분산 장치가 있습니다. 또한 부하 분산 장치에는 클라이언트가 클러스터의 주 복제본 인스턴스에 연결할 수 있는 IP 주소가 포함되어 있으므로 주 복제본인 모든 컴퓨터가 가용성 그룹에 대한 요청에 응답할 수 있습니다.
자동 장애 조치(failover)를 수행하고 노드를 클러스터에 다시 조인
자동 장애 조치 테스트의 경우 주 복제본의 전원을 꺼서 오프라인으로 전환합니다. 이 작업은 주 노드의 갑작스런 사용 불가를 복제합니다. 예상되는 동작은 다음과 같습니다.
클러스터 관리자가 가용성 그룹의 보조 복제본 중 하나를 주 복제본으로 승격합니다.
실패한 주 복제본은 다시 시작한 후 클러스터에 자동으로 조인됩니다. 클러스터 관리자는 이를 보조 복제본으로 승격합니다.
HPE Serviceguard의 경우 장애 조치(failover) 준비에 대한 설치 테스트를 참조하세요.