SQL Server에 대한 RHEL 장애 조치(failover) 클러스터 인스턴스(FCI) 운영
적용 대상: ![]() SQL Server - Linux
SQL Server - Linux
이 문서에서는 Red Hat Enterprise Linux를 사용하는 공유 디스크 장애 조치(failover) 클러스터에서 SQL Server에 대해 다음 작업을 수행하는 방법을 설명합니다.
- 수동으로 클러스터 장애 조치(failover)
- 장애 조치(failover) 클러스터 SQL Server 서비스 모니터링
- 클러스터 노드 추가
- 클러스터 노드 제거
- SQL Server 리소스 모니터링 빈도 변경
아키텍처 설명
클러스터링 계층은 Pacemaker 위에 빌드된 RHEL(Red Hat Enterprise Linux) HA 추가 기능을 기반으로 합니다. Corosync 및 Pacemaker는 클러스터 통신과 리소스 관리를 조정합니다. SQL Server 인스턴스는 한 노드 또는 다른 노드에서 활성화됩니다.
다음 다이어그램에서는 SQL Server가 있는 Linux 클러스터의 구성 요소를 보여 줍니다.
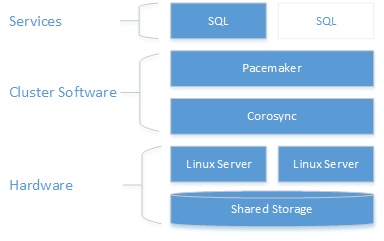
클러스터 구성, 리소스 에이전트 옵션 및 관리에 대한 자세한 내용은 RHEL 참조 설명서를 참조하세요.
수동으로 클러스터 장애 조치(failover)
resource move 명령은 리소스가 대상 노드에서 시작되도록 강제하는 제약 조건을 만듭니다. move 명령을 실행한 후 리소스 clear을(를) 실행하면 제약 조건이 제거되므로 리소스를 다시 이동하거나 리소스가 자동으로 장애 조치(failover)되도록 할 수 있습니다.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
다음 예제에서는 mssqlha 리소스를 sqlfcivm2라는 이름의 노드로 이동한 다음 나중에 리소스가 다른 노드로 이동할 수 있도록 제약 조건을 제거합니다.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
장애 조치(failover) 클러스터 SQL Server 서비스 모니터링
현재 클러스터 상태를 확인합니다.
sudo pcs status
클러스터 및 리소스의 라이브 상태 보기:
sudo crm_mon
/var/log/cluster/corosync.log에서 리소스 에이전트 로그 보기
클러스터에 노드 추가
각 노드의 IP 주소를 확인합니다. 다음 스크립트는 현재 노드의 IP 주소를 보여 줍니다.
ip addr show새 노드에는 15자 이하의 고유 이름이 필요합니다. Red Hat Linux에서 기본적으로 컴퓨터 이름은
localhost.localdomain입니다. 이 기본 이름은 고유하지 않을 수 있으며 너무 깁니다. 새 노드에 컴퓨터 이름을 설정합니다. 컴퓨터 이름을/etc/hosts에 추가하여 설정합니다. 다음 스크립트를 사용하면/etc/hosts를vi로 편집할 수 있습니다.sudo vi /etc/hosts다음 예제에서는
sqlfcivm1,sqlfcivm2, 및sqlfcivm3(이)라는 세 개의 노드의 정보가 추가된/etc/hosts을(를) 보여 줍니다.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3이 파일은 모든 노드에서 동일해야 합니다.
새 노드에서 SQL Server 서비스를 중지합니다.
지침에 따라 데이터베이스 파일 디렉터리를 공유 위치에 탑재합니다.
NFS 서버에서
nfs-utils을(를) 설치합니다.sudo yum -y install nfs-utils클라이언트 및 NFS 서버에서 방화벽 열기
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadmount 명령을 포함하도록
/etc/fstab파일을 편집합니다.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intr변경 내용을 적용하려면
mount -a을(를) 실행하세요.새 노드에서 Pacemaker 로그인을 위한 SQL Server 사용자 이름 및 비밀번호를 저장할 파일을 만듭니다. 다음 명령은 이 파일을 만들고 채웁니다.
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<loginPassword>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwd새 노드에서 Pacemaker 방화벽 포트를 엽니다.
firewalld를 사용하여 이러한 포트를 열려면 다음 명령을 실행합니다.sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reload기본 제공된 고가용성 구성이 없는 또 다른 방화벽을 사용하는 경우 Pacemaker가 클러스터의 다른 노드와 통신할 수 있으려면 다음 포트를 열어야 합니다.
- TCP: 포트 2224, 3121, 21064
- UDP: 포트 5405
새 노드에 Pacemaker 패키지를 설치합니다.
sudo yum install pacemaker pcs fence-agents-all resource-agentsPacemaker 및 Corosync 패키지를 설치할 때 생성된 기본 사용자의 암호를 설정합니다. 기존 노드와 동일한 암호를 사용합니다.
sudo passwd haclusterpcsd서비스 및 Pacemaker를 사용하도록 설정하고 시작합니다. 이렇게 하면 다시 부팅된 후 새 노드가 클러스터에 다시 조인할 수 있습니다. 새 노드에서 다음 명령을 실행합니다.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerSQL Server용 FCI 리소스 에이전트를 설치합니다. 새 노드에서 다음 명령을 실행합니다.
sudo yum install mssql-server-ha클러스터의 기존 노드에서 새 노드를 인증하고 클러스터에 추가합니다.
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>다음 예제에서는 vm3이라는 노드를 클러스터에 추가합니다.
sudo pcs cluster auth sudo pcs cluster start
클러스터에서 노드 제거
클러스터에서 노드를 제거하려면 다음 명령을 실행합니다.
sudo pcs cluster node remove <nodeName>
sqlservr 리소스 모니터링 간격의 빈도 변경
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
다음 예제에서는 mssql 리소스에 대한 모니터링 간격을 2초로 설정합니다.
sudo pcs resource op monitor interval=2s mssqlha
SQL Server에 대한 Red Hat Enterprise Linux 공유 디스크 클러스터 문제 해결
클러스터 문제를 해결할 때 세 디먼(daemon)이 함께 작동하여 클러스터 리소스를 관리하는 방법을 이해하는 데 도움이 됩니다.
| 디먼 | 설명 |
|---|---|
| Corosync | 클러스터 노드 간 Quorum 멤버십 및 메시징을 제공합니다. |
| Pacemaker | Corosync의 맨 위에 있으며 리소스에 대한 상태 머신을 제공합니다. |
| PCSD | pcs 도구를 통해 Pacemaker와 Corosync를 모두 관리합니다. |
pcs 도구를 사용하려면 PCSD가 실행 중이어야 합니다.
현재 클러스터 상태
sudo pcs status는 각 노드의 클러스터, 쿼럼, 노드, 리소스 및 디먼 상태에 대한 기본 정보를 반환합니다.
정상 pacemaker 쿼럼 출력의 예는 다음과 같습니다.
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
이 예제에서 partition with quorum은 노드의 과반수 쿼럼이 온라인 상태임을 의미합니다. 클러스터가 노드의 과반수 Quorum을 잃으면 pcs status이(가) partition WITHOUT quorum을(를) 반환하고 모든 리소스가 중지됩니다.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3]는 현재 클러스터에 참여하는 모든 노드의 이름을 반환합니다. 참여하지 않는 노드가 있으면 pcs status이(가) OFFLINE: [<nodename>]을(를) 반환합니다.
PCSD Status은(는) 각 노드에 대한 클러스터 상태를 표시합니다.
노드가 오프라인 상태일 수 있는 이유
노드가 오프라인일 경우 다음 항목을 확인합니다.
방화벽
Pacemaker가 통신할 수 있으려면 모든 노드에서 다음 포트가 열려 있어야 합니다.
- **TCP: 2224, 3121, 21064
Pacemaker 또는 Corosync 서비스 실행 중
노드 통신
노드 이름 매핑