자습서: R에서 SQL 기계 학습을 사용하여 클러스터링 모델 빌드
적용 대상:![]() SQL Server 2016(13.x) 이상
SQL Server 2016(13.x) 이상 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
4부로 구성된 이 자습서 시리즈의 3부에서는 R에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 파트에서는 SQL Server Machine Learning Services 또는 빅 데이터 클러스터를 사용하여 이 모델을 데이터베이스에 배포합니다.
4부로 구성된 이 자습서 시리즈의 3부에서는 R에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 파트에서는 SQL Server Machine Learning Services를 사용하여 이 모델을 데이터베이스에 배포합니다.
4부로 구성된 이 자습서 시리즈의 3부에서는 R에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 파트에서는 SQL Server R Services를 사용하여 이 모델을 데이터베이스에 배포합니다.
4부로 구성된 이 자습서 시리즈의 3부에서는 R에서 K-평균 모델을 빌드하여 클러스터링을 수행합니다. 이 시리즈의 다음 부분에서는 Azure SQL Managed Instance Machine Learning Services를 사용하여 데이터베이스에 이 모델을 배포합니다.
이 문서에서는 다음을 수행하는 방법을 알아봅니다.
- KI-평균 알고리즘에 대한 클러스터 수 정의
- 클러스터링 수행
- 결과 분석
1부에서는 사전 요구 사항을 설치하고 샘플 데이터베이스를 복원했습니다.
2부에서는 클러스터링을 수행하기 위해 데이터베이스의 데이터를 준비하는 방법을 배웠습니다.
4부에서는 새 데이터를 기준으로 R에서 클러스터링을 수행할 수 있는 저장 프로시저를 데이터베이스에서 만드는 방법을 알아봅니다.
사전 요구 사항
클러스터 수 정의
고객 데이터를 클러스터링하기 위해서는 데이터 그룹화를 위해 가장 잘 알려져 있고 가장 간단한 방법 중 하나인 K-평균 클러스터링 알고리즘을 사용합니다. K-평균에 대한 자세한 내용은 K-평균 클러스터링 알고리즘에 대한 전체 가이드를 참조하세요.
이 알고리즘은 두 가지 입력을 허용합니다. 이 두 가지는 데이터 자체와 생성할 클러스터 수를 나타내는 미리 정의된 숫자인 "k"입니다. 출력은 클러스터 간에 분할된 입력 데이터를 포함하는 k 클러스터입니다.
알고리즘에 사용할 클러스터 수를 결정하려면 추출된 클러스터 수만큼 제곱의 내부 그룹 합계의 플롯을 사용합니다. 사용할 적절한 클러스터 수는 플롯의 굽은 지점 또는 "elbow"에 있습니다.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
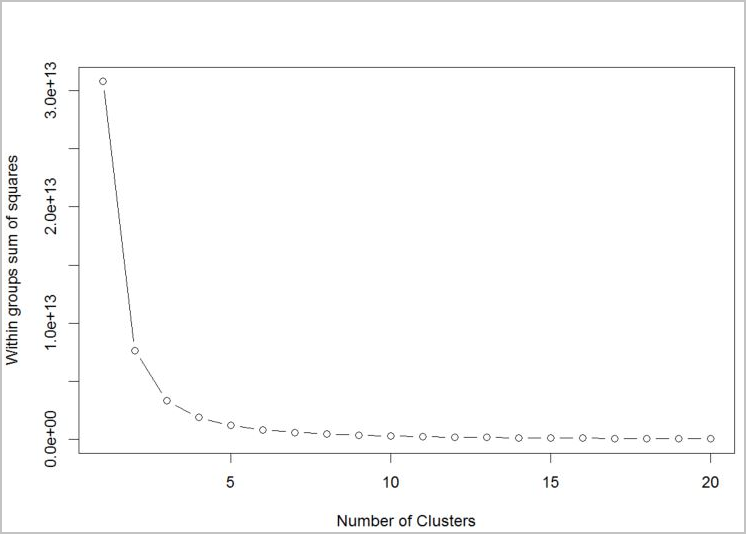
그래프에 따르면 k = 4가 적합한 값으로 보입니다. 이 k 값은 고객을 4개 클러스터로 그룹화합니다.
클러스터링 수행
다음 R 스크립트에서는 kmeans 함수를 사용하여 클러스터링을 수행합니다.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering ouput for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
결과 분석
K-평균을 사용하여 클러스터링을 완료했으므로, 이제 결과를 분석하고 실행 가능한 정보를 찾을 수 있는지 확인할 차례입니다.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
2부에 정의된 변수를 사용하여 4개의 클러스터 평균이 제공되었습니다.
- orderRatio = 반품 주문 비율(전체 주문 수 대비 부분 또는 전체적으로 반품된 주문 합계 수)
- itemsRatio = 반품 항목 비율(구입한 항목 수 대비 반품된 총 항목 수)
- monetaryRatio = 반품 금액 비율(구입한 금액 대비 반품된 항목의 총 금액)
- frequency = 반품 빈도
K-평균을 사용한 데이터 마이닝에는 결과에 대한 추가 분석 및 각 클러스터에 대한 이해 수준 향상을 위한 추가 단계가 필요한 경우가 많지만, 이를 통해 좋은 효과를 얻을 수 있습니다. 이러한 결과를 해석할 수 있는 몇 가지 방법은 다음과 같습니다.
- 클러스터 1(가장 큰 클러스터)은 적극적이지 않은 고객 그룹인 것 같습니다(모든 값이 0).
- 클러스터 3은 반품 비중이 높은 그룹으로 보입니다.
리소스 정리
이 자습서를 계속 진행할 생각이 없으면 tpcxbb_1gb 데이터베이스를 삭제하세요.
다음 단계
이 자습서 시리즈의 3부에서는 다음 작업을 수행하는 방법을 알아보았습니다.
- KI-평균 알고리즘에 대한 클러스터 수 정의
- 클러스터링 수행
- 결과 분석
만든 기계 학습 모델을 배포하려면 다음 자습서 시리즈의 4부를 따르세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기