적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
최소한 모든 SQL Server 데이터베이스에는 데이터 파일과 로그 파일이라는 두 개의 운영 체제 파일이 있습니다. 데이터 파일은 테이블, 인덱스, 저장 프로시저 및 뷰 등의 개체와 데이터를 포함합니다. 로그 파일에는 데이터베이스의 모든 트랜잭션을 복구하는 데 필요한 정보가 포함되어 있습니다. 배정 및 관리 목적으로 파일 그룹에서 데이터 파일을 그룹화할 수 있습니다.
데이터베이스 파일
SQL Server 데이터베이스에는 다음 표에 설명된 것처럼 세 가지 유형의 파일이 있습니다.
| 파일 | 설명 |
|---|---|
| 기본 | 데이터베이스에 대한 시작 정보를 포함하고 데이터베이스의 다른 파일을 가리킵니다. 모든 데이터베이스에는 하나의 기본 데이터 파일이 있습니다. 권장되는 주 데이터 파일의 파일 이름 확장명은 .mdf입니다. |
| 부차적인 | 선택적 사용자 정의 데이터 파일입니다. 각 파일을 다른 디스크 드라이브에 배치하여 여러 디스크에 데이터를 분배할 수 있습니다. 권장되는 보조 데이터 파일의 파일 이름 확장명은 .ndf입니다. |
| 트랜잭션 로그 | 로그는 데이터베이스를 복구하는 데 사용되는 정보를 보유합니다. 각 데이터베이스마다 하나 이상의 로그 파일이 있어야 합니다. 권장되는 트랜잭션 로그의 파일 이름 확장명은 .ldf입니다. |
예를 들어 Sales라고 하는 단순한 데이터베이스는 모든 데이터와 개체를 하나의 주 파일에 저장하고 트랜잭션 로그 정보를 로그 파일에 저장합니다. 기본 파일 1개와 보조 파일 5개를 포함하는 Orders라는 더 복잡한 데이터베이스를 만들 수 있습니다. 데이터베이스 내의 데이터와 개체는 6개의 파일에 분산되고 트랜잭션 로그 정보는 4개의 로그 파일에 포함됩니다.
기본적으로 데이터 및 트랜잭션 로그는 단일 디스크 시스템을 처리하기 위해 동일한 드라이브 및 경로에 배치됩니다. 이 선택은 프로덕션 환경에 적합하지 않을 수 있습니다. 데이터 및 로그 파일을 별도의 디스크에 배치하는 것이 좋습니다.
논리적 및 물리적 파일 이름
SQL Server 파일에는 두 가지 파일 이름 형식이 있습니다.
logical_file_name: 모든 Transact-SQL 문의 실제 파일을 참조하는 데 사용되는 이름입니다. 논리적 파일 이름은 SQL Server 식별자 규칙을 따라야 하고 데이터베이스의 논리적 파일 이름 사이에서 고유해야 합니다.os_file_name: 디렉터리 경로를 포함한 실제 파일의 이름입니다. 운영 체제 파일 이름에 대한 규칙을 따라야 합니다.
NAME 및 FILENAME 인수에 대한 자세한 내용은 ALTER DATABASE파일 및 파일 그룹 옵션을(를) 참조하십시오.
SQL Server의 여러 인스턴스가 단일 컴퓨터에서 실행되면 각 인스턴스는 인스턴스에서 만든 데이터베이스에 대한 파일을 저장할 다른 기본 디렉터리를 받습니다. 자세한 내용은 SQL Server의 기본 및 명명된 인스턴스에 대한 파일 위치를 참조하세요.
파일 시스템 지원
FAT 또는 NTFS 파일 시스템에 SQL Server 데이터 파일 및 로그 파일을 배치할 수 있습니다. Windows 시스템에서는 NTFS의 보안상 NTFS 파일 시스템을 사용하는 것이 좋습니다.
읽기/쓰기 데이터 파일 그룹 및 로그 파일은 NTFS 압축 파일 시스템에서 지원되지 않습니다. 읽기 전용 데이터베이스 및 읽기 전용 보조 파일 그룹만 NTFS 압축 파일 시스템에 배치할 수 있습니다. 공간을 절약하려면 파일 시스템 압축 대신 데이터 압축을 사용합니다.
데이터 파일 페이지
SQL Server 데이터 파일의 페이지는 첫째 페이지가 0으로 시작하여 순차적으로 번호가 매겨집니다. 데이터베이스의 각 파일에는 고유 파일 ID 번호가 있습니다. 데이터베이스에서 페이지를 고유하게 식별하려면 파일 ID와 페이지 번호가 모두 필요합니다. 다음 예제에서는 4MB 기본 데이터 파일과 1MB 보조 데이터 파일이 있는 데이터베이스의 페이지 번호를 보여 줍니다.
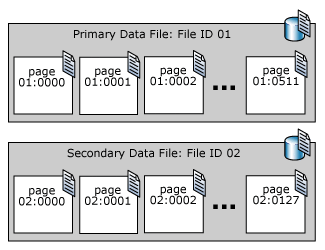
파일 헤더 페이지는 파일의 특성에 대한 정보를 포함하는 첫 번째 페이지입니다. 파일의 시작 부분에 있는 다른 여러 페이지에는 할당 맵과 같은 시스템 정보도 포함되어 있습니다. 기본 데이터 파일과 첫 번째 로그 파일 모두에 저장된 시스템 페이지 중 하나는 데이터베이스의 특성에 대한 정보를 포함하는 데이터베이스 부팅 페이지입니다.
파일 크기
SQL Server 파일은 원래 지정된 크기에서 자동으로 증가할 수 있습니다. 파일을 정의할 때 특정 증가 증분을 지정할 수 있습니다. 파일이 채워질 때마다 파일의 크기가 증분별로 증가합니다. 파일 그룹에 여러 파일이 있는 경우 모든 파일이 가득 찼을 때까지 자동으로 증가하지 않습니다.
페이지 및 페이지 유형에 대한 자세한 내용은 페이지 및 익스텐트 아키텍처 가이드를 참조하세요.
각 파일의 최대 크기를 지정할 수도 있습니다. 최대 크기를 지정하지 않으면 디스크에서 사용 가능한 모든 공간을 사용할 때까지 파일이 계속 증가할 수 있습니다. 이 기능은 사용자가 시스템 관리자에 편리하게 액세스할 수 없는 애플리케이션에 포함된 데이터베이스로 SQL Server를 사용할 때 특히 유용합니다. 사용자는 데이터베이스의 사용 가능한 공간을 모니터링하고 추가 공간을 수동으로 할당하는 관리 부담을 줄이기 위해 필요에 따라 파일이 자동 증가하도록 할 수 있습니다.
트랜잭션 로그 파일 관리에 대한 자세한 내용은 트랜잭션 로그 파일의 크기 관리를 참조하세요.
데이터베이스 스냅샷 파일
데이터베이스 스냅샷에서 쓰기 중 복사 데이터를 저장하는 데 사용되는 파일 형식은 스냅샷을 사용자가 만들거나 내부적으로 사용되는지 여부에 따라 달라집니다.
사용자가 만든 데이터베이스 스냅샷은 하나 이상의 스파스 파일에 데이터를 저장합니다. 스파스 파일 기술은 NTFS 파일 시스템의 기능입니다. 처음에는 스파스 파일에 사용자 데이터가 없으며 사용자 데이터의 디스크 공간이 스파스 파일에 할당되지 않았습니다. 데이터베이스 스냅샷에서 스파스 파일 사용 및 데이터베이스 스냅샷 증가 방법에 대한 일반적인 내용은 데이터베이스 스냅샷의 스파스 파일 크기 보기를 참조하세요.
데이터베이스 스냅샷은 특정 DBCC 명령에서 내부적으로 사용됩니다. 이러한 명령은 다음과 같습니다:
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOC,DBCC CHECKFILEGROUP내부 데이터베이스 스냅샷은 원본 데이터베이스 파일의 희소 대체 데이터 스트림을 사용합니다. 스파스 파일과 마찬가지로 대체어 데이터 스트림은 NTFS 파일 시스템의 기능입니다. 스파스 대체어 데이터 스트림을 사용하면 파일 크기 또는 볼륨 통계에 영향을 주지 않고 여러 데이터 할당을 단일 파일 또는 폴더에 연결할 수 있습니다.
파일 그룹
- 기본 파일 그룹에는 기본 데이터 파일과 다른 파일 그룹에 배치되지 않은 보조 파일이 포함됩니다.
- 관리, 데이터 할당 및 순위를 위해 데이터 파일을 그룹화하기 위해 사용자 정의 파일 그룹을 만들 수 있습니다.
예를 들어 3개의 파일(Data1.ndf, Data2.ndf, Data3.ndf)을 3개의 디스크 드라이브에 하나씩 만들어서 파일 그룹 fgroup1에 할당할 수 있습니다. 그런 다음 파일 그룹 fgroup1에 한 개의 테이블을 만들 수 있습니다. 이렇게 하면 해당 테이블의 데이터에 대한 쿼리가 3개의 디스크로 분산되므로 성능이 향상됩니다. RAID(Redundant Array of Independent Disks) 스트라이프 세트에 단일 파일을 만들어 사용해도 이와 동일한 수준으로 성능이 향상될 수 있습니다. 그러나 파일과 파일 그룹을 사용하면 새 디스크에 새 파일을 쉽게 추가할 수 있습니다.
모든 데이터 파일은 다음 표에 나열된 파일 그룹에 저장됩니다.
| 파일그룹 | 설명 |
|---|---|
| 기본 | 주 파일이 있는 파일 그룹입니다. 주 파일 그룹의 일부로는 모든 시스템 테이블이 있습니다. |
| 메모리 최적화 데이터 | 메모리 최적화 파일 그룹은 FILESTREAM 파일 그룹을 기반으로 합니다. |
| Filestream | 파일 시스템 디렉터리에 저장된 구조화되지 않은 데이터입니다. |
| 사용자 정의 | 사용자가 데이터베이스를 처음 만들거나 나중에 수정할 때 사용자가 만든 모든 파일 그룹입니다. |
기본(주) 파일 그룹
개체가 속한 파일 그룹을 지정하지 않고 데이터베이스에 만들어지면 기본 파일 그룹에 할당됩니다. 언제든지 정확히 하나의 파일 그룹이 기본 파일 그룹으로 지정됩니다. 기본 파일 그룹의 파일은 다른 파일 그룹에 할당되지 않은 새 개체를 저장할 수 있을 만큼 커야 합니다.
PRIMARY 파일 그룹은 문을 사용하여 ALTER DATABASE 변경되지 않는 한 기본 파일 그룹입니다. 시스템 개체 및 테이블에 대한 할당은 새 기본 파일 그룹이 아닌 파일 그룹 내에 PRIMARY 유지됩니다.
메모리 최적화 데이터 파일 그룹
메모리 최적화 파일 그룹에 대한 자세한 내용은 메모리 최적화 파일 그룹을 참조하세요.
FILESTREAM 파일 그룹
파일 스트림 파일 그룹에 대한 자세한 내용은 FILESTREAM 및 FILESTREAM 사용 데이터베이스 만들기를 참조하세요.
파일 및 파일 그룹 예제
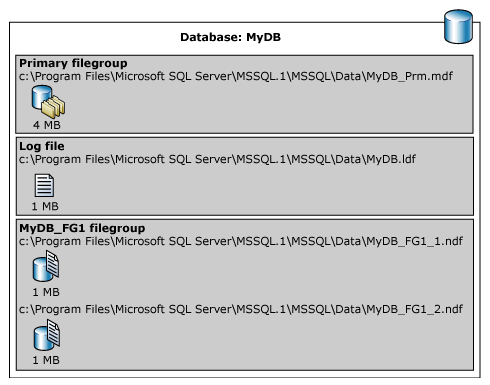
다음 예에서는 SQL Server 인스턴스에서 데이터베이스를 만듭니다. 데이터베이스에는 주 데이터 파일, 사용자 정의 파일 그룹 및 로그 파일이 있습니다. 기본 데이터 파일은 주 파일 그룹에 있고 사용자 정의 파일 그룹에는 두 개의 보조 데이터 파일이 있습니다.
ALTER DATABASE 문은 사용자 정의 파일 그룹을 기본값으로 만듭니다. 그런 다음 사용자 정의 파일 그룹을 지정하는 테이블이 만들어집니다. (이 예제에서는 제네릭 경로를 C:\Program Files\Microsoft SQL Server\MSSQL.1 사용하여 SQL Server 버전을 지정하지 않습니다.)
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
다음 그림에서는 FILESTREAM 데이터를 제외하고 이전 예제의 결과를 요약합니다.
파일 및 파일 그룹 채우기 전략
파일 그룹은 각 파일 그룹 내의 모든 파일에서 비례 채우기 전략을 사용합니다. SQL Server 데이터베이스 엔진이 파일 그룹에 데이터를 쓸 때 은 첫 번째 파일이 꽉 찰 때까지 모든 데이터를 쓰는 대신 파일 그룹 내의 각 파일에 해당 파일의 사용 가능한 공간에 비례하는 양을 씁니다. 그런 다음, 다음 파일에 씁니다. 예를 들어 f1 파일에는 100MB의 빈 공간이 있고 f2 파일에는 200MB의 빈 공간이 있으면 f1 파일에서는 하나의 익스텐트가 제공되고 f2 파일에서는 두 개의 익스텐트가 제공되는 식입니다. 이렇게 하면 거의 동시에 두 파일이 꽉 차며 간단한 스트라이프가 수행됩니다.
예를 들어 파일 그룹이 3개의 파일로 구성되고 모두 자동 증가하도록 설정되었다고 가정합니다. 파일 그룹에 있는 모든 파일의 공간이 소진되면 첫 번째 파일만 확장됩니다. 첫 번째 파일이 꽉 차고 파일 그룹에 더 이상 데이터를 쓸 수 없게 되면 두 번째 파일이 확장됩니다. 두 번째 파일이 꽉 차고 파일 그룹에 더 이상 데이터를 쓸 수 없게 되면 세 번째 파일이 확장됩니다. 세 번째 파일이 꽉 차고 파일 그룹에 더 이상 데이터를 쓸 수 없게 되면 첫 번째 파일이 다시 확장되는 식입니다.
파일 및 파일 그룹 디자인 규칙
파일 및 파일 그룹과 관련된 규칙은 다음과 같습니다.
둘 이상의 데이터베이스에서 파일 또는 파일 그룹을 사용할 수 없습니다. 예를 들어 판매 데이터베이스의 데이터와 개체를 포함하는 파일
sales.mdf및sales.ndf는 다른 데이터베이스에서 사용할 수 없습니다.파일은 하나의 파일 그룹의 구성원일 수 있습니다.
트랜잭션 로그 파일은 파일 그룹의 일부가 되지 않습니다.
권장 사항
파일 및 파일 그룹 작업 시 권장 사항
대부분의 데이터베이스는 단일 데이터 파일 및 단일 트랜잭션 로그 파일에서 잘 작동합니다.
여러 데이터 파일을 사용하는 경우 추가 파일에 대한 두 번째 파일 그룹을 만들고 해당 파일 그룹을 기본 파일 그룹으로 만듭니다. 이러한 방식으로 기본 파일에는 시스템 테이블과 개체만 포함됩니다.
성능을 극대화하려면 가능한 여러 개의 사용 가능한 디스크에 파일이나 파일 그룹을 만듭니다. 디스크 공간이 많이 필요한 개체는 여러 파일 그룹에 배치합니다.
파일 그룹을 사용하여 특정 실제 디스크에 개체를 배치할 수 있습니다.
동일한 조인 쿼리에 사용되는 다른 테이블을 다른 파일 그룹에 배치합니다. 이 단계는 병렬 디스크 I/O를 통해 조인된 데이터를 검색하므로 성능을 향상시킵니다.
액세스가 많은 테이블과 해당 테이블에 속하는 비클러스터형 인덱스를 다른 파일 그룹에 배치합니다. 서로 다른 파일 그룹을 사용하면 파일이 여러 물리적 디스크에 있을 경우 병렬 I/O가 수행되기 때문에 성능이 향상됩니다.
트랜잭션 로그 파일을 다른 파일 및 파일 그룹이 있는 동일한 실제 디스크에 배치하지 마세요.
diskpart와 같은 도구를 사용하여 데이터베이스 파일이 상주하는 볼륨 또는 파티션을 확장해야 하는 경우 모든 시스템 및 사용자 데이터베이스를 백업하고 SQL Server 서비스를 먼저 중지해야 합니다. 또한 디스크 볼륨이 성공적으로 확장되면 볼륨에 있는 모든 데이터베이스의 물리적 무결성을 보장하기 위해 DBCC CHECKDB 명령을 실행하는 것이 좋습니다.
트랜잭션 로그 파일 관리 권장 사항에 대한 자세한 내용은 트랜잭션 로그 파일의 관리를 참조하세요.