SQL Server에서 래치 경합 진단 및 해결
이 가이드에서는 높은 동시성 시스템에서 특정 워크로드와 함께 SQL Server 애플리케이션을 실행할 때 관찰된 래치 경합 이슈를 식별하고 해결하는 방법을 설명합니다.
서버의 CPU 코어 수가 계속 증가함에 따라 관련된 동시성 증가로 인해 데이터베이스 엔진 내에서 직렬 방식으로 액세스해야 하는 데이터 구조에 경합 지점이 생길 수 있습니다. 이는 높은 처리량/높은 동시성 트랜잭션 처리(OLTP) 워크로드의 경우 특히 그렇습니다. 이러한 과제에 접근하는 다양한 도구, 기술 및 방법뿐만 아니라 문제를 완전히 방지하는 데 도움이 될 수 있는 애플리케이션을 설계할 때 활용할 수 있는 방법이 있습니다. 이 문서에서는 스핀 잠금을 사용하여 데이터 구조에 대한 액세스를 직렬화하는 데이터 구조의 특정 경합 유형에 대해 설명합니다.
참고 항목
이 콘텐츠는 높은 동시성 시스템의 SQL Server 애플리케이션에서 페이지 래치 경합과 관련된 문제를 식별하고 해결하기 위한 프로세스를 기반으로 Microsoft SQL Server 고객 자문 팀(SQLCAT) 팀이 작성했습니다. 여기서 설명하는 권장 사항과 모범 사례는 실제 OLTP 시스템을 개발하고 배포하면서 겪은 실제 경험을 기반으로 합니다.
SQL Server 래치 경합이란?
래치는 인덱스, 데이터 페이지, 내부 구조(예: B-트리의 비-리프 페이지)를 비롯한 메모리 내 구조의 일관성을 보장하기 위해 SQL Server 엔진에서 사용하는 간단한 동기화 기본 형식입니다. SQL Server는 버퍼 래치를 사용하여 버퍼 풀의 페이지를 보호하고, I/O 래치를 사용하여 버퍼 풀에 아직 로드되지 않은 페이지를 보호합니다. SQL Server 버퍼 풀의 페이지에서 데이터를 쓰거나 읽을 때마다 작업자 스레드는 먼저 페이지에 대한 버퍼 래치를 획득해야 합니다. 배타적 래치(PAGELATCH_EX) 및 공유 래치(PAGELATCH_SH)를 포함하여 버퍼 풀의 페이지에 액세스하는 데 사용할 수 있는 다양한 버퍼 래치 유형이 있습니다. SQL Server가 버퍼 풀에 아직 없는 페이지에 액세스하려고 하면 비동기 I/O가 게시되어 페이지를 버퍼 풀로 로드합니다. SQL Server가 I/O 하위 시스템이 응답할 때까지 기다려야 하는 경우 요청 유형에 따라 배타적(PAGEIOLATCH_EX) 또는 공유(PAGEIOLATCH_SH) I/O 래치를 기다립니다. 이는 다른 작업자 스레드가 호환되지 않는 래치를 사용하여 동일한 페이지를 버퍼 풀에 로드하지 못하게 막기 위한 것입니다. 래치는 버퍼 풀 페이지 이외의 내부 메모리 구조에 대한 액세스를 보호하는 데도 사용됩니다. 이러한 래치를 비-버퍼 래치라고 합니다.
페이지 래치의 경합은 다중 CPU 시스템에서 발생하는 가장 일반적인 시나리오이므로 이 문서의 대부분은 이러한 시나리오에 중점을 둡니다.
래치 경합은 여러 스레드가 동일한 메모리 내 구조에 대해 호환되지 않는 래치를 동시에 획득하려고 할 때 발생합니다. 래치는 내부 제어 메커니즘이므로 SQL 엔진이 사용할 시기를 자동으로 결정합니다. 래치의 동작이 결정적이기 때문에 스키마 디자인을 포함한 애플리케이션 결정은 이 동작에 영향을 줄 수 있습니다. 이 문서에서는 다음 정보를 제공합니다.
- SQL Server에서 래치를 사용하는 방법에 대한 배경 정보입니다.
- 래치 경합을 조사하는 데 사용하는 도구입니다.
- 관찰된 경합 양이 문제가 되는지 확인하는 방법
몇 가지 일반적인 시나리오와 경합을 완화하기 위해 해당 시나리오를 처리하는 최상의 방법을 알아보겠습니다.
SQL Server는 래치를 어떻게 사용하나요?
SQL Server의 각 페이지는 8KB이며 여러 행을 저장할 수 있습니다. 동시성 및 성능을 높이기 위해 버퍼 래치는 논리 트랜잭션 기간에 동안 유지되는 잠금과 달리 페이지에서 실제 작업 기간 동안만 유지됩니다.
래치는 SQL 엔진 내부에 있으며 메모리 일관성을 제공하는 데 사용되는 반면, 잠금은 SQL Server에서 논리 트랜잭션 일관성을 제공하는 데 사용됩니다. 다음 표에서는 잠금과 래치를 비교해서 설명합니다.
| 구조체 | 목적 | 제어 | 성능 비용 | 노출 |
|---|---|---|---|---|
| 래치 | 메모리 내 구조의 일관성을 보장합니다. | SQL Server 엔진만 제어할 수 있습니다. | 성능 비용이 낮습니다. 최대 동시성을 허용하고 최대 성능을 제공하기 위해 래치는 논리 트랜잭션 기간 동안 유지되는 잠금과 달리 메모리 내 구조에 대한 실제 작업 기간 동안만 유지됩니다. | sys.dm_os_wait_stats(Transact-SQL) - PAGELATCH, PAGEIOLATCH, LATCH 대기 유형(LATCH_EX, LATCH_SH는 모든 비-버퍼 래치 대기를 그룹화하는 데 사용됨)에 대한 정보를 제공합니다. sys.dm_os_latch_stats(Transact-SQL) – 비-버퍼 래치 대기에 대한 자세한 정보를 제공합니다. sys.dm_db_index_operational_stats(Transact-SQL) - 이 DMV는 래치 관련 성능 문제를 해결하는 데 유용한 각 인덱스에 대해 집계된 대기를 제공합니다. |
| 잠금 | 트랜잭션의 일관성을 보장합니다. | 사용자가 제어할 수 있습니다. | 트랜잭션 기간 동안 잠금을 유지해야 하므로 래치에 비해 성능 비용이 높습니다. | sys.dm_tran_locks(Transact-SQL). sys.dm_exec_sessions(Transact-SQL) |
SQL Server 래치 모드 및 호환성
일부 래치 경합은 SQL Server 엔진 작동의 일반적인 부분으로 예상해야 합니다. 높은 동시성 시스템에서는 다양한 호환성의 여러 동시 래치 요청이 발생할 수밖에 없습니다. SQL Server는 호환되지 않는 래치 요청이 미해결 래치 요청이 완료될 때까지 큐에서 대기하도록 요구하여 래치 호환성을 적용합니다.
래치는 액세스 수준과 관련된 5가지 모드 중 하나로 획득됩니다. SQL Server 래치 모드는 다음과 같이 요약할 수 있습니다.
KP -- 래치를 유지하고 참조된 구조를 제거할 수 없게 합니다. 스레드가 버퍼 구조를 보려고 할 때 사용됩니다. KP 래치는 DT(삭제) 래치를 제외한 모든 래치와 호환되므로 KP 래치는 "경량"으로 간주되어 사용 시 성능에 미치는 영향이 최소화됩니다. KP 래치는 DT 래치와 호환되지 않으므로 다른 스레드가 참조된 구조를 삭제하지 못하게 합니다. 예를 들어 KP 래치는 참조된 구조가 지연 기록기 프로세스를 통해 제거되지 않도록 차단합니다. 지연 기록기 프로세스가 SQL Server 버퍼 페이지 관리와 함께 사용되는 방법에 대한 자세한 내용은 페이지 작성을 참조하세요.
SH -- 참조된 구조를 읽는 데 필요한 공유 래치입니다(예: 데이터 페이지 읽기). 여러 스레드가 공유 래치에서 읽기 위해 리소스에 동시에 액세스할 수 있습니다.
UP -- 업데이트 래치는 SH(공유 래치) 및 KP와 호환되지만 다른 항목은 없으므로 EX 래치가 참조된 구조에 쓰도록 허용하지 않습니다.
EX -- 배타적 래치로, 다른 스레드가 참조된 구조에 쓰거나 읽지 못하도록 차단합니다. 한 가지 사용 예는 조각난 페이지 보호를 위해 페이지의 콘텐츠를 수정하는 것입니다.
DT - 제거 래치이며, 참조된 구조의 내용을 제거하기 전에 획득해야 합니다. 예를 들어 지연 기록기 프로세스는 다른 스레드가 사용할 수 있도록 사용 가능한 버퍼 목록에 추가하기 전에 클린 페이지를 확보하기 위해 DT 래치를 획득해야 합니다.
래치 모드는 호환성 수준이 다릅니다. 예를 들어 SH(공유 래치)는 UP(업데이트 래치) 또는 KP(유지 래치)와 호환되지만 DT(삭제 래치)와 호환되지 않습니다. 래치가 호환되기만 하면, 동일한 구조에 대해 여러 래치를 동시에 획득할 수 있습니다. 스레드가 호환되지 않는 모드로 유지된 래치를 획득하려고 하면 리소스를 사용할 수 있음을 나타내는 신호를 기다리기 위해 큐에 배치됩니다. SOS_Task 형식의 스핀 잠금은 큐에 직렬화된 액세스를 적용하여 대기 큐를 보호하는 데 사용됩니다. 큐에 항목을 추가하려면 이 스핀 잠금을 획득해야 합니다. 또한 SOS_Task 스핀 잠금은 호환되지 않는 래치가 해제될 때 큐의 스레드를 신호로 표시하므로 대기 중인 스레드가 호환되는 래치를 획득하고 계속 작동할 수 있습니다. 대기 큐는 래치 요청이 해제될 때 FIFO(선입 선출) 방식으로 처리됩니다. 래치는 이 FIFO 시스템을 따라 공정성을 보장하고 스레드 고갈을 방지합니다.
래치 모드 호환성은 다음 표에 나와 있습니다(Y는 호환성을 나타내고, N은 비호환성을 나타냄).
| 래치 모드 | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
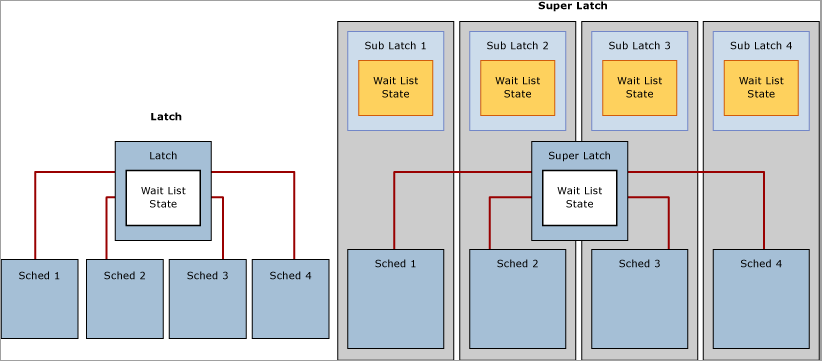
SQL Server 슈퍼 래치 및 하위 래치
NUMA 기반 다중 소켓/다중 코어 시스템의 존재가 증가함에 따라 SQL Server 2005에는 하위 래치라고도 하는 SuperLatches가 도입되었으며, 이는 32개 이상의 논리 프로세서가 있는 시스템에만 적용됩니다. 슈퍼 래치는 동시성이 높은 OLTP 워크로드에서 특정 사용 패턴에 대한 SQL 엔진의 효율성을 향상시킵니다. 예를 들어 특정 페이지에는 읽기 전용 SH(공유) 액세스 패턴이 있지만 거의 기록되지 않는 경우입니다. 이러한 액세스 패턴이 있는 페이지의 예는 B-트리(예: 인덱스) 루트 페이지입니다. SQL 엔진을 사용하려면 B-트리의 모든 수준에서 페이지 분할이 발생할 때 공유 래치가 루트 페이지에 있어야 합니다. 삽입이 많은 높은 동시성 OLTP 워크로드에서는 처리량에 따라 페이지 분할 수가 크게 증가하므로 성능이 저하될 수 있습니다. 슈퍼 래치를 사용하면 동시에 실행되는 여러 작업자 스레드에 SH 래치가 필요한 공유 페이지에 대한 액세스 성능을 높일 수 있습니다. 이를 위해 SQL Server 엔진은 이러한 페이지의 래치를 SuperLatch로 동적으로 승격합니다. SuperLatch는 단일 래치를 하위 래치 구조 배열로 분할하고, CPU 코어당 파티션별로 하나의 하위 래치를 분할합니다. 따라서 기본 래치는 프록시 리디렉터가 되고 읽기 전용 래치에는 전역 상태 동기화가 필요하지 않습니다. 이렇게 하면 항상 특정 CPU에 할당되는 작업자는 로컬 스케줄러에 할당된 공유(SH) 하위 래치만 획득하면 됩니다.
참고 항목
설명서는 인덱스를 지칭할 때 B-트리라는 용어를 사용합니다. rowstore 인덱스에서 데이터베이스 엔진은 B+ 트리를 구현합니다. 이는 columnstore 인덱스나 메모리 최적화 테이블 인덱스에는 적용되지 않습니다. 자세한 내용은 SQL Server 및 Azure SQL 인덱스 아키텍처 및 디자인 가이드를 참조하세요.
공유 슈퍼 래치와 같은 호환되는 래치를 획득하면 리소스를 더 적게 사용하고 분할되지 않은 공유 래치보다 핫 페이지에 대한 액세스가 더 잘 조정됩니다. 전역 상태 동기화 요구 사항을 제거하면 로컬 NUMA 메모리에만 액세스하여 성능이 크게 향상되기 때문입니다. 반대로, SQL이 모든 하위 래치에서 신호를 전달해야 하므로 EX(배타적) SuperLatch를 획득하는 것이 EX 일반 래치를 획득하는 것보다 더 비쌉니다. SuperLatch가 높은 EX 액세스 패턴을 사용하는 것으로 관찰되면 SQL 엔진은 페이지가 버퍼 풀에서 삭제된 후 이를 강등할 수 있습니다. 다음 다이어그램에서는 일반 래치와 분할된 슈퍼 래치를 보여 줍니다.
SQL Server:Latches 개체 및 성능 모니터에 연결된 카운터를 사용하여 SuperLatche 수, 초당 SuperLatch 승격, 초당 SuperLatch 강등을 포함하여 SuperLatches에 대한 정보를 수집합니다. SQL Server:Latches 개체 및 관련 카운터에 대한 자세한 내용은 SQL Server, 래치 개체를 참조하세요.
래치 대기 유형
누적 대기 정보는 SQL Server에서 추적되며, DMV(동적 관리 뷰) sys.dm_os_wait_stats를 사용하여 액세스할 수 있습니다. SQL Server는 sys.dm_os_wait_stats DMV에서 wait_type에 해당하는 것으로 정의된 세 가지 래치 대기 유형을 사용합니다.
버퍼(BUF) 래치: 사용자 개체 인덱스 및 데이터 페이지의 일관성을 보장하는 데 사용됩니다. SQL Server가 시스템 개체에 사용하는 데이터 페이지에 대한 액세스를 보호하는 데에도 사용됩니다. 예를 들어 버퍼 래치는 할당을 관리하는 페이지를 보호합니다. 여기에는 PFS(페이지 여유 공간), GAM(전역 할당 맵), SGAM(공유 전역 할당 맵), IAM(인덱스 할당 맵) 페이지가 포함됩니다. 버퍼 래치는
sys.dm_os_wait_stats에서 PAGELATCH_*의wait_type로 보고됩니다.비-버퍼(Non-BUF) 래치: 버퍼 풀 페이지가 아닌 다른 모든 메모리 내 구조의 일관성을 보장하는 데 사용됩니다. 비-버퍼 래치에 대한 모든 대기는 LATCH_*의
wait_type으로 보고됩니다.IO 래치: 이러한 구조체가 I/O 작업을 사용하여 버퍼 풀로 로드해야 하는 경우 버퍼 래치로 보호되는 동일한 구조의 일관성을 보장하는 버퍼 래치의 하위 집합입니다. IO 래치는 호환되지 않는 래치를 사용하여 동일한 페이지를 버퍼 풀에 로드하는 다른 스레드를 방지합니다. PAGEIOLATCH_*의
wait_type과 연결됩니다.참고 항목
표시되는 PAGEIOLATCH 대기가 상당히 높으면 SQL Server가 I/O 하위 시스템에서 대기하고 있음을 의미합니다. 특정 양의 PAGEIOLATCH 대기가 예상되고 정상적인 동작이지만 평균 PAGEIOLATCH 대기 시간이 일관되게 10ms(밀리초)를 초과하는 경우 I/O 하위 시스템이 압력을 받는 이유를 조사해야 합니다.
sys.dm_os_wait_stats DMV에서 비-버퍼 래치를 발견할 경우 sys.dm_os_latch_stats를 검사하여 비-버퍼 래치에 대한 누적 대기 정보의 자세한 내역을 확인해야 합니다. 모든 버퍼 래치 대기는 BUFFER 래치 클래스로 분류되고 나머지는 비-버퍼 래치를 분류하는 데 사용됩니다.
SQL Server 래치 경합의 증상 및 원인
사용량이 많은 동시성 시스템에서는 SQL Server의 래치 및 기타 제어 메커니즘에 의해 자주 액세스되고 보호되는 구조체에 대한 활성 경합이 발생하는 것이 정상입니다. 페이지의 래치 획득과 관련된 경합 및 대기 시간이 리소스(CPU) 사용률을 줄이기에 충분하여 처리량을 저해하는 경우 문제가 있는 것으로 간주됩니다.
래치 경합 예제
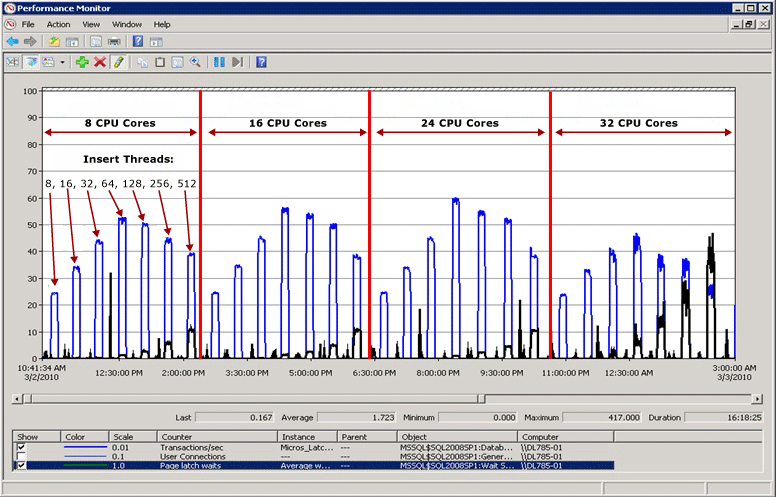
다음 다이어그램에서 파란색 선은 초당 트랜잭션으로 측정된 SQL Server의 처리량을 나타냅니다. 검은색 선은 평균 페이지 래치 대기 시간을 나타냅니다. 이 경우 각 트랜잭션은 데이터 형식 bigint의 IDENTITY 열을 채울 때와 같이 순차적으로 증가하는 선행 값을 사용하여 클러스터형 인덱스에 INSERT를 수행합니다. CPU 수가 32개로 증가함에 따라 전체 처리량이 감소하고 페이지 래치 대기 시간이 검은색 선에서 입증된 대로 약 48밀리초로 증가했음이 분명해졌습니다. 처리량과 페이지 래치 대기 시간 간의 이러한 역관계는 쉽게 진단할 수 있는 일반적인 시나리오입니다.
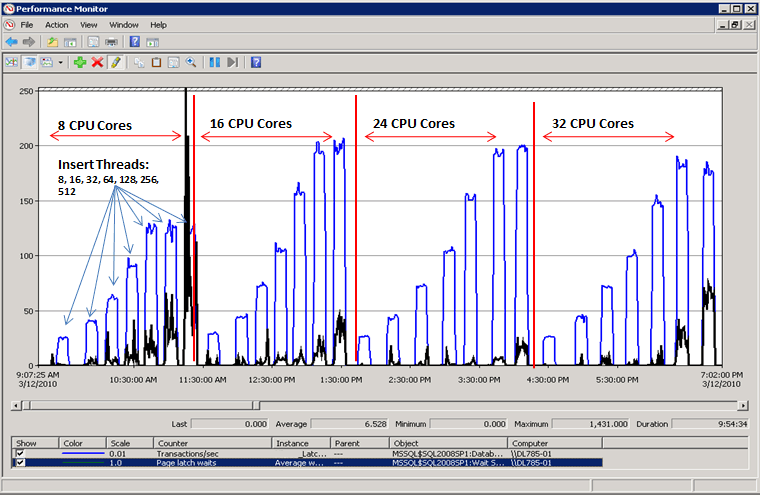
래치 경합이 해결된 경우의 성능
다음 다이어그램에서 볼 수 있듯이 SQL Server는 더 이상 페이지 래치 대기에서 병목 상태가 되지 않으며 초당 트랜잭션으로 측정된 처리량이 300% 증가합니다. 이 작업은 이 문서의 뒷부분에 설명된 계산 열 기술로 해시 분할을 사용하여 수행되었습니다. 이러한 성능 향상은 코어 수가 많고 동시성이 높은 시스템을 대상으로 합니다.
래치 경합에 영향을 주는 요인
OLTP 환경의 성능을 방해하는 래치 경합은 일반적으로 다음 요소 중 하나 이상과 관련된 높은 동시성으로 인해 발생합니다.
| 요소 | 세부 정보 |
|---|---|
| SQL Server에서 많은 수의 논리 CPU 사용 | 래치 경합은 모든 다중 코어 시스템에서 발생할 수 있습니다. SQLCAT 환경에서 허용 수준 이상으로 애플리케이션 성능에 영향을 주는 과도한 래치 경합은 일반적으로 16개 이상의 CPU 코어가 있는 시스템에서 관찰되었으며, 추가 코어를 사용할 수 있게 되면 늘어날 수 있습니다. |
| 스키마 디자인 및 액세스 패턴 | B-트리의 깊이, 클러스터형 및 비클러스터형 인덱스 디자인, 페이지당 행의 크기와 밀도, 액세스 패턴(읽기/쓰기/삭제 작업)은 과도한 페이지 래치 경합에 영향을 줄 수 있는 요소입니다. |
| 애플리케이션 수준에서 높은 동시성 | 과도한 페이지 래치 경합은 일반적으로 애플리케이션 계층에서 높은 수준의 동시 요청과 함께 발생합니다. 특정 페이지에 대한 요청 수가 많아질 수도 있는 특정 프로그래밍 방법이 있습니다. |
| SQL Server 데이터베이스에서 사용하는 논리 파일의 레이아웃 | 논리적 파일 레이아웃은 PFS(Page Free Space), GAM(Global Allocation Map), SGAM(Shared Global Allocation Map), IAM(Index Allocation Map) 페이지와 같은 할당 구조로 인해 페이지 래치 경합 수준에 영향을 줄 수 있습니다. 자세한 내용은 TempDB 모니터링 및 문제 해결: 할당 병목 상태를 참조하세요. |
| I/O 하위 시스템 성능 | PAGEIOLATCH 대기가 상당히 높으면 SQL Server가 I/O 하위 시스템에서 대기하고 있음을 나타납니다. |
SQL Server 래치 경합 진단
이 섹션에서는 SQL Server 래치 경합을 진단하여 환경에 문제가 있는지 확인하는 방법을 제공합니다.
래치 경합을 진단하기 위한 도구 및 방법
래치 경합을 진단하는 데 사용되는 기본 도구는 다음과 같습니다.
성능 모니터를 사용하여 SQL Server 내에서 CPU 사용률 및 대기 시간을 모니터링하고, CPU 사용률과 래치 대기 시간 사이에 관계가 있는지 여부를 설정합니다.
SQL Server DMV는 문제를 일으키는 특정 유형의 래치와 영향을 받는 리소스를 확인하는 데 사용할 수 있습니다.
Windows 디버깅 도구를 사용하여 SQL Server 프로세스의 메모리 덤프를 가져와 분석해야 하는 경우도 있습니다.
참고 항목
이 수준의 고급 문제 해결은 일반적으로 비-버퍼 래치 경합 문제를 해결하는 경우에만 필요합니다. 이러한 유형의 고급 문제 해결을 위해 Microsoft 기술 지원 서비스에 참여할 수 있습니다.
래치 경합을 진단하기 위한 기술 프로세스는 다음과 같은 단계로 요약할 수 있습니다.
래치와 관련된 경합이 있는지 확인합니다.
부록: SQL Server 래치 경합 스크립트에 제공된 DMV 뷰를 사용하여 영향을 받는 래치 및 리소스의 유형을 확인합니다.
다른 테이블 패턴에 대한 래치 경합 처리에 설명된 기술 중 하나를 사용하여 경합을 완화합니다.
래치 경합 표시기
앞에서 설명한 것처럼 래치 경합은 페이지 래치 획득과 관련된 경합 및 대기 시간이 CPU 리소스를 사용할 수 있을 때 처리량이 증가하지 않는 경우에만 문제가 됩니다. 허용되는 경합 수준을 확인하려면 성능 및 처리량 요구 사항과 사용 가능한 I/O 및 CPU 리소스를 함께 고려하는 전체적인 접근 방식이 필요합니다. 이 섹션에서는 다음과 같이 래치 경합이 워크로드에 미치는 영향을 확인하는 단계를 안내합니다.
대표 테스트 중에 전체 대기 시간을 측정합니다.
순서대로 순위를 지정합니다.
래치와 관련된 대기 시간의 비율을 확인합니다.
누적 대기 정보는 sys.dm_os_wait_stats DMV에서 확인할 수 있습니다. 래치 경합의 가장 일반적인 유형은 버퍼 래치 경합이며 PAGELATCH_*의 wait_type인 래치의 대기 시간이 증가하는 것으로 관찰됩니다. 비-버퍼 래치는 LATCH* 대기 유형으로 그룹화됩니다. 다음 다이어그램에서 볼 수 있듯이 먼저 sys.dm_os_wait_stats DMV를 사용하여 시스템 대기를 누적해서 확인하고 버퍼 또는 비-버퍼 래치로 인한 전체 대기 시간의 비율을 결정해야 합니다. 비-버퍼 래치를 발견한 경우 sys.dm_os_latch_stats DMV도 검사해야 합니다.
다음 다이어그램에서는 sys.dm_os_wait_stats 및 sys.dm_os_latch_stats DMV에서 반환된 정보 간의 관계를 설명합니다.

sys.dm_os_wait_stats DMV에 대한 자세한 내용은 SQL Server 도움말에서 sys.dm_os_wait_stats(Transact-SQL)를 참조하세요.
sys.dm_os_latch_stats DMV에 대한 자세한 내용은 SQL Server 도움말에서 sys.dm_os_latch_stats(Transact-SQL)를 참조하세요.
래치 대기 시간의 다음 측정값은 과도한 래치 경합이 애플리케이션 성능에 영향을 미치고 있다는 지표입니다.
평균 페이지 래치 대기 시간이 처리량과 함께 지속적으로 증가:평균 페이지 래치 대기 시간이 처리량과 함께 지속적으로 증가하고 평균 버퍼 래치 대기 시간도 예상 디스크 응답 시간 이상으로 증가하는 경우
sys.dm_os_waiting_tasksDMV를 사용하여 현재 대기 중인 작업을 검사해야 합니다. 격리된 상태로 분석하는 경우 평균이 오해의 소지가 있을 수 있으므로 가능한 경우 워크로드 특성을 이해하기 위해 시스템을 라이브로 보는 것이 중요합니다. 특히 페이지에서 PAGELATCH_EX 및/또는 PAGELATCH_SH 요청의 대기가 높은지 여부를 확인합니다. 처리량과 함께 증가하는 평균 페이지 래치 대기 시간을 진단하려면 다음 단계를 수행합니다.- 세션 ID별로 정렬된 sys.dm_os_waiting_tasks 쿼리 또는 일정 기간 동안 대기 시간 계산 샘플 스크립트를 사용하여 현재 대기 중인 작업을 확인하고 평균 래치 대기 시간을 측정합니다.
- 래치 경합을 일으키는 개체를 확인하는 쿼리 버퍼 설명자 샘플 스크립트를 사용하여 경합이 발생하는 인덱스 및 기본 테이블을 확인합니다.
- MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time 성능 모니터 카운터를 사용하거나
sys.dm_os_wait_statsDMV를 실행하여 평균 페이지 래치 대기 시간을 측정합니다.
참고 항목
특정 대기 유형(
sys.dm_os_wait_stats에서 wt_:type으로 반환)의 평균 대기 시간을 계산하려면 총 대기 시간(wait_time_ms로 반환)을 대기 중인 작업의 수(waiting_tasks_count로 반환)로 나눕니다.최대 부하 동안 래치 대기 유형에 소요된 총 대기 시간의 비율: 애플리케이션 부하에 따라 전체 대기 시간의 백분율로 평균 래치 대기 시간이 증가하는 경우 래치 경합이 성능에 영향을 줄 수 있으며 조사해야 합니다.
SQLServer:Wait Statistics 개체 성능 카운터를 사용하여 페이지 래치 대기와 비페이지 래치 대기를 측정합니다. 그런 다음 이러한 성능 카운터의 값을 CPU, I/O, 메모리, 네트워크 처리량과 연결된 성능 카운터와 비교합니다. 예를 들어 초당 트랜잭션 수와 초당 배치 요청 수는 리소스 사용률의 두 가지 좋은 측정값입니다.
참고 항목
sys.dm_os_wait_statsDMV는 SQL Server 인스턴스가 마지막으로 시작되었거나 누적 대기 통계가 DBCC SQLPERF를 사용하여 다시 설정된 이후의 대기 시간을 측정하기 때문에 각 대기 유형의 상대 대기 시간은 이 DMV에 포함되지 않습니다. 각 대기 유형에 대한 상대 대기 시간을 계산하려면 최대 로드 전, 최대 로드 후의sys.dm_os_wait_stats스냅샷을 생성한 다음 그 차이를 계산합니다. 이 목적을 위해 일정 기간 동안 대기 시간 계산 샘플 스크립트를 사용할 수 있습니다.비프로덕션 환경의 경우에만 다음 명령을 사용하여
sys.dm_os_wait_statsDMV를 지웁니다.dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')유사한 명령을 실행하여
sys.dm_os_latch_statsDMV를 지울 수 있습니다.dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')처리량은 증가하지 않으며, 경우에 따라 애플리케이션 부하가 증가하고 SQL Server에서 사용할 수 있는 CPU 수가 증가함하면 감소합니다. 래치 경합의 예에 설명되어 있습니다.
애플리케이션 워크로드가 증가할 때 CPU 사용률이 증가하지 않습니다. 애플리케이션 처리량에 의해 구동되는 동시성이 증가할 때 시스템의 CPU 사용률이 증가하지 않으면 SQL Server가 무언가를 기다리고 있으며 래치 경합의 증상이 나타나고 있다는 지표입니다.
근본 원인을 분석합니다. 위의 각 조건이 true이더라도 성능 문제의 근본 원인이 다른 곳에 있을 가능성이 여전히 존재합니다. 실제로 대부분의 경우 최적화되지 않은 CPU 사용률은 잠금을 통한 차단, I/O 관련 대기 또는 네트워크 관련 이슈와 같은 다른 유형의 대기로 인해 발생합니다. 경험상, 심층 분석을 진행하기 전에 전반적인 대기 시간의 최대 비율을 나타내는 리소스 대기를 해결하는 것이 항상 가장 좋습니다.
현재 대기 버퍼 래치 분석
버퍼 래치 경합은 sys.dm_os_wait_stats DMV에 표시된 대로 PAGELATCH_* 또는 PAGEIOLATCH_*의 wait_type인 래치에 대한 대기 시간 증가로 나타납니다. 시스템을 실시간으로 확인하려면 시스템에서 다음 쿼리를 실행하여 sys.dm_os_wait_stats, sys.dm_exec_sessions 및 sys.dm_exec_requests DMV와 조인합니다. 결과를 사용하여 서버에서 실행되는 세션에 대한 현재 대기 유형을 확인할 수 있습니다.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
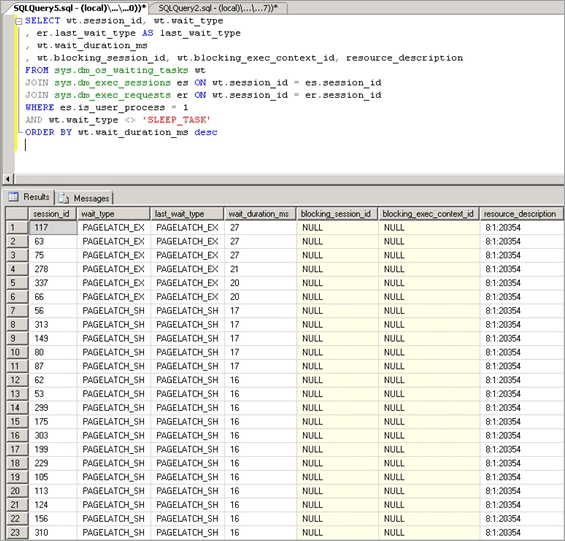
이 쿼리를 통해 노출되는 통계는 다음과 같습니다.
| 통계 | 설명 |
|---|---|
| Session_id | 작업과 연관된 세션의 ID입니다. |
| Wait_type | SQL Server가 엔진에서 기록한 대기 유형으로, 현재 요청이 실행되지 않도록 차단합니다. |
| Last_wait_type | 이 요청이 이전에 차단된 경우 이 열은 마지막 대기 유형을 반환합니다. Null을 허용하지 않습니다. |
| Wait_duration_ms | SQL Server 인스턴스가 시작된 이후 또는 누적 대기 통계가 재설정된 이후 이 대기 유형을 기다리는 데 소요된 총 대기 시간(밀리초)입니다. |
| Blocking_session_id | 요청을 차단하는 세션의 ID입니다. |
| Blocking_exec_context_id | 작업과 연관된 실행 컨텍스트의 ID입니다. |
| Resource_description | resource_description 열에는 대기 중인 정확한 페이지가 <database_id>:<file_id>:<page_id> 형식으로 나열됩니다. |
다음 쿼리는 모든 비-버퍼 래치에 대한 정보를 반환합니다.
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
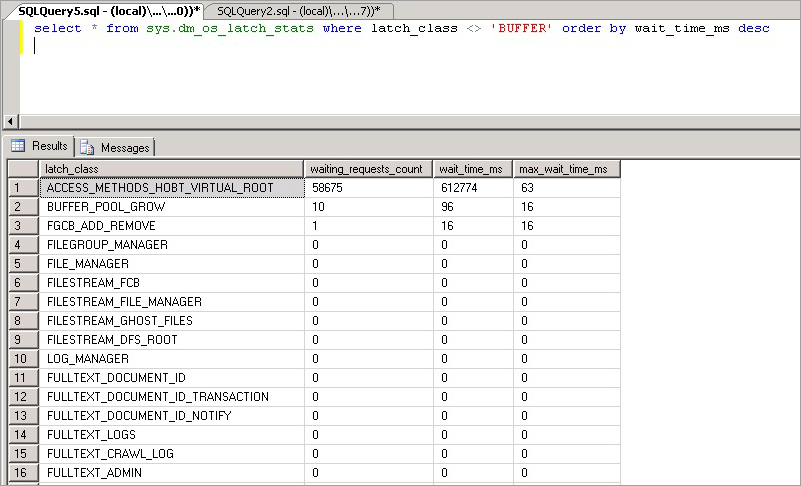
이 쿼리를 통해 노출되는 통계는 다음과 같습니다.
| 통계 | 설명 |
|---|---|
| latch_class | SQL Server가 엔진에서 기록한 래치 유형으로, 현재 요청이 실행되지 않도록 차단합니다. |
| waiting_requests_count | SQL Server가 다시 시작된 이후 이 클래스 래치의 대기 수입니다. 이 카운터는 래치 대기가 시작될 때 증가합니다. |
| wait_time_ms | 이 래치 유형을 기다리는 데 소요된 총 대기 시간(밀리초)입니다. |
| max_wait_time_ms | 요청이 이 래치 유형에서 대기하는 데 소요한 최대 시간(밀리초)입니다. |
참고 항목
이 DMV에서 반환되는 값은 마지막으로 데이터베이스 엔진을 다시 시작했거나 DMV를 다시 설정한 이후 누적된 값입니다. sqlserver_start_time sys.dm_os_sys_info 열을 사용하여 마지막 데이터베이스 엔진 시작 시간을 찾습니다. 오랫동안 실행된 시스템에서 max_wait_time_ms와 같은 일부 통계는 거의 유용하지 않습니다. 다음 명령을 사용하여 이 DMV에 대한 대기 통계를 다시 설정할 수 있습니다.
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
SQL Server 래치 경합 시나리오
다음 시나리오는 과도한 래치 경합을 일으키는 것으로 관찰되었습니다.
마지막 페이지/후행 페이지 삽입 경합
일반적인 OLTP 방식은 ID 또는 날짜 열에 클러스터형 인덱스를 만드는 것입니다. 이렇게 하면 인덱스의 올바른 실제 구성을 유지 관리하는 데 도움이 되므로 인덱스에서 읽기 및 쓰기 성능을 훨씬 향상할 수 있습니다. 그러나 이 스키마 디자인에서는 실수로 래치 경합이 발생할 수 있습니다. 이 문제는 작은 행이 있는 큰 테이블에서 주로 발생하며, 순차적으로 증가하는 선행 키 열(예: 오름차순 정수 또는 datetime 키)을 포함하는 인덱스에 삽입할 때 나타납니다. 이 시나리오에서는 애플리케이션이 아카이빙 작업을 제외하고 업데이트 또는 삭제를 수행하는 경우는 거의 없습니다.
다음 예제에서 스레드 1과 스레드 2는 모두 299페이지에 저장되는 레코드를 삽입하려고 합니다. 논리적 잠금 관점에서 행 수준 잠금을 사용하고 동일한 페이지의 두 레코드에 대한 배타적 잠금을 동시에 보유할 수 있으므로 아무 문제가 없습니다. 그러나 실제 메모리의 무결성을 보장하기 위해 한 번에 하나의 스레드만 배타적 래치를 획득할 수 있으므로 메모리의 업데이트 손실을 방지하기 위해 페이지에 대한 액세스가 직렬화됩니다. 이 예제에서는 스레드 1이 배타적 래치를 획득하고, 스레드 2는 대기 통계에 해당 리소스에 대한 PAGELATCH_EX 대기를 등록합니다. sys.dm_os_waiting_tasks DMV의 wait_type 값으로 표시됩니다.
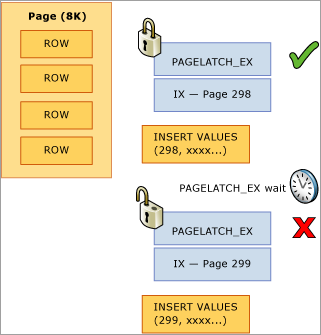
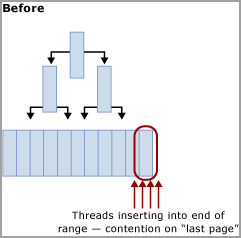
이 경합은 다음 다이어그램에 표시된 대로 B-트리의 오른쪽 가장자리에서 발생하기 때문에 일반적으로 "마지막 페이지 삽입" 경합이라고 합니다.
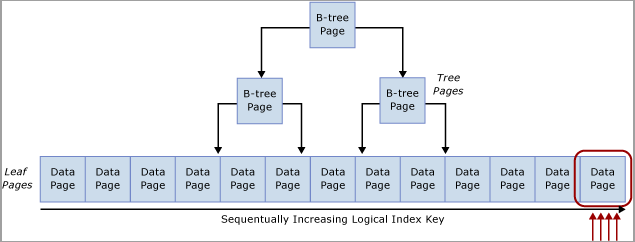
이 유형의 래치 경합은 다음과 같이 설명할 수 있습니다. 새 행이 인덱스로 삽입되면 SQL Server는 다음 알고리즘을 사용하여 수정을 실행합니다.
B-트리를 트래버스하여 새 레코드를 저장할 올바른 페이지를 찾습니다.
페이지를 PAGELATCH_EX로 래치하여 다른 사용자가 페이지를 수정하지 못하게 하고 리프가 아닌 모든 페이지에서 공유 래치(PAGELATCH_SH)를 획득합니다.
참고 항목
경우에 따라 SQL 엔진은 비-리프 B-트리 페이지에 대한 EX 래치도 획득해야 합니다. 예를 들어 페이지 분할이 발생하는 경우 직접 영향을 받을 페이지는 단독으로 래치(PAGELATCH_EX)해야 합니다.
행이 수정된 로그 항목을 기록합니다.
페이지에 행을 추가하고 페이지를 더티로 표시합니다.
모든 페이지의 래치를 해제합니다.
테이블 인덱스가 순차적으로 증가하는 키를 기반으로 하는 경우 각 새 삽입은 해당 페이지가 가득 찰 때까지 B-트리 끝에 있는 동일한 페이지로 이동합니다. 동시성이 높은 시나리오에서 이로 인해 B-트리의 오른쪽 가장자리에 경합이 발생할 수 있으며 클러스터형 및 비클러스터형 인덱스에 발생할 수 있습니다. 이러한 경합 유형의 영향을 받는 테이블은 주로 INSERT를 허용하며, 문제가 있는 인덱스의 페이지는 일반적으로 상대적으로 밀도가 높습니다(예: 행 크기 ~165바이트(행 오버헤드 포함)는 페이지당 ~49행). 삽입이 많은 이 예제에서는 PAGELATCH_EX/PAGELATCH_SH 대기가 발생할 것으로 예상되며 이는 일반적입니다. 페이지 래치 대기와 트리 페이지 래치 대기를 검사하려면 sys.dm_db_index_operational_stats DMV를 사용합니다.
다음 표에서는 이러한 유형의 래치 경합에서 관찰되는 주요 요인을 요약합니다.
| 요소 | 일반적인 관찰 |
|---|---|
| SQL Server에서 사용 중인 논리 CPU | 이러한 유형의 래치 경합은 주로 16개 이상의 CPU 코어 시스템에서 발생하며 가장 흔하게는 32개 이상의 CPU 코어 시스템에서 발생합니다. |
| 스키마 디자인 및 액세스 패턴 | 순차적으로 증가하는 ID 값을 트랜잭션 데이터에 대한 테이블의 인덱스에서 선행 열로 사용합니다. 인덱스에는 삽입 속도가 높은 기본 키가 증가합니다. 인덱스의 열 값이 하나 이상 순차적으로 증가합니다. 일반적으로 페이지당 행이 많은 작은 행 크기입니다. |
| 관찰된 대기 유형 | sys.dm_os_waiting_tasks DMV의 동일한 resource_description와 연결된 EX(배타적) 또는 SH(공유) 래치 대기에서 동일한 리소스를 놓고 경합하며 이는 대기 시간별로 정렬된 sys.dm_os_waiting_tasks 쿼리에서 반환됩니다. |
| 고려할 디자인 요인 | 삽입이 항상 B-트리 전체에 균일하게 분산되도록 할 수 있는 경우 비순차적 인덱스 완화 전략에 설명된 대로 인덱스 열의 순서를 변경하는 것이 좋습니다. 해시 파티션 완화 전략을 사용할 경우 슬라이딩 윈도우 보관과 같은 다른 모든 용도로 분할을 사용할 수 없게 됩니다. 해시 파티션 완화 전략을 사용하면 애플리케이션에서 사용되는 SELECT 쿼리에 대해 파티션 제거 문제가 발생할 수 있습니다. |
비클러스터형 인덱스 및 임의 삽입이 있는 작은 테이블의 래치 경합(큐 테이블)
이 시나리오는 일반적으로 SQL 테이블이 임시 큐(예: 비동기 메시징 시스템)로 사용될 때 표시됩니다.
이 시나리오에서는 EX(배타적) 및 공유(SH) 래치 경합이 다음 조건에서 발생할 수 있습니다.
- 삽입, 선택, 업데이트 또는 삭제 작업은 높은 동시성에서 발생합니다.
- 행 크기가 상대적으로 작습니다(페이지 밀도가 높아짐).
- 테이블의 행 수가 비교적 적어 인덱스 깊이가 2 또는 3으로 정의된 단순 B-트리가 생성됩니다.
참고 항목
DML(데이터 조작 언어)의 빈도와 시스템의 동시성이 충분히 높은 경우 이보다 깊이가 더 깊은 B-트리도 이러한 유형의 액세스 패턴으로 경합을 경험할 수 있습니다. 시스템에서 16개 이상의 CPU 코어를 사용할 수 있는 경우 동시성이 증가함에 따라 래치 경합 수준도 높아질 수 있습니다.
비순차적 열이 클러스터형 인덱스의 선행 키인 경우와 같이 B-트리에서 액세스가 무작위로 수행되는 경우에도 래치 경합이 발생할 수 있습니다. 다음 스크린샷은 이러한 유형의 래치 경합이 발생한 시스템의 스크린샷입니다. 이 예제에서 경합은 작은 행 크기와 상대적으로 얕은 B-트리로 인한 페이지의 밀도 때문입니다. 동시성이 증가함에 따라 GUID가 인덱스의 선행 열이었기 때문에 삽입이 B-트리에서 임의로 발생하더라도 페이지에 대한 래치 경합이 발생합니다.
다음 스크린샷에서는 버퍼 데이터 페이지와 PFS(페이지 사용 가능한 공간) 페이지에서 대기가 발생합니다. PFS 페이지 래치 경합에 대한 자세한 내용은 SQLSkills에서 타사 블로그 게시물(벤치마킹: SSD에서의 다중 데이터 파일)을 참조하세요. 데이터 파일 수가 증가한 경우에도 버퍼 데이터 페이지에서 래치 경합이 많이 발생했습니다.
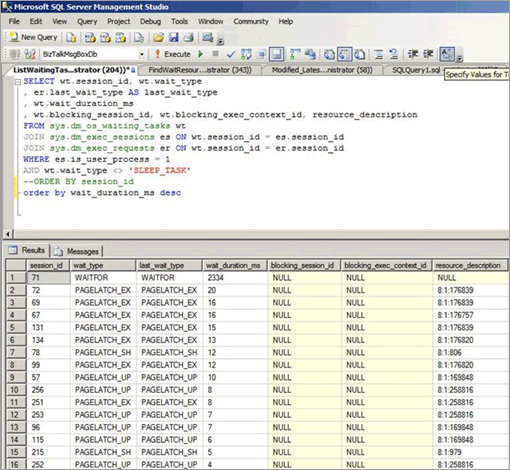
다음 표에서는 이러한 유형의 래치 경합에서 관찰되는 주요 요인을 요약합니다.
| 요소 | 일반적인 관찰 |
|---|---|
| SQL Server에서 사용 중인 논리 CPU | 래치 경합은 주로 16개 이상의 CPU 코어가 있는 컴퓨터에서 발생합니다. |
| 스키마 디자인 및 액세스 패턴 | 작은 테이블에 대한 삽입/선택/업데이트/삭제 액세스 패턴의 높은 비율 단순 B-트리(인덱스 깊이 2~3개). 작은 행 크기(페이지당 많은 레코드). |
| 동시성 수준 | 래치 경합은 애플리케이션 계층에서 동시성 수준이 높은 요청에서만 발생합니다. |
| 관찰된 대기 유형 | 루트 분할로 인한 버퍼(PAGELATCH_EX 및 PAGELATCH_SH) 및 비-버퍼 래치 ACCESS_METHODS_HOBT_VIRTUAL_ROOT의 대기를 관찰합니다. 또한 PAGELATCH_UP은 PFS 페이지에서 대기합니다. 비-버퍼 래치 대기에 대한 자세한 내용은 SQL Server 도움말에서 sys.dm_os_latch_stats(Transact-SQL)를 참조하세요. |
단순 B-트리와 인덱스에 대한 임의 삽입의 조합은 B-트리에서 페이지 분할을 유발하는 경향이 있습니다. 페이지 분할을 수행하려면 SQL Server가 모든 수준에서 공유(SH) 래치를 획득한 다음, 페이지 분할에 관련된 B-트리 페이지에 대한 배타적(EX) 래치를 획득해야 합니다. 동시성이 높고 데이터가 지속적으로 삽입 및 삭제되는 경우에도 B-트리 루트 분할이 발생할 수 있습니다. 예제에서는 다른 삽입이 B-트리에 대한 비-버퍼 래치가 획득될 때까지 기다려야 할 수 있습니다. 이 사항은 sys.dm_os_latch_stats DMV에서 관찰된 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 래치 유형의 대기 수가 많은 것에서 확인할 수 있습니다.
다음 스크립트를 수정하여 영향을 받는 테이블의 인덱스에 대한 B-트리의 깊이를 확인할 수 있습니다.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
PFS(페이지 사용 가능한 공간) 페이지에서 래치 경합
PFS는 Page Free Space의 약어로, SQL Server는 각 데이터베이스 파일의 모든 8088페이지(PageID = 1부터 시작)에 대해 PFS 1페이지를 할당합니다. PFS 페이지의 각 바이트는 페이지에 있는 사용 가능한 공간의 양, 할당 여부 및 페이지에 삭제할 레코드를 저장하는지 여부를 포함한 정보를 기록합니다. PFS 페이지에는 삽입 또는 업데이트 작업에서 새 페이지가 필요한 경우 할당에 사용할 수 있는 페이지에 대한 정보가 포함되어 있습니다. PFS 페이지는 할당 또는 할당 해제가 발생하는 경우를 포함하여 다양한 시나리오에서 업데이트해야 합니다. PFS 페이지를 보호하려면 업데이트(UP) 래치를 사용해야 하므로, 파일 그룹의 데이터 파일 수가 비교적 적고 CPU 코어 수가 많은 경우 PFS 페이지에서 래치 경합이 발생할 수 있습니다. 이 문제를 해결하는 간단한 방법은 파일 그룹당 파일 수를 늘리는 것입니다.
Warning
파일 그룹당 파일 수를 늘리면 메모리를 디스크에 분산하는 많은 대규모 정렬 작업을 포함하는 부하와 같은 특정 부하의 성능이 저하될 수 있습니다.
tempdb의 PFS 또는 SGAM 페이지에 대해 많은 PAGELATCH_UP 대기가 관찰되는 경우 다음 단계를 완료하여 이 병목 상태를 제거합니다.
tempdb 데이터 파일 수가 서버의 프로세서 코어 수와 같도록 tempdb에 데이터 파일을 추가합니다.
SQL Server 추적 플래그 1118을 사용하도록 설정합니다.
시스템 페이지의 경합으로 인한 할당 병목 상태에 대한 자세한 내용은 할당 병목 상태란? 블로그 게시물을 참조하세요.
tempdb의 테이블 반환 함수 및 래치 경합
쿼리 내에서 TVF를 많이 사용하는 것과 같이 tempdb에서 래치 경합을 일으킬 수 있는 할당 경합 이외의 다른 요인이 있습니다.
다양한 테이블 패턴의 래치 경합 처리
다음 섹션에서는 과도한 래치 경합과 관련된 성능 이슈를 해결하는 데 사용할 수 있는 기술에 대해 설명합니다.
비순차적 선행 인덱스 키 사용
래치 경합을 처리하는 한 가지 방법은 순차적 인덱스 키를 비순차적 키로 바꿔 인덱스 범위에서 삽입을 균등하게 분산하는 것입니다.
일반적으로 이 작업은 인덱스에 워크로드를 비례적으로 배포하는 선행 열을 배치하는 방식으로 수행됩니다. 두 가지 방법이 있습니다.
옵션: 테이블 내의 열을 사용하여 인덱스 키 범위에 값 분산
워크로드에서 키 범위에 삽입을 분산하는 데 사용할 수 있는 자연 값을 평가합니다. 예를 들어 ATM 뱅킹 시나리오를 고려해 보세요. 이 경우에는 한 고객이 한 번에 하나의 ATM만 사용할 수 있기 때문에 인출 트랜잭션 테이블에 삽입을 분산하는 데 ATM_ID가 적합할 수 있습니다. 마찬가지로, POS(Point of Sale) 시스템에서는 Checkout_ID 또는 스토어 ID가 키 범위에 삽입을 분산하는 데 사용할 수 있는 자연 값이 됩니다. 이 기술을 사용하려면 선행 키 열이 식별된 열의 값이거나 해당 값의 일부 해시를 하나 이상의 추가 열과 결합하여 고유성을 제공하는 복합 인덱스 키를 만들어야 합니다. 대부분의 경우 고유 값이 너무 많으면 물리적 조직이 좋지 않으므로 값의 해시가 가장 잘 작동합니다. 예를 들어 POS(Point of Sale) 시스템에서 CPU 코어 수와 일치하는 일부 모듈로인 Store ID에서 해시를 만들 수 있습니다. 이 기술을 사용하면 테이블 내에서 범위 수가 상대적으로 적어집니다. 그러나 래치 경합을 방지하기 위해 삽입을 분산하는 것으로 충분합니다. 다음 이미지에서 이 기술을 보여줍니다.
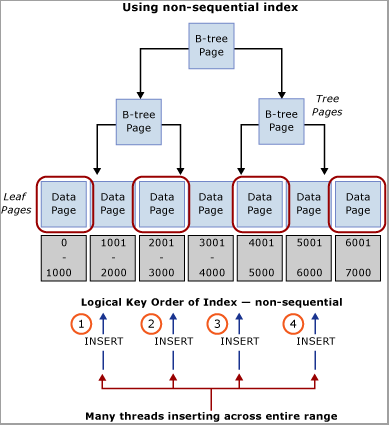
Important
이 패턴은 기존의 인덱싱 모범 사례와 모순됩니다. 이 기술은 B-트리에서 삽입을 균일하게 분산하는 데 도움이 되지만 애플리케이션 수준에서 스키마를 변경해야 할 수도 있습니다. 또한 이 패턴은 클러스터형 인덱스를 활용하는 범위 검색이 필요한 쿼리의 성능에 부정적인 영향을 미칠 수 있습니다. 이 디자인 방식이 제대로 작동하는지 확인하려면 워크로드 패턴에 대한 일부 분석이 필요합니다. 삽입 처리량 및 스케일링을 얻기 위해 순차적 검사 성능을 희생할 수 있는 경우 이 패턴을 구현해야 합니다.
이 패턴은 성능 랩 참여 중에 구현되었으며 실제 CPU 코어가 32개 있는 시스템에서 래치 경합을 해결했습니다. 이 테이블은 트랜잭션이 끝날 때 마감 잔액을 저장하는 데 사용되었습니다. 각 비즈니스 트랜잭션은 테이블에 단일 삽입을 수행했습니다.
원래 테이블 정의
원래 테이블 정의를 사용하는 경우 클러스터형 인덱스 pk_table1에서 과도한 래치 경합이 발생하는 것으로 관찰되었습니다.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
참고 항목
테이블 정의의 개체 이름이 원래 값에서 변경되었습니다.
다시 정렬된 인덱스 정의
UserID를 사용하여 인덱스의 키 열을 기본 키의 선행 열로 다시 정렬하면 페이지에서 삽입이 거의 임의로 분산됩니다. 모든 사용자가 동시에 온라인 상태가 아니므로 결과적 분포는 100% 임의가 아니었지만, 배포는 과도한 래치 경합을 완화할 만큼 무작위였습니다. 인덱스 정의를 다시 정렬할 때의 한 가지 주의 사항은 이 테이블에 대한 모든 select 쿼리를 수정하여 UserID와 TransactionID 둘 다를 같음 조건자로 사용해야 한다는 것입니다.
Important
프로덕션 환경에서 실행하기 전에 테스트 환경의 변경 내용을 철저히 테스트해야 합니다.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
기본 키의 선행 열로 해시 값 사용
다음 테이블 정의는 CPU 수에 맞는 모듈로를 생성하는 데 사용할 수 있습니다. HashValue는 순차적으로 증가하는 값 TransactionID를 사용하여 생성되어 B-트리 간에 균일한 분포를 보장합니다.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
옵션: 인덱스의 선행 키 열로 GUID 사용
자연 구분 기호가 없는 경우 GUID 열을 인덱스의 선행 키 열로 사용하여 삽입이 균일하게 분산되도록 할 수 있습니다. GUID를 인덱스 키 접근 방식의 선행 열로 사용하면 다른 기능에 분할을 사용할 수 있지만, 이 기술은 더 많은 페이지 분할, 열악한 물리적 조직, 낮은 페이지 밀도의 잠재적 단점을 가져올 수도 있습니다.
참고 항목
GUID를 인덱스의 주요 키 열로 사용하는 것은 논쟁의 여지가 있는 주제입니다. 이 방법의 장단점에 대한 심층적인 논의는 이 문서의 범위를 벗어납니다.
계산 열에서 해시 분할 사용
SQL Server 내의 테이블 분할을 사용하여 과도한 래치 경합을 완화할 수 있습니다. 분할된 테이블에 계산 열을 사용하여 해시 분할 구성표를 만드는 것은 다음 단계를 통해 수행할 수 있는 일반적인 방법입니다.
새 파일 그룹을 만들거나 기존 파일 그룹을 사용하여 파티션을 보유합니다.
새 파일 그룹을 사용하는 경우 LUN을 통해 개별 파일의 균형을 동일하게 조정하여 최적의 레이아웃을 사용합니다. 액세스 패턴에 높은 삽입 속도가 적용된 경우 SQL Server 컴퓨터에 실제 CPU 코어가 있는 것과 동일한 수의 파일을 만들어야 합니다.
CREATE PARTITION FUNCTION 명령을 사용하여 테이블을 X 파티션으로 분할합니다. 여기서 X는 SQL Server 컴퓨터의 실제 CPU 코어 수입니다. (파티션 최대 32개)
참고 항목
CPU 코어 수에 대한 파티션 수의 1:1 맞춤이 항상 필요한 것은 아닙니다. 대부분의 경우 CPU 코어 수보다 작은 값이면 됩니다. 파티션이 많을수록 모든 파티션을 검색해야 하는 쿼리에 대한 오버헤드가 더 많이 발생할 수 있으며, 이러한 경우 더 적은 파티션이 도움이 됩니다. 실제 고객 워크로드가 32개 파티션인 64 및 128 논리 CPU 시스템에 대한 SQLCAT 테스트에서는 과도한 래치 경합을 해결하고 확장 목표에 도달하기에 충분했습니다. 궁극적으로 이상적인 파티션 수는 테스트를 통해 결정해야 합니다.
CREATE PARTITION SCHEME 명령을 사용합니다.
- 파티션 함수를 파일 그룹에 바인딩합니다.
- tinyint 또는 smallint 형식의 해시 열을 테이블에 추가합니다.
- 좋은 해시 분포를 계산합니다. 예를 들어 모듈로 또는 binary_checksum의 해시바이트를 사용합니다.
구현을 위해 다음 샘플 스크립트를 사용자 지정할 수 있습니다.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
이 스크립트를 사용하여 마지막 페이지/후행 페이지 삽입 경합으로 인한 문제가 발생한 테이블을 해시 분할할 수 있습니다. 이 기술은 테이블을 분할하고 해시 값 모듈러스 작업을 사용하여 테이블 파티션에 삽입을 분산함으로써 마지막 페이지에서 경합을 이동합니다.
계산 열이 있는 해시 분할의 역할
다음 다이어그램과 같이 이 기술은 해시 함수의 인덱스를 다시 작성하고 SQL Server 컴퓨터의 물리적 CPU 코어 수와 동일한 개수의 파티션을 만들어 마지막 페이지에서 다른 곳으로 경합을 이동합니다. 삽입은 여전히 논리 범위의 끝(순차적으로 증가하는 값)으로 이동하지만 해시 값 모듈러스 연산을 통해 삽입이 다른 B-트리 간에 분할되어 병목 현상이 완화됩니다. 이 내용은 다음 다이어그램에 설명되어 있습니다.
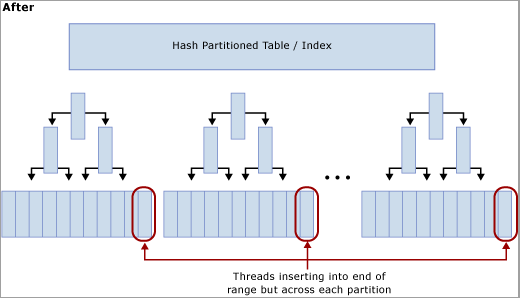
해시 분할을 사용할 경우의 장단점
해시 분할은 삽입에 대한 경합을 제거할 수 있지만, 이 기술을 사용할지 여부를 결정할 때 고려해야 할 몇 가지 장단점이 있습니다.
대부분의 경우 조건자에 해시 파티션을 포함하고, 이 쿼리를 실행할 때 파티션 제거를 제공하지 않는 쿼리 계획을 생성하도록 select 쿼리를 수정해야 합니다. 다음 스크린샷은 해시 분할이 구현된 후 파티션 제거가 없는 잘못된 계획을 보여줍니다.
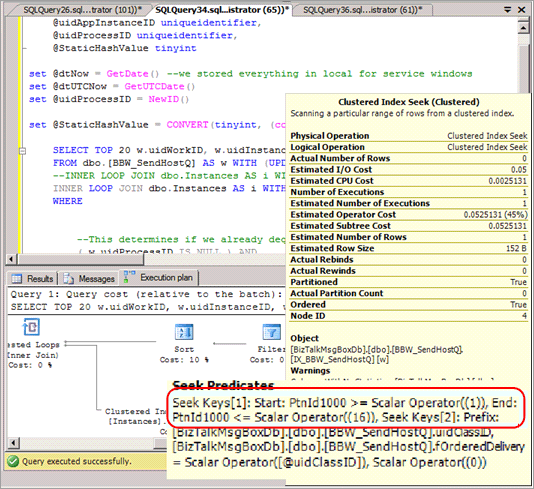
범위 기반 보고서와 같은 다른 특정 쿼리에서 파티션 제거 가능성을 제거합니다.
해시 분할 테이블을 다른 테이블에 조인할 때 파티션 제거를 위해 두 번째 테이블은 동일한 키에서 해시 분할되어야 하며 해시 키는 조인 조건의 일부여야 합니다.
해시 분할은 슬라이딩 윈도우 보관 및 파티션 스위치 기능과 같은 다른 관리 기능에 대한 분할 사용을 방지합니다.
해시 분할은 삽입에 대한 경합을 완화하여 전체 시스템 처리량을 늘리기 때문에 과도한 래치 경합을 완화하기 위한 효과적인 전략입니다. 관련된 몇 가지 장단점이 있기 때문에 일부 액세스 패턴에 대한 최적의 솔루션이 아닐 수 있습니다.
래치 경합 해결을 위해 사용하는 기술 요약
다음 두 섹션에서는 과도한 래치 경합을 해결하는 데 사용할 수 있는 기술을 요약해서 보여줍니다.
비순차 키/인덱스
장점:
- 슬라이딩 윈도우 구성표 및 파티션 스위치 기능을 사용하여 데이터 보관과 같은 다른 분할 기능을 사용할 수 있습니다.
단점:
- 항상 삽입이 ‘충분히’ 균일하게 분산되도록 키/인덱스를 선택하기 어려울 수 있습니다.
- GUID를 선행 열로 사용하면 페이지 분할 작업이 과도하게 발생할 수 있다는 주의와 함께 균일한 배포를 보장할 수 있습니다.
- B-트리에서 임의 삽입을 수행하면 페이지 분할 작업이 너무 많아지고 리프가 아닌 페이지에서 래치 경합이 발생할 수 있습니다.
계산 열을 사용하여 해시 분할
장점:
- 삽입에 대해 투명합니다.
단점:
- 파티션 전환 옵션을 사용한 데이터 보관 등의 의도한 관리 기능에 분할을 사용할 수 없습니다.
- 개별 및 범위 기반 선택/업데이트와 조인을 수행하는 쿼리를 비롯한 쿼리에 대한 파티션 제거 문제가 발생할 수 있습니다.
- 지속형 계산 열 추가는 오프라인 작업입니다.
팁
추가 기술에 대해서는 PAGELATCH_EX 대기 및 과도한 삽입 블로그 게시물을 참조하세요.
연습: 래치 경합 진단
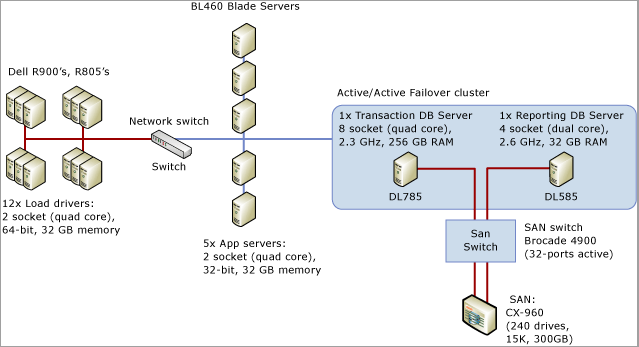
다음 연습에서는 실제 시나리오에서 문제를 해결하기 위해 SQL Server 래치 경합 진단 및 다양한 테이블 패턴에 대한 래치 경합 처리에 설명된 도구와 기술을 보여줍니다. 이 시나리오에서는 256GB 메모리와 함께 8개 소켓, 32개의 물리적 코어 시스템에서 실행되는 SQL Server 애플리케이션에 대해 트랜잭션을 수행하는 약 8,000개의 저장소를 시뮬레이션한 POS(Point of Sale) 시스템의 부하 테스트를 수행하는 고객 참여를 설명합니다.
다음 다이어그램은 POS(Point of Sale) 시스템을 테스트하는 데 사용되는 하드웨어를 자세히 설명합니다.
증상: 핫 래치
이 경우 일반적으로 평균 1ms 이상을 높은 것으로 정의하는 PAGELATCH_EX 대한 높은 대기가 발생했습니다. 이 경우 대기 시간이 20ms를 초과하는 것으로 일관되게 관찰되었습니다.
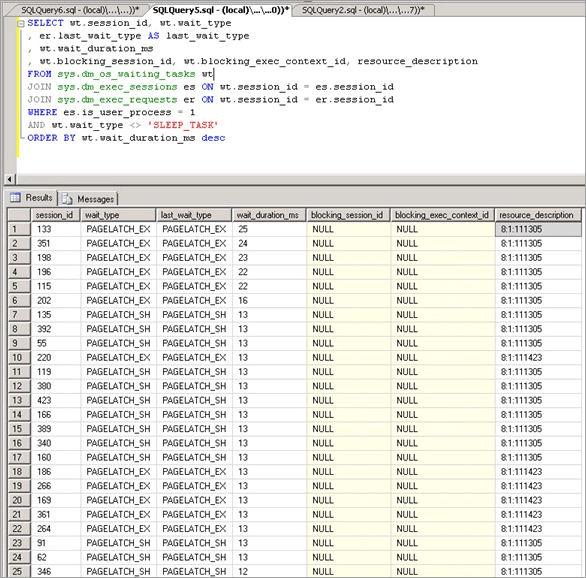
래치 경합에 문제가 있다고 판단되면 래치 경합의 원인을 파악하는 작업을 시작했습니다.
래치 경합을 일으키는 개체 격리
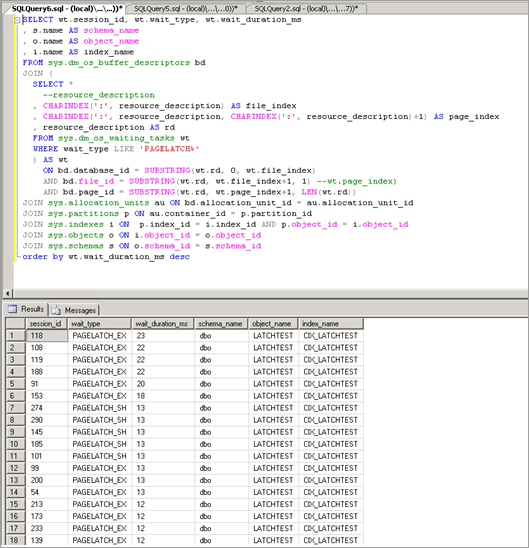
다음 스크립트는 resource_description 열을 사용하여 PAGELATCH_EX 경합을 일으키는 인덱스를 격리합니다.
참고 항목
이 스크립트에서 반환된 resource_description 열은 <DatabaseID,FileID,PageID> 형식으로 리소스를 설명합니다. 여기서 DatabaseID와 연결된 데이터베이스의 이름은 DatabaseID 값을 DB_NAME () 함수에 전달하여 확인할 수 있습니다.
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
여기에 표시된 것처럼 경합은 LATCHTEST 테이블과 인덱스 이름 CIX_LATCHTEST에서 발생합니다. 워크로드를 익명화하도록 메모 이름이 변경되었습니다.
반복적으로 폴링하고 임시 테이블을 사용하여 구성 가능한 기간 동안의 총 대기 시간을 결정하는 고급 스크립트는 부록에서 쿼리 버퍼 설명자를 사용하여 래치 경합을 일으키는 개체 확인을 참조하세요.
래치 경합을 일으키는 개체를 격리하는 대체 기술
경우에 따라 sys.dm_os_buffer_descriptors를 쿼리하는 것이 실용적이지 않을 수 있습니다. 버퍼 풀에서 사용할 수 있는 시스템 메모리가 증가하면 이 DMV를 실행하는 데 필요한 시간도 늘어납니다. 256GB 시스템에서 이 DMV를 실행하는 데 최대 10분 이상이 걸릴 수 있습니다. 대체 기술을 사용할 수 있으며 다음과 같이 광범위하게 설명되며 랩에서 실행한 다른 워크로드로 설명됩니다.
부록 스크립트인 대기 시간별로 정렬된 sys.dm_os_waiting_tasks 쿼리를 사용하여 현재 대기 중인 작업을 쿼리합니다.
여러 스레드가 동일한 페이지에서 경합하는 경우 호위가 발생하는 키 페이지를 식별합니다. 이 예제에서 삽입을 수행하는 스레드는 B-트리의 후행 페이지에서 경합하며 EX 래치를 획득할 수 있을 때까지 대기합니다. 이는 첫 번째 쿼리의 resource_description(이 경우 8:1:111305)으로 표시됩니다.
DBCC PAGE를 통해 페이지에 대한 추가 정보를 표시하는 추적 플래그 3604를 다음 구문으로 사용하도록 설정합니다. resource_description을 통해 얻은 값으로 괄호 안의 값을 대체합니다.
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);DBCC 출력을 검사합니다. 연결된 메타데이터 ObjectID(이 경우 '78623323')가 있어야 합니다.
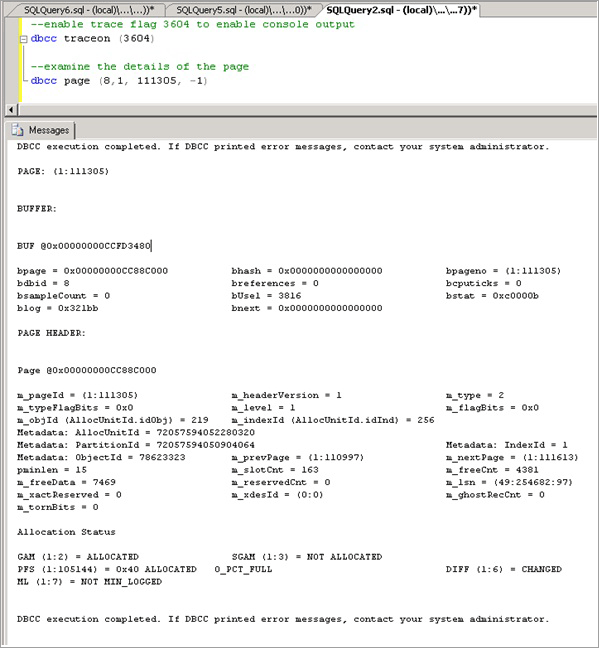
이제 다음 명령을 실행하여 경합을 유발하는 개체의 이름을 확인할 수 있습니다. 예상대로 LATCHTEST입니다.
참고 항목
올바른 데이터베이스 컨텍스트에 있는지 확인합니다. 그렇지 않으면 쿼리가 NULL을 반환합니다.
--get object name select OBJECT_NAME (78623323);
요약 및 결과
위의 기술을 사용하여 지금까지 가장 많은 삽입을 받은 테이블의 키 값이 순차적으로 증가하는 클러스터형 인덱스에 경합이 발생했음을 확인할 수 있었습니다. 이 유형의 경합은 날짜/시간, ID 또는 애플리케이션에서 생성된 transactionID와 같이 순차적으로 증가하는 키 값이 있는 인덱스에 일반적이지 않습니다.
이 문제를 해결하기 위해 계산 열과 해시 분할을 사용하고 690% 성능 향상이 관찰되었습니다. 다음 표에서는 계산 열로 해시 분할을 구현하기 전과 후에 애플리케이션의 성능을 요약합니다. 래치 경합 병목 현상이 제거된 후 CPU 사용률이 예상대로 처리량에 따라 크게 증가합니다.
| 측정 | 해시 분할 이전 | 해시 분할 후 |
|---|---|---|
| 초당 비즈니스 트랜잭션 | 36 | 249 |
| 평균 페이지 래치 대기 시간 | 36밀리초 | 0.6밀리초 |
| 초당 래치 대기 | 9,562 | 2,873 |
| SQL 프로세서 시간 | 24% | 78% |
| 초당 SQL 배치 요청 | 12,368 | 47,045 |
위의 표에서 볼 수 있듯이 과도한 페이지 래치 경합으로 인한 성능 문제를 올바르게 식별하고 해결하면 전체 애플리케이션 성능에 긍정적인 영향을 미칠 수 있습니다.
부록: 대체 기술
과도한 페이지 래치 경합을 방지하기 위한 한 가지 가능한 전략은 각 행이 전체 페이지를 사용하도록 CHAR 열이 있는 행을 패딩하는 것입니다. 이 전략은 전반적인 데이터 크기가 작고, 다음과 같은 요소가 결합되어 발생하는 EX 페이지 래치 경합을 처리해야 하는 경우에 사용할 수 있는 옵션입니다.
- 작은 행 크기
- 단순 B-트리
- 임의 삽입, 선택, 업데이트, 삭제 작업의 비율이 높은 액세스 패턴
- 임시 큐 테이블과 같은 작은 테이블
전체 페이지를 차지하도록 행을 패딩하여 SQL에서 추가 페이지를 할당하게 함으로써 삽입에 사용할 수 있는 페이지를 늘리고 EX 페이지 래치 경합을 줄입니다.
각 행이 전체 페이지를 차지하도록 행 패딩
다음과 유사한 스크립트를 사용하여 행을 패딩하고 전체 페이지를 차지할 수 있습니다.
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
참고 항목
패딩 값에 대한 추가 CPU 요구 사항과 행을 기록하는 데 필요한 추가 공간을 줄이기 위해 페이지당 하나의 행을 강제로 적용하는 가능한 가장 작은 문자를 사용합니다. 모든 바이트는 고성능 시스템에서 계산됩니다.
이 기술은 완전성을 위해 설명됩니다. 실제로 SQLCAT는 단일 성능 참여에서 10,000개의 행이 있는 작은 테이블에서만 이 작업을 사용했습니다. 이 기술은 큰 테이블에 대한 SQL Server의 메모리 압력을 증가시키고 리프가 아닌 페이지에서 비-버퍼 래치 경합을 초래할 수 있기 때문에 애플리케이션이 제한적입니다. 추가 메모리 압력은 이 기술을 적용하는 데 애플리케이션에 대한 중요한 제한 요인이 될 수 있습니다. 최신 서버에서 사용할 수 있는 메모리 양을 사용하면 OLTP 워크로드에 대한 작업 집합의 상당 부분을 일반적으로 메모리에 보관합니다. 데이터 집합이 메모리에 더 이상 맞지 않는 크기로 증가하면 성능이 크게 저하됩니다. 따라서 이 기술은 작은 테이블에만 적용할 수 있는 옵션입니다. 이 기술은 SQLCAT에서 큰 테이블에 대한 마지막 페이지/후행 페이지 삽입 경합과 같은 시나리오에 사용되지 않습니다.
Important
이 전략을 사용할 경우 B-트리의 비-리프 수준에서 많은 페이지 분할이 발생할 수 있으므로 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 래치 유형의 대기 수가 많을 수 있습니다. 이 경우 SQL Server는 모든 수준에서 SH(공유) 래치를 획득한 다음 페이지 분할이 가능한 B-트리의 페이지에서 EX(배타적) 래치를 획득해야 합니다. 행을 패딩한 후 sys.dm_os_latch_stats DMV에서 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 래치 유형의 대기 수가 많은지 확인합니다.
부록: SQL Server 래치 경합 스크립트
이 섹션에는 래치 경합 문제를 진단하고 해결하는 데 사용할 수 있는 스크립트가 포함되어 있습니다.
세션 ID별로 정렬된 sys.dm_os_waiting_tasks 쿼리
다음 샘플 스크립트는 sys.dm_os_waiting_tasks를 쿼리하고 세션 ID를 기준으로 정렬된 래치 대기를 반환합니다.
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
대기 기간별로 정렬된 sys.dm_os_waiting_tasks 쿼리
다음 샘플 스크립트는 sys.dm_os_waiting_tasks를 쿼리하고 대기 기간을 기준으로 정렬된 래치 대기를 반환합니다.
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
일정 기간 동안 대기 계산
다음 스크립트는 일정 기간 동안 래치 대기를 계산하고 반환합니다.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
래치 경합을 일으키는 개체를 확인하기 위한 쿼리 버퍼 설명자
다음 스크립트는 버퍼 설명자를 쿼리하여 가장 긴 래치 대기 시간과 연결된 개체를 결정합니다.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
해시 분할 스크립트
이 스크립트의 사용은 계산 열과 함께 해시 분할 사용에 설명되어 있으며 구현을 위해 사용자 지정해야 합니다.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
다음 단계
성능 모니터링 도구에 대한 자세한 내용은 성능 모니터링 및 튜닝 도구를 참조하세요.