메모리 최적화 테이블의 테이블 및 행 크기
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL 데이터베이스
Azure SQL 데이터베이스 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server 2016(13.x) 이전에는 메모리 최적화 테이블의 행 내 데이터 크기가 8,060바이트를 초과할 수 없었습니다. 그러나 SQL Server 2016(13.x)부터 Azure SQL 데이터베이스에서 큰 열(예: 여러 varbinary(8000) 열) 및 LOB 열(즉, varbinary(max) 여러 개와 varchar(max) 및 nvarchar(max)이 있는 메모리 최적화 테이블을 만들고 고유하게 컴파일된 T-SQL(Transact-SQL) 모듈 및 테이블 형식을 사용하여 작업을 수행할 수 있습니다.
8,060바이트 행 크기 제한에 맞지 않는 열은 행 외부의 별도 내부 테이블에 배치됩니다. 각 행 외부 열에는 해당하는 내부 테이블이 있으며, 이 테이블에는 단일 비클러스터형 인덱스가 있습니다. 행 외부 열에 사용되는 이 내부 테이블에 대한 자세한 내용은 sys.memory_optimized_tables_internal_attributes를 참조하세요.
행과 테이블의 크기를 계산하는 데 유용한 특정 시나리오가 있습니다.
테이블에서 사용하는 메모리 양입니다.
테이블에서 사용하는 메모리 양은 정확하게 계산할 수 없습니다. 여러 가지 요소들이 사용되는 메모리 양에 영향을 줍니다. 페이지 기반 메모리 할당, 지역성, 캐싱 및 패딩과 같은 요소입니다. 또한 활성 트랜잭션이 연결되어 있거나 가비지 수집을 기다리는 여러 버전의 행도 있습니다.
테이블의 데이터 및 인덱스에 필요한 최소 크기는 나중에 본 문서에서 설명하는
<table size>에 대한 계산으로 제공됩니다.메모리 사용량에 대한 계산은 아무리 잘해도 근사값만 얻을 수 있으며, 배포 계획에 용량 계획을 포함하는 것이 좋습니다.
행의 데이터 크기이며 8,060 바이트 행 크기 제한에 맞습니까? 이 질문에 대답하려면 나중에 본 문서에서 설명하는
<row body size>에 대한 계산을 사용해야 합니다.
메모리 최적화 테이블은 행에 대한 포인터를 포함하는 행 및 인덱스의 컬렉션으로 구성됩니다. 다음 그림은 인덱스와 행이 있는 테이블입니다. 이 테이블에는 행 머리글과 본문이 있습니다.
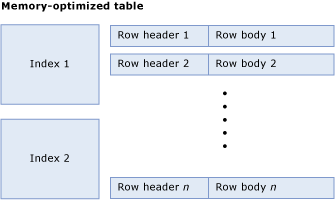
테이블 크기 계산
테이블의 메모리 내 크기(바이트)는 다음과 같이 계산합니다.
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
해시 인덱스의 크기는 테이블 생성 시 고정되며 실제 버킷 수에 따라 달라집니다. 인덱스 정의로 지정된 값 bucket_count은 가장 가까운 2의 거듭제곱으로 반올림하여 실제 버킷 수를 구합니다. 예를 들어, 지정된 bucket_count가 100000인 경우 인덱스의 실제 버킷 수는 131072입니다.
<hash index size> = 8 * <actual bucket count>
비클러스터형 인덱스의 크기는 <row count> * <index key size>입니다.
행 크기는 헤더 및 본문을 추가하여 계산됩니다.
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
행 본문 크기 계산
메모리 최적화 테이블의 행에는 다음과 같은 구성 요소가 있습니다.
행 머리글에는 행 버전 관리를 구현하는 데 필요한 타임스탬프가 포함됩니다. 행 헤더에는 해시 버킷에서 행 체인을 구현하기 위한 인덱스 포인터도 포함되어 있습니다(앞에서 설명).
행 본문에는 실제 열 데이터가 포함됩니다. 여기에는 null 허용 열의 null 배열 및 가변 길이 데이터 형식에 대한 오프셋 배열과 같은 일부 보조 정보가 포함됩니다.
다음 그림에서는 두 개의 인덱스가 있는 테이블에 대한 행 구조를 보여 줍니다.

시작 및 종료 타임스탬프는 특정 행 버전의 유효 기간을 나타냅니다. 이 간격에서 시작하는 트랜잭션은 이 행 버전을 볼 수 있습니다. 자세한 내용은 메모리 최적화 테이블이 있는 트랜잭션을 참조하세요.
인덱스 포인터는 체인에서 해시 버킷에 속한 그 다음 행을 가리킵니다. 다음 그림은 열이 두 개(이름, 도시), 인덱스가 두 개 있는 테이블의 구조입니다. 하나는 이름 열에, 다른 하나는 도시 열에 있습니다.
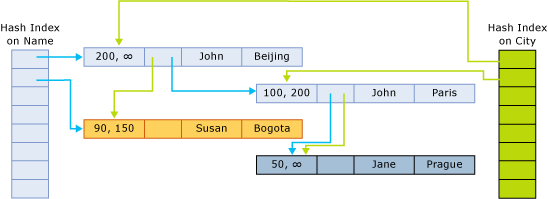
이 그림에서, 이름 John와 Jane는 첫 버킷에 해시됩니다. Susan은 두 번째 버킷에 해시됩니다. 도시 Beijing과 Bogota는 첫 버킷에 해시됩니다. Paris과 Prague는 두 번째 버킷에 해시됩니다.
따라서 이름에 대한 해시 인덱스의 체인은 다음과 같습니다.
- 첫 번째 버킷:
(John, Beijing),(John, Paris),(Jane, Prague) - 두 번째 버킷:
(Susan, Bogota)
도시 인덱스의 체인은 다음과 같습니다.
- 첫 번째 버킷:
(John, Beijing),(Susan, Bogota) - 두 번째 버킷:
(John, Paris),(Jane, Prague)
종료 타임스탬프 ∞(무한대)는 해당 행이 현재 유효한 버전의 행임을 나타냅니다. 이 행 버전이 작성된 이후로 행이 업데이트되거나 삭제되지는 않았습니다.
200보다 큰 시간 동안 테이블에는 다음 행이 포함됩니다.
| 속성 | City |
|---|---|
| John | 베이징 |
| Jane | 프라하 |
그러나 시작 시간 100이 있는 활성 트랜잭션은 다음 버전의 테이블을 참조하세요.
| 속성 | City |
|---|---|
| John | 파리 |
| Jane | 프라하 |
| Susan | 보고타 |
<row body size>의 계산은 다음 표에서 설명합니다.
행 본문 크기는 계산된 크기 및 실제 크기의 두 가지 방식으로 계산할 수 있습니다.
계산된 행 본문 크기로 표시된 계산 크기는 8,060바이트의 행 크기 제한을 초과하는지 확인하는 데 사용됩니다.
실제 행 본문 크기로 표시된 실제 크기는 메모리 및 검사점 파일에서 행 본문의 실제 스토리지 크기입니다.
계산된 행 본문 크기와 실제 행 본문 크기는 모두 비슷하게 계산됩니다. 유일한 차이점은 다음 표의 하단에 표시된 것처럼 (n)varchar(i) 및 varbinary(i) 열의 크기에 대한 계산입니다. 계산된 행 본문 크기는 선언된 크기인 i 를 열 크기로 사용하고, 실제 행 본문 크기는 데이터의 실제 크기를 사용합니다.
다음 표에서는 <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>와 같이 지정된 행 본문 크기의 계산에 대해 설명합니다.
| 섹션 | 크기 | 설명 |
|---|---|---|
| 단순 형식 열 | SUM(<size of shallow types>). 개별 형식의 크기(바이트)는 다음과 같습니다.bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8Numeric(전체 자릿수 <= 18): 8time: 8Numeric(전체 자릿수 > 18): 16uniqueidentifier: 16 |
|
| 단순 열 안쪽 여백 | 가능한 값은 다음과 같습니다. 딥 형식 열이 있고 단순 열의 총 데이터 크기가 홀수인 경우 1.그렇지 않으면 0입니다. |
딥 형식은 (var)binary와 (n)(var)char 형식입니다. |
| 딥 형식 열의 오프셋 배열 | 가능한 값은 다음과 같습니다. 딥 형식 열이 없으면 0그렇지 않으면 2 + 2 * <number of deep type columns>입니다. |
딥 형식은 (var)binary와 (n)(var)char 형식입니다. |
| Null 배열 | <number of nullable columns> / 8 전체 바이트로 반올림됨. |
배열에는 nullable 열당 1비트가 있습니다. 바이트 단위로 반올림됩니다. |
| Null 배열 패딩 | 가능한 값은 다음과 같습니다. 딥 형식 열이 있고 1 배열의 크기가 홀수 바이트인 경우 NULL입니다.그렇지 않으면 0입니다. |
딥 형식은 (var)binary와 (n)(var)char 형식입니다. |
| 안쪾 여백 | 딥 형식 열이 없는 경우: 0딥 형식 열이 있는 경우 단순 열에 필요한 가장 큰 맞춤에 따라 0~7바이트의 안쪽 여백이 추가됩니다. GUID 열에는 1바이트(16이 아님)의 맞춤이 필요하고 숫자 열에는 항상 8바이트(16이 아님)의 맞춤이 필요하다는 점을 제외하고 각 단순 열에는 이전에 설명한 것과 같은 크기가 필요합니다. 모든 단순 열 중에서 가장 큰 맞춤 요구 사항이 사용됩니다. 0~7바이트 안쪽 여백이 추가되어 지금까지의 총 크기(딥 형식 열 제외)는 필요한 맞춤의 배수가 됩니다. |
딥 형식은 (var)binary와 (n)(var)char 형식입니다. |
| 고정 길이 딥 형식 열 | SUM(<size of fixed length deep type columns>)각 열의 크기는 다음과 같습니다. char(i) 및 binary(i)는 i.nchar(i)는 2 * i |
고정 길이 딥 형식 열은 char(i), nchar(i) 또는 binary(i) 형식의 열입니다. |
| 가변 길이 딥 형식 컬럼 계산 크기 | SUM(<computed size of variable length deep type columns>)각 열의 계산 크기는 다음과 같습니다. varchar(i) 및 varbinary(i)는 invarchar(i)는 2 * i |
이 행은 계산된 행 본문 크기에만 적용되었습니다. 가변 길이 딥 형식 열은 varchar(i), nvarchar(i) 또는 varbinary(i) 형식의 열입니다. 계산된 크기는 열의 최대 길이( i)에 의해 결정됩니다. |
| 가변 길이 전체 형식 열 실제 크기 | SUM(<actual size of variable length deep type columns>)각 열의 실제 크기는 다음과 같습니다. n, 여기서 n은 varchar(i)에 대해 열에 저장된 문자 수입니다.2 * n, 여기서 n은 nvarchar(i)에 대해 열에 저장된 문자 수입니다.n, 여기서 n은 varbinary(i)에 대해 열에 저장된 바이트 수입니다. |
이 행은 실제 행 본문 크기에만 적용되었습니다. 실제 크기는 행의 열에 저장된 데이터에 의해 결정됩니다. |
예제: 테이블 및 행 크기 계산
해시 인덱스의 경우 실제 버킷 수는 가장 가까운 2의 거듭제곱으로 반올림됩니다. 예를 들어, 지정된 bucket_count가 100000인 경우 인덱스의 실제 버킷 수는 131072입니다.
다음 정의의 Orders 테이블을 살펴보십시오.
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
이 테이블에는 해시 인덱스 하나와 비클러스터형 인덱스(기본 키)가 있습니다. 또한 고정 길이 열 세 개와 가변 길이 열 한 개가 있으며 열 중 하나가 NULL합니다(OrderDescription). Orders 테이블에 행이 8,379개 있고 OrderDescription 열에 있는 값의 평균 길이가 78자라고 가정해 보겠습니다.
테이블 크기를 결정하려면 먼저 인덱스 크기를 결정해야 합니다. 두 인덱스의 bucket_count은 10000으로 지정됩니다. 가장 가까운 2의 거듭 제곱인 16384로 반올림됩니다 따라서 Orders 테이블에서 인덱스의 총 크기는 다음과 같습니다.
8 * 16384 = 131072 bytes
남은 것은 테이블 데이터 크기로 다음과 같습니다.
<row size> * <row count> = <row size> * 8379
예제 테이블에는 행이 8,379개 있습니다. 즉 다음과 같습니다.
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
다음으로, <actual row body size>을 계산해 보겠습니다.
단순 형식 열:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16총 단순 열 크기는 짝수이므로 단순 열 패딩은 0입니다.
딥 형식 열의 오프셋 배열:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULL배열 = 1NULL배열 패딩 = 1,NULL배열 크기가 홀수이고 딥 형식 열이 있기 때문입니다.패딩
- 가장 큰 맞춤 요구 사항은 8입니다.
- 지금까지 크기는 16 + 0 + 4 + 1 + 1 = 22입니다.
- 가장 가까운 8의 배수는 24입니다.
- 총 패딩은 24 - 22 = 2바이트입니다.
고정 길이 딥 형식 열이 없습니다(고정 길이 딥 형식 열: 0.).
전체 형식 열의 실제 크기는 2 * 78 = 156입니다. 단일 딥 형식 열
OrderDescription에는 형식nvarchar이 있습니다.
<actual row body size> = 24 + 156 = 180 bytes
계산을 완료하려면 다음을 수행합니다.
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
따라서 메모리의 총 테이블 크기는 약 2MB입니다. 메모리 할당으로 인해 발생할 수 있는 잠재적 오버헤드와 이 테이블에 액세스하는 트랜잭션에 필요한 행 버전 관리를 고려하지 않은 수치입니다.
이 테이블 및 해당 인덱스에 할당되어 사용되는 실제 메모리는 다음 쿼리를 통해 얻을 수 있습니다.
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
행 외부 열 제한 사항
메모리 최적화 테이블에 행 외부 열을 사용할 경우의 특정 제한 사항 및 유의 사항은 다음과 같습니다.
- 메모리 최적화 테이블에 대한 columnstore 인덱스가 있는 경우 모든 열이 행 내부에 맞아야 합니다.
- 모든 인덱스 키 열은 행 내부에 저장되어야 합니다. 인덱스 키 열이 행 내부에 맞지 않을 경우 인덱스를 추가하지 못합니다.
- 행 외부 열이 없는 메모리 최적화 테이블을 변경하는 경우 주의 해야 합니다.
- LOB의 경우 크기 제한은 디스크 기반 테이블의 크기 제한(LOB 값에 대한 2GB 제한)을 반영합니다.
- 최적의 성능을 위해 열은 대부분 8,060바이트 이내여야 합니다.
- 행이 없으면 과도한 메모리 및/또는 디스크 사용량이 발생할 수 있습니다.