쿼리 저장소 사용한 워크로드 모니터링 모범 사례
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL 데이터베이스
Azure SQL 데이터베이스 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 워크로드에 SQL Server 쿼리 저장소를 사용하는 모범 사례에 대해 설명합니다.
- 쿼리 저장소를 구성하고 관리하는 방법에 대한 자세한 내용은 쿼리 저장소를 사용하여 성능 모니터링을 참조하세요.
- 실행 가능한 정보를 검색하고 쿼리 저장소 사용하여 성능을 조정하는 방법에 대한 자세한 내용은 쿼리 저장소를 사용하여 성능 조정을 참조하세요.
- Azure SQL 데이터베이스에서 쿼리 저장소를 운영하는 방법에 대한 자세한 내용은 Azure SQL 데이터베이스에서 쿼리 저장소 운영을 참조하세요.
- Azure Synapse Analytics에서 쿼리 저장소는 전용 SQL 풀에 대해 기본적으로 사용하도록 설정되지 않지만 사용하도록 설정할 수 있습니다. 쿼리 저장소 대한 추가 구성 옵션은 지원되지 않습니다. 자세한 내용은 Azure Synapse Analytics의 기록 쿼리 저장소 및 분석을 참조하세요.
최신 SQL Server Management Studio 사용
SQL Server Management Studio에는 쿼리 저장소를 구성하고 워크로드에 대한 수집된 데이터를 사용하기 위해 설계된 사용자 인터페이스 세트가 있습니다. 최신 버전의 SQL Server Management Studio 다운로드
문제 해결 시나리오에서 쿼리 저장소를 사용하는 방법에 대한 간략한 설명은 Query Store Azure blogs를 참조하세요.
Azure SQL 데이터베이스의 쿼리 성능 Insight 사용
Azure SQL 데이터베이스에서 쿼리 저장소를 실행하는 경우 쿼리 성능 Insight를 사용하여 시간에 따른 리소스 사용량을 분석할 수 있습니다. Management Studio 및 Azure Data Studio를 사용하여 CPU, 메모리, I/O 등 모든 쿼리의 자세한 리소스 사용 정보를 가져올 수 있으며 Query Performance Insight를 사용하면 이와 같은 쿼리가 데이터베이스의 전반적인 DTU 사용에 미치는 영향을 빠르고 효율적으로 확인할 수 있습니다. 자세한 내용은 Azure SQL 데이터베이스 쿼리 성능 Insight를 참조하세요.
탄력적 풀 데이터베이스와 쿼리 저장소 사용
조밀하게 압축된 Azure SQL 데이터베이스 Elastic Pool에서도 모든 데이터베이스에서 쿼리 저장소를 사용할 수 있습니다. Elastic Pool의 많은 수의 데이터베이스에 대해 쿼리 저장소를 사용하도록 설정했을 때 발생할 수 있는 과도한 자원 배정 현황과 관련된 이전의 모든 문제가 해결되었습니다.
쿼리 성능 문제 해결 시작
다음 다이어그램에 표시된 대로 쿼리 저장소의 워크플로 문제는 간단히 해결됩니다.

이전 섹션에서 설명한 대로 Management Studio를 통해 쿼리 저장소를 사용하도록 설정하거나, 다음 Transact-SQL 문을 실행합니다.
ALTER DATABASE [DatabaseOne] SET QUERY_STORE = ON;
쿼리 저장소가 워크로드를 정확하게 나타내는 데이터 집합을 수집할 때까지 시간이 걸립니다. 일반적으로 매우 복잡한 워크로드에도 하루면 충분합니다. 그러나 데이터 탐색을 시작하고 기능을 사용하도록 설정한 직후 주의가 필요한 쿼리를 식별할 수 있습니다. Management Studio의 개체 탐색기에 데이터베이스 노드 아래의 쿼리 저장소 하위 폴더로 이동하여 특정 시나리오에 대한 문제 해결 보기를 엽니다.
Management Studio 쿼리 저장소 보기는 각각 다음 통계 함수 중 하나로 표현되는 실행 메트릭 세트로 작동합니다.
| SQL Server 버전 | 실행 메트릭 | 통계 함수 |
|---|---|---|
| SQL Server 2016(13.x) | CPU 시간, 기간, 실행 횟수, 논리 읽기, 논리 쓰기, 메모리 사용량, 실제 읽기, CLR 시간, DOP(병렬 처리 수준) 및 행 수 | 평균, 최대, 최소, 표준 편차, 합계 |
| SQL Server 2017(14.x) | CPU 시간, 기간, 실행 횟수, 논리 읽기, 논리 쓰기, 메모리 사용량, 실제 읽기, CLR 시간, 병렬 처리 수준, 행 수, 로그 메모리, TempDB 메모리 및 대기 시간 | 평균, 최대, 최소, 표준 편차, 합계 |
다음 그래픽에서는 쿼리 저장소 보기를 찾는 방법을 보여줍니다.

다음 테이블에서는 각 쿼리 저장소 보기를 사용하는 시기를 설명합니다.
| SQL Server Management Studio 보기 | 시나리오 |
|---|---|
| 회귀된 쿼리 | 최근에 실행 메트릭이 재발(예: 악화로 변경)된 쿼리를 정확히 파악합니다. 애플리케이션에서 관찰된 성능 문제와 수정하거나 개선해야 할 실제 쿼리의 상관 관계를 지정하려면 이 보기를 사용합니다. |
| 전체 리소스 사용량 | 실행 메트릭 중 하나에 대한 데이터베이스의 리소스 사용량 합계를 분석합니다. 이 보기를 사용하여 리소스 패턴(일별 워크로드 및 야간 워크로드)을 식별하고 데이터베이스의 전체 사용량을 최적화합니다. |
| 리소스 사용량 상위 쿼리 | 관심 있는 메트릭 실행을 선택하고 제공된 시간 간격 동안 가장 값이 높은 쿼리를 확인합니다. 이 뷰를 사용하여 데이터베이스 리소스 사용에 가장 큰 영향을 미치는 관련성이 가장 높은 쿼리에 집중할 수 있습니다. |
| 강제 계획이 포함된 쿼리 | 쿼리 저장소를 사용하여 이전 강제 계획을 나열합니다. 모든 현재 강제 계획에 빠르게 액세스하려면 이 보기를 사용합니다. |
| 고변형 쿼리 | 원하는 시간 간격으로 기간, CPU 시간, IO 및 메모리 사용과 같은 사용 가능한 차원과 관련되므로 높은 실행 변형을 사용하여 쿼리를 분석합니다. 이 보기를 사용하여 애플리케이션 전체의 사용자 환경에 영향을 미칠 수 있는 광범위한 변형 성능으로 쿼리를 식별합니다. |
| 쿼리 대기 통계 | 데이터베이스에서 가장 많이 사용되는 대기 범주는 무엇이고 선택한 대기 범주에 가장 많은 영향을 주는 쿼리는 무엇인지 분석합니다. 이 보기를 사용하여 대기 통계를 분석하고 애플리케이션 전체의 사용자 환경에 영향을 미칠 수 있는 쿼리를 식별합니다. 적용 대상: SQL Server Management Studio v18.0 및 SQL Server 2017(14.x)부터 |
| 추적된 쿼리 | 가장 중요한 쿼리의 실행을 실시간으로 추적합니다. 일반적으로 강제 계획이 있는 쿼리가 있고 쿼리 성능이 안정적인지 확인하려는 경우 이 보기를 사용합니다. |
팁
Management Studio를 사용하여 리소스를 가장 많이 사용하는 쿼리를 확인하고, 선택한 계획을 변경하여 재발된 쿼리를 수정하는 방법은 Query Store Azure Blogs를 참조하세요.
최적 상태가 아닌 성능의 쿼리를 식별한 경우 수행할 작업은 문제의 성격에 따라 다릅니다.
- 쿼리가 여러 계획으로 실행되고 마지막 계획이 이전 계획보다 훨씬 나쁜 경우 계획 적용 메커니즘을 사용하여 이를 강제할 수 있습니다. SQL Server는 최적화 프로그램에서 계획을 적용하려고 합니다. 계획을 적용하는 데 실패하면 XEvent가 발생하고, 최적화 프로그램이 일반적인 방법으로 최적화하도록 지시됩니다.
참고 항목
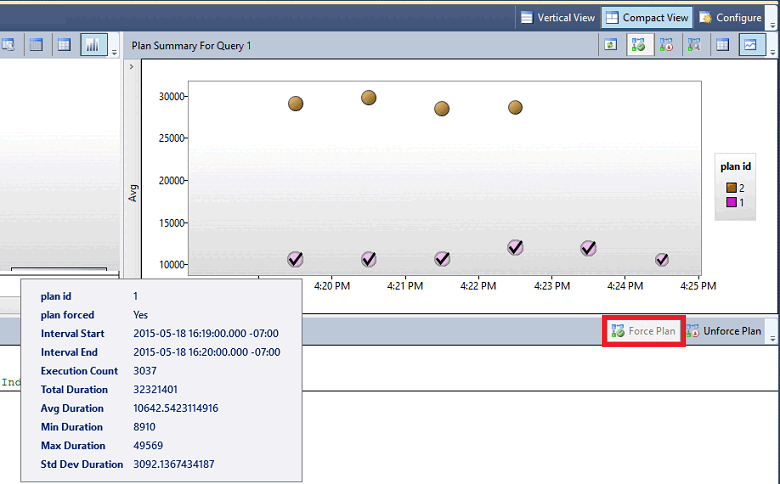
이전의 그래픽에서 특정 쿼리 계획에 따라 다른 모양으로 표시될 수 있으며, 가능한 각 상태의 의미는 다음과 같습니다.
| 도형 | 의미 |
|---|---|
| 원 | 쿼리가 완료되었습니다. 즉, 정규 실행이 성공적으로 완료되었습니다. |
| Square | 취소되었습니다. 즉, 클라이언트가 시작한 실행이 중단되었습니다. |
| 삼각형 | 실패(예외로 실행이 중단됨) |
또한 셰이프 크기는 지정된 시간 간격 내의 쿼리 실행 횟수를 나타냅니다. 실행 수가 많을수록 크기가 증가합니다.
- 쿼리에 최적의 실행을 위한 인덱스가 누락된 것으로 결론을 내릴 수 있습니다. 이 정보는 쿼리 실행 계획 내에 표시됩니다. 누락된 인덱스를 만들고 쿼리 저장소를 사용하여 쿼리 성능을 확인합니다.

SQL Database에서 워크로드를 실행하는 경우 SQL Database Index Advisor에 가입하여 인덱스 권장 사항을 자동으로 수신합니다.
- 경우에 따라 실행 계획의 예상 행 수와 실제 행 수 간의 차이가 중요한 경우 통계 다시 컴파일을 적용할 수 있습니다.
- 예를 들어 쿼리 매개 변수화를이용하거나 최적의 논리를 구현하기 위해 문제가 있는 쿼리를 다시 작성합니다.
팁
Azure SQL 데이터베이스에서는 코드를 변경하지 않고 쿼리에서 쿼리 힌트를 적용하기 위해 쿼리 저장소 힌트 기능을 고려합니다. 자세한 내용 및 예제는 쿼리 저장소 힌트를 참조하세요.
쿼리 저장소에서 쿼리 데이터가 계속 수집되는지 확인
쿼리 저장소에서 작동 모드가 자동으로 변경될 수 있습니다. 쿼리 저장소의 상태를 정기적으로 모니터링하여 쿼리 저장소가 작동 중인지 확인하고, 예방 가능한 원인으로 인해 오류가 발생하지 않도록 조치를 취합니다. 다음 쿼리를 실행하여 작동 모드를 확인하고 가장 관련성이 큰 매개 변수를 확인합니다.
USE [QueryStoreDB];
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
actual_state_desc 및 desired_state_desc 간 차이는 작업 모드 변경이 자동으로 발생했음을 나타냅니다. 가장 일반적인 변경 내용은 쿼리 저장소를 자동으로 읽기 전용 모드로 전환하는 것입니다. 아주 드물긴 하지만, 내부 오류로 인해 쿼리 저장소가 오류 상태로 종료될 수도 있습니다.
실제 상태가 읽기 전용인 경우 readonly_reason 열을 사용하여 근본 원인을 확인합니다. 일반적으로 크기 할당량 초과로 인해 쿼리 저장소가 읽기 전용 모드로 전환되었음을 알 수 있습니다. 이 경우 readonly_reason이 65536으로 설정됩니다. 다른 이유를 보려면 sys.database_query_store_options(Transact-SQL)를 참조하세요.
쿼리 저장소를 읽기/쓰기 모드로 전환하고 데이터 컬렉션을 활성화하려면 다음 단계를 고려하세요.
ALTER DATABASE의MAX_STORAGE_SIZE_MB옵션을 사용하여 최대 스토리지 크기를 늘립니다.다음 문을 사용하여 쿼리 저장소 데이터를 정리합니다.
ALTER DATABASE [QueryStoreDB] SET QUERY_STORE CLEAR;
명시적으로 작업 모드를 읽기/쓰기로 변경하는 다음 문을 실행하여 위 단계 중 하나 또는 모두를 적용할 수 있습니다.
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
사전 대응하려면 다음 단계를 수행합니다.
- 모범 사례를 적용하여 작동 모드의 자동 변경을 방지할 수 있습니다. 쿼리 저장소 크기가 항상 최대 허용 값보다 낮아 읽기 전용 모드로 전환할 가능성을 크게 줄여야 합니다. 크기가 제한에 가까워지면 쿼리 저장소가 자동으로 데이터를 정리할 수 있도록 쿼리 저장소 구성 섹션에 설명된 대로 크기 기반 정책을 활성화합니다.
- 가장 최근 데이터가 보존되도록 하려면 오래된 정보를 정기적으로 제거하도록 시간 기반 정책을 구성합니다.
- 마지막으로 쿼리 저장소 캡처 모드를 Auto로 설정하는 것이 좋습니다. 이렇게 하면 주로 워크로드와 관련성이 낮은 쿼리가 필터링하여 제외됩니다.
ERROR 상태
쿼리 저장소 복구하려면 읽기/쓰기 모드를 명시적으로 설정하고 실제 상태를 다시 확인합니다.
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
문제가 지속되면 쿼리 저장소 데이터의 손상이 디스크에서 지속되고 있음을 나타냅니다.
SQL Server 2017(14.x)부터 영향을 받는 데이터베이스 내에서 sys.sp_query_store_consistency_check 저장 프로시저를 실행하여 쿼리 저장소 복구할 수 있습니다. 복구 작업을 시도하기 전에 쿼리 저장소를 사용하지 않도록 설정해야 합니다. QDS의 일관성 검사 및 복구를 수행하기 위해 사용하거나 수정할 샘플 쿼리는 다음과 같습니다.
IF EXISTS (SELECT * FROM sys.database_query_store_options WHERE actual_state=3)
BEGIN
BEGIN TRY
ALTER DATABASE [QDS] SET QUERY_STORE = OFF
Exec [QDS].dbo.sp_query_store_consistency_check
ALTER DATABASE [QDS] SET QUERY_STORE = ON
ALTER DATABASE [QDS] SET QUERY_STORE (OPERATION_MODE = READ_WRITE)
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_SEVERITY() AS ErrorSeverity
,ERROR_STATE() AS ErrorState
,ERROR_PROCEDURE() AS ErrorProcedure
,ERROR_LINE() AS ErrorLine
,ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
END
SQL Server 2016(13.x)의 경우 표시된 바와 같이 쿼리 저장소에서 데이터를 정리해야 합니다.
복구에 실패한 경우 읽기/쓰기 모드를 설정하기 전에 쿼리 저장소 지울 수 있습니다.
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE CLEAR;
GO
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
매개 변수화되지 않은 쿼리 사용 방지
필요하지 않은 경우 매개 변수가 없는 쿼리를 사용하는 것이 모범 사례는 아닙니다. 예는 임시 분석의 경우입니다. 쿼리 최적화 프로그램에서 고유한 쿼리 텍스트 모두에 대해 쿼리를 컴파일하도록 강제로 캐시된 계획은 다시 사용할 수 없습니다. 자세한 내용은 강제 매개 변수화 사용 지침을 참조하세요.
또한 쿼리 저장소는 잠재적으로 많은 수의 다른 쿼리 텍스트로 인해 크기 할당량을 빠르게 초과할 수 있으며, 따라서 셰이프가 비슷한 다양한 실행 계획이 많습니다. 따라서 워크로드 성능이 최적이 아닌 상태가 되고 쿼리 저장소가 읽기 전용 모드로 전환되거나 들어오는 쿼리 속도에 맞춰 데이터를 계속 삭제해야 할 수 있습니다.
다음 옵션을 살펴보세요.
- 해당하는 경우 쿼리를 매개 변수화합니다. 예를 들어, 저장 프로시저 또는
sp_executesql내부에 쿼리를 래핑합니다. 자세한 내용은 매개 변수 및 실행 계획 재사용을 참조하세요. - 워크로드에 다른 쿼리 계획이 있는 일회용 임시 일괄 처리가 많이 포함된 경우 임시 작업을 위해 최적화 옵션을 사용합니다.
- 고유 query_hash 값의 수를
sys.query_store_query의 항목 수 합계와 비교합니다. 비율이 1에 가까우면 임시 워크로드가 다른 쿼리를 생성합니다.
- 고유 query_hash 값의 수를
- 다른 쿼리 계획의 수가 크지 않은 경우 데이터베이스 또는 쿼리 하위 집합에 대해 강제 매개 변수화를 적용합니다.
- 선택한 쿼리에 대해서만 매개 변수화를 강제로 적용하려면 계획 지침을 사용합니다.
- 워크로드에 여러 쿼리 계획이 적은 경우 매개 변수화 데이터베이스 옵션 명령을 사용하여 강제 매개 변수화를 구성합니다. 예를 들어
sys.query_store_query의 고유 query_hash 개수와 항목 수 합계 사이의 비율이 1보다 훨씬 작은 경우입니다.
QUERY_CAPTURE_MODE를AUTO로 설정하여 리소스 사용량이 작은 임시 쿼리를 자동으로 필터링하여 제외합니다.
팁
EF(Entity Framework)와 같은 ORM(개체 관계형 매핑) 솔루션 사용 시, 수동 LINQ 쿼리 트리 또는 특정 원시 SQL 쿼리 같은 애플리케이션 쿼리는 매개 변수화되지 않을 수도 있습니다. 이로 인해 플랜 재사용 및 쿼리 저장소에서 쿼리를 추적하는 능력이 영향을 받게 됩니다. 자세한 내용은 EF 쿼리 캐싱 및 매개 변수화 및 EF 원시 SQL 쿼리를 참조하세요.
쿼리 저장소 매개 변수가 없는 쿼리 찾기
아래 쿼리, 쿼리 저장소 DMV, SQL Server, Azure SQL Managed Instance 또는 Azure SQL Database를 사용하여 쿼리 저장소에 저장된 계획 수를 찾을 수 있습니다.
SELECT count(Pl.plan_id) AS plan_count, Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
FROM sys.query_store_plan AS Pl
INNER JOIN sys.query_store_query AS Qry
ON Pl.query_id = Qry.query_id
INNER JOIN sys.query_store_query_text AS Txt
ON Qry.query_text_id = Txt.query_text_id
GROUP BY Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
ORDER BY plan_count desc;
다음 샘플에서는 쿼리 리소스 소비를 진단하는 데 유용할 수 있는 query_store_db_diagnostics 이벤트를 캡처하는 확장 이벤트 세션을 만듭니다. SQL Server에서 이 확장 이벤트 세션은 기본적으로 SQL Server 로그 폴더에 이벤트 파일을 만듭니다. 예를 들어 Windows에 기본 SQL Server 2019(15.x) 설치하는 경우 이벤트 파일(.xel 파일)을 C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\Log 폴더에 만들어야 합니다. Azure SQL Managed Instance 대신 Azure Blob Storage 위치를 지정합니다. 자세한 내용은 Azure SQL Managed Instance용 XEvent event_file을 참조하세요. ‘qds.query_store_db_diagnostics’ 이벤트는 Azure SQL Database에 사용할 수 없습니다.
CREATE EVENT SESSION [QueryStore_Troubleshoot] ON SERVER
ADD EVENT qds.query_store_db_diagnostics(
ACTION(sqlos.system_thread_id,sqlos.task_address,sqlos.task_time,sqlserver.database_id,sqlserver.database_name))
ADD TARGET package0.event_file(SET filename=N'QueryStore',max_file_size=(100))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF);
이 데이터를 사용하면 쿼리 저장소 계획 수와 다른 많은 통계도 찾을 수 있습니다. 사용된 메모리 양과 쿼리 저장소에서 추적되는 계획의 수를 이해하기 위해 이벤트 데이터의 plan_count, query_count, max_stmt_hash_map_size_kb 및 max_size_mb 열을 찾습니다. 계획 수가 정상보다 많은 경우 매개 변수가 없는 쿼리가 증가했음을 나타낼 수 있습니다. 아래 쿼리 저장소 DMV 쿼리를 사용하여 쿼리 저장소 매개 변수가 있는 쿼리 및 매개 변수가 없는 쿼리를 검토합니다.
매개 변수가 있는 쿼리의 경우:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE qsq.query_parameterization_type<>0 or qsqt.query_sql_text like '%@%';
매개 변수가 없는 쿼리의 경우:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE query_parameterization_type=0;
개체를 포함하기 위한 DROP 또는 CREATE 패턴 방지
쿼리 저장소는 쿼리 항목을 저장 프로시저, 함수 및 트리거와 같은 포함하는 개체와 연결합니다. 포함하는 개체를 다시 만들면 동일한 쿼리 텍스트에 대한 새 쿼리 항목이 생성됩니다. 이 때문에 시간에 따른 해당 쿼리의 성능 통계 추적과 계획 강제 적용 메커니즘을 사용할 수 없게 됩니다. 이 상황을 방지하려면 가능할 때마다 ALTER <object> 프로세스를 사용하여 포함하는 개체 정의를 변경합니다.
정기적으로 강제 계획의 상태 확인
계획 강제 적용은 중요한 쿼리의 성능을 수정하고 보다 예측 가능하게 만드는 편리한 메커니즘입니다. 계획 힌트 및 계획 지침과 마찬가지로 계획 강제 적용은 향후 실행에 사용될 것이라는 보장이 아닙니다. 일반적으로 실행 계획에서 참조하는 개체가 변경되거나 삭제되는 방식으로 데이터베이스 스키마가 변경하는 경우 강제 계획이 실패하기 시작합니다. 이 경우 실제 강제 실패 이유가 sys.query_store_plan에 표시되는 동안 SQL Server는 쿼리 다시 컴파일로 대체됩니다. 다음 쿼리는 강제 계획에 대한 정보를 반환합니다.
USE [QueryStoreDB];
GO
SELECT p.plan_id, p.query_id, q.object_id as containing_object_id,
force_failure_count, last_force_failure_reason_desc
FROM sys.query_store_plan AS p
JOIN sys.query_store_query AS q on p.query_id = q.query_id
WHERE is_forced_plan = 1;
전체 이유 목록은 sys.query_store_plan을 참조하세요. query_store_plan_forcing_failed XEvent를 사용하여 플랜 강제 오류를 추적하고 문제를 해결할 수 있습니다.
팁
Azure SQL 데이터베이스에서는 코드를 변경하지 않고 쿼리에서 쿼리 힌트를 적용하기 위해 쿼리 저장소 힌트 기능을 고려합니다. 자세한 내용 및 예제는 쿼리 저장소 힌트를 참조하세요.
강제 계획이 있는 쿼리의 데이터베이스 이름 바꾸기 방지
실행 계획은 database.schema.object와 같은 세 부분으로 구성된 이름을 사용하여 개체를 참조합니다.
데이터베이스 이름을 바꾸면 계획 강제 실행이 실패하여 모든 후속 쿼리 실행에서 다시 컴파일됩니다.
중요 업무용 서버에서 쿼리 저장소 사용
전역 추적 플래그 7745 및 7752를 사용하여 쿼리 저장소를 사용하는 데이터베이스의 사용 가능성을 개선할 수 있습니다. 자세한 내용은 추적 플래그를 참조하세요.
- SQL Server를 종료하기 전에 추적 플래그 7745는 쿼리 저장소에서 데이터를 디스크에 기록하는 기본 동작을 방지할 수 있습니다. 즉, 수집되었지만 디스크에 아직 유지되지 않은 쿼리 저장소 데이터는
DATA_FLUSH_INTERVAL_SECONDS로 정의된 기간까지 손실됩니다. - 추적 플래그 7752는 쿼리 저장소의 비동기 로드를 사용하도록 설정합니다. 이 설정을 통해 쿼리 저장소가 완전히 복구되기 전에 데이터베이스가 온라인 상태로 전환되고 쿼리를 실행할 수 있습니다. 기본 동작은 쿼리 저장소의 동기 로드를 수행하는 것입니다. 이 기본 동작은 쿼리 저장소가 복구되기 전에 쿼리가 실행되지 않도록 방지할 뿐 아니라 데이터 수집에서 쿼리가 누락되지 않도록 방지합니다.
참고 항목
SQL Server 2019(15.x)부터 이 동작은 엔진에서 제어되며, 7752 추적 플래그는 아무 효과가 없습니다.
Important
SQL Server 2016(13.x)에서 Just-In-Time 워크로드 인사이트를 위해 쿼리 저장소를 사용하는 경우, 최대한 빨리 SQL Server 2016(13.x) SP2 CU2(KB 4340759)의 성능 확장성 기능 향상을 설치하세요. 이러한 개선이 없으면 데이터베이스에 워크로드가 많은 경우 스핀 잠금 경합이 발생하고 서버 성능이 느려질 수 있습니다. 특히 QUERY_STORE_ASYNC_PERSIST 스핀 잠금 또는 SPL_QUERY_STORE_STATS_COOKIE_CACHE 스핀 잠금에서 경합이 심할 수 있습니다. 이 개선이 적용되면 쿼리 저장소에서 더 이상 스핀 잠금 경합을 일으키지 않습니다.
Important
SQL Server(SQL Server 2016(13.x)에서 SQL Server 2017(14.x)까지)의 Just-In-Time 워크로드 인사이트에 쿼리 저장소를 사용하는 경우 가능한 한 빨리 SQL Server 2016(13.x) SP2 CU15, SQL Server 2017(14.x) CU23 및 SQL Server 2019(15.x) CU9에 성능 확장성 향상을 설치할 계획입니다. 이러한 기능 향상을 사용하지 않으면 데이터베이스의 사용량이 많은 경우에는 쿼리 저장소에서 많은 양의 메모리를 사용할 수 있으며 서버 성능이 저하될 수 있습니다. 이 개선 사항이 적용되면 쿼리 저장소는 다양한 구성 요소가 사용할 수 있는 메모리 양에 내부 제한을 적용하고 충분한 메모리가 데이터베이스 엔진에 반환될 때까지 작동 모드를 읽기 전용으로 자동 변경할 수 있습니다. 쿼리 저장소 내부 메모리 제한은 변경될 수 있으므로 문서화되지 않습니다.
Azure SQL 데이터베이스 활성 지역 복제에서 쿼리 저장소 사용
Azure SQL 데이터베이스의 보조 지역 복제본에서 쿼리 저장소는 주 복제본 작업의 읽기 전용 복사본이 됩니다.
Azure SQL 데이터베이스 지역에서 복제와 계층이 일치하지 않도록 합니다. 보조 데이터베이스는 주 데이터베이스와 동일한 컴퓨팅 크기 및 주 데이터베이스의 동일한 서비스 계층에 있어야 합니다. 보조 지연 시간으로 인해 주 복제본에서 트랜잭션 로그 속도 제한을 나타내는 sys.dm_db_wait_stats의 HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO 대기 유형을 찾습니다.
활성 지역 복제의 보조 Azure SQL 데이터베이스 크기를 예측하고 구성하는 방법에 대한 자세한 내용은 보조 데이터베이스 구성을 참조하세요.
워크로드에 맞게 조정된 쿼리 저장소 유지
쿼리 저장소를 구성하고 관리하기 위한 모범 사례 및 권장 사항은 이 문서의 쿼리 저장소를 관리하기 위한 모범 사례에서 확장되었습니다.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기