적용 대상:![]() SQL 서버
SQL 서버![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() 분석 플랫폼 시스템(PDW)
분석 플랫폼 시스템(PDW)![]() Microsoft Fabric의 SQL 데이터베이스
Microsoft Fabric의 SQL 데이터베이스
SQL Server는 조인을 사용하여 여러 테이블 간의 논리적 관계를 기반으로 여러 테이블에서 데이터를 검색합니다. 조인은 관계형 데이터베이스 작업의 기본 사항이며 두 개 이상의 테이블의 데이터를 단일 결과 집합으로 결합할 수 있습니다.
SQL Server는 논리 조인 작업(Transact-SQL 구문으로 정의됨)과 실제 조인 작업(조인을 실행하는 데 사용되는 실제 알고리즘)을 모두 구현합니다. 두 측면을 모두 이해하면 효율적인 쿼리를 작성하고 데이터베이스 성능을 최적화할 수 있습니다.
논리적 조인 작업에는 다음이 포함됩니다.
- 내부 조인
- 왼쪽, 오른쪽 및 전체 외부 조인
- 교차 조인
물리적 조인 작업에는 다음이 포함됩니다.
- 중첩 루프 조인
- 병합 조인
- 해시 조인
- 적응 조인(적용 대상: SQL Server 2017(14.x) 이상 버전)
이 문서에서는 조인의 작동 방식, 다양한 조인 형식을 사용하는 시기 및 쿼리 최적화 프로그램에서 테이블 크기, 사용 가능한 인덱스 및 데이터 분포와 같은 요인에 따라 가장 효율적인 조인 알고리즘을 선택하는 방법을 설명합니다.
Note
조인 구문에 대한 자세한 내용은 FROM 절과 JOIN, APPLY, PIVOT을 참조하세요.
조인 기본 사항
조인을 사용하면 테이블 간의 논리적 관계를 기준으로 둘 이상의 테이블에서 데이터를 검색할 수 있습니다. 조인은 SQL Server가 한 테이블의 데이터를 사용하여 다른 테이블의 행을 선택하는 방법을 나타냅니다.
조인 조건은 다음과 같이 쿼리에서 두 테이블의 관계를 정의합니다.
- 조인에 사용될 각 테이블에서 열을 지정합니다. 일반적인 조인 조건은 한 테이블의 외래 키를 지정하고 다른 테이블의 연결된 키를 지정합니다.
- 열의 값을 비교하는 데 사용할 논리 연산자(예: = 또는 <>)를 지정합니다.
조인은 논리적으로 다음 Transact-SQL 구문을 사용하여 표현됩니다.
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
내부 조인은 FROM 또는 WHERE 절에서 지정할 수 있습니다.
외부 조인 및 교차 조인은 FROM 절에만 지정할 수 있습니다. 조인 조건은 WHERE 절에서 참조되는 기본 테이블에서 선택한 행을 제어하기 위해 HAVING 및 FROM 검색 조건과 결합됩니다 .
FROM 절에 조인 조건을 지정하면 WHERE 절에 지정할 수 있는 다른 검색 조건과 구분하기 쉬우므로 적합한 조인 지정 방법입니다. 간단한 ISO FROM 절의 조인 구문은 다음과 같습니다.
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- join_type은 수행되는 조인 종류(내부, 외부 또는 교차 조인)를 지정합니다. 다양한 유형의 조인에 대한 설명은 FROM 절을 참조하세요.
- join_condition은 조인된 행의 각 쌍에 대해 평가할 조건자를 정의합니다.
다음 코드는 FROM 절 조인 사양의 예제입니다.
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
다음 코드는 위의 조인을 사용하는 간단한 SELECT 문입니다.
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
SELECT 문은 회사 이름이 문자 F로 시작하고 제품 가격이 10달러 이상인 회사에서 제공하는 부품의 조합에 대한 제품 및 공급업체 정보를 반환합니다.
단일 쿼리에서 여러 테이블을 참조하는 경우 모든 열 참조는 명확해야 합니다. 이전 예제에서 ProductVendor 및 Vendor 테이블에는 이름이 BusinessEntityID인 열이 있습니다. 쿼리에서 참조되는 두 개 이상의 테이블 간에 중복되는 열 이름은 테이블 이름으로 한정되어야 합니다. 예제의 Vendor 열에 대한 모든 참조는 정규화됩니다.
쿼리에 사용되는 두 개 이상의 테이블에서 열 이름이 중복되지 않는 경우 열에 대한 참조를 테이블 이름으로 정규화할 필요가 없습니다. 위의 예에도 이러한 열이 포함되어 있습니다.
SELECT 이러한 절은 각 열을 제공한 테이블을 나타내는 것이 없기 때문에 이해하기 어려운 경우가 있습니다. 모든 열이 테이블 이름으로 한정된 경우 쿼리의 가독성이 향상됩니다. 테이블 별칭을 사용하면 가독성이 더욱 향상되며 특히 테이블 이름을 데이터베이스 이름과 소유자 이름으로 한정해야 할 경우 그러합니다. 다음 코드는 테이블 별칭이 할당되고 가독성을 높이기 위해 테이블 별칭으로 한정된 열을 제외하고 동일한 예제입니다.
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
이전 예제에서는 FROM 절에 조인 조건을 지정했는데, 이 조건이 기본 설정 메서드입니다. 다음은 동일한 조인 조건을 WHERE 절에 지정한 쿼리입니다.
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
조인의 SELECT 목록은 조인된 테이블의 모든 열 또는 열의 하위 집합을 참조할 수 있습니다. 목록은 SELECT 조인의 모든 테이블의 열을 포함할 필요가 없습니다. 예를 들어 3개의 테이블로 이루어진 조인에서는 다른 테이블 중 하나에서 세 번째 테이블로 연결하는 데 하나의 테이블만 사용할 수 있으며 가운데 테이블의 열을 선택 목록에서 참조할 필요가 없습니다. 이를 안티 세미 조인이라고도합니다.
조인 조건에는 일반적으로 같음 연산자(=)를 사용하지만 다른 조건자처럼 기타 비교 연산자나 관계 연산자를 지정할 수 있습니다. 자세한 내용은 비교 연산자 및 WHERE를 참조하세요.
SQL Server에서 조인을 처리할 때 쿼리 최적화 프로그램은 여러 가지 가능한 방법 중 가장 효율적인 방법을 선택합니다. 여기에는 가장 효율적인 형식의 물리적 조인 선택, 테이블이 조인되는 순서, 세미 조인 및 세미 조인 방지와 같은 Transact-SQL 구문으로 직접 표현할 수 없는 논리 조 인 작업 형식을 사용하는 것도 포함됩니다. 다양한 조인의 물리적 실행은 다양한 최적화를 사용할 수 있으므로 안정적으로 예측할 수 없습니다. 세미 조인 및 세미 조인 방지에 대한 자세한 내용은 논리 및 물리적 실행 계획 연산자 참조를 참조하세요.
조인 조건에서 사용되는 열은 이름이 같거나 데이터 형식이 같을 필요가 없습니다. 그러나 데이터 형식이 동일하지 않은 경우 호환되거나 SQL Server에서 암시적으로 변환할 수 있는 형식이어야 합니다. 데이터 형식을 암시적으로 변환할 수 없는 경우 조인 조건은 함수를 사용하여 CAST 데이터 형식을 명시적으로 변환해야 합니다. 암시적 및 명시적 변환에 대한 자세한 내용은 데이터 형식 변환(데이터베이스 엔진)을 참조하세요.
조인을 사용하는 대부분의 쿼리는 하위 쿼리(다른 쿼리 내에 중첩된 쿼리)를 사용하여 다시 작성할 수 있으며 대부분의 하위 쿼리는 조인으로 다시 작성할 수 있습니다. 하위 쿼리에 대한 자세한 내용은 하위 쿼리(SQL Server)를 참조하세요.
Note
테이블은 ntext, 텍스트 또는 이미지 열에서 직접 조인할 수 없습니다. 하지만 SUBSTRING을 사용하여 ntext, text 또는 image 열에 간접적으로 테이블을 조인할 수 있습니다.
예를 들어 SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20)은 t1 및 t2 테이블에서 각 텍스트 열의 처음 20자에서 2개의 테이블 내부 조인을 수행합니다.
또한 두 테이블의 ntext 또는 텍스트 열을 비교할 수 있는 또 다른 가능성은 열의 길이를 WHERE 절과 비교하는 것입니다. 예를 들면 WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)와 같습니다.
중첩 루프 조인 이해
한 조인 입력이 작거나(행이 10개 미만) 다른 조인 입력이 상당히 크고 조인 열에서 인덱싱되는 경우, 인덱스 중첩 루프 조인은 최소 I/O 및 가장 적은 비교가 필요하기 때문에 가장 빠른 조인 작업입니다.
중첩 반복이라고도 하는 중첩 루프 조인은 조인 입력 한 개를 외부 입력 테이블(그래픽 실행 계획에서 최상위 입력으로 표시됨)로 사용하고 한 개는 내부(최하위) 입력 테이블로 사용합니다. 외부 루프는 외부 입력 테이블에서 한 번에 한 행씩 입력받아 처리합니다. 각 외부 행에 대해 실행되는 내부 루프는 외부 테이블의 행과 일치하는 내부 입력 테이블의 행을 검색합니다.
가장 간단한 경우 검색은 전체 테이블 또는 인덱스를 검색합니다. 이를 단순한 중첩 루프 조인이라고 합니다. 검색이 인덱스를 악용하는 경우 인 덱스 중첩 루프 조인이라고 합니다. 인덱스가 쿼리 계획의 일부로 빌드되고 쿼리가 완료될 때 제거되는 경우 임시 인덱스 중첩 루프 조인이라고 합니다. 이러한 모든 변형은 쿼리 최적화 프로그램에서 고려됩니다.
중첩 루프 조인은 외부 입력이 작고 내부 입력이 크고 미리 인덱스되는 경우에 특히 효과적입니다. 작은 행 집합에만 영향을 주는 트랜잭션과 같은 많은 작은 트랜잭션에서, 인덱스 중첩 루프 조인은 병합 조인과 해시 조인 모두보다 우수합니다. 하지만 대규모 쿼리에서는 중첩된 루프 조인이 최적의 옵션이 아닌 경우가 많습니다.
중첩 루프 조인 연산자의 OPTIMIZED 특성이 True로 설정된 경우, 병렬 처리 여부에 관계없이 내부 테이블이 클 때 최적화된 중첩 루프(또는 배치 정렬)를 사용하여 I/O를 최소화합니다. 정렬 자체가 숨겨진 작업임을 고려하면, 지정된 계획에서 이 최적화의 존재는 실행 계획을 분석할 때 아주 명백하지 않을 수 있습니다. 하지만 OPTIMIZED 특성에 대한 계획 XML을 살펴보면, 중첩 루프 조인이 입력 행의 순서를 다시 지정하여 I/O 성능을 높일 수 있음을 나타냅니다.
병합 조인
두 조인 입력이 작지는 않지만 조인 열에서 정렬된 경우(예: 정렬된 인덱스를 검사하여 가져온 경우) 병합 조인은 가장 빠른 조인 작업입니다. 두 조인 입력이 모두 크고 두 입력의 크기가 비슷한 경우, 이전 정렬과 해시 조인을 사용하는 병합 조인이 비슷한 성능을 제공합니다. 하지만 두 입력 크기가 서로 크게 다른 경우 해시 조인 작업이 훨씬 더 빠른 경우가 많습니다.
병합 조인을 사용하려면 병합 열에서 두 입력을 모두 정렬해야 하며 조인 조건자의 같음(ON) 절에 의해 정의됩니다. 쿼리 최적화 프로그램은 일반적으로 적절한 열 집합에 인덱스가 있거나 병합 조인 아래에 정렬 연산자를 배치하는 경우에 인덱스를 검색합니다. 간혹 여러 개의 등가 절이 있는 경우도 있지만 사용 가능한 등가 절에서만 병합 열을 가져옵니다.
각 입력이 정렬되므로 병합 조인 연산자는 각 입력에서 행을 가져오고 비교합니다. 예를 들어 내부 조인 작업의 경우 행이 서로 같으면 반환됩니다. 값이 같지 않으면 하위 값 행이 삭제되고 해당 입력에서 다른 행을 가져옵니다. 모든 행이 처리될 때까지 이 과정이 반복됩니다.
병합 조인 작업은 일반 또는 다대다 작업일 수 있습니다. 다대다 병합 조인은 임시 테이블을 사용하여 행을 저장합니다. 각 입력에서 중복 값이 있는 경우 다른 입력에서 중복된 각 항목이 처리될 때 입력 중 하나가 중복 항목의 시작으로 되감기해야 합니다.
잔여 조건자가 있는 경우 병합 조건자를 충족하는 모든 행은 잔여 조건자를 평가하고 이를 만족하는 행만 반환됩니다.
병합 조인 자체는 매우 빠르지만 정렬 작업이 필요한 경우 비용이 많이 들 수 있습니다. 하지만 데이터 볼륨이 크고 원하는 데이터를 기존 B-트리 인덱스에서 미리 정렬할 수 있는 경우 병합 조인이 사용 가능한 가장 빠른 조인 알고리즘인 경우가 많습니다.
해시 조인
해시 조인은 정렬되지 않고 인덱싱되지 않은 대규모 입력을 효율적으로 처리할 수 있습니다. 다음의 이유로, 복잡한 쿼리의 중간 결과에 유용합니다.
- 중간 결과는 인덱싱되지 않으며(디스크에 명시적으로 저장한 다음 인덱싱되지 않은 경우) 쿼리 계획의 다음 작업에 적합하게 정렬되지 않는 경우가 많습니다.
- 쿼리 최적화 프로그램은 중간 결과 크기만 예측합니다. 예측은 복잡한 쿼리에 대해 매우 부정확할 수 있으므로, 중간 결과를 처리하는 알고리즘은 효율적일 뿐만 아니라 중간 결과가 예상보다 훨씬 큰 것으로 판명될 경우 정상적으로 저하되어야 합니다.
해시 조인을 사용하면 비정규화 사용을 줄일 수 있습니다. 비정규화는 일관성 없는 업데이트와 같은 중복성의 위험에도 불구하고, 조인 작업을 줄여 성능을 높이는 데 일반적으로 사용됩니다. 해시 조인은 비정규화할 필요성을 줄입니다. 해시 조인을 사용하면 수직 분할(별도의 파일 또는 인덱스에 있는 단일 테이블의 열 그룹을 나타냄)이 실제 데이터베이스 디자인에 사용할 수 있는 옵션이 될 수 있습니다.
해시 조인에는 빌드 입력 및 프로브 입력 등 두 가지 입력이 있습니다. 쿼리 최적화 프로그램은 두 입력 중 작은 값이 빌드 입력이 되도록 이러한 역할을 할당합니다.
해시 조인은 내부 조인, 왼쪽, 오른쪽 및 전체 외부 조인, 왼쪽 및 오른쪽 세미 조인, 교차점, 합집합, 차이점 등 여러 유형의 집합 매칭 작업에 사용됩니다. 또한, 해시 조인의 변형은 중복 요소 제거 및 그룹화(예: SUM(salary) GROUP BY department)를 수행할 수 있습니다. 이러한 수정에서는 빌드 및 프로브 역할 모두에 하나의 입력만 사용합니다.
다음 섹션에서는 인-메모리 해시 조인, 유예 해시 조인 및 재귀 해시 조인 등 여러 해시 조인 유형을 설명합니다.
인-메모리 해시 조인
해시 조인은 먼저 전체 빌드 입력을 검사하거나 계산한 다음, 메모리에 해시 테이블을 빌드합니다. 각 행은 해시 키에 대해 계산된 해시 값에 따라 해시 버킷에 삽입됩니다. 전체 빌드 입력이 사용 가능한 메모리보다 작은 경우, 모든 행을 해시 테이블에 삽입할 수 있습니다. 이 빌드 단계 다음에 프로브 단계가 수행됩니다. 전체 프로브 입력은 한 번에 한 행씩 검색되거나 계산되며, 각 프로브 행에 대해 해시 키의 값이 계산되고, 해당 해시 버킷이 검색되고, 일치 항목이 생성됩니다.
유예 해시 조인
빌드 입력이 메모리에 맞지 않으면 해시 조인이 여러 단계로 진행됩니다. 이를 유예 해시 조인이라고 합니다. 각 단계마다 빌드 단계와 검색 단계가 있습니다. 처음에는 전체 빌드 및 검색 입력이 사용되며 해시 키에 대한 해시 함수를 사용하여 여러 파일로 분할됩니다. 해시 키에 대한 해시 함수를 사용하면 2개의 조인 레코드가 모두 동일한 파일 쌍에 있는 것이 보장됩니다. 따라서 두 개의 큰 입력을 조인하는 작업이 동일한 작업의 더 작은 여러 인스턴스로 축소되었습니다. 그런 다음 해시 조인이 분할된 각 파일 쌍에 적용됩니다.
재귀 해시 조인
빌드 입력이 너무 커서 표준 외부 병합에 대한 입력에 여러 개의 병합 수준이 필요한 경우에는 여러 개의 분할 단계와 여러 개의 분할 수준이 요구됩니다. 일부 파티션만 큰 경우에는 해당 파티션에서만 추가 분할 단계가 사용됩니다. 모든 분할 단계를 최대한 빨리 만들기 위해, 단일 스레드가 여러 디스크 드라이브를 사용 중인 상태로 유지할 수 있도록 대규모 비동기 I/O 작업이 사용됩니다.
Note
빌드 입력이 사용 가능한 메모리보다 조금밖에 크지 않다면 인-메모리 해시 조인과 유예 해시 조인의 요소가 단일 단계에서 결합되어 하이브리드 해시 조인이 생성됩니다.
최적화 중에 사용되는 해시 조인을 확인하는 것이 항상 가능한 것은 아닙니다. 따라서 SQL Server는 메모리 내 해시 조인을 사용하여 시작하고, 빌드 입력 크기에 따라 유예 해시 조인 및 재귀 해시 조인으로 점진적으로 전환합니다.
쿼리 최적화 프로그램에서 두 입력 중 어느 것이 더 작은지 잘못 예상하여 빌드 입력이어야 하는 경우 빌드 및 프로브 역할은 동적으로 반전됩니다. 해시 조인은 더 작은 오버플로 파일을 빌드 입력으로 사용하는지 확인합니다. 이 기법을 역할 반전이라고 합니다. 역할 반전은 디스크에 하나 이상 분산된 후 해시 조인 내에서 발생합니다.
Note
역할 반전은 모든 쿼리 참고 또는 구조와 관계없이 발생합니다. 역할 반전은 쿼리 계획에 표시되지 않습니다. 이 경우 사용자에게 투명합니다.
해시 구제 금융
해시 재귀 한도 초과라는 용어는 경우에 따라 유예 해시 조인 또는 재귀 해시 조인을 설명하는 데 사용됩니다.
Note
재귀 해시 조인 또는 해시 재귀 한도 초과는 서버 성능을 저하시킵니다. 추적에서 해시 경고 이벤트가 많이 발견되면 조인되는 열의 통계를 업데이트하십시오.
해시 재귀 한도 초과에 대한 자세한 내용은 해시 경고 이벤트 클래스를 참조하세요.
적응 조인
배치 모드 적응 조인 연산자를 사용하면 해시 조인 또는 중첩된 루프 조인 메서드 선택을 첫 번째 입력이 검사된 후까지 지연할 수 있습니다. 적응 조인 연산자는 중첩 루프 계획으로 전환할 시기를 결정하는 데 사용되는 임계값을 정의합니다. 따라서 쿼리 계획을 다시 컴파일하지 않고도 실행 중에 더 나은 조인 전략으로 동적으로 전환할 수 있습니다.
Tip
소규모 및 대규모 조인 입력 검사 간에 자주 진동하는 워크로드는 이 기능을 통해 가장 많은 이점을 얻을 수 있습니다.
런타임은 다음 단계에 따라 결정됩니다.
- 중첩 루프 조인이 해시 조인보다 적합할 만큼 빌드 조인 입력의 행 수가 충분히 적으면 계획이 중첩 루프 알고리즘으로 전환됩니다.
- 빌드 조인 입력이 특정 행 수 임계값을 초과하면 전환이 발생하지 않으며 계획이 해시 조인을 계속 사용합니다.
다음 쿼리는 적응 조인 예제를 설명하는 데 사용됩니다.
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
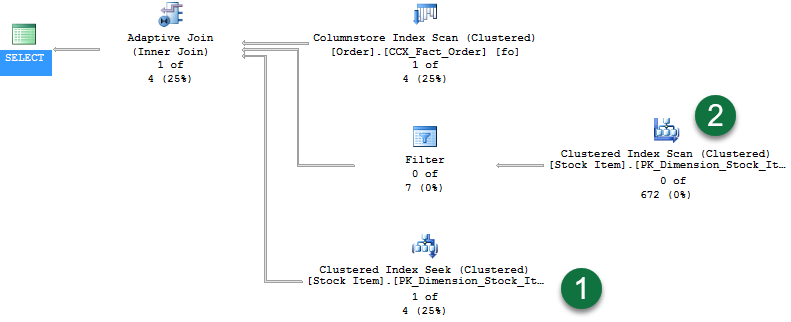
이 쿼리는 336개의 행을 반환합니다. 라이브 쿼리 통계를 사용하도록 설정하면 다음 계획이 표시됩니다.

계획에서 다음 사항에 유의하세요.
- 해시 조인 빌드 단계에 대한 행을 제공하는 데 사용되는 columnstore 인덱스 검사입니다.
- 새 적응 조인 연산자입니다. 이 연산자는 중첩 루프 계획으로 전환할 시기를 결정하는 데 사용되는 임계값을 정의합니다. 이 예제에서 임계값은 78개 행입니다. >= 78개 행이면 모두 해시 조인을 사용합니다. 임계값보다 작으면 중첩 루프 조인이 사용됩니다.
- 쿼리가 336개의 행을 반환하므로, 임계값을 초과하므로 두 번째 분기는 표준 해시 조인 작업의 프로브 단계를 나타냅니다. 라이브 쿼리 통계에는 연산자를 통해 흐르는 행(이 예의 경우 "672/672")이 표시됩니다.
- 마지막 분기는 임계값을 초과하지 않을 경우 중첩된 루프 조인에서 사용하기 위한 Clustered Index Seek입니다. "336개 중 0개" 행이 표시됩니다(분기가 사용되지 않음).
이제 계획과 동일한 쿼리를 비교합니다. 단, 이번에는 테이블의 Quantity 값에 하나의 행만 있습니다.
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
쿼리가 하나의 행을 반환합니다. 라이브 쿼리 통계를 사용하도록 설정하면 다음 계획이 표시됩니다.
계획에서 다음 사항에 유의하세요.
- 한 행이 반환되면 클러스터형 인덱스 검색에 행이 전달됩니다.
- 그리고 해시 조인 빌드 단계가 계속되지 않았기 때문에 두 번째 분기를 통과하는 행이 없습니다.
적응 조인 설명
적응 조인은 인덱싱된 동등한 중첩 루프 조인 계획보다 메모리 요구 사항이 더 높습니다. 중첩 루프가 해시 조인인 것처럼 추가 메모리가 요청됩니다. 빌드 단계의 오버헤드는 중지 및 이동 작업과 동일한 조인 스트리밍 중첩 루프로도 있습니다. 이러한 추가 비용을 통해 빌드 입력에서 행 수가 변동할 수 있는 시나리오에 유연성이 제공됩니다.
일괄 처리 모드 적응 조인은 문의 초기 실행에서 작동하며, 컴파일된 후에는 컴파일된 적응 조인 임계값과 외부 입력의 빌드 단계를 통과하는 런타임 행에 따라 연속 실행이 적응 상태로 유지됩니다.
적응 조인이 중첩된 루프 작업으로 전환하는 경우 해시 조인 빌드에서 이미 읽은 행이 사용됩니다. 연산자는 외부 참조 행을 다시 읽지 않습니다.
적응형 조인 활동 추적
적응 조인 연산자에는 다음과 같은 계획 연산자 특성이 있습니다.
| 계획 특성 | Description |
|---|---|
| AdaptiveThresholdRows | 해시 조인에서 중첩된 루프 조인으로 전환하는 데 사용하는 임계값을 표시합니다. |
| EstimatedJoinType | 조인 유형이 될 가능성이 있는 유형입니다. |
| ActualJoinType | 실제 계획에서 임계값에 따라 최종적으로 선택된 조인 알고리즘을 보여 줍니다. |
예상 계획은 정의된 적응 조인 임계값 및 예상 조인 형식과 함께 적응 조인 계획 모양을 보여줍니다.
Tip
쿼리 저장소는 일괄 처리 모드 적응 조인 계획을 캡처하고 강제로 적용할 수 있습니다.
적응 조인 적격 문
논리 조인을 일괄 처리 모드 적응 조인에 적합하게 만드는 몇 가지 조건은 다음과 같습니다.
- 데이터베이스 호환성 수준이 140 이상입니다.
- 쿼리는
SELECT문입니다(데이터 수정 문은 현재 부적격). - 조인은 인덱싱된 중첩 루프 조인 또는 해시 조인 실제 알고리즘을 통해 실행할 수 있습니다.
- 해시 조인은 쿼리 전체의 columnstore 인덱스 현재 상태를 통해 사용하도록 설정되거나, 조인에서 직접 참조되는 columnstore 인덱싱된 테이블을 통해 사용하도록 설정되거나, rowstore의 일괄 처리 모드를 사용하여 활성화되는 일괄 처리 모드를 사용합니다.
- 중첩 루프 조인 및 해시 조인의 생성된 대체 솔루션에는 동일한 첫 번째 자식(외부 참조)이 있어야 합니다.
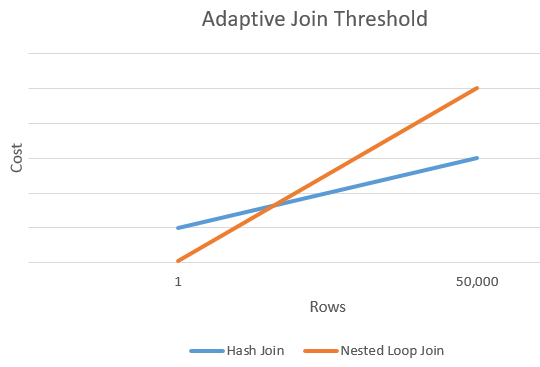
적응 임계값 행
다음 차트에서는 해시 조인 비용과 중첩된 루프 조인 대안 비용 간의 교차 예를 보여 줍니다. 이 교차점에서 임계값은 조인 작업에 사용되는 실제 알고리즘을 결정합니다.
호환성 수준을 변경하지 않고 적응 조인 사용 중지
데이터베이스 호환성 수준 140 이상을 유지하면서 데이터베이스 또는 문 범위에서 적응 조인을 사용하지 않도록 설정할 수 있습니다.
데이터베이스에서 발생하는 모든 쿼리 실행에 대한 적응형 조인을 재활성화하려면 해당 데이터베이스의 컨텍스트 내에서 다음을 실행합니다.
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
사용으로 설정하면 sys.database_scoped_configurations에서 이 설정이 enabled로 표시됩니다.
데이터베이스에서 발생하는 모든 쿼리 실행에 대한 적응형 조인을 재활성화하려면 해당 데이터베이스의 컨텍스트 내에서 다음을 실행합니다.
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
또한 적응 조인은 DISABLE_BATCH_MODE_ADAPTIVE_JOINS을 USE HINT 쿼리 힌트로 지정하여 특정 쿼리에 대해 사용하지 않도록 설정될 수도 있습니다. 다음은 그 예입니다.
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
USE HINT 쿼리 힌트는 데이터베이스 범위 구성 또는 추적 플래그 설정보다 우선합니다.
Null 값 및 조인
조인되는 테이블의 열에 null 값이 있는 경우 null 값이 서로 일치하지 않습니다. 조인되는 테이블 중 하나에서 열에 null 값이 있으면 WHERE 절에서 null 값을 제외하지 않는 한 외부 조인을 사용해야만 반환할 수 있습니다.
다음은 조인에 참여할 열에 각각 NULL이 있는 두 개의 테이블입니다.
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
열의 값을 열 ac 과 비교하는 조인은 다음 값이 있는 열에서 일치하는 항목을 NULL얻지 못합니다.
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
4 열과 a 열에서 값이 c인 한 행만 반환됩니다.
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
기본 테이블에서 반환되는 Null 값은 외부 조인에서 반환되는 Null 값과 구분하기가 어렵습니다. 예를 들어 다음 SELECT 문은 다음 두 테이블에서 왼쪽 외부 조인을 수행합니다.
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
결과 집합은 다음과 같습니다.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
따라서 조인 실패를 NULL 나타내는 데이터와 NULL 데이터를 쉽게 구분할 수 없습니다. 조인되는 데이터에 값이 있는 경우 NULL 일반적으로 일반 조인을 사용하여 결과에서 값을 생략하는 것이 좋습니다.