적용 대상:![]() Windows
Windows ![]() Azure SQL Managed Instance의 SQL Server
Azure SQL Managed Instance의 SQL Server
이 문서에서는 SQL Server 인스턴스에서 PolyBase를 사용하여 Hadoop에서 외부 데이터를 쿼리하는 방법을 설명합니다.
참고
SQL Server 2022(16.x)부터 Hadoop은 PolyBase에서 지원되지 않습니다.
필수 조건
- PolyBase를 설치하지 않은 경우 PolyBase 설치를 참조하세요. 설치 문서에서는 필수 구성 요소를 설명합니다.
- SQL Server 2019(15.x)부터 PolyBase 기능도 사용하도록 설정해야 합니다.
- PolyBase는 두 개의 Hadoop 공급자 Hortonworks Data Platform(HDP) 및 Cloudera Distributed Hadoop(CDH)을 지원합니다. Hadoop은 새 릴리스의 "Major.Minor.Version" 패턴을 따르며, 지원되는 주/부 릴리스 내의 모든 버전이 지원됩니다. 지원되는 HDP(Hortonworks Data Platform) 및 CDH(Cloudera Distributed Hadoop) 버전에 대한 자세한 내용은 PolyBase 연결 구성을 참조하세요.
참고
PolyBase는 SQL Server 2016 SP1 CU7 및 SQL Server 2017 CU3부터 Hadoop 암호화 영역을 지원합니다. PolyBase 스케일 아웃 그룹을 사용 중인 경우 모든 컴퓨팅 노드도 Hadoop 암호화 영역 지원을 포함하는 빌드에 있어야 합니다.
Hadoop 연결 구성
먼저 특정 Hadoop 공급자를 사용하도록 SQL Server PolyBase를 구성합니다.
'hadoop 연결'을 사용하여 sp_configure를 실행하고 공급자에 적절한 값을 설정합니다. 공급자의 값을 찾으려면 PolyBase 연결 구성을 참조하세요.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOservices.msc를 사용하여 SQL Server를 다시 시작해야 합니다. SQL Server를 다시 시작하면 다음 서비스가 다시 시작됩니다.
- SQL Server PolyBase 데이터 이동 서비스
- SQL Server PolyBase 엔진

푸시다운 계산 사용
쿼리 성능을 향상하려면 Hadoop 클러스터에 대한 푸시다운 계산을 사용하도록 설정합니다.
SQL Server의 설치 경로에서 yarn-site.xml 파일을 찾습니다. 일반적인 경로는 다음과 같습니다.
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\PolyBase\Hadoop\conf\Hadoop 컴퓨터에서 Hadoop 구성 디렉터리의 유사한 파일을 찾습니다. 파일에서 구성 키 yarn.application.classpath의 값을 찾아 복사합니다.
SQL Server 컴퓨터의 yarn-site.xml 파일에서 yarn.application.classpath 속성을 찾습니다. Hadoop 컴퓨터의 값을 값 요소에 붙여 넣습니다.
모든 CDH 5.X 버전에서 mapreduce.application.classpath 구성 매개 변수를 yarn.site.xml 파일의 끝이나 mapred-site.xml 파일에 추가해야 합니다. HortonWorks는 yarn.application.classpath 구성 내에 이러한 구성을 포함합니다. 예제는 PolyBase 구성을 참조하세요.
중요한
Hadoop에서 계산 푸시다운 기능을 사용하려면 대상 Hadoop 클러스터에 작업 기록 서버를 사용하도록 설정된 HDFS, YARN 및 MapReduce의 핵심 구성 요소가 있어야 합니다. PolyBase는 MapReduce를 통해 푸시다운 쿼리를 제출하고 작업 기록 서버에서 상태 가져옵니다. 두 구성 요소 중 하나가 없으면 쿼리가 실패합니다.
외부 테이블 구성
Hadoop 데이터 원본의 데이터를 쿼리하려면 Transact-SQL 쿼리에 사용할 외부 테이블을 정의해야 합니다. 다음 단계에서는 외부 테이블을 구성하는 방법을 설명합니다.
마스터 키가 없는 경우 데이터베이스에 마스터 키를 만듭니다. 이 키는 자격 증명 비밀을 암호화하는 데 필요합니다.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';논쟁
비밀번호 ='password'
데이터베이스의 마스터 키를 암호화하는 데 사용하는 암호입니다. password는 SQL Server의 인스턴스를 호스팅하는 컴퓨터의 Windows 암호 정책 요구 사항을 충족해야 합니다.
Kerberos 보안 Hadoop 클러스터를 위해 데이터베이스 범위에서 사용할 자격 증명을 생성합니다.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';CREATE EXTERNAL DATA SOURCE를 사용하여 외부 데이터 원본을 만듭니다.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );CREATE EXTERNAL FILE FORMAT을 사용하여 외부 파일 형식을 만듭니다.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE))CREATE EXTERNAL TABLE을 사용하여 Hadoop에 저장된 데이터를 가리키는 외부 테이블을 만듭니다. 이 예제에서 외부 데이터에는 자동차 센서 데이터가 포함되어 있습니다.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );외부 테이블에 대한 통계를 생성합니다.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
PolyBase 쿼리
PolyBase에 적합한 세 가지 함수가 있습니다.
- 외부 테이블에 대한 임시 쿼리
- 데이터 가져오기
- 데이터 내보내기
다음 쿼리는 가상의 자동차 센서 데이터를 사용한 예제를 제공합니다.
임시 쿼리
다음 임시 쿼리는 관계형 데이터와 Hadoop 데이터를 조인합니다. 이 쿼리는 35mph보다 빠르게 주행하는 고객을 선택하고 SQL Server에 저장된 구조화된 고객 데이터를 Hadoop에 저장된 차량 센서 데이터와 조인합니다.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
데이터 가져오기
다음 쿼리는 외부 데이터를 SQL Server로 가져옵니다. 이 예제에서는 더 자세한 분석을 수행하도록 빠른 드라이버의 데이터를 SQL Server로 가져옵니다. 성능을 높이기 위해 샘플은 columnstore 인덱스를 사용합니다.
SELECT DISTINCT
Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
INTO Fast_Customers from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
ORDER BY YearlyIncome
CREATE CLUSTERED COLUMNSTORE INDEX CCI_FastCustomers ON Fast_Customers;
데이터 내보내기
다음 쿼리는 SQL Server에서 Hadoop으로 데이터를 내보냅니다. 이를 수행하려면 먼저 PolyBase 내보내기를 사용하도록 설정해야 합니다. 그런 다음 데이터를 내보내기 전에 대상의 외부 테이블을 만듭니다.
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
-- Create an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] (
[FirstName] char(25) NOT NULL,
[LastName] char(25) NOT NULL,
[YearlyIncome] float NULL,
[MaritalStatus] char(1) NOT NULL
)
WITH (
LOCATION='/old_data/2009/customerdata',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO dbo.FastCustomer2009
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
SSMS에서 PolyBase 개체 보기
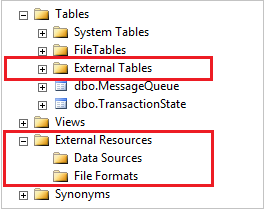
SSMS에서 외부 테이블은 별도의 외부 테이블 폴더에 표시됩니다. 외부 데이터 원본 및 외부 파일 형식은 외부 리소스 아래의 하위 폴더에 있습니다.
다음 단계
다양한 데이터 원본에 외부 데이터 원본 및 외부 테이블을 만드는 방법에 대한 자세한 자습서는 PolyBase Transact-SQL 참조를 참조하세요.
다음 문서에서 PolyBase를 사용하고 모니터링하는 더 많은 방법을 알아보세요.