쿼리 처리 아키텍처 가이드
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL 데이터베이스
Azure SQL 데이터베이스 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server 데이터베이스 엔진은 로컬 테이블, 분할된 테이블 및 여러 서버에 분산된 테이블과 같은 다양한 데이터 스토리지 아키텍처의 쿼리를 처리합니다. 다음 섹션에서는 SQL Server가 실행 계획 캐싱을 통해 쿼리를 처리하고 쿼리 재사용을 최적화하는 방법을 설명합니다.
실행 모드
SQL Server 데이터베이스 엔진은 두 가지 고유한 처리 모드를 사용하여 Transact-SQL 문을 처리할 수 있습니다.
- 행 모드 실행
- 일괄 처리 실행
행 모드 실행
행 모드 실행은 데이터가 행 형식으로 저장되어 있는 기존 RDBMS 테이블에서 사용되는 쿼리 처리 메서드입니다. 쿼리가 실행되고 행 저장 테이블의 데이터에 액세스하는 경우 실행 트리 연산자 및 자식 연산자는 테이블 스키마에서 지정된 모든 열에 걸쳐 필요한 각 행을 읽습니다. 그런 다음 SQL Server는 읽은 각 행에서 SELECT 문, JOIN 조건자 또는 필터 조건자에서 참조하는 대로 결과 집합에 필요한 열을 검색합니다.
참고 항목
행 모드 실행은 OLTP 시나리오에 매우 효율적이지만 데이터 웨어하우징 시나리오와 같이 많은 양의 데이터를 검색할 때는 효율성이 떨어집니다.
일괄 처리 실행
일괄 처리 모드 실행은 여러 행을 함께 처리하는 쿼리 처리 방법입니다(따라서 용어 일괄처리). 일괄 처리 내의 각 열은 별도의 메모리 영역에 벡터로 저장되므로 일괄 처리 모드 처리는 벡터 기반입니다. 일괄 처리 모드 처리는 다중 코어 CPU에 최적화된 알고리즘과 최신 하드웨어에서 발견되는 메모리 처리량 증가도 사용합니다.
배치 모드 실행은 처음 소개되었을 때 columnstore 스토리지 형식과 긴밀히 통합되고 그에 맞게 최적화되었습니다. 그러나 SQL Server 2019(15.x)부터 Azure SQL 데이터베이스에서 일괄 처리 모드를 실행하려면 더 이상 columnstore 인덱스가 필요하지 않습니다. 자세한 내용은 rowstore의 일괄 처리 모드를 참조하세요.
일괄 처리 모드는 가능한 경우 압축된 데이터에서 작동하고 행 모드 실행에서 사용하는 교환 연산자를 제거합니다. 그 결과 병렬 처리가 개선되고 성능이 향상됩니다.
쿼리가 일괄 처리 모드에서 실행되고 columnstore 인덱스의 데이터에 액세스하는 경우 실행 트리 연산자와 자식 연산자는 열 세그먼트에서 여러 행을 함께 읽습니다. SQL Server는 SELECT 문, 조인 조건자 또는 필터 조건자에 의해 참조된 대로 결과에 필요한 열만 읽습니다. Columnstore 인덱스에 대한 자세한 내용은 Columnstore 인덱스 아키텍처를 참조하세요.
참고 항목
일괄 처리 모드 실행은 많은 양의 데이터를 읽고 집계하는 시나리오를 데이터 웨어하우징에 매우 효율적입니다.
SQL 문 처리
단일 Transact-SQL 문 처리는 SQL Server가 Transact-SQL 문을 실행하는 가장 기본적인 방법입니다. 로컬 기본 테이블(뷰 또는 원격 테이블 없음)만 참조하는 단일 SELECT 문을 처리하는 데 사용되는 단계는 기본 프로세스를 보여줍니다.
논리 연산자 우선 순위
문에 두 개 이상의 논리 연산자가 사용될 경우 NOT이 가장 먼저 계산되고 다음은 AND, 마지막으로 OR이 계산됩니다. 산술 연산자와 비트 연산자는 논리 연산자 이전에 처리됩니다. 자세한 내용은 운영자 우선 순위를 참조하세요.
다음 예제에서 색 조건은 제품 모델 21과 관련이 있으며 제품 모델 20과는 관련이 없습니다. AND가 OR보다 우선하기 때문입니다.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
괄호를 추가하여 OR를 가장 먼저 강제로 평가하고 쿼리의 의미를 변경할 수 있습니다. 다음 쿼리는 빨간색인 모델 20 및 21에서만 제품을 찾습니다.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
꼭 필요한 경우가 아니라도 괄호를 사용하면 쿼리의 가독성을 높이고 연산자 우선 순위로 인한 사소한 실수를 줄일 수 있습니다. 괄호를 사용하더라도 성능에는 거의 영향을 미치지 않습니다. 다음 예제는 구문적으로 동일하지만 원래 예제보다 더 읽기 쉬운 예제입니다.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
SELECT 문 최적화
SELECT 문은 비절차적입니다. 데이터베이스 서버가 요청된 데이터를 검색하는 데 사용해야 하는 정확한 단계를 명시하지 않습니다. 즉, 데이터베이스 서버는 문을 분석하여 요청된 데이터를 추출하는 가장 효율적인 방법을 결정해야 합니다. 이것을 SELECT 문 최적화라고 하며 이를 위한 구성 요소를 쿼리 최적화 프로그램이라고 합니다. 쿼리 최적화 프로그램의 입력은 쿼리, 데이터베이스 스키마(테이블 및 인덱스 정의), 데이터베이스 통계로 구성됩니다. 쿼리 최적화 프로그램의 출력은 쿼리 실행 계획이며 경우에 따라 쿼리 계획이나 실행 계획이라고 합니다. 실행 계획의 내용은 이 문서의 뒷부분에서 자세히 설명합니다.
다음 다이어그램은 단일 SELECT 문을 최적화하는 동안 쿼리 최적화 프로그램에 입력되는 내용과 출력 내용을 보여줍니다.
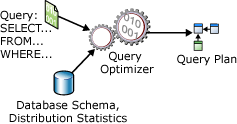
SELECT 문은 다음 항목만을 지정합니다.
- 결과 집합의 형식. 이는 주로 선택 목록에 지정됩니다. 그러나
ORDER BY및GROUP BY와 같은 다른 절은 결과 집합의 최종 형식에도 영향을 줍니다. - 원본 데이터를 포함하는 테이블.
FROM절에 지정됩니다. - 테이블이
SELECT문의 목적을 위해 논리적으로 관련되는 방식. 이는WHERE절 또는FROM다음에 오는ON절에 나타날 수 있는 조인 사양에서 정의됩니다. - 원본 테이블의 행이
SELECT문을 한정하기 위해 충족해야 하는 조건입니다. 이러한 항목은WHERE및HAVING절에 지정됩니다.
쿼리 실행 계획은 다음 사항을 정의합니다.
원본 테이블이 액세스되는 순서
일반적으로 데이터베이스 서버가 기본 테이블에 액세스하여 결과 집합을 빌드할 수 있는 많은 시퀀스가 있습니다. 예를 들어SELECT문이 세 개의 테이블을 참조하는 경우 데이터베이스 서버는 먼저TableA에 액세스하고,TableA의 데이터를 사용하여TableB에서 일치하는 행을 추출한 후TableB의 데이터를 사용하여TableC에서 데이터를 추출합니다. 다음은 데이터베이스 서버가 테이블에 액세스할 수 있는 여러 순서입니다.
TableC,TableB,TableA또는
TableB,TableA,TableC또는
TableB,TableC,TableA또는
TableC, ,TableATableB각 테이블에서 데이터를 추출하는 데 사용되는 메서드
일반적으로 각 테이블의 데이터에 액세스하는 방법에는 여러 가지가 있습니다. 특정 키 값을 가진 몇몇 행만 필요한 경우 데이터베이스 서버는 인덱스를 사용할 수 있습니다. 테이블의 모든 행이 필요한 경우 데이터베이스 서버는 인덱스를 무시하고 테이블을 검색할 수 있습니다. 테이블의 모든 행이 필요하지만 키 열이ORDER BY에 있는 인덱스가 있으면 테이블 검색 대신 인덱스 검색을 수행하여 다른 종류의 결과 집합을 저장할 수 있습니다. 테이블이 매우 작은 경우 테이블 검색이 거의 모든 테이블에 액세스하는 가장 효율적인 방법이 될 수 있습니다.계산 컴퓨팅에 사용되는 방법과 각 테이블의 데이터를 필터링, 집계, 정렬하는 방법
테이블에서 데이터에 액세스하는 경우 여러 가지 방법으로 스칼라 값 계산과 같은 데이터에 대한 계산을 수행하고, 쿼리 텍스트에 정의된 대로 데이터를 집계 및 정렬(예:GROUP BY또는ORDER BY절 사용)하며, 데이터를 필터링(예:WHERE또는HAVING절 사용)할 수 있습니다.
가능한 여러 계획에서 하나의 실행 계획을 선택하는 프로세스를 최적화라고 합니다. 쿼리 최적화 프로그램은 데이터베이스 엔진의 가장 중요한 구성 요소 중 하나입니다. 쿼리 최적화 프로그램에서 쿼리를 분석하고 계획을 선택하는 데 일부 오버헤드가 사용되지만, 쿼리 최적화 프로그램에서 효율적인 실행 계획을 선택하면 일반적으로 이 오버헤드가 몇 배 절약됩니다. 예를 들어, 두 건설 회사는 집에 대해 동일한 청사진을 부여 할 수 있습니다. 한 회사가 집을 짓는 방법을 계획하기 위해 처음에 며칠을 보내고 다른 회사가 계획없이 건물을 짓기 시작하면 프로젝트 계획에 시간을 할애한 회사가 먼저 완료 될 것입니다.
SQL Server 쿼리 최적화 프로그램은 비용 기반 최적화 프로그램입니다. 가능한 각 실행 계획에는 사용된 컴퓨팅 리소스의 양과 관련된 비용이 있습니다. 쿼리 최적화 프로그램은 가능한 실행 계획을 분석하고 예상 비용이 가장 낮은 계획을 선택해야 합니다. 일부 복잡한 SELECT 문에는 가능한 수많은 실행 계획이 포함될 수 있습니다. 이러한 경우 쿼리 최적화 프로그램은 가능한 모든 조합을 분석하지 않습니다. 대신, 복잡한 알고리즘을 사용하여 가능한 최소 비용에 상당히 가까운 비용이 있는 실행 계획을 찾습니다.
SQL Server 쿼리 최적화 프로그램이 리소스 비용이 가장 낮은 실행 계획만 선택하는 것은 아닙니다. 쿼리 최적화 프로그램은 타당한 리소스 비용을 사용하여 사용자에게 결과를 반환하고 가장 빠른 결과를 반환하는 계획을 선택합니다. 예를 들어 쿼리를 병렬로 처리하는 것은 일반적으로 쿼리를 직렬로 처리하는 것보다 더 많은 리소스를 사용하지만 쿼리를 더 빠르게 완료합니다. SQL Server 쿼리 최적화 프로그램은 서버 로드에 나쁜 영향을 미치지 않는 경우 병렬 실행 계획을 사용하여 결과를 반환합니다.
SQL Server 쿼리 최적화 프로그램은 테이블 또는 인덱스에서 정보를 추출하기 위한 다양한 방법의 리소스 비용을 추정할 때 배포 통계를 사용합니다. 배포 통계는 열 및 인덱스에 대해 유지되며 기본 데이터의 밀도1에 대한 정보를 보유합니다. 이는 특정 인덱스 또는 열에 있는 값의 선택을 나타내는 데 사용됩니다. 예를 들어 자동차를 나타내는 테이블에서 많은 자동차에는 제조업체가 동일하지만 각 자동차에는 고유한 VIN(차량 식별 번호)이 있습니다. VIN의 밀도가 제조업체보다 낮으므로 VIN의 인덱스가 제조업체의 인덱스보다 더 선택적입니다. 인덱스 통계가 현재의 데이터가 아니면 쿼리 최적화 프로그램은 테이블의 현재 상태에 대해 최상의 선택을 하지 못할 수 있습니다. 밀도에 대한 자세한 내용은 통계를 참조하세요.
1 밀도는 데이터에 존재하는 고유 값의 분포 또는 지정된 열의 평균 중복 값 수를 정의합니다. 밀도가 감소하면 값의 선택도가 증가합니다.
SQL Server 쿼리 최적화 프로그램은 데이터베이스 서버가 프로그래머 또는 데이터베이스 관리자의 입력 없이도 데이터베이스의 변화하는 조건에 동적으로 조정할 수 있게 하기 때문에 중요합니다. 이를 통해 프로그래머는 쿼리의 최종 결과를 설명하는 데 집중할 수 있습니다. SQL Server 쿼리 최적화 프로그램은 문이 실행될 때마다 데이터베이스 상태에 대한 효율적인 실행 계획을 빌드할 것이라고 신뢰할 수 있습니다.
참고 항목
SQL Server Management Studio에는 실행 계획을 표시하는 세 가지 옵션이 있습니다.
SELECT 문 처리
SQL Server가 단일 SELECT 문을 처리하는 데 사용하는 기본 단계는 다음과 같습니다.
- 파서는
SELECT문을 검색하여 키워드, 식, 연산자, 식별자와 같은 논리 단위로 나눕니다. - 시퀀스 트리라고도 하는 쿼리 트리는 원본 데이터를 결과 집합에 필요한 형식으로 변환하는 데 필요한 논리적 단계를 설명하며 빌드됩니다.
- 쿼리 최적화 프로그램은 원본 테이블에 액세스할 수 있는 다양한 방법을 분석합니다. 그런 후 리소스 사용을 줄이는 동시에 결과를 가장 빨리 반환하는 일련의 단계를 선택합니다. 쿼리 트리는 이 정확한 일련의 단계를 기록하도록 업데이트됩니다. 쿼리 트리의 최적화된 최종 버전을 실행 계획이라고 합니다.
- 관계형 엔진이 실행 계획을 실행하기 시작합니다. 기본 테이블의 데이터가 필요한 단계가 처리되면 관계형 엔진은 스토리지 엔진이 관계형 엔진에서 요청한 행 집합의 데이터를 전달하도록 요청합니다.
- 관계형 엔진은 스토리지 엔진에서 반환된 데이터를 결과 집합에 대해 정의된 형식으로 처리하고 결과 집합을 클라이언트에 반환합니다.
상수 폴딩 및 식 평가
SQL Server에서는 일부 상수 식을 초기에 평가하여 쿼리 성능을 향상합니다. 이를 상수 폴딩이라고 합니다. 상수는 3, 'ABC', '2005-12-31', 1.0e3 또는 0x12345678 같은 Transact-SQL 리터럴입니다.
폴딩 가능 식
SQL Server에서는 다음 유형의 식에 상수 폴딩을 사용합니다.
- 상수만 포함하는 산술 식(예:
1 + 1및5 / 3 * 2)입니다. - 상수만 포함된 논리 식(예:
1 = 1및1 > 2 AND 3 > 4)입니다. - SQL Server에서 폴더블로 간주되는 기본 제공 함수입니다(
CAST및CONVERT포함). 일반적으로 기본 함수는 SET 옵션, 언어 설정, 데이터베이스 옵션, 암호화 키와 같은 다른 컨텍스트 정보가 아닌 입력의 함수인 경우에만 폴딩이 가능합니다. 비결정적 함수는 폴딩 가능하지 않습니다. 결정적 기본 제공 함수는 몇 가지 예외를 제외하고 폴딩할 수 있습니다. - CLR 사용자 정의 형식의 결정적 메서드 및 결정적 스칼라 반환 CLR 사용자 정의 함수입니다(SQL Server 2012(11.x)부터). 자세한 내용은 CLR 사용자 정의 함수 및 메서드에 대한 상수 폴딩을 참조하세요.
참고 항목
큰 개체 형식에 대해서는 예외가 발생합니다. 접기 프로세스의 출력 형식이 큰 개체 형식(text, ntext, image, nvarchar(max), varchar(max), varbinary(max) 또는 XML)인 경우 SQL Server는 식을 접지 않습니다.
비폴딩 식
다른 모든 식 유형은 폴딩할 수 없습니다. 특히 다음 식 유형은 폴딩할 수 없습니다.
- 비상수 식(예: 열 값에 따라 결과가 달라지는 식)
- 결과가 지역 변수 또는 매개 변수(예: @x)에 따라 달라지는 식입니다.
- 비결정적 함수
- 사용자 정의 Transact-SQL 함수1.
- 언어 설정에 따라 결과가 달라지는 식
- SET 옵션에 따라 결과가 달라지는 식
- 서버 구성 옵션에 따라 결과가 달라지는 식
1 SQL Server 2012(11.x) 이전에는 결정적 스칼라 반환 CLR 사용자 정의 함수 및 CLR 사용자 정의 형식의 메서드를 접을 수 없었습니다.
폴딩 가능 및 비폴딩 상수 식의 예
다음과 같은 쿼리를 고려해 보세요.
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
이 쿼리에서 PARAMETERIZATION 데이터베이스 옵션을 FORCED로 설정하지 않으면 쿼리가 컴파일되기 전에 117.00 + 1000.00 식이 평가되고 1117.00 결과로 바뀝니다. 이 상수 폴딩의 이점은 다음과 같습니다.
- 런타임에서 식을 반복적으로 평가할 필요가 없습니다.
- 계산 후 식의 값은 쿼리 최적화 프로그램에서 쿼리
TotalDue > 117.00 + 1000.00부분의 결과 집합 크기를 예측하는 데 사용됩니다.
반면 dbo.f가 스칼라 사용자 정의 함수인 경우 SQL Server는 결정적이더라도 사용자 정의 함수를 포함하는 식을 접지 않으므로 dbo.f(100) 식이 폴딩되지 않습니다. 매개 변수화에 대한 자세한 내용은 이 문서의 뒷부분에 있는 강제 매개 변수화를 참조하세요.
식 계산
뿐만 아니라 상수 폴딩 가능 식이 아니지만 해당 인수를 컴파일 시간에 알 수 없는 일부 식은 최적화 중 최적화 프로그램의 구성 요소인 결과 집합 크기(카디널리티) 평가자에 의해 평가됩니다. 이때 인수가 매개 변수인지 또는 상수인지 여부는 고려하지 않습니다.
특히 모든 입력이 알려진 경우(UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST, CONVERT) 컴파일 시간에 다음과 같은 기본 제공 함수 및 특수 연산자가 평가됩니다. 다음 연산자는 모든 입력이 알려진 경우 컴파일 시간에 평가됩니다.
- 산술 연산자: +, -, *, /, 단항 -
- 논리 연산자:
AND,OR,NOT - 비교 연산자: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
이외에 다른 함수나 연산자는 카디널리티 예측 중에 쿼리 최적화 프로그램에서 평가되지 않습니다.
컴파일 시간 식 평가의 예
다음 저장 프로시저를 고려합니다.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
프로시저의 SELECT 문을 최적화하는 동안 쿼리 최적화 프로그램은 OrderDate > @d+1 조건에 대한 결과 집합의 예상 카디널리티를 평가하려고 합니다. @d가 매개 변수이므로 @d+1 식은 상수 폴딩되지 않습니다. 그러나 최적화 시 매개 변수의 값을 알 수 있습니다. 이렇게 하면 쿼리 최적화 프로그램에서 결과 집합의 크기를 정확하게 예측할 수 있으므로 적절한 쿼리 계획을 선택하는 데 도움이 됩니다.
이제 앞의 예와 유사한 다음 예를 살펴보십시오. 지역 변수로 @d2 대신 @d+1가 사용되고, 식이 쿼리 내에서가 아니라 SET 문에서 실행된다는 점만 다릅니다.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
SQL Server에서 MyProc2의 SELECT 문을 최적화할 때 @d2 값이 알려지지 않습니다. 따라서 쿼리 최적화 프로그램에서는 OrderDate > @d2의 선택도에 대해 기본 추정값(이 예의 경우 30%)을 사용합니다.
다른 문 처리
SELECT 문 처리를 위해 설명된 기본 단계는 INSERT, UPDATE 및 DELETE와 같은 다른 Transact-SQL 문에도 적용됩니다. UPDATE 및 DELETE 문은 모두 수정하거나 삭제할 행 집합을 대상으로 지정해야 합니다. 이러한 행을 식별하는 프로세스는 SELECT 문의 결과 집합에 기여하는 원본 행을 식별하는 데 사용되는 프로세스와 동일합니다. UPDATE 문 및 INSERT문 모두 업데이트 또는 삽입할 데이터 값을 제공하는 포함된 SELECT 문을 포함할 수 있습니다.
DDL(데이터 정의 언어) 문(예: CREATE PROCEDURE 또는 ALTER TABLE)조차도 궁극적으로 시스템 카탈로그 테이블에 대한 일련의 관계형 작업으로 확인되고 때로는 ALTER TABLE ADD COLUMN과 같이 데이터 테이블에 대해 확인됩니다.
작업 테이블
관계형 엔진은 Transact-SQL 문에 지정된 논리 작업을 수행하기 위해 작업 테이블을 작성해야 합니다. 작업 테이블은 중간 결과를 보관하는 데 사용되는 내부 테이블입니다. 특정 GROUP BY, ORDER BY 또는 UNION 쿼리에 대해 작업 테이블이 생성됩니다. 예를 들어 ORDER BY 절이 인덱스 범위에 해당하지 않는 열을 참조하는 경우 관계형 엔진은 요청되는 순서로 결과 집합을 정렬하기 위해 작업 테이블을 만들어야 할 수 있습니다. 또한 작업 테이블은 쿼리 계획의 일부를 실행한 결과를 일시적으로 보유하는 스풀로도 사용됩니다. 작업 테이블은 기본 제공 tempdb이며 더 이상 필요하지 않을 때 자동으로 삭제됩니다.
뷰 확인
SQL Server 쿼리 프로세서는 인덱싱된 뷰와 인덱싱되지 않은 뷰를 다르게 처리합니다.
- 인덱싱된 뷰의 행은 테이블과 동일한 형식으로 데이터베이스에 저장됩니다. 쿼리 최적화 프로그램이 쿼리 계획에서 인덱싱된 뷰를 사용하기로 결정한 경우 인덱싱된 뷰는 기본 테이블과 동일한 방식으로 처리됩니다.
- 인덱싱되지 않은 뷰의 정의만 저장되고 뷰의 행은 저장되지 않습니다. 쿼리 최적화 프로그램은 인덱싱되지 않은 뷰를 참조하는 Transact-SQL 문에 대해 작성하는 실행 계획에 뷰 정의의 논리를 추가합니다.
SQL Server 쿼리 최적화 프로그램에서 인덱싱된 뷰의 사용 시기를 결정하는 데 사용되는 논리는 테이블 인덱스의 사용 시기를 결정하는 데 사용되는 논리와 유사합니다. 인덱싱된 뷰의 데이터가 Transact-SQL 문의 전체나 일부를 포괄하고 해당 뷰의 인덱스가 저렴한 비용의 액세스 경로로 확인되면, 쿼리에서 이름별로 뷰가 참조되는지 여부와 관계없이 인덱스가 선택됩니다.
Transact-SQL 문에서 인덱싱되지 않은 뷰를 참조할 경우 파서와 쿼리 최적화 프로그램은 Transact-SQL 문의 원본과 뷰의 원본을 모두 분석하고 단일 실행 계획을 세웁니다. Transact-SQL 문과 뷰에 대해 별도의 계획이 있는 것은 아닙니다.
다음 보기를 살펴보세요.
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
이 뷰를 기반으로 두 Transact-SQL 문이 모두 기본 테이블에 대해 동일한 작업을 수행하고 동일한 결과를 생성합니다.
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
SQL Server Management Studio 실행 계획 기능은 관계형 엔진이 두 SELECT 문 모두에 대해 동일한 실행 계획을 빌드한다는 것을 보여줍니다.
보기와 함께 힌트 사용
쿼리의 뷰에 배치되는 힌트는 뷰가 확장되어 기본 테이블에 액세스할 때 검색되는 다른 힌트와 충돌할 수 있습니다. 이러한 경우 쿼리에서 오류를 반환합니다. 예를 들어 다음과 같이 뷰 정의에 테이블 힌트가 포함되어 있습니다.
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
이제 이 쿼리를 입력한다고 가정합니다.
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
쿼리의 뷰 SERIALIZABLE 에 적용되는 힌트 Person.AddrState 가 뷰 확장 시 뷰의 Person.Address 테이블과 Person.StateProvince 테이블에 모두 전파되기 때문에 이 쿼리는 실패합니다. 그러나 보기를 확장하면 Person.Address에 대한 NOLOCK 힌트도 표시됩니다. SERIALIZABLE 및 NOLOCK 힌트가 충돌하기 때문에 결과 쿼리가 올바르지 않습니다.
PAGLOCK, NOLOCK, ROWLOCK, TABLOCK또는 TABLOCKX 테이블 힌트도 HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD, SERIALIZABLE 테이블 힌트처럼 서로 충돌합니다.
여러 수준의 중첩된 뷰를 통해 힌트가 전파될 수 있습니다. 예를 들어 쿼리가 뷰 v1에 HOLDLOCK 힌트를 적용한다고 가정합니다. v1 이 확장될 때 이 뷰의 정의에 v2 뷰가 포함되어 있음을 확인했습니다. v2의 정의에는 기본 테이블 중 하나에 대한 NOLOCK 힌트가 포함됩니다. 그러나 이 테이블에는 HOLDLOCK 뷰의 쿼리로부터 v1힌트도 상속됩니다. NOLOCK 힌트와 HOLDLOCK 힌트가 충돌하므로 쿼리가 실패합니다.
뷰를 포함하는 쿼리에 FORCE ORDER 힌트를 사용하면 정렬된 구조체에서의 뷰 위치에 따라 뷰 내의 테이블 조인 순서가 결정됩니다. 예를 들어 다음 쿼리는 세 개의 테이블과 뷰 중에서 선택합니다.
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
View1은 다음과 같이 정의됩니다.
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
쿼리 계획의 조인 순서는 Table1, Table2, TableA, TableB, Table3입니다.
뷰에서 인덱스 확인
모든 인덱스와 마찬가지로 SQL Server는 쿼리 최적화 프로그램에서 인덱싱된 뷰를 사용하는 것이 유익하다고 판단하는 경우에만 쿼리 계획에서 인덱싱된 뷰를 사용하도록 선택합니다.
인덱싱된 뷰는 모든 버전의 SQL Server에서 만들 수 있습니다. 이전 버전의 일부 SQL Server에서는 쿼리 최적화 프로그램에서 인덱싱된 뷰를 자동으로 고려합니다. 이전 버전의 일부 SQL Server에서는 인덱싱된 뷰를 사용하려면 NOEXPAND 테이블 힌트를 사용해야 합니다. SQL Server 2016(13.x) 서비스 팩 1 이전에는 쿼리 최적화 프로그램에서 인덱싱된 뷰를 자동으로 사용하는 것은 SQL Server의 특정 버전에서만 지원됩니다. 이후 모든 버전이 인덱싱된 뷰의 자동 사용을 지원합니다. Azure SQL 데이터베이스와 Azure SQL Managed Instance도 NOEXPAND 힌트를 지정하지 않고 인덱싱된 뷰를 자동으로 사용하도록 지원합니다.
SQL Server 쿼리 최적화 프로그램은 다음 조건이 충족될 때 인덱싱된 뷰를 사용합니다.
- 이러한 세션 옵션은 다음에서
ON으로 설정됩니다.ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
NUMERIC_ROUNDABORT세션 옵션이 OFF로 설정됩니다.- 쿼리 최적화 프로그램에서 쿼리의 요소와 뷰 인덱스 열 간의 일치 사항을 찾습니다. 예를 들어 다음과 같은 사항이 일치합니다.
- WHERE 절의 검색 조건 조건자
- 조인 작업
- 집계 함수
GROUP BY절- 테이블 참조
- 인덱스 사용 시 예상 비용이 쿼리 최적화 프로그램에서 고려하는 액세스 메커니즘의 비용 중에서 가장 낮습니다.
- 인덱싱된 뷰의 테이블 참조에 해당하는 쿼리에서 참조되는 모든 테이블(직접 또는 기본 테이블에 액세스하기 위해 뷰를 확장)은 쿼리에서 동일한 힌트 집합을 적용해야 합니다.
참고 항목
이 컨텍스트에서 READCOMMITTED 힌트와 READCOMMITTEDLOCK 힌트는 현재 트랜잭션 격리 수준과 관계없이 항상 다른 힌트로 간주됩니다.
SET 옵션 및 테이블 힌트에 대한 요구 사항을 제외하고 위의 사항은 쿼리 최적화 프로그램에서 쿼리가 테이블 인덱스 범위에 해당하는지 즉, 테이블 인덱스로 쿼리를 처리할 수 있는지 여부를 확인하는 데 사용하는 규칙과 동일합니다. 인덱싱된 뷰를 사용하려면 쿼리에 다른 항목을 지정하지 않아야 합니다.
쿼리가 쿼리 최적화 프로그램에서 인덱싱된 뷰를 사용하기 위해 FROM 절에서 인덱싱된 뷰를 명시적으로 참조할 필요는 없습니다. 쿼리가 인덱싱된 뷰에도 있는 기본 테이블의 열에 대한 참조를 포함하고 쿼리 최적화 프로그램에서 해당 인덱싱된 뷰를 사용할 때 비용이 가장 저렴한 액세스 메커니즘을 제공할 수 있을 것으로 예상하는 경우 쿼리 최적화 프로그램은 기본 테이블 인덱스가 쿼리에서 직접 참조되지 않을 때 이러한 기본 테이블 인덱스를 선택하는 것과 유사한 방법으로 인덱싱된 뷰를 선택합니다. 쿼리에서 참조하지 않는 열을 포함하는 뷰의 경우 뷰가 쿼리에 지정된 하나 이상의 열을 포괄하기 위한 가장 저렴한 비용 옵션을 제공하면 쿼리 최적화 프로그램에서 이 뷰를 선택할 수 있습니다.
쿼리 최적화 프로그램은 FROM 절에서 참조되는 인덱싱된 뷰를 표준 뷰로 처리합니다. 쿼리 최적화 프로그램은 최적화 프로세스 시작 시 뷰의 정의를 쿼리로 확장합니다. 그런 다음 인덱싱된 뷰 일치가 수행됩니다. 쿼리 최적화 프로그램에서 선택하는 최종 실행 계획에 인덱싱된 뷰가 사용될 수 있습니다. 또는 계획이 뷰에서 참조하는 기본 테이블에 액세스하여 뷰에서 필요한 데이터를 구체화할 수 있습니다. 쿼리 최적화 프로그램에서는 이 중 비용이 가장 낮은 방법을 선택합니다.
인덱싱된 뷰에서 힌트 사용
EXPAND VIEWS 쿼리 힌트를 사용하여 뷰 인덱스가 쿼리에 사용되는 것을 방지하거나 NOEXPAND 테이블 힌트를 사용하여 쿼리의 FROM 절에 지정된 인덱싱된 뷰에 대한 인덱스 사용을 강제할 수 있습니다. 그러나 쿼리 최적화 프로그램에서 각 쿼리에 사용할 최상의 액세스 방법을 동적으로 결정하게 해야 합니다. 테스트를 통해 성능이 크게 향상되는 특정 사례에 EXPAND 및 NOEXPAND의 사용을 제한합니다.
EXPAND VIEWS옵션은 쿼리 최적화 프로그램에서 전체 쿼리에 뷰 인덱스를 사용하지 않도록 지정합니다.뷰에
NOEXPAND를 지정하면 쿼리 최적화 프로그램은 뷰에 정의된 인덱스의 사용을 고려합니다.NOEXPAND를 선택적INDEX()절로 지정하면 쿼리 최적화 프로그램에서 지정된 인덱스를 사용하도록 강제 적용됩니다.NOEXPAND는 인덱싱된 뷰에 대해서만 지정할 수 있으며 인덱싱되지 않은 뷰에 대해 지정할 수 없습니다. SQL Server 2016(13.x) 서비스 팩 1 이전에는 쿼리 최적화 프로그램에서 인덱싱된 뷰를 자동으로 사용하는 것은 SQL Server의 특정 버전에서만 지원됩니다. 이후 모든 버전이 인덱싱된 뷰의 자동 사용을 지원합니다. Azure SQL 데이터베이스와 Azure SQL Managed Instance도NOEXPAND힌트를 지정하지 않고 인덱싱된 뷰를 자동으로 사용하도록 지원합니다.
뷰가 포함된 쿼리에서 NOEXPAND 및 EXPAND VIEWS 둘 다 지정하지 않으면 뷰가 확장되어 기본 테이블에 액세스합니다. 뷰를 구성하는 쿼리에 테이블 힌트가 포함된 경우 해당 힌트는 기본 테이블로 전파됩니다. (이 절차는 뷰 확인에서 자세히 설명합니다.) 뷰의 기본 테이블에 있는 힌트 집합이 모두 동일하면 쿼리를 인덱싱된 뷰와 일치시킬 수 있습니다. 대부분의 경우 이러한 힌트는 보기에서 직접 상속되기 때문에 서로 일치합니다. 그러나 쿼리가 뷰 대신 테이블을 참조하고 이러한 테이블에 직접 적용된 힌트가 동일하지 않으면 쿼리를 인덱싱된 뷰와 일치시킬 수 없습니다. 뷰 확장 후 쿼리에서 참조되는 테이블에 INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK 또는 XLOCK 힌트가 적용되는 경우 쿼리는 인덱싱된 뷰 일치에 적합하지 않습니다.
INDEX (index_val[ ,...n] ) 형식의 테이블 힌트가 쿼리의 뷰를 참조하고 NOEXPAND 힌트도 지정하지 않으면 인덱스 힌트는 무시됩니다. 특정 인덱스를 사용하도록 지정하려면 NOEXPAND를 사용합니다.
일반적으로 쿼리 최적화 프로그램이 인덱싱된 뷰를 쿼리와 일치하면 쿼리의 테이블 또는 뷰에 지정된 모든 힌트가 인덱싱된 뷰에 직접 적용됩니다. 쿼리 최적화 프로그램에서 인덱싱된 뷰를 사용하지 않도록 선택하면 모든 힌트가 뷰에서 참조되는 테이블에 직접 전파됩니다. 자세한 내용은 뷰 확인을 참조하세요. 이 전파는 조인 힌트에는 적용되지 않습니다. 쿼리의 원래 위치에만 적용됩니다. 쿼리 최적화 프로그램에서 쿼리를 인덱싱된 뷰와 일치시킬 때 조인 힌트는 고려되지 않습니다. 쿼리 계획에서 조인 힌트가 포함된 쿼리의 일부와 일치하는 인덱싱된 뷰를 사용하는 경우 조인 힌트는 계획에 사용되지 않습니다.
인덱싱된 뷰 정의에는 힌트가 허용되지 않습니다. 호환 모드 80 이상에서 SQL Server는 인덱싱된 뷰 정의 내에서 힌트를 유지 관리하거나 인덱싱된 뷰를 사용하는 쿼리를 실행할 때 힌트를 무시합니다. 인덱싱된 뷰 정의에서 힌트를 사용하면 80 호환성 모드에서 구문 오류가 발생하지 않지만 무시됩니다.
자세한 내용은 테이블 힌트(Transact-SQL)를 참조하세요.
분산형 분할 뷰 해결
SQL Server 쿼리 프로세서는 분산형 분할 뷰의 성능을 최적화합니다. 분산형 분할 뷰 성능의 가장 중요한 측면은 멤버 서버 간에 전송되는 데이터의 양을 최소화하는 것입니다.
SQL Server는 분산 쿼리를 효율적으로 사용하여 원격 멤버 테이블의 데이터에 액세스하는 지능적이고 동적인 계획을 빌드합니다.
- 먼저 쿼리 프로세서는 OLE DB를 사용하여 각 멤버 테이블에서 check 제약 조건 정의를 검색합니다. 쿼리 프로세서는 이를 통해 멤버 테이블에 키 값을 분산하여 매핑할 수 있습니다.
- 쿼리 프로세서는 Transact-SQL 문
WHERE절에 지정된 키 범위를 멤버 테이블에 행이 배포되는 방식을 보여주는 맵과 비교합니다. 그런 다음, 쿼리 프로세서는 분산 쿼리를 사용하여 Transact-SQL 문을 완료하는 데 필요한 원격 행만 검색하는 쿼리 실행 계획을 작성합니다. 또한 데이터 또는 메타데이터에 대한 원격 멤버 테이블에 대한 액세스가 정보가 필요할 때까지 지연되는 방식으로 실행 계획이 빌드됩니다.
예를 들어 Customers 테이블이 Server1(CustomerID 1~3299999), Server2(CustomerID 3300000~6599999), Server3(CustomerID 6600000~9999999)에 걸쳐 분할되는 시스템을 고려합니다.
Server1에서 실행되는 이 쿼리에 대해 빌드된 실행 계획을 고려합니다.
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
이 쿼리에 대한 실행 계획은 로컬 멤버 테이블에서 CustomerID 키 값이 3200000~3299999인 행을 추출하고 Server2에서 키 값이 3300000~3400000인 행을 검색하는 분산 쿼리를 실행합니다.
또한 SQL Server 쿼리 프로세서는 실행 계획이 작성되어야 할 때 키 값이 알려지지 않은 Transact-SQL 문에 대해 동적 논리를 쿼리 실행 계획으로 작성할 수 있습니다. 예를 들어 다음 저장 프로시저를 고려합니다.
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server에서는 프로시저가 실행될 때마다 @CustomerIDParameter 매개 변수에서 어떤 키 값을 제공하는지 예측할 수 없습니다. 키 값을 예측할 수 없으므로 쿼리 프로세서는 액세스해야 하는 멤버 테이블을 예측할 수도 없습니다. 이 경우를 처리하기 위해 SQL Server는 동적 필터라고 하는 조건부 논리가 있는 실행 계획을 빌드하여 입력 매개 변수 값에 따라 액세스되는 멤버 테이블을 제어합니다. Server1에서 GetCustomer 저장 프로시저가 실행되었다고 가정하면 실행 계획 논리는 다음과 같이 표시될 수 있습니다.
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server에서는 매개 변수가 없는 쿼리에 대해서도 이러한 유형의 동적 실행 계획을 작성할 때가 있습니다. 쿼리 최적화 프로그램은 실행 계획을 다시 사용할 수 있도록 쿼리를 매개 변수화할 수 있습니다. 쿼리 최적화 프로그램이 분할된 뷰를 참조하는 쿼리를 매개 변수화하는 경우 쿼리 최적화 프로그램에서는 지정된 기본 테이블에서 필요한 행이 나오는 것으로 간주하지 않게 됩니다. 그런 다음 실행 계획에서 동적 필터를 사용해야 합니다.
저장 프로시저 및 트리거 실행
SQL Server는 저장 프로시저 및 트리거의 원본만 저장합니다. 저장 프로시저 또는 트리거가 처음 실행되면 원본이 실행 계획으로 컴파일됩니다. 실행 계획이 메모리에서 에이징되기 전에 저장 프로시저나 트리거가 다시 실행되는 경우 관계형 엔진은 기존 계획을 검색하고 다시 사용합니다. 계획이 메모리가 부족하면 새 계획이 빌드됩니다. 이 프로세스는 SQL Server에서 모든 Transact-SQL 문에 대해 수행하는 프로세스와 유사합니다. 성능 면에서 동적 Transact-SQL의 일괄 처리와 비교했을 때 SQL Server에서 저장 프로시저와 트리거의 주요 이점은 Transact-SQL 문이 항상 동일하다는 것입니다. 따라서 관계형 엔진은 기존 실행 계획과 쉽게 일치합니다. 저장 프로시저 및 트리거 계획은 쉽게 재사용됩니다.
저장 프로시저 및 트리거에 대한 실행 계획은 저장 프로시저를 호출하거나 트리거를 실행하는 일괄 처리에 대한 실행 계획과 별도로 실행됩니다. 따라서 저장 프로시저와 트리거 실행 계획을 더 많이 다시 사용할 수 있습니다.
실행 계획 캐싱 및 다시 사용
SQL Server에는 실행 계획과 데이터 버퍼를 모두 저장하는 데 사용되는 메모리 풀이 있습니다. 실행 계획 또는 데이터 버퍼에 할당된 풀의 비율은 시스템 상태에 따라 동적으로 변동합니다. 실행 계획을 저장하는 데 사용되는 메모리 풀 부분을 계획 캐시라고 합니다.
계획 캐시에는 컴파일된 모든 계획에 대해 두 개의 저장소가 있습니다.
- 지속형 개체(저장 프로시저, 함수, 트리거)와 관련된 계획에 사용되는 Object Plans 캐시 저장소(OBJCP)입니다.
- 자동 매개 변수화, 동적 또는 준비된 쿼리와 관련된 계획에 사용되는 SQL Plans 캐시 저장소(SQLCP)입니다.
아래 쿼리는 다음 두 캐시 저장소의 메모리 사용량에 대한 정보를 제공합니다.
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
참고 항목
계획 캐시에는 계획을 저장하는 데 사용되지 않는 두 개의 추가 저장소가 있습니다.
- 뷰, 제약 조건, 기본값에 대한 계획 컴파일 중에 사용되는 데이터 구조에 사용되는 바인딩된 트리 캐시 저장소(PHDR)입니다. 이러한 구조를 바운드 트리 또는 대수 트리라고합니다.
- Transact-SQL 문을 사용하지 않고 DLL을 사용하여 정의되는
sp_executeSql또는xp_cmdshell같이 미리 정의된 시스템 프로시저에 사용되는 확장 저장 프로시저 캐시 저장소(XPROC). 캐시된 구조체에는 프로시저가 구현되는 함수 이름과 DLL 이름만 포함됩니다.
SQL Server 실행 계획은 다음으로 구성됩니다.
컴파일된 계획(또는 쿼리 계획)
컴파일 프로세스에서 생성되는 쿼리 계획은 대부분 모든 수의 사용자가 사용하는 재입력 읽기 전용 데이터 구조입니다. 다음 정보를 저장합니다.논리 연산자가 설명하는 연산을 구현하는 물리 연산자입니다.
데이터에 액세스, 필터링 및 집계되는 순서를 결정하는 이러한 연산자의 순서입니다.
연산자를 통해 흐르는 예상 행 수입니다.
참고 항목
최신 버전의 데이터베이스 엔진 카디널리티 추정에 사용된 통계 개체에 대한 정보도 저장됩니다.
worktables 또는
tempdb의 작업 파일 같이 만들어야 하는 지원 개체입니다. 쿼리 계획에 사용자 컨텍스트 또는 런타임 정보가 저장되지 않습니다. 메모리에는 쿼리 계획의 복사본이 하나 또는 두 개 이상 없습니다. 즉, 모든 직렬 실행에 대한 복사본 하나와 모든 병렬 실행에 대한 복사본이 하나 이상 있습니다. 병렬 복사는 병렬 처리 정도에 관계없이 모든 병렬 실행을 포함합니다.
실행 컨텍스트
현재 쿼리를 실행 중인 각 사용자에게는 매개 변수 값과 같이 실행과 관련된 데이터를 보유하는 데이터 구조가 있습니다. 이 데이터 구조를 실행 컨텍스트라고 합니다. 실행 컨텍스트 데이터 구조는 다시 사용되지만 해당 콘텐츠는 다시 사용되지 않습니다. 다른 사용자가 동일한 쿼리를 실행하는 경우 데이터 구조가 새 사용자를 위한 컨텍스트로 다시 초기화됩니다.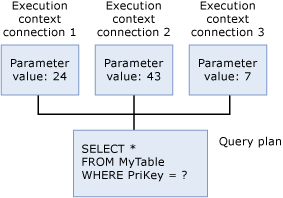
SQL Server에서 Transact-SQL 문을 실행할 때 데이터베이스 엔진은 먼저 계획 캐시를 조사하여 동일한 Transact-SQL 문에 대해 기존 실행 계획이 있는지 확인합니다. Transact-SQL 문은 문자 그대로 문자당 캐시된 계획 및 문자 하나와 이전에 실행된 Transact-SQL 문이 일치하는 경우 존재하는 것으로 규정합니다. 기존 계획을 찾으면 SQL Server는 그것을 재사용하기 때문에 Transact-SQL 문을 다시 컴파일하기 위한 오버헤드가 발생하지 않습니다. 기존의 실행 계획이 없는 경우 SQL Server에서 쿼리에 대해 새로운 실행 계획이 생성됩니다.
참고 항목
rowstore에서 실행 중인 대량 작업 명령문이나 크기가 8KB를 넘는 문자열 리터럴이 포함된 문과 같은 일부 Transact-SQL 문의 실행 계획은 일부 문은 계획 캐시에서 지속되지 않습니다. 이러한 계획은 쿼리가 실행되는 동안에만 존재합니다.
SQL Server에는 특정 Transact-SQL 문에 대한 기존 실행 계획을 찾는 효율적인 알고리즘이 있습니다. 대부분의 시스템에서 이러한 검색에 사용되는 최소 리소스는 모든 Transact-SQL 문을 컴파일하는 대신 기존 계획을 다시 사용함으로써 절약되는 리소스보다도 적습니다.
계획 캐시에서 사용되지 않는 기존 실행 계획과 새 Transact-SQL 문을 대응시키는 알고리즘을 적용하려면 모든 개체 참조가 정규화되어야 합니다. 예를 들어 Person이 아래 SELECT 문을 실행하는 사용자의 기본 스키마라고 가정합니다. 이 예제에서는 Person 테이블이 정규화되어 실행될 필요는 없으며, 두 번째 문은 기존 계획과 일치하지 않지만 세 번째 문은 일치한다는 의미입니다.
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
지정된 실행에 대해 다음 SET 옵션을 변경하면 데이터베이스 엔진 상수 폴딩을 수행하고 이러한 옵션은 이러한 식의 결과에 영향을 주므로 계획을 다시 사용하는 기능에 영향을 줍니다.
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
동일한 쿼리의 여러 계획 캐싱
쿼리 및 실행 계획은 지문처럼 데이터베이스 엔진에서 고유하게 식별할 수 있습니다.
- 쿼리 계획 해시는 지정된 쿼리의 실행 계획에서 계산되고 유사한 실행 계획을 고유하게 식별하는 데 사용되는 이진 해시 값입니다.
- 쿼리 해시는 쿼리의 Transact-SQL 텍스트에서 계산되는 이진 해시 값으로, 쿼리를 고유하게 식별하는 데 사용됩니다.
계획이 캐시에 남아 있는 동안에만 일정하게 유지되는 임시 식별자인 계획 핸들을 사용하여 계획 캐시에서 컴파일된 계획을 검색할 수 있습니다. 계획 핸들은 전체 일괄 처리의 컴파일된 계획에서 파생된 해시 값입니다. 일괄 처리에서 하나 이상의 문이 다시 컴파일되더라도 컴파일된 계획에 대한 계획 핸들은 동일하게 유지됩니다.
참고 항목
단일 문 대신 일괄 처리에 대해 계획을 컴파일한 경우 계획 핸들 및 문 오프셋을 사용하여 일괄 처리의 개별 문에 대한 계획을 검색할 수 있습니다.
sys.dm_exec_requests DMV에는 현재 실행 중인 일괄 처리 또는 영구적 개체의 현재 실행 문을 참조하는 각 레코드에 대한 statement_start_offset 열과 statement_end_offset 열이 포함됩니다. 자세한 내용은 sys.dm_exec_requests(Transact-SQL)을 참조하세요.
sys.dm_exec_query_stats DMV는 일괄 처리 또는 지속형 개체 내에서 문의 위치를 참조하는 각 레코드의 해당 열도 포함합니다. 자세한 내용은 dm_exec_query_stats(Transact-SQL)를 참조하세요.
일괄 처리의 실제 Transact-SQL 텍스트는 SQL 관리자 캐시(SQLMGR)라는 계획 캐시의 별도 메모리 공간에 저장됩니다. 식별자를 참조하는 하나 이상의 계획이 계획 캐시에 남아 있는 동안에만 일정하게 유지되는 임시 식별자인 SQL 핸들을 사용하여 SQL 관리자 캐시에서 컴파일된 계획의 Transact-SQL 텍스트는 검색할 수 있습니다. SQL 핸들은 전체 일괄 처리 텍스트에서 파생되는 해시 값이며 모든 일괄 처리에서 고유하게 됩니다.
참고 항목
컴파일된 계획처럼 Transact-SQL 텍스트는 주석을 포함하여 일괄 처리별로 저장됩니다. SQL 핸들은 전체 일괄 처리 텍스트의 MD5 해시이며 모든 일괄 처리에서 고유하게 됩니다.
아래 쿼리는 sql 관리자 캐시의 메모리 사용량에 대한 정보를 제공합니다.
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
SQL 핸들과 계획 핸들 사이에는 1:N 관계가 있습니다. 이러한 조건은 컴파일된 계획의 캐시 키가 다른 경우에 발생합니다. 이 문제는 동일한 일괄 처리의 두 실행 간에 SET 옵션이 변경되어 발생할 수 있습니다.
다음과 같은 저장 프로시저가 있다고 가정합니다.
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
아래 쿼리를 사용하여 계획 캐시에서 찾을 수 있는 항목을 확인합니다.
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
결과 집합은 다음과 같습니다.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
이제 실행 컨텍스트는 변경하지 않지만 다른 매개 변수를 사용하여 저장 프로시저를 실행합니다.
EXEC usp_SalesByCustomer 8
GO
계획 캐시에서 찾을 수 있는 내용을 다시 확인합니다. 결과 집합은 다음과 같습니다.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
usecounts은 실행 컨텍스트 데이터 구조가 재사용되었기 때문에 캐시된 계획이 그대로 재사용되었음을 의미하는 2로 증가했습니다. 이제 SET ANSI_DEFAULTS 옵션을 변경하고 동일한 매개 변수를 사용하여 저장 프로시저를 실행합니다.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
계획 캐시에서 찾을 수 있는 내용을 다시 확인합니다. 결과 집합은 다음과 같습니다.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
이제 sys.dm_exec_cached_plans DMV 출력에 두 개의 항목이 있습니다.
usecounts열에는SET ANSI_DEFAULTS OFF를 사용하여 한 번 실행된 계획인 첫 번째 레코드의1값이 표시됩니다.usecounts열에는 두 번 실행되었기 때문에SET ANSI_DEFAULTS ON을 사용하여 실행된 계획인 두 번째 레코드의2값이 표시됩니다.- 다른
memory_object_address는 계획 캐시의 다른 실행 계획 항목을 참조합니다. 그러나 두 항목 모두 동일한 일괄 처리를 참조하므로 두 항목의sql_handle값은 동일합니다.ANSI_DEFAULTS가 OFF로 설정된 실행은 새로운plan_handle을 포함하며 동일한 SET 옵션 세트가 포함된 호출에 다시 사용될 수 있습니다. 변경된 SET 옵션으로 인해 실행 컨텍스트가 다시 초기화되었으므로 새 계획 핸들이 필요합니다. 그러나 다시 컴파일을 트리거하지 않습니다. 동일한query_plan_hash및query_hash값에서 알 수 있듯이 두 항목은 모두 동일한 계획 및 쿼리를 참조합니다.
이는 동일한 일괄 처리에 해당하는 두 개의 계획 항목이 캐시에 있음을 의미하며, 계획 다시 사용에 맞게 최적화하고 계획 캐시 크기를 필요한 최솟값으로 유지하기 위해 동일한 쿼리를 반복해서 실행하는 경우 SET 옵션에 영향을 주는 계획 캐시가 동일한지 확인하는 것의 중요성을 강조합니다.
팁
일반적인 문제는 여러 클라이언트가 SET 옵션에 대해 서로 다른 기본값을 가질 수 있다는 것입니다. 예를 들어 SQL Server Management Studio를 통한 연결은 QUOTED_IDENTIFIER가 자동으로 ON으로 설정되지만 SQLCMD는 QUOTED_IDENTIFIER가 OFF로 설정됩니다. 이러한 두 클라이언트에서 동일한 쿼리를 실행하면 위의 예제에 설명된 대로 여러 계획이 생성됩니다.
계획 캐시에서 실행 계획 제거
실행 계획은 이를 저장하기에 충분한 메모리가 있는 한 계획 캐시에 계속 남아 있습니다. 메모리의 여유가 많지 않으면 SQL Server 데이터베이스 엔진에서는 비용을 기반으로 한 방법을 사용하여 계획 캐시에서 어떤 실행 계획을 제거할지 결정합니다. 비용 기반 결정을 내리기 위해 SQL Server 데이터베이스 엔진이 다음 요인에 따라 각 실행 계획에 대한 현재 비용 변수를 늘리고 줄입니다.
사용자 프로세스에서 캐시에 실행 계획을 삽입하는 경우 현재 비용을 원래 쿼리 컴파일 비용과 같게 설정하고, 임시 실행 계획의 경우 사용자 프로세스에서 현재 비용을 0으로 설정합니다. 그 후 사용자 프로세스가 실행 계획을 참조할 때마다 현재 비용을 원래 컴파일 비용으로 다시 설정합니다. 임시 실행 계획의 경우 사용자 프로세스로 현재 비용이 증가합니다. 모든 계획의 경우 현재 비용의 최대값은 원래 컴파일 비용입니다.
메모리 압력이 있는 경우 SQL Server 데이터베이스 엔진 계획 캐시에서 실행 계획을 제거하여 응답합니다. 제거할 계획을 결정하기 위해 SQL Server 데이터베이스 엔진이 각 실행 계획의 상태를 반복적으로 검사하고 현재 비용이 0이면 계획을 제거합니다. 메모리가 부족하다는 이유만으로는 현재 비용이 0인 실행 계획이 자동으로 제거되지 않습니다. SQL Server 데이터베이스 엔진에서 계획을 조사하여 현재 비용이 0이라는 사실을 확인했을 때만 해당 계획이 제거됩니다. 실행 계획을 검사할 때 SQL Server 데이터베이스 엔진은 쿼리가 현재 계획을 사용하지 않는 경우 현재 비용을 줄여 현재 비용을 0으로 푸시합니다.
SQL Server 데이터베이스이 엔진 메모리 요구 사항을 충족하기 위해 충분히 제거될 때까지 실행 계획을 반복적으로 검사합니다. 그 결과로 메모리가 부족한 상태에서 실행 계획의 비용이 여러 차례에 걸쳐 증감할 수 있습니다. 충분한 메모리가 다시 확보되면 SQL Server 데이터베이스 엔진에서는 사용되지 않는 실행 계획의 현재 비용을 더 이상 줄이지 않으며 해당 비용이 0인 계획을 포함한 모든 실행 계획이 계획 캐시에 계속 남습니다.
SQL Server 데이터베이스 엔진에서는 리소스 모니터와 사용자 작업자 스레드를 사용하여 계획 캐시에서 메모리를 확보하여 메모리 부족 문제에 대처합니다. 리소스 모니터 및 사용자 작업자 스레드는 계획 실행을 동시에 검사하여 사용되지 않는 각 실행 계획에 대한 현재 비용을 줄일 수 있습니다. 전체적인 메모리 부족 현상이 발생하면 리소스 모니터를 통해 계획 캐시에서 실행 계획이 제거됩니다. 메모리를 해제하여 시스템 메모리, 프로세스 메모리, 리소스 풀 메모리 및 모든 캐시의 최대 크기에 대한 정책을 적용합니다.
모든 캐시의 최대 크기는 버퍼 풀 크기에 따라 결정되며 최대 서버 메모리를 초과할 수 없습니다. 최대 서버 메모리를 구성하는 방법에 대한 자세한 내용은 sp_configure의 max server memory 설정을 참조하세요.
단일 캐시 메모리 압력이 있는 경우 사용자 작업자 스레드는 계획 캐시에서 실행 계획을 제거합니다. 최대 단일 캐시 크기 및 최대 단일 캐시 항목에 대한 정책을 적용합니다.
다음 예제에서는 계획 캐시에서 제거되는 실행 계획을 보여줍니다.
- 실행 계획은 비용이 0으로 이동하지 않도록 자주 참조됩니다. 메모리가 부족하지 않고 현재 비용이 0이 아닌 경우 계획이 계획 캐시에 남아 있고 제거되지 않습니다.
- 임시 실행 계획이 삽입되고 메모리 압력이 존재하기 전에 다시 참조되지 않습니다. 임시 계획은 현재 비용이 0으로 초기화되므로 SQL Server 데이터베이스 엔진에서 실행 계획을 검사하면 현재 비용이 0으로 표시되고 계획 캐시에서 계획이 제거됩니다. 임시 실행 계획은 메모리 압력이 없을 때 현재 비용이 0인 계획 캐시에 유지됩니다.
단일 계획이나 모든 계획을 캐시에서 수동으로 제거하려면 DBCC FREEPROCCACHE를 사용하세요. DBCC FREESYSTEMCACHE를 사용하여 계획 캐시를 비롯한 모든 캐시를 지울 수도 있습니다. SQL Server 2016(13.x)부터 ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE를 사용하여 범위 내 데이터베이스의 프로시저(계획) 캐시를 지울 수 있습니다.
또한 sp_configure 및 다시 구성을 통해 일부 구성 설정을 변경하면 계획 캐시에서 계획이 제거됩니다. 구성 설정 목록은 DBCC FREEPROCCACHE 문서의 설명 섹션에서 확인할 수 있습니다. 이와 같은 구성 변경은 오류 로그에 다음 정보 메시지를 기록합니다.
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
실행 계획 다시 컴파일
데이터베이스의 특정 변경 내용으로 인해 데이터베이스의 새 상태에 따라 실행 계획이 비효율적이거나 유효하지 않을 수 있습니다. SQL Server는 실행 계획을 무효화하는 변경 내용을 검색하고 계획을 유효하지 않은 것으로 표시합니다. 그런 다음 쿼리를 실행하는 다음 연결에 대해 새 계획을 다시 컴파일해야 합니다. 계획을 무효화하는 조건은 다음과 같습니다.
- 쿼리에서 참조하는 테이블이나 뷰가 변경된 경우(
ALTER TABLE및ALTER VIEW). - 단일 프로시저를 변경하여 해당 프로시저에 대한 모든 계획을 캐시(
ALTER PROCEDURE)에서 삭제합니다. - 실행 계획에 사용되는 인덱스가 변경된 경우
- 실행 계획에서 사용하는 통계에 대한 업데이트로, 문(예:
UPDATE STATISTICS)에서 명시적으로 생성되거나 자동으로 생성됩니다. - 실행 계획에 사용되는 인덱스가 삭제된 경우
sp_recompile에 대한 명시적 호출입니다.- 키에 대한 많은 변경 내용(쿼리에서 참조하는 테이블을 수정하는 다른 사용자의
INSERT문 또는DELETE문에서 생성됨). - 트리거가 있는 테이블에서 삽입되거나 삭제된 테이블의 행 수가 크게 증가하는 경우
WITH RECOMPILE옵션을 사용하여 저장 프로시저를 실행합니다.
문 정확성을 위해 또는 잠재적으로 더 빠른 쿼리 실행 계획을 얻기 위해서는 대부분 다시 컴파일해야 합니다.
2005 이전 SQL Server 버전에서는 일괄 처리 내의 문이 다시 컴파일을 발생시킬 때마다 저장 프로시저, 트리거, 임시 일괄 처리 또는 준비된 문을 통해 제출되었는지와 관계없이 전체 일괄 처리가 다시 컴파일됩니다. SQL Server 2005(9.x)부터 다시 컴파일을 트리거하는 일괄 처리 내의 문만 다시 컴파일됩니다. 또한 SQL Server 2005(9.x) 이상 버전에서는 기능 집합이 확장되어 더 많은 다시 컴파일 유형을 제공합니다.
대부분의 경우 적은 수의 문이 CPU 시간 및 잠금 측면에서 다시 컴파일 및 관련 처벌을 유발하기 때문에 문 수준 다시 컴파일은 성능에 이점을 제공합니다. 따라서 이러한 처벌은 다시 컴파일할 필요가 없는 일괄 처리의 다른 문에 대해 방지됩니다.
확장 이벤트(XEvent)는 sql_statement_recompile 문 수준 다시 컴파일을 보고합니다. 이 XEvent는 모든 종류의 일괄 처리에서 문 수준 다시 컴파일이 필요한 경우에 발생합니다. 여기에는 저장 프로시저, 트리거, 임시 일괄 처리, 쿼리가 포함됩니다. 일괄 처리는 sp_executesql 동적 SQL, Prepare 메서드 또는 Execute 메서드를 비롯한 여러 인터페이스를 통해 제출할 수 있습니다.
XEvent 열 sql_statement_recompile 에는 recompile_cause 다시 컴파일 이유를 나타내는 정수 코드가 포함되어 있습니다. 다음 표에는 다음과 같은 가능한 이유가 포함되어 있습니다.
스키마가 변경됨
통계 변경됨
컴파일이 지연됨
SET 옵션이 변경됨
임시 테이블이 변경됨
원격 행 집합 변경됨
FOR BROWSE 권한 변경됨
쿼리 알림 환경 변경됨
분할 뷰가 변경됨
커서 옵션 변경됨
OPTION (RECOMPILE) 요청됨
매개 변수가 있는 계획 플러시됨
데이터베이스 버전에 영향을 주는 계획 변경됨
쿼리 저장소 계획의 강제 정책 변경됨
쿼리 저장소 계획 강제 적용이 실패함
쿼리 저장소 계획 누락됨
참고 항목
XEvents를 사용할 수 없는 SQL Server 버전에서는 문 수준 다시 컴파일을 보고하는 동일한 목적으로 SQL Server Profiler SP:Recompile 추적 이벤트를 사용할 수 있습니다.
또한 추적 이벤트 SQL:StmtRecompile는 문 수준 다시 컴파일을 보고하며, 이 추적 이벤트를 사용하여 다시 컴파일을 추적하고 디버그할 수도 있습니다.
SP:Recompile이 저장 프로시저 및 트리거에 대해서만 생성하는 반면 SQL:StmtRecompile은 저장 프로시저, 트리거, 임시 일괄 처리, sp_executesql을 사용하여 실행한 일괄 처리, 준비된 쿼리 및 동적 SQL을 사용하여 실행되는 일괄 처리에 대해 생성합니다.
SP:Recompile 및 SQL:StmtRecompile의 EventSubClass 열에는 다시 컴파일할 이유를 나타내는 정수 코드가 들어 있습니다. 코드는 여기에 설명되어 있습니다.
참고 항목
AUTO_UPDATE_STATISTICS 데이터베이스 옵션을 ON로 설정하면 통계가 업데이트되었거나 마지막 실행 이후 카디널티가 크게 변경된 테이블 또는 인덱싱된 뷰를 대상으로 할 때 쿼리가 다시 컴파일됩니다.
이 동작은 표준 사용자 정의 테이블, 임시 테이블 및 DML 트리거에서 만든 삽입 및 삭제된 테이블에 적용됩니다. 과도한 재컴파일로 인해 쿼리 성능이 저하되면 이 설정을 OFF로 변경하세요. AUTO_UPDATE_STATISTICS 데이터베이스 옵션을 OFF로 설정하면 통계나 카디널리티 변경 내용에 따른 다시 컴파일은 발생하지 않습니다. 단, DML INSTEAD OF 트리거에 의해 생성되는 삽입 테이블과 삭제 테이블은 예외입니다. 두 테이블은 tempdb에 생성되므로 두 테이블에 액세스하는 쿼리의 다시 컴파일은 tempdb의 AUTO_UPDATE_STATISTICS 설정에 따라 결정됩니다.
2005 이전의 SQL Server에서는 이 설정이 OFF인 경우에도 DML 트리거에 의한 삽입 테이블과 삭제 테이블의 카디널리티 변경 사항에 따라 계속하여 쿼리가 다시 컴파일됩니다.
매개 변수 및 실행 계획 재사용
ADO, OLE DB 및 ODBC 애플리케이션의 매개 변수 마커를 포함한 매개 변수를 사용하면 실행 계획의 재사용이 증가할 수 있습니다.
Warning
매개 변수 또는 매개 변수 표식을 사용하여 최종 사용자가 입력한 값을 저장하는 것이 데이터 액세스 API 메서드, EXECUTE 문 또는 sp_executesql 저장 프로시저를 사용하여 실행되는 문자열에 값을 연결하는 것보다 더 안전합니다.
다음 두 SELECT 문 간의 유일한 차이점은 WHERE 절에서 비교되는 값입니다.
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
이러한 쿼리에 대한 실행 계획 간의 유일한 차이점은 ProductSubcategoryID 열을 비교할 때 저장되는 값이 다르다는 것입니다. SQL Server에서 항상 해당 명령문이 기본적으로 동일한 계획을 생성하고 그 계획을 재사용한다는 것을 인식하게 하려는 것이 목적이지만 때때로 SQL Server는 복잡한 Transact-SQL 문에서 이러한 사실을 탐지하지 못합니다.
매개 변수를 사용하여 Transact-SQL 문에서 상수를 분리하면 관계형 엔진이 중복된 계획을 인식하는 데 도움이 됩니다. 다음과 같은 방법으로 매개 변수를 사용할 수 있습니다.
Transact-SQL에서는
sp_executesql을 사용합니다.DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParm이 메서드는 동적으로 SQL 문을 생성하는 Transact-SQL 스크립트, 저장 프로시저 또는 트리거에 권장됩니다.
ADO, OLE DB, ODBC는 매개 변수 표식을 사용합니다. 매개 변수 표식은 SQL 문의 상수를 대체하고 프로그램 변수에 바인딩되는 물음표(?)입니다. 예를 들어 ODBC 애플리케이션에서 다음을 수행합니다.
SQL 문의 첫 번째 매개 변수 표식에 정수 변수를 바인딩하는 데 사용합니다
SQLBindParameter.정수 값을 변수에 저장합니다.
매개 변수 표식(?)을 지정하여 문을 실행합니다.
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
애플리케이션에서 매개 변수 표식을 사용하는 경우 SQL Server에 포함된 SQL Server Native Client OLE DB Provider와 SQL Server Native Client ODBC 드라이버는
sp_executesql을 사용하여 문을 SQL Server에 보냅니다.디자인에 따라 매개 변수를 사용하는 저장 프로시저를 디자인합니다.
애플리케이션 디자인에 매개 변수를 명시적으로 빌드하지 않으면 SQL Server 쿼리 최적화 프로그램으로 단순 매개 변수화의 기본 동작을 사용하여 특정 쿼리를 자동으로 매개 변수화할 수도 있습니다. 또는 쿼리 최적화 프로그램에서 ALTER DATABASE 문의 PARAMETERIZATION 옵션을 FORCED로 설정하여 데이터베이스의 모든 쿼리를 매개 변수화하는 것을 고려하도록 할 수 있습니다.
강제 매개 변수화를 사용하도록 설정하면 간단한 매개 변수화가 계속 발생할 수 있습니다. 예를 들어 강제 매개 변수화 규칙에 따라 다음 쿼리를 매개 변수화할 수 없습니다.
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
그러나 간단한 매개 변수화 규칙에 따라 매개 변수화할 수 있습니다. 강제 매개 변수화를 시도했지만 실패하면 간단한 매개 변수화가 계속 시도됩니다.
단순 매개 변수화
SQL Server에서는 Transact-SQL 문에 매개 변수 또는 매개 변수 표식을 사용하여 새 Transact-SQL 문을 이전에 컴파일된 기존의 실행 계획과 일치시키는 관계형 엔진의 성능을 향상시킵니다.
Warning
매개 변수 또는 매개 변수 표식을 사용하여 최종 사용자가 입력한 값을 저장하는 것이 데이터 액세스 API 메서드, EXECUTE 문 또는 sp_executesql 저장 프로시저를 사용하여 실행되는 문자열에 값을 연결하는 것보다 더 안전합니다.
매개 변수를 사용하지 않고 Transact-SQL 문이 실행되면 SQL Server는 내부적으로 해당 문을 매개 변수화하여 기존 실행 계획과 일치할 가능성을 높입니다. 이 프로세스를 단순 매개 변수화라고 합니다. 2005 이전의 SQL Server에서는 이 프로세스를 자동 매개 변수화라고 했습니다.
다음 문을 살펴보세요.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
문 끝에 있는 값 1을 매개 변수로 지정할 수 있습니다. 관계형 엔진은 값 1 대신 매개 변수가 지정된 것처럼 이 일괄 처리에 대한 실행 계획을 빌드합니다. 이 간단한 매개 변수화로 인해 SQL Server는 다음 두 문이 기본적으로 동일한 실행 계획을 생성한다는 것을 인식하고 두 번째 문에 대한 첫 번째 계획을 다시 사용합니다.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
복잡한 Transact-SQL 문을 처리할 때 관계형 엔진은 매개 변수화할 수 있는 식을 결정하기가 어려울 수 있습니다. 복잡한 Transact-SQL 문을 사용되지 않은 기존 실행 계획과 일치시키는 관계형 엔진의 성능을 향상하려면 sp_executesql 또는 매개 변수 표식을 사용하여 매개 변수를 명시적으로 지정합니다.
참고 항목
+, -, *, / 또는 % 산술 연산자는 int, smallint, tinyint 또는 bigint 상수 값을 float, real, decimal 또는 numeric 데이터 형식으로 암시적 또는 명시적으로 변환하는 경우 SQL Server에서 식 결과의 형식과 정밀도를 계산하는 특정 규칙을 적용합니다. 그러나 이러한 규칙은 쿼리가 매개 변수화되었는지 여부에 따라 다릅니다. 따라서 쿼리에서 유사한 식을 사용해도 다른 결과가 발생하는 경우가 있습니다.
SQL Server는 단순 매개 변수화의 기본 동작에 따라 비교적 작은 클래스의 쿼리를 매개 변수화합니다. 그러나 ALTER DATABASE 명령의 PARAMETERIZATION 옵션을 FORCED로 설정하여 특정 제한 사항에 따라 데이터베이스의 모든 쿼리를 매개 변수화하도록 지정할 수 있습니다. 이렇게 하면 쿼리 컴파일 빈도를 줄여 많은 양의 동시 쿼리를 경험하는 데이터베이스의 성능을 향상시킬 수 있습니다.
또는 단일 쿼리와 구문적으로 동일하지만 매개 변수 값에만 다른 다른 쿼리를 매개 변수화되도록 지정할 수 있습니다.
팁
EF(Entity Framework)와 같은 ORM(개체 관계형 매핑) 솔루션 사용 시, 수동 LINQ 쿼리 트리 또는 특정 원시 SQL 쿼리 같은 애플리케이션 쿼리는 매개 변수화되지 않을 수도 있습니다. 이로 인해 플랜 재사용 및 쿼리 저장소에서 쿼리를 추적하는 능력이 영향을 받게 됩니다. 자세한 내용은 EF 쿼리 캐싱 및 매개 변수화 및 EF 원시 SQL 쿼리를 참조하세요.
강제 매개 변수화
데이터베이스의 모든 SELECT, INSERT, UPDATE, DELETE 문이 특정 제한에 따라 매개 변수화되도록 지정하여 SQL Server의 기본 단순 매개 변수화 동작을 무시할 수 있습니다. ALTER DATABASE 문에서 PARAMETERIZATION 옵션을 FORCED로 설정하여 강제 매개 변수화를 사용하도록 설정합니다. 강제 매개 변수화는 쿼리 컴파일 및 재컴파일 빈도를 줄여 특정 데이터베이스의 성능을 향상시킬 수 있습니다. 강제 매개 변수화의 이점을 활용하는 데이터베이스는 일반적으로 판매 시점 애플리케이션과 같은 원본에서 대량의 동시 쿼리를 경험합니다.
PARAMETERIZATION 옵션을 FORCED로 설정하면 임의의 형식으로 전송된 SELECT, INSERT, UPDATE또는 DELETE 문에 표시되는 리터럴 값이 쿼리 컴파일 중에 매개 변수로 변환됩니다. 예외는 다음 쿼리 구문에 표시되는 리터럴입니다.
INSERT...EXECUTE문.- 저장 프로시저, 트리거 또는 사용자 정의 함수의 본문 내 문입니다. SQL Server는 이러한 루틴에 대한 쿼리 계획을 이미 다시 사용합니다.
- 클라이언트 쪽 애플리케이션에서 이미 매개 변수화된 준비된 문
- XQuery 메서드 호출이 포함된 문. 이러한 문에서는
WHERE절과 같이 해당 인수가 일반적으로 매개 변수화되는 컨텍스트에서 메서드가 나타납니다. 해당 인수가 매개 변수화되지 않는 컨텍스트에 메서드가 나타나면 나머지 문이 매개 변수화됩니다. - Transact-SQL 커서 내의 문입니다. (API 커서 내의
SELECT문은 매개 변수화됩니다.) - 사용되지 않는 쿼리 구문입니다.
OFF으로 설정된ANSI_PADDING또는ANSI_NULLS의 컨텍스트에서 실행되는 모든 문입니다.- 매개 변수화에 적합한 2,097개 이상의 리터럴을 포함하는 문입니다.
- 변수를 참조하는 문(예:
WHERE T.col2 >= @bb). RECOMPILE쿼리 힌트를 포함하는 문.COMPUTE절을 포함하는 문.WHERE CURRENT OF절을 포함하는 문.
또한 다음 쿼리 절은 매개 변수화되지 않습니다. 이러한 경우 해당 절만 매개 변수화되지 않습니다. 동일한 쿼리 내의 다른 절은 강제 매개 변수화에 적합할 수 있습니다.
- 모든
SELECT문의 <select_list>. 여기에는SELECT의 하위 쿼리 목록과INSERT문 내의SELECT목록이 포함됩니다. IF문 내에 표시되는 하위 쿼리SELECT문입니다.- 쿼리의
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTO또는FOR XML절입니다. - 인수(직접 또는 하위 식으로
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXML또는FULLTEXT연산자)입니다. LIKE절의 패턴 및 escape_character 인수입니다.CONVERT절의 스타일 인수입니다.IDENTITY절 내의 정수 상수입니다.- ODBC 확장 구문을 사용하여 지정한 상수
+,-,*,/,%연산자의 인수인 상수 접이식 식입니다. 강제 매개 변수화에 대한 자격을 고려할 때 SQL Server는 다음 조건 중 하나가 충족되는 경우 식을 상수 폴딩 가능으로 간주합니다.- 식에 열, 변수 또는 하위 쿼리가 나타나지 않습니다.
- 식에
CASE절이 포함됩니다.
- 힌트 절을 쿼리하는 인수입니다. 여기에는
FAST쿼리 힌트의 number_of_rows 인수,MAXDOP쿼리 힌트의 number_of_processors 인수,MAXRECURSION쿼리 힌트의 number 인수가 포함됩니다.
매개 변수화는 개별 Transact-SQL 문의 수준에서 발생합니다. 즉, 일괄 처리의 개별 문이 매개 변수화됩니다. 컴파일 후 매개 변수가 있는 쿼리는 원래 제출된 일괄 처리의 컨텍스트에서 실행됩니다. 쿼리에 대한 실행 계획이 캐시된 경우 sys.syscacheobjects 동적 관리 뷰의 sql 열을 참조하여 쿼리가 매개 변수화되었는지 여부를 확인할 수 있습니다. 쿼리가 매개 변수화된 경우 @1 tinyint와 같이 이 열에서 매개 변수의 이름 및 데이터 형식은 전송된 일괄 처리 텍스트 앞에 옵니다.
참고 항목
매개 변수 이름은 임의입니다. 사용자 또는 애플리케이션은 특정 명명 순서에 의존해서는 안 됩니다. 또한 SQL Server 버전과 서비스 팩 업그레이드 간에 매개 변수 이름, 매개 변수가 있는 리터럴 선택 및 매개 변수가 있는 텍스트의 간격 간에 변경될 수 있습니다.
매개 변수의 데이터 형식
SQL Server에서 리터럴을 매개 변수화하면 매개 변수가 다음 데이터 형식으로 변환됩니다.
- 정수 리터럴은 그 크기가 int 데이터 형식에 적합하면 int로 매개 변수화됩니다. 비교 연산자와 관련된 조건자의 일부인 큰 정수 리터럴(
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEEN,IN포함)은 numeric(38,0)으로 매개 변수화됩니다. 비교 연산자와 관련된 조건자의 일부가 아닌 큰 리터럴은 전체 자릿수가 리터럴의 크기를 지원할 만큼 크고 소수 자릿수가 0인 numeric으로 매개 변수화됩니다. - 비교 연산자와 관련된 조건자의 일부가 아닌 고정 소수점 숫자 리터럴은 정밀도가 38이고 크기가 리터럴의 크기를 지원할 만큼 큰 numeric으로 매개 변수화됩니다. 비교 연산자와 관련된 조건자의 일부가 아닌 고정 소수점 숫자 리터럴은 전체 자릿수 및 소수 자릿수가 리터럴의 크기를 지원할 만큼 큰 numeric으로 매개 변수화됩니다.
- 부동 소수점 숫자 리터럴은 float(53)으로 매개 변수화됩니다.
- 비유니코드 문자열 리터럴은 리터럴의 크기가 8,000자 내일 때는 varchar(8000)로 매개 변수화되고 8,000자보다 클 때는 varchar(max)로 매개 변수화됩니다.
- 유니코드 문자열 리터럴은 리터럴의 크기가 유니코드 문자로 4,000자 내일 때는 nvarchar(4000)로 매개 변수화되고 4,000자보다 클 때는 nvarchar(max)로 매개 변수화됩니다.
- 이진 리터럴은 리터럴 크기가 8,000바이트 내일 때는 varbinary(8000)로 매개 변수화되고 8,000바이트보다 클 때는 varbinary(max)로 변환됩니다.
- 돈 유형 리터럴은 돈으로 매개 변수화됩니다.
강제 매개 변수화 사용에 대한 지침
FORCED로 PARAMETERIZATION 옵션을 설정할 때 다음을 고려합니다.
- 강제 매개 변수화를 적용하면 쿼리 컴파일 시 쿼리의 리터럴 상수가 매개 변수로 변경됩니다. 따라서 쿼리 최적화 프로그램은 쿼리에 대한 최적이 아니면 계획을 선택할 수 있습니다. 특히 쿼리 최적화 프로그램에서는 인덱싱된 뷰 또는 계산 열의 인덱스에 쿼리를 대응시키지 못할 수 있습니다. 분할된 테이블 및 분산 분할된 뷰에 대해 제기되는 쿼리에 대한 최적이 않은 계획을 선택할 수도 있습니다. 강제 매개 변수화는 계산 열에서 인덱싱된 뷰 및 인덱스에 크게 의존하는 환경에 사용하면 안 됩니다. 일반적으로
PARAMETERIZATION FORCED옵션은 숙련된 데이터베이스 관리자가 이 작업을 수행해도 성능에 부정적인 영향을 주지 않는다고 판단한 후에만 사용해야 합니다. - 둘 이상의 데이터베이스를 참조하는 분산 쿼리는 쿼리가 실행 중인 컨텍스트의 데이터베이스에서
PARAMETERIZATION옵션이FORCED로 설정된 경우 강제 매개 변수화에 적합합니다. PARAMETERIZATION옵션을FORCED로 설정하면 현재 컴파일되거나 다시 컴파일되거나 실행되고 있는 쿼리 계획을 제외한 모든 쿼리 계획이 데이터베이스의 계획 캐시에서 플러시됩니다. 설정 변경 중에 컴파일되거나 실행되는 쿼리에 대한 계획은 다음에 쿼리가 실행될 때 매개 변수화됩니다.PARAMETERIZATION옵션을 설정하는 작업은 온라인으로 수행되므로 데이터베이스 수준의 배타적 잠금이 필요하지 않습니다.PARAMETERIZATION옵션의 현재 설정은 데이터베이스를 다시 연결하거나 복원할 때 유지됩니다.
단일 쿼리에서 단순 매개 변수화를 시도하도록 지정하고 구문적으로 동일하지만 매개 변수 값에만 다른 다른 매개 변수화를 지정하여 강제 매개 변수화 동작을 재정의할 수 있습니다. 반대로 데이터베이스에서 강제 매개 변수화를 사용하지 않도록 설정한 경우에도 구문상 동등한 쿼리 집합에서만 강제 매개 변수화를 시도하도록 지정할 수 있습니다. 이와 같은 작업을 수행할 때계획 지침 을 사용합니다.
참고 항목
PARAMETERIZATION 옵션이 FORCED로 설정되어 있으면 오류 메시지 보고가 PARAMETERIZATION 옵션이 SIMPLE로 설정된 경우와 다를 수 있습니다. 단순 매개 변수화에서 보고되는 메시지가 적은 강제 매개 변수화에서는 많은 오류 메시지가 보고될 수 있으며 오류가 발생한 줄 번호가 잘못 보고될 수 있습니다.
SQL 문 준비
SQL Server 관계형 엔진에서는 실행하기 전에 Transact-SQL 문을 준비할 수 있는 기능을 제공합니다. 애플리케이션에서 Transact-SQL 문을 여러 번 실행해야 하는 경우에는 데이터베이스 API를 사용하여 다음을 수행할 수 있습니다.
- 문을 한 번 준비합니다. 이렇게 하면 Transact-SQL 문이 실행 계획으로 컴파일됩니다.
- 문을 실행해야 할 때마다 미리 컴파일한 실행 계획을 실행합니다. 이렇게 하면 첫 번째 실행 이후 실행할 때마다 Transact-SQL 문을 다시 컴파일할 필요가 없습니다. 문 준비 및 실행은 API 함수 및 메서드에 의해 제어됩니다. Transact-SQL 언어의 일부가 아닙니다. Transact-SQL 문 실행에 대한 준비/실행 모델은 SQL Server Native Client OLE DB 공급자 및 SQL Server Native Client ODBC 드라이버에 의해 지원됩니다. 준비 요청에서 공급자 또는 드라이버는 문을 준비하라는 요청과 함께 문을 SQL Server에 보냅니다. SQL Server는 실행 계획을 컴파일하고 해당 계획에 대한 핸들을 공급자 또는 드라이버에 반환합니다. 실행 요청 시, 공급자 또는 드라이버는 핸들과 관련된 계획의 실행 요청을 서버에 보냅니다.
준비된 문은 SQL Server에서 임시 개체를 만드는 데 사용할 수 없습니다. 준비된 문은 임시 테이블과 같은 임시 개체를 만드는 시스템 저장 프로시저를 참조할 수 없습니다. 이러한 프로시저는 직접 실행해야 합니다.
준비/실행 모델을 과도하게 사용하면 성능이 저하할 수 있습니다. 문이 한 번만 실행되는 경우 직접 실행은 서버로의 네트워크 왕복을 1회만 필요로 합니다. 한 번만 실행되는 Transact-SQL 문을 준비하고 실행하면 네트워크 왕복이 추가로 필요합니다. 즉 명령문을 준비하는 데 한 번, 명령문을 실행하는 데 한 번이 필요합니다.
매개 변수 표식이 사용되는 경우 문을 준비하는 것이 좀 더 효과적입니다. 예를 들어 애플리케이션이 때때로 AdventureWorks 샘플 데이터베이스에서 제품 정보를 검색하라는 메시지가 표시된다고 가정합니다. 애플리케이션에서 이 작업을 수행할 수 있는 방법에는 두 가지가 있습니다.
첫 번째 방법을 사용하여 애플리케이션은 요청된 각 제품에 대해 별도의 쿼리를 실행할 수 있습니다.
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
두 번째 방법을 사용하여 애플리케이션은 다음을 수행합니다.
매개 변수 표식(?)이 포함된 문을 준비합니다.
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;프로그램 변수를 매개 변수 표식에 바인딩합니다.
제품 정보가 필요할 때마다 바운드 변수를 키 값으로 채우고 문을 실행합니다.
두 번째 방법은 문이 세 번 이상 실행될 때 더 효율적입니다.
SQL Server에서는 준비/실행 모델이 직접 실행에 비해 성능상의 큰 이점이 없는데 이는 SQL Server에서 실행 계획을 재사용하기 때문입니다. SQL Server에는 현재 Transact-SQL 문을 동일한 Transact-SQL 문의 사전 실행을 위해 생성된 실행 계획과 일치시키기 위한 효율적인 알고리즘이 있습니다. 애플리케이션이 매개 변수 표식을 사용하여 여러 번 Transact-SQL 문을 실행하는 경우 SQL Server에서는 해당 계획이 계획 캐시에서 에이징되지 않는 이상 두 번째 실행부터는 첫 번째 실행의 실행 계획을 재사용합니다. 준비/실행 모델에는 여전히 다음과 같은 이점이 있습니다.
- 식별 핸들로 실행 계획을 찾는 것이 Transact-SQL 문을 기존 실행 계획과 비교하는 데 사용되는 알고리즘보다 더 효율적입니다.
- 애플리케이션은 실행 계획을 만드는 시기와 다시 사용할 시기를 제어할 수 있습니다.
- 준비/실행 모델은 이전 버전의 SQL Server를 비롯한 다른 데이터베이스로 이식 가능합니다.
매개 변수 민감도
"매개 변수 스니핑"으로도 알려진 매개 변수 민감도는 SQL Server가 컴파일 또는 다시 컴파일 중에 현재 매개 변수 값을 "스니핑"하고 쿼리 최적화 도구에 전달하여 잠재적으로 더 효율적인 쿼리 실행 계획을 생성하는 데 사용할 수 있는 프로세스를 나타냅니다.
컴파일 또는 재컴파일을 수행하는 동안 다음 유형의 일괄 처리에 대해 매개 변수 값을 검사합니다.
- 저장 프로시저
sp_executesql을 통해 제출된 쿼리- 준비된 쿼리
잘못된 매개 변수 스니핑 문제를 해결하는 방법에 대한 자세한 내용은 다음을 참조하세요.
- 매개 변수에 민감한 이슈를 조사하고 해결
- 매개 변수 및 실행 계획 재사용
- 매개 변수 중요한 계획 최적화
- Azure SQL 데이터베이스에서 매개 변수가 중요한 쿼리 실행 계획 문제를 사용하여 쿼리 문제 해결
- Azure SQL Managed Instance에서 매개 변수가 중요한 쿼리 실행 계획 문제를 사용하여 쿼리 문제 해결
참고 항목
RECOMPILE 힌트를 사용하는 쿼리의 경우 매개 변수 값과 지역 변수의 현재 값이 모두 검색됩니다. 검색된 값(매개 변수 및 지역 변수)은 RECOMPILE 힌트가 있는 문 바로 앞에 배치된 위치에 있는 값입니다. 특히 매개 변수의 경우 일괄 처리 호출과 함께 사용된 값은 검사하지 않습니다.
병렬 쿼리 처리
SQL Server는 둘 이상의 CPU(마이크로프로세서)가 있는 컴퓨터에 대해 쿼리 실행 및 인덱스 작업을 최적화하는 병렬 쿼리를 제공합니다. SQL Server는 여러 운영 체제 작업자 스레드를 사용하여 쿼리 또는 인덱스 작업을 병렬로 수행할 수 있으므로 작업을 빠르고 효율적으로 완료할 수 있습니다.
쿼리 최적화 중에 SQL Server는 병렬 실행의 이점을 얻을 수 있는 쿼리 또는 인덱스 작업을 찾습니다. 이러한 쿼리의 경우 SQL Server는 쿼리 실행 계획에 교환 연산자를 삽입하여 병렬 실행을 위해 쿼리를 준비합니다. 교환 연산자는 프로세스 관리, 데이터 재배포 및 흐름 제어를 제공하는 쿼리 실행 계획의 연산자입니다. Exchange 연산자에는 하위 형식으로 Distribute Streams, Repartition Streams, Gather Streams 논리 연산자가 포함되며, 그 중 하나 이상이 병렬 쿼리에 대한 쿼리 계획의 실행 계획 출력에 나타날 수 있습니다.
Important
특정 구문은 전체 실행 계획 또는 파트 또는 실행 계획에서 병렬 처리를 사용하는 SQL Server의 기능을 억제합니다.
병렬 처리를 억제하는 구문은 다음과 같습니다.
스칼라 UDF
스칼라 사용자 정의 함수에 대한 자세한 내용은 사용자 정의 함수 만들기를 참조하세요. SQL Server 2019(15.x)부터 SQL Server 데이터베이스 엔진에서는 이러한 함수를 인라인 처리하고 쿼리 처리 중에 병렬 처리 사용을 잠금 해제할 수 있습니다. 스칼라 UDF 인라인에 대한 자세한 내용은 SQL Database의 지능형 쿼리 처리를 참조하세요.원격 쿼리
원격 쿼리에 대한 자세한 내용은 실행 계획 논리 및 물리 연산자 참조를 참조하세요.동적 커서
커서에 대한 자세한 내용은 DECLARE CURSOR를 참조하세요.재귀 쿼리
재귀에 대한 자세한 내용은재귀 공용 테이블 식 정의 및 사용 지침 및 T-SQL의 재귀를 참조하세요.다중 문 테이블 반환 함수(MSTVF)
MSTVF에 대한 자세한 내용은 사용자 정의 함수 만들기(데이터베이스 엔진)를 참조하세요.TOP 키워드
자세한 내용은 TOP(Transact-SQL)을 참조하세요.
쿼리 실행 계획에는 병렬 처리가 사용되지 않은 이유를 설명하는 QueryPlan 요소의 NonParallelPlanReason 특성이 포함될 수 있습니다. 이 특성의 값은 다음과 같습니다.
| NonParallelPlanReason 값 | 설명 |
|---|---|
| MaxDOPSetToOne | 최대 병렬 처리 수준이 1로 설정됩니다. |
| EstimatedDOPIsOne | 예상 병렬 처리 수준은 1입니다. |
| NoParallelWithRemoteQuery | 원격 쿼리에는 병렬 처리가 지원되지 않습니다. |
| NoParallelDynamicCursor | 동적 커서에는 병렬 계획이 지원되지 않습니다. |
| NoParallelFastForwardCursor | 빠른 전방 커서에는 병렬 계획이 지원되지 않습니다. |
| NoParallelCursorFetchByBookmark | 책갈피로 가져오는 커서에는 병렬 계획이 지원되지 않습니다. |
| NoParallelCreateIndexInNonEnterpriseEdition | Enterprise가 아닌 버전에서는 병렬 인덱스 생성이 지원되지 않습니다. |
| NoParallelPlansInDesktopOrExpressEdition | Desktop 및 Express 버전에서는 병렬 계획이 지원되지 않습니다. |
| NonParallelizableIntrinsicFunction | 쿼리는 병렬 처리할 수 없는 내장 함수를 참조합니다. |
| CLRUserDefinedFunctionRequiresDataAccess | 데이터 액세스가 필요한 CLR UDF에는 병렬 처리가 지원되지 않습니다. |
| TSQLUserDefinedFunctionsNotParallelizable | 쿼리는 병렬 처리할 수 없는 T-SQL 사용자 정의 함수를 참조합니다. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | 테이블 변수 트랜잭션은 병렬 중첩 트랜잭션을 지원하지 않습니다. |
| DMLQueryReturnsOutputToClient | DML 쿼리는 클라이언트에 출력을 반환하며 병렬 처리할 수 없습니다. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | 단일 온라인 인덱스 빌드에 대해 지원되지 않는 직렬 및 병렬 계획의 혼합입니다. |
| CouldNotGenerateValidParallelPlan | 병렬 계획 확인이 실패하여 직렬로 장애 복구(failback)됩니다. |
| NoParallelForMemoryOptimizedTables | 참조된 메모리 내 OLTP 테이블에는 병렬 처리가 지원되지 않습니다. |
| NoParallelForDmlOnMemoryOptimizedTable | 메모리 내 OLTP 테이블에서 DML에 대해 병렬 처리가 지원되지 않습니다. |
| NoParallelForNativelyCompiledModule | 참조된 고유하게 컴파일된 모듈에는 병렬 처리가 지원되지 않습니다. |
| NoRangesResumableCreate | 다시 시작 가능한 만들기 작업에 대한 범위 생성에 실패했습니다. |
교환 연산자를 삽입하면 병렬 쿼리 실행 계획이 완성됩니다. 병렬 쿼리 실행 계획은 작업자 스레드를 여러 개 사용할 수 있습니다. 병렬이 아닌(직렬) 쿼리에서 사용하는 직렬 실행 계획은 해당 실행에 작업자 스레드를 하나만 사용합니다. 병렬 쿼리에서 사용되는 작업자 스레드의 실제 수는 쿼리 계획 실행 초기화 시 결정되며 계획의 복잡성과 병렬 처리 정도에 따라 결정됩니다.
DOP(병렬 처리 수준)에 따라 사용되는 최대 CPU 수가 결정됩니다. 사용되는 작업자 스레드 수를 의미하지는 않습니다. DOP 제한은 작업별로 설정됩니다. 요청별 또는 쿼리 제한별로 수행되지 않습니다. 즉, 병렬 쿼리 실행 중에 단일 요청은 스케줄러에 할당되는 여러 작업을 생성할 수 있습니다. 여러 작업을 동시에 실행하는 경우, 특정 쿼리 실행 지점에서 MAXDOP로 지정된 개수보다 많은 프로세서가 동시에 사용될 수 있습니다. 자세한 내용은 스레드 및 태스크 아키텍처 가이드를 참조하세요.
SQL Server 쿼리 최적화 프로그램은 다음 중 해당하는 조건이 있을 경우 병렬 실행 계획을 사용하지 않습니다.
- 직렬 실행 계획은 간단하거나 병렬 처리 설정에 대한 비용 임계값을 초과하지 않습니다.
- 직렬 실행 계획은 최적화 프로그램에서 탐색한 병렬 실행 계획보다 총 예상 하위 트리 비용이 낮습니다.
- 쿼리에는 병렬로 실행할 수 없는 스칼라 또는 관계형 연산자가 포함됩니다. 특정 연산자는 쿼리 계획의 한 섹션이 직렬 모드로 실행되도록 하거나 전체 계획이 직렬 모드로 실행되도록 할 수 있습니다.
참고 항목
병렬 계획의 총 예상 하위 트리 비용은 병렬 처리 설정에 대한 비용 임계값보다 낮을 수 있습니다. 이는 직렬 계획의 총 예상 하위 트리 비용이 이를 초과했으며 총 예상 하위 트리 비용이 낮은 쿼리 계획을 선택했음을 나타냅니다.
DOP(병렬 처리 수준)
SQL Server는 병렬 쿼리 실행 또는 DDL(인덱스 데이터 정의 언어) 작업의 각 인스턴스에 대해 최상의 병렬 처리 수준을 자동으로 검색합니다. 다음 조건에 따라 이 작업을 수행합니다.
SQL Server가 SMP(대칭적 다중 처리) 컴퓨터와 같이 둘 이상의 마이크로프로세서 또는 CPU가 있는 컴퓨터에서가 실행 중인지 여부. 둘 이상의 CPU가 있는 컴퓨터만 병렬 쿼리를 사용할 수 있습니다.
사용할 수 있는 작업자 스레드 수가 충분한지 여부. 각 쿼리 또는 인덱스 작업을 실행하려면 특정 수의 작업자 스레드가 필요합니다. 병렬 계획을 실행하려면 직렬 계획보다 더 많은 작업자 스레드가 필요하며, 병렬 처리 정도에 따라 필요한 작업자 스레드 수가 증가합니다. 특정 수준의 병렬 처리에 대한 병렬 계획의 작업자 스레드 요구 사항을 충족할 수 없는 경우 SQL Server 데이터베이스 엔진는 병렬 처리 수준을 자동으로 줄이거나 지정된 워크로드 컨텍스트에서 병렬 계획을 완전히 중단합니다. 그런 다음 직렬 계획(작업자 스레드 1개)을 실행합니다.
실행된 쿼리 또는 인덱스 작업의 형식입니다. 인덱스를 만들거나 다시 작성하거나, CPU 주기를 많이 사용하는 클러스터형 인덱스 및 쿼리를 삭제하는 인덱스 작업은 병렬 계획에 가장 적합한 후보입니다. 예를 들어 대형 테이블의 조인, 대규모 집계 및 대형 결과 집합의 정렬이 병렬 쿼리에 적절합니다. 트랜잭션 처리 애플리케이션에서 자주 발견되는 간단한 쿼리는 잠재적인 성능 향상보다 쿼리를 병렬로 실행하는 데 필요한 추가 조정을 찾습니다. 병렬 처리의 이점을 활용하는 쿼리와 도움이 되지 않는 쿼리를 구분하기 위해 SQL Server 데이터베이스 엔진 쿼리 또는 인덱스 작업을 실행하는 예상 비용을 병렬 처리 값에 대한 비용 임계값과 비교합니다. 적절한 테스트를 통해 다른 값이 워크로드 실행에 더 적합하다고 확인되는 경우 사용자들은 sp_configure를 사용하여 기본값 5를 변경할 수 있습니다.
처리할 행 수가 충분한지 여부입니다. 쿼리 최적화 프로그램에서 행 수가 부족하다고 판단하는 경우 행을 배포하기 위해 교환 연산자를 사용하지 않습니다. 따라서 연산자는 직렬로 실행됩니다. 직렬 계획에서 연산자를 실행하면 시작, 배포 및 조정 비용이 병렬 연산자 실행에 의해 달성된 이익을 초과하는 시나리오를 방지할 수 있습니다.
현재 분포 통계를 사용할 수있는지 여부입니다. 가장 높은 병렬 처리 수준을 사용할 수 없는 경우 병렬 계획이 중단되기 전에 하위 수준을 고려합니다. 예를 들어 뷰에 클러스터형 인덱스를 만들 때 클러스터형 인덱스가 아직 없으므로 배포 통계를 평가할 수 없습니다. 이 경우 SQL Server 데이터베이스 엔진은 이 인덱스 작업에는 가장 높은 병렬 처리 수준을 할당하지 않습니다. 그러나 정렬 및 검색과 같은 일부 연산자는 병렬 실행의 이점을 활용할 수 있습니다.
참고 항목
병렬 인덱스 작업은 SQL Server Enterprise, Developer 및 Evaluation 버전에서만 사용할 수 있습니다.
실행 시 SQL Server 데이터베이스 엔진 앞에서 설명한 현재 시스템 워크로드 및 구성 정보가 병렬 실행을 허용하는지 여부를 결정합니다. 병렬 실행이 보장되면 SQL Server 데이터베이스 엔진 최적의 작업자 스레드 수를 결정하고 병렬 계획의 실행을 해당 작업자 스레드에 분산합니다. 쿼리 또는 인덱스 작업이 병렬 실행을 위해 여러 작업자 스레드에서 실행되기 시작하면 작업이 완료될 때까지 동일한 수의 작업자 스레드가 사용됩니다. SQL Server 데이터베이스 엔진은 계획 캐시에서 실행 계획을 검색할 때마다 최적의 작업자 스레드 결정 수를 다시 검사합니다. 예를 들어 쿼리를 한 번 실행하면 직렬 계획을 사용할 수 있고, 나중에 동일한 쿼리를 실행하면 3개의 작업자 스레드를 사용하는 병렬 계획이 생성될 수 있으며, 세 번째 실행은 4개의 작업자 스레드를 사용하는 병렬 계획이 될 수 있습니다.
병렬 쿼리 실행 계획의 업데이트 및 삭제 연산자는 순차적으로 실행되지만 UPDATE 또는 DELETE 문의 WHERE 절은 병렬로 실행할 수 있습니다. 그러면 실제 데이터 변경 내용이 데이터베이스에 직렬로 적용됩니다.
SQL Server 2012(11.x)까지 삽입 연산자도 직렬로 실행됩니다. 그러나 INSERT 문의 SELECT 부분은 병렬로 실행될 수 있습니다. 그러면 실제 데이터 변경 내용이 데이터베이스에 직렬로 적용됩니다.
SQL Server 2014(12.x) 및 데이터베이스 호환성 수준 110부터 SELECT ... INTO 문을 병렬로 실행할 수 있습니다. 다른 형태의 삽입 연산자는 SQL Server 2012(11.x)에 대해 설명한 것과 동일한 방식으로 작동합니다.
그러나 SQL Server 2016(13.x) 및 데이터베이스 호환성 수준 130부터 힙 또는 CCI(클러스터형 columnstore 인덱스)에 삽입할 때 TABLOCK 힌트를 사용하여 INSERT ... SELECT 문을 병렬로 실행할 수 있습니다. 로컬 임시 테이블(# 접두사로 식별) 및 전역 임시 테이블(## 접두사로 식별)에 대한 삽입도 TABLOCK 힌트를 사용하여 병렬 처리에 사용할 수 있습니다. 자세한 내용은 INSERT(Transact-SQL)를 참조하세요.
정적 및 키 집합 기반 커서는 병렬 실행 계획으로 채울 수 있습니다. 그러나 동적 커서의 동작은 직렬 실행에서만 제공할 수 있습니다. 쿼리 최적화 프로그램은 동적 커서에 포함된 쿼리에 대해서는 항상 직렬 실행 계획을 생성합니다.
병렬 처리 수준 재정의
병렬 처리 수준은 병렬 계획 실행에 사용할 프로세서 수를 설정합니다. 이 구성은 다양한 수준에서 설정할 수 있습니다.
서버 수준, MAXDOP(최대 병렬 처리 수준) 서버 구성 옵션을 사용합니다.
적용 대상: SQL Server참고 항목
SQL Server 2019(15.x)에서는 설치하는 동안 MAXDOP 서버 구성 옵션을 설정하기 위한 자동 권장 사항이 도입되었습니다. 설정 사용자 인터페이스를 사용하여 권장 설정을 적용하거나 사용자 고유 값을 입력할 수 있습니다. 자세한 내용은 데이터베이스 엔진 구성 - MaxDOP 페이지를 참조하세요.
워크로드 수준, MAX_DOP Resource Governor 작업 그룹 구성 옵션을 사용합니다.
적용 대상: SQL Server데이터베이스 수준, MAXDOP 데이터베이스 범위 구성을 사용합니다.
적용 대상: SQL Server 및 Azure SQL 데이터베이스쿼리 또는 인덱스 문 수준, MAXDOP 쿼리 힌트 또는 MAXDOP 인덱스 옵션을 사용합니다. 예를 들어 MAXDOP 옵션을 사용하여 온라인 인덱스 작업 전용 프로세서 수를 늘리거나 줄여 제어할 수 있습니다. 이런 방법으로 인덱스 작업에 사용되는 리소스와 동시 사용자의 리소스 간에 균형을 유지할 수 있습니다.
적용 대상: SQL Server 및 Azure SQL 데이터베이스
최대 병렬 처리 수준 옵션을 0(기본값)으로 설정하면 SQL Server에서 사용 가능한 모든 프로세서(최대 64개)를 병렬 계획 실행에 사용할 수 있습니다. MAXDOP 옵션을 0으로 설정하면 SQL Server에서 64개 논리적 프로세서의 런타임 대상을 설정해도 필요한 경우 다른 값을 수동으로 설정할 수 있습니다. 쿼리 및 인덱스에 대해 MAXDOP를 0으로 설정하면 SQL Server에서 특정 쿼리 또는 인덱스에 대해 사용 가능한 모든 프로세서(최대 64개)를 병렬 계획 실행에 사용할 수 있습니다. MAXDOP는 모든 병렬 쿼리에 적용된 값이 아니라 병렬 처리에 적합한 모든 쿼리에 대한 임시 대상입니다. 즉, 런타임에 충분한 작업자 스레드를 사용할 수 없는 경우 쿼리가 MAXDOP 서버 구성 옵션보다 낮은 병렬 처리로 실행될 수 있습니다.
팁
자세한 내용은 서버, 데이터베이스, 쿼리 또는 힌트 수준에서MAXDOP 구성에 대한 MAXDOP 권장 사항 지침을 참조하세요.
병렬 쿼리 예제
다음 쿼리는 2000년 4월 1일부터 특정 분기에 주문한 수와 고객이 커밋된 날짜보다 늦게 받은 주문의 품목을 하나 이상 계산합니다. 이 쿼리는 각 주문의 우선 순위별로 그룹화되고 오름차순으로 정렬된 이러한 주문 수를 나열합니다.
이 예에서는 이론적인 테이블 및 열 이름을 사용합니다.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
다음 인덱스가 lineitem 및 orders 테이블에 정의되어 있다고 가정합니다.
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
다음은 위에 표시된 쿼리에 대해 생성될 수 있는 병렬 계획 중 하나입니다.
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
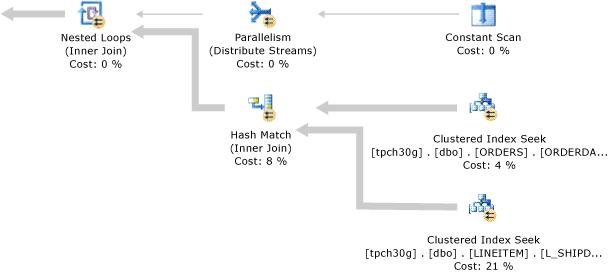
아래 일러스트레이션에서는 병렬 처리 수준이 4로 실행되고 두 개의 테이블 조인을 포함하는 쿼리 계획을 보여줍니다.
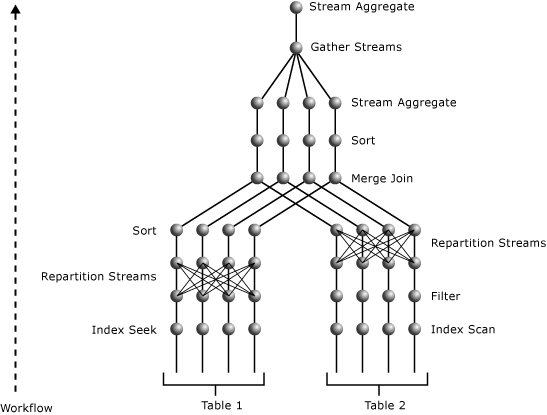
병렬 계획에는 세 개의 병렬 처리 연산자가 포함됩니다. o_datkey_ptr 인덱스의 Index Seek 연산자와 l_order_dates_idx 인덱스의 Index Scan 연산자 모두 병렬로 수행됩니다. 이렇게 하면 몇 가지 배타적 스트림이 생성됩니다. 이는 Index Scan 및 Index Seek 연산자 위에 있는 가장 가까운 Parallelism 연산자에 의해 각각 결정될 수 있습니다. 두 연산자는 모두 교환 유형을 다시 분할합니다. 즉, 스트림 간에 데이터를 다시 구성하고 입력과 동일한 수의 스트림을 출력에 생성합니다. 이 스트림 수는 병렬 처리 수준과 같습니다.
l_order_dates_idx Index Seek 연산자 위의 Parallelism 연산자는 L_ORDERKEY 값을 키로 사용하여 입력 스트림을 다시 분할합니다. 이러한 방식으로 동일한 L_ORDERKEY 값은 동일한 출력 스트림을 생성합니다. 동시에 출력 스트림은 병합 조인 연산자의 입력 요구 사항을 충족하기 위해 L_ORDERKEY 열의 순서를 유지 관리합니다.
Index Seek 연산자 위의 Parallelism 연산자는 O_ORDERKEY 값을 사용하여 입력 스트림을 다시 분할합니다. 이 입력은 O_ORDERKEY 열 값을 기준으로 정렬되지 않았으며 Merge Join 연산자를 통한 조인 열이므로 Parallelism 연산자와 Merge Join 연산자 사이에 있는 Sort 연산자가 Merge Join 연산자에 대한 입력을 조인 열을 기준으로 정렬합니다. Sort 연산자는 Merge Join 연산자처럼 병렬로 처리됩니다.
최상위 병렬 처리 연산자는 여러 스트림의 결과를 단일 스트림으로 수집합니다. 그런 다음 병렬 처리 연산자 아래에 있는 Stream Aggregate 연산자가 수행하는 부분 집계는 병렬 처리 연산자 위에 있는 Stream Aggregate 연산자의 각 다른 O_ORDERPRIORITY 값에 대해 단일 SUM 값으로 누적됩니다. 이 계획에는 병렬 처리 수준이 4인 두 개의 교환 세그먼트가 있으므로 8개의 작업자 스레드가 사용됩니다.
이 예제에 사용된 연산자에 대한 자세한 내용은 Showplan 논리 및 물리 연산자 참조를 참조하세요.
병렬 인덱스 작업
인덱스를 만들거나 다시 작성하는 인덱스 작업 또는 클러스터형 인덱스를 삭제하는 인덱스 작업을 위해 작성된 쿼리 계획에서는 여러 마이크로프로세서가 있는 컴퓨터에서 병렬 다중 작업자 스레드 작업을 할 수 있습니다.
참고 항목
병렬 인덱스 작업은 SQL Server 2008(10.0.x)부터 Enterprise Edition에서만 사용할 수 있습니다.
SQL Server는 동일한 알고리즘을 사용하여 다른 쿼리와 마찬가지로 인덱스 작업에 대한 병렬 처리 수준(실행할 개별 작업자 스레드의 총 수)을 결정합니다. 인덱스 작업에 대한 최대 병렬 처리 수준은 max degree of parallelism 서버 구성 옵션을 따릅니다. CREATE INDEX, ALTER INDEX, DROP INDEX, ALTER TABLE 문에 MAXDOP 인덱스 옵션을 지정하면 개별 인덱스 작업의 max degree of parallelism 값을 재정의할 수 있습니다.
SQL Server 데이터베이스 엔진에서 인덱스 실행 계획을 작성하는 경우 병렬 작업의 수는 다음 중에서 가장 낮은 값으로 설정됩니다.
- 컴퓨터의 마이크로프로세서의 수 또는 CPU의 수
- 최대 병렬 처리 서버 구성 옵션에 지정된 숫자입니다.
- SQL Server 작업자 스레드에 대해 수행된 작업의 임계값을 초과하지 않은 CPU의 수입니다.
예를 들어 8개의 CPU가 있으나 max degree of parallelism이 6으로 설정된 컴퓨터의 경우 인덱스 작업에 대해 생성될 수 있는 최대 병렬 작업자 스레드 수는 6개입니다. 인덱스 실행 계획을 작성할 때 컴퓨터에 있는 5개의 CPU가 SQL Server 작업의 임계값을 초과하는 경우 실행 계획은 3개의 병렬 작업자 스레드만 지정합니다.
병렬 인덱스 작업의 주요 단계는 다음과 같습니다.
- 조정 작업자 스레드는 신속하게 무작위로 테이블을 검색하여 인덱스 키의 분포를 예상합니다. 조정 작업자 스레드는 병렬 작업 수준과 동일한 여러 키 범위를 만드는 키 경계를 설정합니다. 여기서 각 키 범위는 비슷한 수의 행을 포함하도록 추정됩니다. 예를 들어 테이블에 4백만 개의 행이 있고 병렬 처리 정도가 4인 경우 조정 작업자 스레드는 각 집합에 1백만 개의 행이 있는 4개의 행 집합을 구분하는 키 값을 결정합니다. 모든 CPU를 사용하기에 충분한 키 범위를 설정할 수 없는 경우 그에 따라 병렬 처리 정도가 줄어듭니다.
- 조정 작업자 스레드는 병렬 작업 수준과 동일한 여러 작업자 스레드를 디스패치하고 이러한 작업자 스레드가 작업을 완료할 때까지 기다립니다. 각 작업자 스레드는 작업자 스레드에 할당된 범위 내에서 키 값이 있는 행만 검색하는 필터를 사용하여 기본 테이블을 검색합니다. 각 작업자 스레드는 키 범위의 행에 대한 인덱스 구조를 빌드합니다. 분할된 인덱스의 경우 각 작업자 스레드는 지정한 수만큼의 파티션을 작성합니다. 파티션은 작업자 스레드 간에 공유되지 않습니다.
- 모든 병렬 작업자 스레드가 완료된 후 조정 작업자 스레드는 인덱스 하위 단위를 단일 인덱스에 연결합니다. 이 단계는 오프라인 인덱스 작업에만 적용됩니다.
개별 CREATE TABLE 또는 ALTER TABLE 문에는 인덱스를 만들어야 하는 여러 제약 조건이 있을 수 있습니다. 각 개별 인덱스 만들기 작업은 여러 CPU가 있는 컴퓨터에서 병렬로 수행될 수 있지만 이러한 여러 인덱스 만들기 작업은 연속해서 수행됩니다.
분산 쿼리 아키텍처
Microsoft SQL Server는 Transact-SQL 문에서 다른 유형의 OLE DB 데이터 원본을 참조할 수 있도록 두 가지 메서드를 지원합니다.
연결된 서버 이름
시스템 저장 프로시저sp_addlinkedserver및sp_addlinkedsrvlogin는 OLE DB 데이터 원본에 서버 이름을 지정하는 데 사용됩니다. Transact-SQL 문에서는 4부분으로 된 이름을 사용하여 이러한 연결 서버의 개체를 참조할 수 있습니다. 예를 들어 연결된 서버 이름이DeptSQLSrvr인 SQL Server의 다른 인스턴스에 대해 정의된 경우 다음 문은 해당 서버의 테이블을 참조합니다.SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;또한 연결된 서버 이름은 OLE DB 데이터 원본에서 행 집합을 열도록
OPENQUERY문에 지정될 수 있습니다. 그런 다음 이 행 집합은 Transact-SQL 문의 테이블처럼 참조될 수 있습니다.임시 커넥터 이름
데이터 원본에 대한 자주 참조되지 않는 경우 연결된 서버에 연결하는 데 필요한 정보를 사용하여OPENROWSET또는OPENDATASOURCE함수를 지정합니다. 그런 다음 Transact-SQL 문에서 테이블을 참조하는 것과 동일한 방식으로 행 집합을 참조할 수 있습니다.SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server는 OLE DB를 사용하여 관계형 엔진과 스토리지 엔진 간에 통신합니다. 관계형 엔진은 각 Transact-SQL 문을 기본 테이블에서 스토리지 엔진이 연 간단한 OLE DB 행 집합에 대한 일련의 작업으로 나눕니다. 즉, 관계형 엔진은 모든 OLE DB 데이터 원본에서 간단한 OLE DB 행 집합을 열 수도 있습니다.
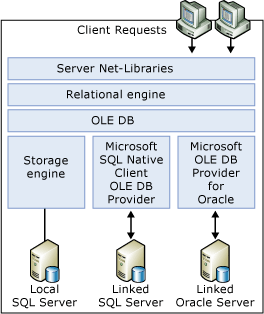
관계형 엔진은 OLE DB API(애플리케이션 프로그래밍 인터페이스)를 사용하여 연결된 서버에서 행 집합을 열고, 행을 가져오고, 트랜잭션을 관리합니다.
연결된 서버로 액세스되는 각 OLE DB 데이터 원본의 경우 SQL Server를 실행하는 서버에 OLE DB 공급자가 있어야 합니다. 특정 OLE DB 데이터 원본에 대해 사용할 수 있는 Transact-SQL 연산 집합은 OLE DB 공급자의 기능에 따라 다릅니다.
SQL Server의 각 인스턴스에 대해 sysadmin 고정 서버 역할의 멤버는 SQL Server DisallowAdhocAccess 속성을 사용하여 OLE DB 공급자에 대한 임시 커넥터 이름을 사용하거나 사용하지 않도록 설정할 수 있습니다. 임의 액세스가 활성화되어 있는 경우 해당 인스턴스에 로그온된 모든 사용자는 OLE DB 공급자를 사용하여 액세스할 수 있는 네트워크에서 데이터 원본을 참조하며 임의 커넥터 이름이 있는 Transact-SQL 문을 실행할 수 있습니다. 데이터 원본에 대한 액세스를 제어하기 위해 sysadmin 역할의 멤버는 해당 OLE DB 공급자에 대한 임시 액세스를 사용하지 않도록 설정하여 사용자가 관리자가 정의한 연결된 서버 이름으로 참조되는 데이터 원본으로만 제한할 수 있습니다. 기본적으로 SQL Server OLE DB 공급자에 대해 임시 액세스를 사용하도록 설정하고 다른 모든 OLE DB 공급자에 대해서는 사용하지 않도록 설정됩니다.
분산 쿼리를 사용하면 사용자가 SQL Server 서비스가 실행 중인 Microsoft Windows 계정의 보안 컨텍스트를 사용하여 다른 데이터 원본(예: 파일, Active Directory와 같은 비관계형 데이터 원본 등)에 액세스할 수 있습니다. SQL Server는 Windows 로그인에서는 적절하게 로그인을 가장하지만 SQL Server 로그인에서는 그렇지 못합니다. 이렇게 하면 사용 권한이 없는 다른 데이터 원본에 대한 액세스를 분산 쿼리 사용자에게 허용할 수 있지만 SQL Server 서비스가 실행 중인 계정에는 사용 권한이 없습니다. sp_addlinkedsrvlogin 을 사용하여 연결된 해당 서버에 액세스할 권한이 부여된 특정 로그인을 정의할 수 있습니다. 이 컨트롤은 임시 이름에 사용할 수 없으므로 임시 액세스를 위해 OLE DB 공급자를 사용하도록 설정하는 데 주의해야 합니다.
가능하면 SQL Server는 조인, 제한 사항, 프로젝션, 정렬 및 그룹화와 같은 관계형 작업을 OLE DB 데이터 원본에 푸시합니다. SQL Server는 기본적으로 기본 테이블을 검색하여 SQL Server에 전송한 후 자체적으로 관계형 연산을 수행하지는 않습니다. SQL Server는 OLE DB 공급자를 쿼리하여 지원하는 SQL 문법 수준을 확인하고, 해당 정보에 따라 가능한 한 많은 관계형 작업을 공급자에게 푸시합니다.
SQL Server는 OLE DB 공급자가 OLE DB 데이터 원본에서 키 값이 배포되는 방식을 나타내는 통계를 반환하기 위한 메커니즘을 지정합니다. 이렇게 하면 SQL Server 쿼리 최적화 프로그램은 각 Transact-SQL 문의 요구 사항에 대해 데이터 원본의 데이터의 패턴을 좀 더 잘 분석하므로 최적의 실행 계획을 생성하는 쿼리 최적화 프로그램의 기능을 향상시킬 수 있습니다.
분할된 테이블 및 인덱스의 쿼리 병렬 처리 개선 사항
SQL Server 2008(10.0.x)에서는 여러 병렬 계획에 대해 분할된 테이블에서의 쿼리 처리 성능을 향상시키고, 병렬 및 직렬 계획이 표시되는 방식을 변경하고, 컴파일 시간 및 런타임 실행 계획에 제공되는 분할 정보를 개선했습니다. 이 문서에서는 이러한 향상된 기능을 설명하고 분할된 테이블 및 인덱스의 쿼리 실행 계획을 해석하는 방법에 대한 지침을 제공하며 분할된 개체의 쿼리 성능을 개선하기 위한 모범 사례를 제공합니다.
참고 항목
SQL Server 2014(12.x)까지 분할된 테이블 및 인덱스는 SQL Server Enterprise, Developer 및 Evaluation 버전에서만 지원됩니다. SQL Server 2016(13.x) SP1부터 분할된 테이블 및 인덱스도 SQL Server Standard 버전에서 지원됩니다.
새 파티션 인식 검색 작업
SQL Server에서 분할된 테이블의 내부 표현이 변경되어 테이블이 쿼리 프로세서에 선행 열로 PartitionID가 포함된 다중 열 인덱스로 표시됩니다. PartitionID는 특정 행을 포함하는 파티션의 ID를 나타내기 위해 내부에서 사용하는 숨겨진 계산 열입니다. 예를 들어 T(a, b, c)로 정의되는 테이블은 a 열에서 분할되고 b 열에 클러스터형 인덱스가 있다고 가정합니다. SQL Server에서 이 분할된 테이블은 내부적으로 스키마 T(PartitionID, a, b, c)와 복합 키 (PartitionID, b)의 클러스터형 인덱스가 있는 분할되지 않은 테이블로 처리됩니다. 이렇게 하면 쿼리 최적화 프로그램에서 분할된 테이블 또는 인덱스의 PartitionID에 따라 검색 작업을 수행할 수 있습니다.
파티션 제거는 이제 이 검색 작업에서 수행됩니다.
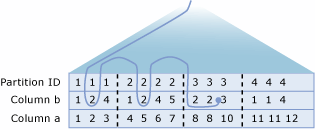
또한 쿼리 최적화 프로그램은 확장되므로 seek 또는 scan 연산이 한 가지 조건을 사용하여 PartitionID (논리적 선행 열)과 가능한 다른 인덱스 키 열에서 수행된 후, 두 번째 수준의 seek 연산은 다른 조건을 사용하여 첫 번째 수준의 seek 연산에 대한 제한을 충족시키는 각각의 고유 값에 대해 수행될 수 있습니다. 즉 skip scan이라고 하는 이 연산을 통해 쿼리 최적화 프로그램은 seek 또는 scan 연산을 하나의 조건을 기준으로 수행하여 액세스할 파티션을 결정하고 해당 연산자에서 두 번째 수준 index seek 연산을 수행하여 다른 조건을 충족시키는 이러한 파티션에서 행을 반환할 수 있습니다. 예를 들어 다음과 같은 쿼리를 고려해 보겠습니다.
SELECT * FROM T WHERE a < 10 and b = 2;
이 예에서 T(a, b, c)로 정의되는 T 테이블은 a 열에서 분할되고 b 열에 클러스터형 인덱스가 있다고 가정합니다. T 테이블의 파티션 경계는 다음 파티션 함수로 정의됩니다.
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
쿼리를 해결하기 위해 쿼리 프로세서는 조건 T.a < 10을 충족하는 행이 포함된 모든 파티션을 찾기 위해 첫 번째 수준 검색 작업을 수행합니다. 이렇게 하면 액세스할 파티션이 식별됩니다. 식별된 각 파티션 내에서 프로세서는 b열의 클러스터형 인덱스에 대한 두 번째 수준 검색을 수행하여 조건 T.b = 2 및 T.a < 10을 충족하는 행을 찾습니다.
다음 그림은 검색 건너뛰기 작업의 논리적 표현입니다. a 열과 b 열의 데이터와 함께 T 테이블을 보여줍니다. 파티션은 파선 세로선으로 표시되는 파티션 경계를 사용하여 1부터 4까지 번호가 매겨집니다. 파티션에 대한 첫 번째 수준 seek 연산(그림에는 표시되지 않음)에서는 파티션 1, 2 및 3이 a 열에 테이블 및 조건자에 대해 정의된 분할로 포함된 검색 조건을 충족시키는지 확인했습니다. 즉 T.a < 10입니다. 건너뛰기 검사 작업의 두 번째 수준 검색 부분으로 트래버스되는 경로는 곡선으로 표시됩니다. 기본적으로 검색 건너뛰기 작업은 b = 2 조건을 충족하는 행에 대해 이러한 각 파티션을 찾습니다. 검색 건너뛰기 작업의 총 비용은 세 개의 개별 인덱스 검색과 동일합니다.
쿼리 실행 계획에 분할 정보 표시
분할 테이블과 인덱스에서의 쿼리 실행 계획은 Transact-SQL SET 문 SET SHOWPLAN_XML 또는 SET STATISTICS XML을 사용하거나 Management Studio의 그래픽 실행 플랜 출력을 사용하여 검사할 수 있습니다. 예를 들어 쿼리 편집기 도구 모음에서 예상 실행 계획 표시를 선택하여 컴파일 시간 실행 계획을 표시할 수 있고 실제 실행 계획 포함을 선택하여 런타임 계획을 표시할 수 있습니다.
이러한 도구를 사용하여 다음 정보를 확인할 수 있습니다.
- 분할된 테이블 또는 인덱스에 액세스하는 작업(예:
scans,seeks,inserts,updates,merges,deletes)입니다. - 쿼리에서 액세스하는 파티션입니다. 예를 들어 액세스된 파티션의 총 수와 액세스되는 연속 파티션의 범위는 런타임 실행 계획에서 사용할 수 있습니다.
- 검색 또는 검색 작업에서 검색 건너뛰기 작업을 사용하여 하나 이상의 파티션에서 데이터를 검색하는 경우입니다.
향상된 파티션 정보 기능
SQL Server는 컴파일 시간 및 런타임 실행 계획 모두에 대해 향상된 분할 정보를 제공합니다. 이제 실행 계획에서 다음 정보를 제공합니다.
- 분할된 테이블에서
Partitioned,seek,scan,insert,update,merge같은 연산자가 실행되었음을 나타내는 선택적delete특성. - 선행 인덱스 키 열 및
PartitionID에 대한 범위 검색을 지정하는 필터 조건으로PartitionID을 포함하는SeekKeys하위 요소가 있는 새SeekPredicateNew요소입니다. 두SeekKeys하위 요소의 존재는PartitionID에서 건너뛰기 검사 작업이 사용됨을 나타냅니다. - 액세스된 파티션의 총 수를 제공하는 요약 정보입니다. 이 정보는 런타임 계획에서만 사용할 수 있습니다.
이 정보가 그래픽 실행 계획 출력과 XML 실행 계획 출력 모두에 표시되는 방법을 보여 주려면 분할된 테이블 fact_sales에서 다음 쿼리를 고려합니다. 이 쿼리는 두 파티션의 데이터를 업데이트합니다.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
다음 그림에서는 이 쿼리에 대한 런타임 실행 계획에서 Clustered Index Seek 연산자의 속성을 보여줍니다. fact_sales 테이블 및 파티션 정의의 정의를 보려면 이 문서의 "예제"를 참조하세요.

분할된 특성
인덱스 검색과 같은 연산자가 분할된 테이블 또는 인덱스에 실행되면 Partitioned 특성이 컴파일 시간 및 런타임 계획에 표시되고 True(1)로 설정됩니다. 이 특성이 False(0)로 설정되면 표시되지 않습니다.
Partitioned 특성은 다음과 같은 물리적 및 논리 연산자에서 나타날 수 있습니다.
- Table Scan
- Index Scan
- 인덱스 검색
- 삽입
- 엽데이트
- 삭제
- Merge
이전 그림과 같이 이 특성은 정의된 연산자의 속성에 표시됩니다. XML 실행 계획 출력에서 이 특성은 정의된 연산자의 RelOp 노드에 Partitioned="1"로 나타납니다.
새 검색 조건자
XML 실행 계획 출력에서 SeekPredicateNew 요소가 정의된 연산자에 나타납니다. 최대 두 번의 SeekKeys 하위 항목을 포함할 수 있습니다. 첫 번째 SeekKeys 항목은 논리적 인덱스의 파티션 ID 수준에 첫 번째 수준 seek 연산을 지정합니다. 즉, 이 검색은 쿼리 조건을 충족하기 위해 액세스해야 하는 파티션을 결정합니다. 두 번째 SeekKeys 항목은 첫 번째 수준 seek 연산자에서 식별된 각 파티션에서 발생하는 skip scan 연산의 두 번째 수준 seek 부분을 지정합니다.
파티션 요약 정보
런타임 실행 계획에서 파티션 요약 정보는 액세스된 파티션의 수와 액세스된 실제 파티션의 ID를 제공합니다. 이 정보를 사용하여 쿼리에서 올바른 파티션에 액세스하고 다른 모든 파티션이 고려 사항에서 제거되었는지 확인할 수 있습니다.
정보가 제공됩니다(Actual Partition Count 및 Partitions Accessed).
Actual Partition Count는 쿼리에서 액세스하는 총 파티션 수입니다.
Partitions Accessed는 XML 실행 계획 출력에서 정의된 연산자의 RelOp 노드에 있는 새 RuntimePartitionSummary 요소에 나타나는 파티션 요약 정보입니다. 다음 예제에서는 두 개의 총 파티션(파티션 2 및 3)에 액세스함을 나타내는 RuntimePartitionSummary 요소의 내용을 보여줍니다.
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
다른 실행 계획 메서드를 사용하여 파티션 정보 표시
실행 계획 메서드인 SHOWPLAN_ALL, SHOWPLAN_TEXT, STATISTICS PROFILE은 다음과 같은 경우를 제외하고 이 항목에서 설명한 파티션 정보를 보고하지 않습니다. SEEK 조건자의 일부로 액세스할 파티션은 파티션 ID를 나타내는 계산 열의 범위 조건자로 식별됩니다. 다음 예제에서는 SEEK 연산자의 Clustered Index Seek 조건자를 보여 줍니다. 파티션 2와 3에 액세스하고 검색 연산자는 date_id BETWEEN 20080802 AND 20080902 조건을 충족하는 행을 필터링합니다.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
분할된 힙에 대한 실행 계획 해석
분할된 힙이 파티션 ID의 논리적 인덱스로 취급됩니다. 분할된 힙에서의 파티션 제거는 파티션 ID의 Table Scan 조건자를 사용하는 SEEK 연산자로 실행 계획에 나타납니다. 다음 예제에서는 제공된 실행 계획 정보를 보여줍니다.
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
배치된 조인의 실행 계획 해석
같거나 상응하는 파티션 함수를 사용하여 두 개의 테이블이 분할되고 조인의 양쪽 면에서 분할 열을 사용하여 쿼리의 조인 조건에 되면 조인 콜러케이션이 발생합니다. 쿼리 최적화 프로그램은 동일한 파티션 ID가 있는 각 테이블의 파티션이 개별적으로 조인되는 계획을 생성할 수 있습니다. 배치된 조인은 메모리 및 처리 시간이 더 적게 필요할 수 있으므로 정렬되지 않은 조인보다 더 빠를 수 있습니다. 쿼리 최적화 프로그램은 비용 예측에 따라 정렬되지 않은 계획 또는 정렬된 계획을 선택합니다.
배치된 계획에서 Nested Loops 조인은 내부 측면에서 조인된 테이블 또는 인덱스 파티션을 하나 이상 읽습니다. Constant Scan 연산자 내의 숫자는 파티션 번호를 나타냅니다.
분할된 테이블 또는 인덱스에 대해 정렬된 조인에 대한 병렬 계획이 생성되면 병렬 처리 연산자와 Constant Scan 및 Nested Loops 조인 연산자 사이에 병렬 처리 연산자가 나타납니다. 이 경우 조인의 바깥쪽에 있는 여러 작업자 스레드가 각각 읽고 다른 파티션에서 작동합니다.
다음 그림에서는 정렬된 조인에 대한 병렬 쿼리 계획을 보여줍니다.
분할된 개체에 대한 병렬 쿼리 실행 전략
쿼리 프로세서는 분할된 개체에서 선택하는 쿼리에 대해 병렬 실행 전략을 사용합니다. 실행 전략의 일부로 쿼리 프로세서에서는 쿼리에 필요한 테이블 파티션과 각 파티션에 할당할 작업자 스레드 수를 결정합니다. 대부분의 경우 쿼리 프로세서는 각 파티션에 동일하거나 거의 동일한 수의 작업자 스레드를 할당한 다음 파티션 간에 쿼리를 병렬로 실행합니다. 다음 단락에서는 작업자 스레드 할당에 대해 자세히 설명합니다.
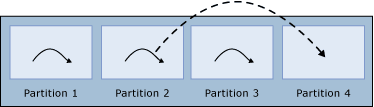
작업자 스레드 수가 파티션 수보다 적은 경우 쿼리 프로세서는 각 작업자 스레드를 서로 다른 파티션에 할당합니다. 따라서 처음에는 하나 이상의 파티션에 작업자 스레드가 할당되지 않습니다. 작업자 스레드가 파티션에서 실행을 마치면 쿼리 프로세서는 각 파티션에 단일 작업자 스레드가 할당될 때까지 다음 파티션에 할당합니다. 쿼리 프로세서가 작업자 스레드를 다른 파티션에 다시 할당하는 유일한 경우입니다.
완료 후 재할당된 작업자 스레드를 표시합니다. 작업자 스레드 수가 파티션 수와 동일한 경우 쿼리 프로세서는 각 파티션에 하나의 작업자 스레드를 할당합니다. 이때 작업자 스레드가 완료되어도 다른 파티션에 다시 할당되지 않습니다.

작업자 스레드 수가 파티션 수보다 많은 경우 쿼리 프로세서는 각 파티션에 동일한 수의 작업자 스레드를 할당합니다. 작업자 스레드 수가 파티션 수의 정확한 배수가 아닌 경우 쿼리 프로세서는 사용 가능한 모든 작업자 스레드를 사용하기 위해 일부 파티션에 하나의 추가 작업자 스레드를 할당합니다. 파티션이 하나만 있는 경우 모든 작업자 스레드가 해당 파티션에 할당됩니다. 아래 다이어그램에는 4개의 파티션과 14개의 작업자 스레드가 있습니다. 이 경우 각 파티션에 3개의 작업자 스레드가 할당되고 총 14개의 작업자 스레드를 할당하기 위해 2개의 파티션에 추가 작업자 스레드가 하나씩 할당됩니다. 이때 작업자 스레드가 완료되어도 다른 파티션에 재할당되지 않습니다.

위의 예제에서는 작업자 스레드를 할당하는 간단한 방법을 제안하지만 실제 전략은 더 복잡하며 쿼리 실행 중에 발생하는 다른 변수를 고려합니다. 예를 들어 테이블이 분할되고 A 열에 클러스터형 인덱스가 있고 쿼리에 조건자 WHERE A IN (13, 17, 25) 절이 있는 경우 쿼리 프로세서는 각 테이블 파티션 대신 이러한 세 개의 검색 값(A=13, A=17, A=25)에 하나 이상의 작업자 스레드를 할당합니다. 이러한 값을 포함하는 파티션에서 쿼리를 실행하기만 하면 되며, 이러한 모든 검색 조건자가 동일한 테이블 파티션에 있는 경우 모든 작업자 스레드가 동일한 테이블 파티션에 할당됩니다.
또 다른 예를 들어 테이블에 경계점(10, 20, 30), B 열의 인덱스가 있는 열 A에 4개의 파티션이 있고 쿼리에 조건자 절 WHERE B IN (50, 100, 150)이 있다고 가정합니다. 테이블 파티션은 A 값을 기반으로 하므로 B 값은 테이블 파티션에서 발생할 수 있습니다. 따라서 쿼리 프로세서는 각 4개의 테이블 파티션에서 B(50, 100, 150)의 세 값을 각각을 검색합니다. 쿼리 프로세서는 이러한 12개의 쿼리 검사를 각각 병렬로 실행할 수 있도록 작업자 스레드를 비례적으로 할당합니다.
| 열 A를 기반으로 하는 테이블 파티션 | 각 테이블 파티션에서 B열 찾기 |
|---|---|
| 테이블 파티션 1: A < 10 | B=50, B=100, B=150 |
| 테이블 파티션 2: A >= 10 AND A < 20 | B=50, B=100, B=150 |
| 테이블 파티션 3: A >= 20 AND A < 30 | B=50, B=100, B=150 |
| 테이블 파티션 4: A > 30 | B=50, B=100, B=150 |
모범 사례
대규모 분할된 테이블 및 인덱스에서 대량의 데이터에 액세스하는 쿼리의 성능을 향상시키려면 다음 모범 사례를 사용하는 것이 좋습니다.
- 여러 디스크에 각 파티션을 스트라이프합니다. 이는 회전 디스크를 사용할 때 특히 관련이 있습니다.
- 가능한 경우 자주 액세스하는 파티션 또는 메모리의 모든 파티션에 적합하게 충분한 주 메모리가 있는 서버를 사용하여 I/O 비용을 줄입니다.
- 쿼리한 데이터가 메모리 크기에 맞지 않을 경우 해당 테이블과 인덱스를 압축합니다. 이렇게 하면 I/O 비용이 줄어듭니다.
- 병렬 쿼리 처리 기능을 활용하려면 빠른 프로세서와 가능한 한 많은 프로세서 코어가 있는 서버를 사용합니다.
- 서버에 충분한 I/O 컨트롤러 대역폭이 있는지 확인합니다.
- 모든 분할된 대형 테이블에 클러스터형 인덱스를 만들어 B-트리 검색 최적화를 이용합니다.
- 데이터를 분할된 테이블로 대량 로드할 때 백서의 모범 사례 권장 사항인 데이터 로드 성능 가이드를 따릅니다.
예시
다음 예제에서는 7개의 파티션이 있는 단일 테이블을 포함하는 테스트 데이터베이스를 만듭니다. 이 예제에서 쿼리를 실행할 때 이전에 설명한 도구를 사용하여 컴파일 시간 및 런타임 계획 모두에 대한 분할 정보를 볼 수 있습니다.
참고 항목
이 예에서는 백만 개 이상의 행을 테이블로 삽입합니다. 이 예를 실행하는 데에는 하드웨어에 따라 시간이 몇 분 정도 걸릴 수 있습니다. 이 예를 실행하기 전에 1.5GB 이상의 사용 가능한 디스크 공간이 있는지 확인하십시오.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO