적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server 데이터베이스 엔진 인스턴스의 I/O에는 논리적 및 물리적 읽기가 포함됩니다. 논리 읽기는 데이터베이스 엔진이 버퍼 캐시(버퍼풀이라고도 함)에서 페이지를 요청할 때마다 발생합니다. 페이지가 현재 버퍼 캐시에 없는 경우 실제 읽기는 먼저 디스크에서 캐시로 페이지를 복사합니다.
데이터베이스 엔진 인스턴스에서 생성된 읽기 요청은 관계형 엔진에 의해 제어되고 스토리지 엔진에 의해 최적화됩니다. 관계형 엔진은 가장 효과적인 액세스 방법(예: 테이블 검색, 인덱스 검색 또는 키 읽기)을 결정합니다. 스토리지 엔진의 액세스 메서드 및 버퍼 관리자 구성 요소는 수행할 일반적인 읽기 패턴을 결정하고 액세스 방법을 구현하는 데 필요한 읽기를 최적화합니다. 일괄 처리를 실행하는 스레드는 읽기를 예약합니다.
Read-ahead
데이터베이스 엔진은 미리 읽기라는 성능 최적화 메커니즘을 지원합니다. 미리 읽기는 쿼리 실행 계획을 수행하는 데 필요한 데이터 및 인덱스 페이지를 예상하며, 쿼리에서 사용되기 전에 페이지를 버퍼 캐시로 가져옵니다. 이 프로세스를 통해 계산 및 I/O가 겹쳐서 CPU와 디스크를 모두 최대한 활용할 수 있습니다.
미리 읽기 메커니즘을 사용하면 데이터베이스 엔진이 한 파일에서 최대 64개의 연속 페이지(512KB)를 읽을 수 있습니다. 읽기는 버퍼 캐시에서 적절한 수의(아마도 인접하지 않은) 버퍼에 대한 단일 분산 수집 읽기로 수행됩니다. 범위의 페이지가 버퍼 캐시에 이미 있는 경우 읽기가 완료되면 읽기의 해당 페이지가 삭제됩니다. 해당 페이지가 캐시에 이미 있는 경우 페이지 범위가 양쪽 끝에서 "트리밍"될 수도 있습니다.
미리 읽기에는 데이터 페이지 와 인덱스 페이지용의 두 가지 종류가 있습니다.
데이터 페이지 읽기
데이터베이스 엔진에서 데이터 페이지를 읽는 데 사용하는 테이블 검색이 효율적입니다. SQL Server 데이터베이스의 IAM(인덱스 할당 맵) 페이지에는 테이블 또는 인덱스에 사용되는 범위가 나열됩니다. 스토리지 엔진은 IAM을 읽어 읽어야 하는 디스크 주소의 정렬된 목록을 작성할 수 있습니다. 이렇게 하면 스토리지 엔진이 디스크의 위치에 따라 순서대로 수행되는 대규모 순차 읽기로 I/O를 최적화할 수 있습니다. IAM 페이지에 대한 자세한 내용은 개체에서 사용하는 공간 관리를 참조하세요.
인덱스 페이지 읽기
스토리지 엔진은 키 순서로 인덱스 페이지를 직렬로 읽습니다. 예를 들어 이 그림에서는 리프 페이지를 매핑하는 키 집합과 중간 인덱스 노드가 포함된 리프 페이지 집합의 단순화된 표현을 보여 줍니다. 인덱스의 페이지 구조에 대한 자세한 내용은 클러스터형 및 비클러스터형 인덱스를 참조하세요.
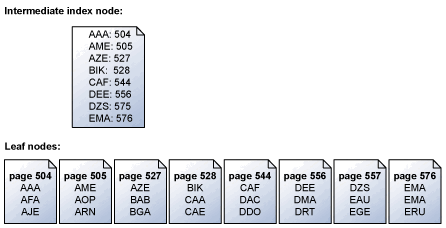
스토리지 엔진은 리프 수준 위의 중간 인덱스 페이지의 정보를 사용하여 키가 포함된 페이지에 대한 직렬 미리 읽기를 예약합니다.
ABC에서 DEF까지 모든 키에 대한 요청이 발생하면, 스토리지 엔진은 먼저 리프 페이지 위에 있는 인덱스 페이지를 읽습니다. 그러나 각 데이터 페이지를 504페이지에서 556페이지(지정된 범위의 키가 있는 마지막 페이지)로 순서대로 읽는 것은 아닙니다. 대신 스토리지 엔진은 중간 인덱스 페이지를 검색하고 읽어야 하는 리프 페이지 목록을 작성합니다. 그런 다음 스토리지 엔진은 모든 읽기를 키 순서대로 예약합니다. 또한 스토리지 엔진은 504/505 및 527/528 페이지가 연속적임을 인식하고 단일 분산 읽기를 수행하여 단일 작업에서 인접한 페이지를 검색합니다. 직렬 작업에서 검색할 페이지가 많은 경우 스토리지 엔진은 한 번에 읽기 블록을 예약합니다. 이러한 읽기의 하위 집합이 완료되면 스토리지 엔진은 필요한 모든 읽기가 예약될 때까지 동일한 수의 새 읽기를 예약합니다.
스토리지 엔진은 프리페치를 사용하여 비클러스터형 인덱스의 기본 테이블 조회 속도를 향상합니다. 비클러스터형 인덱스의 리프 행에는 각 특정 키 값이 포함된 데이터 행에 대한 포인터가 포함됩니다. 스토리지 엔진은 비클러스터형 인덱스의 리프 페이지를 읽는 동안 포인터가 이미 검색된 데이터 행에 대한 비동기 읽기 예약을 시작합니다. 이렇게 하면 스토리지 엔진이 비클러스터형 인덱스 검사를 완료하기 전에 기본 테이블에서 데이터 행을 검색할 수 있습니다. 프리페치는 테이블에 클러스터형 인덱스가 있는지 여부에 관계없이 사용됩니다. SQL Server Enterprise Edition은 다른 버전의 SQL Server보다 더 많은 프리페치를 사용하므로 더 많은 페이지를 미리 읽을 수 있습니다. 프리페치 수준은 어떤 버전에서도 구성할 수 없습니다. 비클러스터형 인덱스에 대한 자세한 내용은 클러스터형 및 비클러스터형 인덱스를 참조하세요.
고급 검사
SQL Server Enterprise Edition에서 고급 검색 기능을 사용하면 여러 작업이 전체 테이블 검사를 공유할 수 있습니다. Transact-SQL 문의 실행 계획에서 테이블의 데이터 페이지를 검색해야 하고 데이터베이스 엔진이 테이블이 이미 다른 실행 계획을 검색하고 있음을 감지하는 경우 데이터베이스 엔진은 두 번째 검색의 현재 위치에서 두 번째 검색을 첫 번째 검색에 조인합니다. 데이터베이스 엔진은 각 페이지를 한 번 읽고 각 페이지의 행을 두 실행 계획 모두에 전달합니다. 이 작업은 테이블의 끝에 도달할 때까지 계속됩니다.
이 시점에서 첫 번째 실행 계획에는 검사의 전체 결과가 있습니다. 그러나 두 번째 실행 계획은 진행 중인 검사에 조인하기 전에 읽은 데이터 페이지를 검색해야 합니다. 그런 다음 두 번째 실행 계획에 대한 검색은 테이블의 첫 번째 데이터 페이지로 다시 래핑되고 첫 번째 검색에 조인된 위치로 앞으로 검색합니다. 다음과 같이 여러 검사를 결합할 수 있습니다. 데이터베이스 엔진은 모든 검사를 완료할 때까지 데이터 페이지를 반복합니다. 이 메커니즘은 "회전목마 스캐닝"이라고도 하며, SELECT 문에서 ORDER BY 절이 없으면 반환된 결과의 순서를 보장할 수 없는 이유를 보여줍니다.
예를 들어 페이지가 500,000개인 테이블이 있다고 가정합니다.
UserA 는 테이블을 스캔해야 하는 Transact-SQL 문을 실행합니다. 그 스캔이 100,000페이지를 처리하면 UserB는 같은 테이블을 검색하는 또 다른 Transact-SQL 문을 실행합니다. 데이터베이스 엔진은 100,001 이후 페이지에 대한 읽기 요청 집합을 예약하고 각 페이지의 행을 두 검사에 다시 전달합니다. 검색이 200,000번째 페이지에 UserC 도달하면 동일한 테이블을 검색하는 다른 Transact-SQL 문을 실행합니다. 200,001페이지부터 데이터베이스 엔진은 읽은 각 페이지의 행을 세 가지 검사 모두에 전달합니다. 500,000번째 행을 읽은 후, UserA에 대한 검색이 완료되고, UserB 및 UserC에 대한 검색이 다시 시작되어 1페이지부터 페이지를 읽기 시작합니다. 데이터베이스 엔진이 100,000페이지로 이동하면 검색 UserB 이 완료됩니다. 그런 후 검색 UserC 는 200,000페이지에 도달할 때까지 혼자 계속 진행됩니다. 이 시점에서 모든 검사가 완료되었습니다.
고급 스캔이 없으면 각 사용자가 버퍼 공간을 놓고 경쟁하여 디스크 암 경합이 발생할 수 있습니다. 그러면 한 번 읽고 여러 사용자가 공유하는 대신 각 사용자에 대해 동일한 페이지를 한 번 읽으면 성능이 저하되고 리소스가 부담됩니다.