SQL Server 트랜잭션 로그 아키텍처 및 관리 가이드
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL 데이터베이스
Azure SQL 데이터베이스 ![]() SQL Managed Instance
SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() PDW(분석 플랫폼 시스템)
PDW(분석 플랫폼 시스템)
각 SQL Server 데이터베이스에는 각 트랜잭션에 의해 적용된 모든 트랜잭션 및 데이터베이스 수정 내용을 기록하는 트랜잭션 로그가 있습니다. 트랜잭션 로그는 데이터베이스의 중요한 구성 요소이며, 시스템 오류가 발생한 경우 데이터베이스를 일관된 상태로 되돌리기 위해 트랜잭션 로그가 필요할 수 있습니다. 이 가이드에서는 트랜잭션 로그의 물리적 아키텍처와 논리적 아키텍처에 대한 정보를 제공합니다. 아키텍처를 이해하면 트랜잭션 로그를 보다 효율적으로 관리할 수 있습니다.
트랜잭션 로그 논리 아키텍처
SQL Server 트랜잭션 로그는 논리적으로 마치 트랜잭션 로그가 로그 레코드의 문자열인 것처럼 작동합니다. 각 로그 레코드는 LSN(로그 시퀀스 번호)으로 식별됩니다. 각 새 로그 레코드는 LSN과 함께 로그의 논리적 끝에 작성되며 이때 LSN은 오름차순입니다. 로그 레코드는 만들어진 순서에 따라 순차적으로 저장됩니다. 예를 들어 LSN2가 LSN1보다 큰 경우 로그 레코드 LSN1에 해당하는 변경이 먼저 발생하고 로그 레코드 LSN2에 해당하는 변경이 이후에 발생한 것입니다. 각 로그 레코드에는 해당 레코드가 속한 트랜잭션의 ID가 포함됩니다. 각 트랜잭션에서 트랜잭션과 관련된 모든 로그 레코드는 트랜잭션의 롤백 속도를 높이는 후방 포인터로 체인에 개별적으로 연결되어 있습니다.
LSN의 기본 구조는 [VLF ID:Log Block ID:Log Record ID]입니다. 자세한 내용은 VLF 및 로그 블록 섹션을 참조하세요.
다음은 LSN의 예입니다. 00000031:00000da0:0001. 여기서 0x31은 VLF의 ID이고 0xda0은 로그 블록 ID이며 0x1은 해당 로그 블록의 첫 번째 로그 레코드입니다. LSN의 예는 sys.dm_db_log_info DMV의 출력을 확인하고 vlf_create_lsn 열을 검사합니다.
데이터 수정에 대한 로그 레코드는 수행된 논리적 연산이나 수정된 데이터의 이전 이미지와 이후 이미지를 기록합니다. 이전 이미지는 연산이 수행되기 전의 데이터 복사본이고 이후 이미지는 연산이 수행된 후의 데이터 복사본입니다.
연산을 복구하는 단계는 다음과 같이 로그 레코드의 유형에 따라 다릅니다.
로깅된 논리 연산
- 논리 연산을 롤포워드하기 위해 연산이 다시 수행됩니다.
- 논리 연산을 롤백하기 위해 역방향 논리 연산이 수행됩니다.
이미지가 로깅되기 전과 후
- 연산을 롤포워드하기 위해 이후 이미지가 적용됩니다.
- 연산을 롤백하기 위해 이전 이미지가 적용됩니다.
많은 유형의 연산이 트랜잭션 로그에 기록됩니다. 다음과 같은 작업이 여기에 포함됩니다.
각 트랜잭션의 시작과 끝입니다.
모든 데이터 수정 사항(삽입, 업데이트 또는 삭제)입니다. 수정 사항에는 시스템 저장 프로시저 또는 DDL(데이터 정의 언어) 문에 의한, 시스템 테이블을 비롯한 모든 테이블에 대한 변경 내용이 포함됩니다.
모든 익스텐트 및 페이지 할당 또는 할당 취소
테이블이나 인덱스 만들기 또는 삭제
롤백 작업도 로깅됩니다. 각 트랜잭션은 트랜잭션 로그에 공간을 예약하여 명시적 롤백 문 또는 오류로 인해 발생한 롤백을 지원하기에 충분한 로그 공간이 있는지 확인합니다. 예약된 공간의 크기는 트랜잭션에서 수행되는 작업에 따라 다르지만 일반적으로 각 작업을 기록하는 데 사용되는 공간의 크기와 같습니다. 이 예약된 공간은 트랜잭션이 완료되면 해제됩니다.
데이터베이스 전체 롤백에 성공하기 위해 확보해야 하는 첫 번째 로그 레코드에서 마지막으로 쓴 로그 레코드로의 로그 파일 섹션을 로그, 활성 로그 또는 비상 로그의 활성 부분이라고 합니다. 데이터베이스의 전체 복구에 필요한 로그의 섹션입니다. 활성 로그는 어떤 부분도 잘라낼 수 없습니다. 이 첫 번째 로그 레코드의 LSN(로그 시퀀스 번호)은 최소 복구 LSN(MinLSN)이라고 합니다. 트랜잭션 로그에서 지원되는 작업에 대한 자세한 내용은 트랜잭션 로그를 참조하세요.
차등 및 로그 백업의 경우 데이터베이스는 보다 나중의 것으로 복원되며 이는 더 높은 LSN에 해당합니다.
트랜잭션 로그 물리적 아키텍처
데이터베이스 트랜잭션 로그는 하나 이상의 물리적 파일에 매핑됩니다. 개념상으로 로그 파일은 로그 레코드의 문자열입니다. 실제로 로그 레코드 시퀀스는 트랜잭션 로그를 구현하는 물리적 파일 세트에 효율적으로 저장됩니다. 각 데이터베이스마다 하나 이상의 로그 파일이 있어야 합니다.
VLF(가상 로그 파일)
SQL Server 데이터베이스 엔진은 각 물리적 로그 파일을 내부적으로 여러 VLF(가상 로그 파일)로 나눕니다. 가상 로그 파일의 크기는 고정되어 있지 않으며 실제 로그 파일에 대한 가상 로그 파일의 수도 고정되되어 있지 않습니다. 데이터베이스 엔진은 로그 파일을 생성하거나 확장할 때 동적으로 가상 파일 로그 크기를 선택합니다. 데이터베이스 엔진은 몇 개의 가상 파일을 유지 관리하려고 시도합니다. 로그 파일이 확장된 후의 가상 파일 크기는 기존 로그의 크기와 새로 증가한 파일 크기의 합계입니다. 관리자는 가상 로그 파일의 크기 또는 수를 구성하거나 설정할 수 없습니다.
가상 로그 파일 만들기
VLF(가상 로그 파일)는 다음 방법에 따라 만듭니다.
- SQL Server 2014(12.x) 이상 버전에서 다음으로 증가하는 크기가 현재 로그 실제 크기의 1/8보다 작은 경우 증가 크기를 충당하는 1개의 VLF를 만듭니다.
- 다음으로 증가하는 크기가 현재 로그 크기의 1/8보다 큰 경우 2014년 이전 방법을 사용합니다. 즉,
- 증가 크기가 64MB 미만인 경우 증가 크기를 충당하는 4개의 VLL을 만듭니다(예: 1MB 증가의 경우 256KB 크기의 VLF를 4개 만듦).
- Azure SQL Database에서 SQL Server 2022(16.x)(모든 버전)부터는 논리가 약간 다릅니다. 증가 크기가 64MB보다 작거나 같으면 데이터베이스 엔진 증가 크기를 충당하기 위해 하나의 VLF만 만듭니다.
- 증가 크기가 64MB에서 1GB 사인인 경우 증가 크기를 충당하는 8개의 VLL을 만듭니다(예: 512MB 증가의 경우 64MB 크기의 VLF 8개를 만듦).
- 증가 크기가 1GB보다 큰 경우 증가 크기를 충당하는 16개의 VLF를 만듭니다(예: 8GB 증가의 경우 512MB 크기의 VLF를 16개 만듦).
- 증가 크기가 64MB 미만인 경우 증가 크기를 충당하는 4개의 VLL을 만듭니다(예: 1MB 증가의 경우 256KB 크기의 VLF를 4개 만듦).
수많은 작은 증가값에서 로그 파일이 크게 증가하는 경우 가상 로그 파일이 많이 생성됩니다. 이로 인해 데이터베이스 시작 속도가 느려지고, 백업 및 복원 작업이 로깅되며, 트랜잭션 복제/CDC 및 Always On 다시 실행 대기 시간이 발생할 수 있습니다. 반대로 로그 파일이 몇 개 또는 하나의 증분으로 큰 크기로 설정된 경우 매우 큰 가상 로그 파일이 몇 개만 포함됩니다. 트랜잭션 로그의 필요한 크기 및 자동 증가 설정을 적절하게 예측하는 방법에 대한 자세한 내용은 트랜잭션 로그 파일의 크기 관리의 권장 사항 섹션을 참조하세요.
최적의 VLF 배포를 달성하는 데 필요한 증분을 사용하여 필요한 최종 크기에 가까운 로그 파일을 만들고 상대적으로 큰 growth_increment 값을 설정하는 것이 좋습니다.
현재 트랜잭션 로그 크기에 대해 최적의 VLF 분포를 결정하려면 다음 팁을 참조하세요.
ALTER DATABASE의SIZE인수로 설정된 크기 값은 로그 파일의 초기 크기입니다.ALTER DATABASE세트의FILEGROWTH인수인 growth_increment 값(자동 증가 값이라고도 함)은 새 공간이 필요할 때마다 파일에 추가되는 공간의 양입니다.
FILEGROWTH 및 SIZE 인수에 대한 자세한 내용은 ALTER DATABASE(Transact-SQL) 파일 및 파일 그룹 옵션을 참조하세요.
팁
주어진 인스턴스의 모든 데이터베이스의 현재 트랜잭션 로그 크기에 대한 최적의 VLF 분포 및 필수 크기를 수행할 필수 성장 증분을 결정하려면 GitHub에서 이 Fixing-VLF 스크립트를 참조하세요.
VLF가 너무 많으면 어떻게 되나요?
데이터베이스 복구 프로세스의 초기 단계에서 SQL Server는 모든 트랜잭션 로그 파일의 모든 VLF를 검색하고 이러한 VLF의 목록을 작성합니다. 특정 데이터베이스에 있는 VLF 수에 따라 이 프로세스에 시간이 오래 걸릴 수 있습니다. VLF가 많을수록 프로세스가 길어집니다. 트랜잭션 로그 자동 증가 또는 수동 증가가 작은 크기로 발생하는 경우 데이터베이스의 VLF 수가 많아질 수 있습니다. VLF 수가 수십만 개의 범위에 도달하면 다음 증상 중 일부 또는 대부분이 발생할 수 있습니다.
- SQL Server를 시작하는 동안 하나 이상의 데이터베이스가 복구를 완료하는 데 시간이 매우 오래 걸립니다.
- 데이터베이스 복원을 완료하는 데 시간이 매우 오래 걸립니다.
- 데이터베이스 연결 시도를 완료하는 데 시간이 매우 오래 걸립니다.
- 데이터베이스 미러링을 설정하려고 하면 시간 제한을 나타내는 1413, 1443 및 1479 오류 메시지가 발생합니다.
- 데이터베이스를 복원하려고 할 때 701을 비롯한 메모리 관련 오류가 발생합니다.
- 트랜잭션 복제 또는 변경 데이터 캡처 시에 상당한 대기 시간이 발생할 수 있습니다.
SQL Server 오류 로그를 검사할 때 데이터베이스 복구 프로세스의 분석 단계 전에 상당한 시간이 소요되는 것을 알 수 있습니다. 예시:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
또한 SQL Server에서 VLF 수가 많은 데이터베이스를 복원할 때 MSSQLSERVER_9017 오류가 로깅될 수 있습니다.
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
자세한 내용은 MSSQLSERVER_9017을 참조하세요.
많은 수의 VLF가 있는 데이터베이스 수정
최대 수천 개에 달하는 총 VLF 수를 적절한 양으로 유지하기 위해, 다음 단계를 수행하여 더 적은 수의 VLF을 포함하도록 트랜잭션 로그 파일을 다시 설정할 수 있습니다.
트랜잭션 로그 파일을 수동으로 축소합니다.
다음 T-SQL 스크립트를 사용하여 한 단계로, 파일을 필요한 크기로 수동 확장합니다.
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);참고 항목
이 단계는 SQL Server Management Studio에서도 데이터베이스 속성 페이지를 사용하여 수행할 수 있습니다.
더 적은 수의 VLF로 트랜잭션 로그 파일의 새 레이아웃을 설정한 후 트랜잭션 로그의 자동 증가 설정을 검토하고 필요한 변경 사항을 적용합니다. 이 설정 유효성 검사는 로그 파일에서 나중에 동일한 문제가 발생하지 않도록 합니다.
이 작업을 수행하기 전에, 나중에 문제가 발생할 경우 복원 가능한 유효한 백업이 있는지 확인합니다.
주어진 인스턴스의 모든 데이터베이스의 현재 트랜잭션 로그 크기에 대한 최적의 VLF 분포 및 필수 크기를 수행할 필수 성장 증분을 결정하려면 다음 GitHub 스크립트를 사용하여 VLF를 수정하면 됩니다.
로그 블록
각 VLF에는 하나 이상의 로그 블록이 포함되어 있습니다. 각 로그 블록은 로그 레코드(4 바이트 경계에 정렬됨)로 구성됩니다. 로그 블록은 크기가 가변적이고 항상 512바이트 크기(SQL Server에서 지원하는 최소 섹터 크기)의 정수 배수이며 최대 크기는 60KB입니다. 로그 블록은 트랜잭션 로깅에 대한 기본 I/O 단위입니다.
요약하자면, 로그 블록은 디스크에 로그 레코드를 쓸 때 트랜잭션 로깅의 기본 단위로 사용되는 로그 레코드의 컨테이너입니다.
VLF 내의 각 로그 블록은 블록 오프셋으로 고유하게 주소가 지정됩니다. 첫 번째 블록에는 항상 VLF의 처음 8KB를 가리키는 블록 오프셋이 있습니다.
일반적으로 VLF는 항상 로그 블록으로 채워집니다. VLF의 마지막 로그 블록이 비어 있을 수 있습니다(예: 로그 레코드가 포함되지 않음). 이 문제는 기록할 로그 레코드가 현재 로그 블록에 맞지 않는 경우에, 그리고 VLF에 남아 있는 공간이 이 로그 레코드를 보유하기에 충분하지 않은 경우에 발생합니다. 이 경우 VLF를 채우기 위한 빈 로그 블록이 만들어집니다. 이 로그 레코드는 다음 VLF의 첫 번째 블록에 삽입됩니다.
트랜잭션 로그의 순환 특성
트랜잭션 로그는 랩 어라운드 파일입니다. 예를 들어 하나의 물리적 로그 파일이 있는 데이터베이스를 4개의 VLF로 나누었다고 가정해 보겠습니다. 데이터베이스가 만들어지면 논리적 로그 파일은 실제 로그 파일의 시작 부분에 시작됩니다. 새 로그 레코드는 논리 로그의 끝에 추가되고 실제 로그의 끝까지 확장됩니다. 로그 잘림은 최소 MinLSN(복구 로그 시퀀스 번호) 앞에 레코드가 모두 표시되는 모든 가상 로그를 해제합니다. MinLSN은 데이터베이스 전체 롤백을 성공적으로 수행하는 데 필요한 가장 오래된 로그 레코드의 로그 시퀀스 번호입니다. 예제 데이터베이스의 트랜잭션 로그는 다음 다이어그램의 로그와 유사합니다.
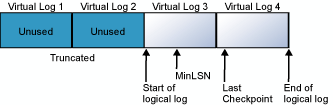
논리적 로그의 끝이 물리적 로그 파일의 끝에 도달하면 새 로그 레코드가 물리적 로그 파일의 시작 부분까지 래핑됩니다.
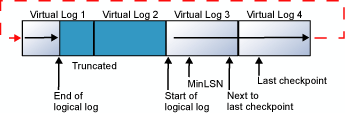
이러한 순환은 논리 로그 끝 부분이 논리 로그의 시작 부분에 도달하지 않는 한 계속 반복됩니다. 다음 검사점까지 생성되는 모든 새 로그 레코드를 위해 항상 충분한 공간이 남을 만큼 기존 로그 레코드가 자주 잘리면 로그는 가득 차지 않습니다. 하지만 논리 로그의 끝이 논리 로그의 시작 부분에 도달하면 다음 두 가지 중 하나가 발생합니다.
로그의
FILEGROWTH설정이 활성화되어 있고 디스크에 사용할 수 있는 공간이 있으면 파일은 growth_increment 매개 변수에 지정된 크기만큼 확장되며 새 로그 레코드가 확장 부분에 추가됩니다.FILEGROWTH설정에 대한 자세한 내용은 ALTER DATABASE(Transact-SQL) 파일 및 파일 그룹 옵션을 참조하세요.FILEGROWTH설정이 활성화되지 않았거나 로그 파일이 저장된 디스크의 여유 공간이 growth_increment에 지정된 양보다 적으면 9002 오류가 생성됩니다. 자세한 내용은 전체 트랜잭션 로그 문제 해결(SQL Server 오류 9002)을 참조하세요.
로그에 여러 물리적 로그 파일이 포함된 경우 논리적 로그는 첫 번째 물리적 로그 파일의 시작으로 다시 래핑되기 전에 모든 물리적 로그 파일을 통해 이동합니다.
Important
트랜잭션 로그 크기 관리에 대한 자세한 내용은 트랜잭션 로그 파일의 크기 관리를 참조하세요.
로그 잘림
로그 잘림은 로그가 채워지지 않도록 하는 데 필수적입니다. 로그 잘림은 SQL Server 데이터베이스의 논리 트랜잭션 로그에서 비활성 가상 로그 파일을 삭제하여 물리적 트랜잭션 로그에서 다시 사용할 수 있도록 논리적 로그의 공간을 확보합니다. 트랜잭션 로그가 잘리지 않으면 결국 물리적 로그 파일에 할당된 모든 디스크 공간이 채워집니다. 하지만 로그를 자르기 전에 검사점 작업이 발생해야 합니다. 검사점은 현재 메모리 내의 수정된 페이지(더티 페이지라고 함)와 메모리의 트랜잭션 로그 정보를 디스크에 씁니다. 검사점을 수행하면 트랜잭션 로그의 비활성 부분은 재사용 가능으로 표시됩니다. 그런 다음, 로그 잘림은 비활성 부분을 해제할 수 있습니다. 검사점에 대한 자세한 내용은 데이터베이스 검사점(SQL Server)을 참조하세요.
다음 다이어그램은 잘림 전후의 트랜잭션 로그를 보여 줍니다. 첫 번째 다이어그램은 잘린 적이 없는 트랜잭션 로그를 보여줍니다. 현재 논리적 로그에서 4개의 가상 로그 파일을 사용하고 있습니다. 이 논리적 로그는 첫 번째 가상 로그 파일의 맨 앞에서 시작하여 가상 로그 4에서 끝납니다. MinLSN 레코드는 가상 로그 3에 있습니다. 가상 로그 1과 가상 로그 2에는 비활성 로그 레코드만 포함되어 있습니다. 이러한 레코드는 자를 수 있습니다. 가상 로그 5는 아직 사용되지 않으며, 현재 논리 로그의 일부가 아닙니다.
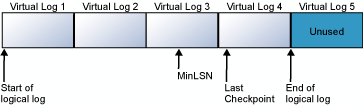
두 번째 다이어그램은 잘린 후 로그가 어떻게 표시되는지 보여 줍니다. 가상 로그 1과 가상 로그 2는 재사용을 위해 해제되었습니다. 이제 논리적 로그가 가상 로그 3의 시작 부분에서 시작됩니다. 가상 로그 5는 아직 사용되지 않으며, 현재 논리 로그의 일부가 아닙니다.
로그 잘림은 특정한 이유로 인해 지연된 경우를 제외하고, 다음 이벤트 이후에 자동으로 발생합니다.
- 단순 복구 모델에서 검사점 뒤
- 전체 복구 모델 또는 대량 로그된 복구 모델에서 이전 백업 이후 검사점이 발생한 경우, 로그 백업 후에 잘림이 발생합니다.
로그 잘림은 다양한 요인으로 지연될 수 있습니다. 로그 잘림이 장시간 지연될 경우 트랜잭션 로그가 꽉 찰 수 있습니다. 자세한 내용은 로그 잘림을 지연시킬 수 있는 요소 및 꽉 찬 트랜잭션 로그 문제 해결(SQL Server Error 9002)을 참조하세요.
미리 쓰기 트랜잭션 로그
이 섹션에서는 디스크에 대한 데이터 수정 내용을 기록하는 미리 쓰기 트랜잭션 로그의 역할을 설명합니다. SQL Server에서는 WAL(미리 쓰기 로깅) 알고리즘을 사용하여 연결된 로그 레코드가 디스크에 기록되기 전에는 어떠한 데이터 수정 내용도 디스크에 기록되지 않도록 합니다. 따라서 트랜잭션에 대한 ACID 속성이 유지됩니다.
WAL에 대한 자세한 내용은 SQL Server I/O 기본 사항을 참조하세요.
트랜잭션 로그와 관련하여 미리 쓰기 로깅이 작동하는 방식을 이해하려면, 수정된 데이터가 디스크에 기록되는 방식을 알아야 합니다. SQL Server는 데이터를 검색해야 할 경우 데이터 페이지를 읽는 버퍼 캐시(버퍼 풀이라고도 함)를 유지 관리합니다. 페이지가 버퍼 캐시에서 수정될 때 페이지는 디스크에 바로 다시 기록되지 않고 대신 더티로 표시됩니다. 데이터 페이지는 물리적으로 디스크에 기록되기 전에 두 개 이상의 논리적 쓰기를 수행할 수 있습니다. 각 논리적 쓰기마다 수정 내용을 기록하는 트랜잭션 로그 레코드가 로그 캐시에 삽입됩니다. 로그 레코드는 관련된 더티 페이지가 버퍼 캐시에서 디스크로 제거되기 전에 디스크에 기록되어야 합니다. 검사점 프로세스는 지정된 데이터베이스의 페이지가 있는 버퍼에 대한 버퍼 캐시를 주기적으로 검사하고 모든 더티 페이지를 디스크에 씁니다. 검사점은 모든 더티 페이지가 디스크에 기록되도록 보장되는 지점을 만들어 나중에 복구 시에 시간을 절약합니다.
버퍼 캐시로부터 디스크로 수정된 데이터 페이지를 쓰는 것을 페이지를 플러시라고 합니다. SQL Server에는 연결된 로그 레코드가 기록되기 전에 더티 페이지가 플러시되지 않도록 하는 논리가 있습니다. 로그 레코드는 로그 버퍼가 플러시될 때 디스크에 쓰여집니다. 이는 트랜잭션 커밋 또는 로그 버퍼가 가득 찼을 때마다 발생합니다.
트랜잭션 로그 백업
이 섹션에서는 트랜잭션 로그를 백업 및 복원(적용)하는 방법에 대한 개념을 제시합니다. 전체 및 대량 로그된 복구 모델에서는 데이터 복구를 위해 트랜잭션 로그(로그 백업)의 일상적인 백업을 수행해야 합니다. 전체 백업이 실행되는 동안 로그를 백업할 수 있습니다. 복구 모델에 대한 자세한 내용은 SQL Server 데이터베이스의 백업 및 복원을 참조하세요.
첫 번째 로그 백업을 만들려면 먼저 데이터베이스 백업 또는 파일 백업 세트의 첫 번째 백업과 같은 전체 백업을 만들어야 합니다. 파일 백업만 사용하여 데이터베이스를 복원하면 작업이 복잡해질 수 있습니다. 따라서 가능한 경우 전체 데이터베이스 백업으로 시작하는 것이 좋습니다. 그 후에는 트랜잭션 로그를 주기적으로 백업해야 합니다. 이렇게 하면 작업 손실에 대한 노출을 최소화할 뿐만 아니라 트랜잭션 로그를 자를 수도 있습니다. 일반적으로 트랜잭션 로그는 모든 일반 로그 백업 후에 잘립니다.
Important
비즈니스 요구 사항, 특히 손상된 로그 스토리지로 인해 발생할 수 있는 작업 손실에 대한 허용치를 지원하기에 충분할 만큼 로그 백업을 자주 수행하는 것이 좋습니다.
로그 백업의 적절한 수행 빈도는 저장 및 관리는 물론 복원까지 가능할 수 있는 로그 백업의 횟수에 의해 조정되는 작업 손실 위험에 대한 허용 범위에 따라 달라집니다. 복구 전략을 구현할 때 필요한 RTO(복구 시간 목표) 및 RPO(복구 지점 목표), 특히 로그 백업 주기를 생각해보세요. 로그 백업에 걸리는 시간은 매 15분에서 30분이면 충분합니다. 비즈니스에서 작업 손실 위험을 최소화하려는 경우에는 로그 백업을 더 자주 수행해야 합니다. 로그 백업 빈도가 높아질수록 로그 잘림 빈도가 증가하여 로그 파일이 더 작아질 수 있습니다.
복원해야 하는 로그 백업 수를 제한하려면 데이터를 주기적으로 백업해야 합니다. 예를 들어 주별 전체 데이터베이스 백업과 일별 차등 데이터베이스 백업을 예약할 수 있습니다.
복구 전략을 구현할 때 필요한 RTO 및 RPO, 특히 전체 및 차등 데이터베이스 백업 케이던스에 대해 생각해보세요.
트랜잭션 로그 백업에 대한 자세한 내용은 트랜잭션 로그 백업(SQL Server)을 참조하세요.
로그 체인
로그 백업의 연속된 시퀀스를 로그 체인이라고 합니다. 로그 체인은 데이터베이스의 전체 백업으로 시작합니다. 일반적으로 데이터베이스를 처음 백업할 때나 단순 복구 모델에서 전체 또는 대량 로그 복구 모델로 전환한 후에만 새 로그 체인이 시작됩니다. 전체 데이터베이스 백업을 만들 때 기존 백업 세트를 덮어쓰도록 선택하지 않는 한, 기존 로그 체인이 그대로 유지됩니다. 로그 체인이 그대로 유지되면 미디어 세트의 전체 데이터베이스 백업에서 데이터베이스를 복원한 후 모든 후속 로그 백업을 복구 지점까지 복원할 수 있습니다. 복구 지점은 마지막 로그 백업의 끝이나 로그 백업의 특정 복구 지점일 수 있습니다. 자세한 내용은 트랜잭션 로그 백업(SQL Server)을 참조하세요.
실패 지점까지 데이터베이스를 복원하려면 로그 체인이 그대로 유지되어야 합니다. 즉, 트랜잭션 로그 백업의 끊어지지 않은 시퀀스가 실패 지점까지 이어져야 합니다. 이 로그 시퀀스를 시작해야 하는 위치는 복원 중인 데이터 백업 유형(데이터베이스, 부분 또는 파일)에 따라 달라집니다. 데이터베이스 또는 부분 백업의 경우 로그 백업의 시퀀스는 데이터베이스 또는 부분 백업의 끝 지점에서 이어져야 합니다. 파일 백업 세트의 경우 로그 백업 시퀀스는 전체 파일 백업 세트의 시작부터 이어져야 합니다. 자세한 내용은 트랜잭션 로그 백업 적용(SQL Server)을 참조하세요.
로그 백업 복원
로그 백업을 복원하면 트랜잭션 로그에 기록된 변경 내용이 롤아웃되어 로그 백업 작업이 시작될 때 데이터베이스의 정확한 상태가 재현됩니다. 데이터베이스를 복원할 때 복원하는 전체 데이터베이스 백업 이후 또는 복원한 첫 번째 파일 백업의 시작부터 만든 로그 백업을 복원해야 합니다. 일반적으로 가장 최근의 데이터나 차등 백업을 복원하고 나면 복구 지점에 이를 때까지 일련의 로그 백업을 복원한 다음 그런 다음 데이터베이스를 복구합니다. 이를 통해 복구가 시작될 때 불완전했던 모든 트랜잭션이 롤백되고 데이터베이스가 온라인 상태가 됩니다. 데이터베이스가 복구된 후에는 더 이상 백업을 복원할 수 없습니다. 자세한 내용은 트랜잭션 로그 백업 적용(SQL Server)을 참조하세요.
검사점 및 로그의 활성 부분
검사점은 현재 데이터베이스의 버퍼 캐시로부터 디스크로 더티 데이터 페이지를 플러시합니다. 따라서 데이터베이스의 전체 복구 중에 처리되어야 하는 로그의 활성 부분이 최소화됩니다. 전체 복구 중에는 다음 유형의 작업이 수행됩니다.
- 시스템이 중지되기 전에는 수정된 로그 레코드가 디스크로 플러시되지 않습니다.
- COMMIT 또는 ROLLBACK 로그 레코드가 없는 트랜잭션과 같은 불완전한 트랜잭션과 관련된 모든 수정 내용이 롤백됩니다.
검사점 작업
검사점은 데이터베이스에서 다음 프로세스를 수행합니다.
로그 파일에 레코드를 기록하여 검사점의 시작을 표시합니다.
검사점에 대해 기록된 정보를 검사점 로그 레코드 체인에 저장합니다.
검사점에 기록되는 정보 중 하나는 성공적인 데이터베이스 전체 롤백을 위해 있어야 하는 첫 번째 로그 레코드의 LSN(로그 시퀀스 번호)입니다. 이 LSN을 MinLSN(최소 복구 LSN)이라고 합니다. MinLSN은 다음의 최소값입니다.
- 검사점 시작의 LSN
- 가장 오래된 활성 트랜잭션 시작의 LSN
- 아직 배포 데이터베이스로 전달되지 않은 가장 오래된 복제 트랜잭션 시작의 LSN
검사점 레코드에는 데이터베이스를 수정한 모든 활성 트랜잭션의 목록도 포함됩니다.
데이터베이스에서 단순 복구 모델을 사용하는 경우 MinLSN 앞에 있는 공간을 다시 사용하도록 표시합니다.
모든 더티 로그 및 데이터 페이지를 디스크에 씁니다.
검사점의 끝을 표시하는 레코드를 로그 파일에 씁니다.
이 체인의 시작 LSN을 데이터베이스 부팅 페이지에 씁니다.
검사점을 발생시키는 작업
검사점은 다음 경우에 발생합니다.
- CHECKPOINT 문이 명시적으로 실행된 경우. 현재 연결된 데이터베이스에서 검사점이 발생합니다.
- 데이터베이스에서 최소 로깅 작업이 수행된 경우 - 예: 대량 복사 작업이 대량 로그 복구 모델을 사용하는 데이터베이스에서 수행된 경우.
- ALTER DATABASE를 사용하여 데이터베이스 파일이 추가되거나 제거되었습니다.
- SHUTDOWN 문을 사용하거나 SQL Server(MSSQLSERVER) 서비스를 중지하여 SQL Server 인스턴스를 중지한 경우. 두 경우 모두 SQL Server 인스턴스의 각 데이터베이스에 검사점이 발생합니다.
- SQL Server 인스턴스는 주기적으로 각 데이터베이스에 자동 검사점을 생성하여, 인스턴스가 데이터베이스를 복구하는 데 걸리는 시간을 줄입니다.
- 데이터베이스 백업이 수행됩니다.
- 데이터베이스 종료가 필요한 활동이 수행되었습니다. 이 동작은 AUTO_CLOSE 옵션이 ON이고 데이터베이스에 대한 마지막 사용자 연결이 닫힌 경우에 발생할 수 있습니다. 또 다른 예는 적용하려면 데이터베이스를 다시 시작해야 하는 데이터베이스 옵션 변경을 수행하는 경우입니다.
자동 검사점
SQL Server 데이터베이스 엔진은 자동 검사점을 생성합니다. 자동 검사점 간의 간격은 마지막 검사점 이후 경과된 시간과 사용된 로그 공간에 따라 결정됩니다. 데이터베이스에서 수정이 거의 수행되지 않는 경우 자동 검사점 간의 시간 간격은 매우 가변적이고 길어질 수 있습니다. 많은 데이터가 수정되는 경우에도 자동 검사점이 자주 발생할 수 있습니다.
복구 간격 서버 구성 옵션을 사용하여 서버 인스턴스의 모든 데이터베이스에 대한 자동 검사점 간 간격을 계산할 수 있습니다. 이 옵션은 시스템을 다시 시작하는 동안 데이터베이스 엔진이 데이터베이스를 복구하는 데 사용하는 최대 시간을 지정합니다. 데이터베에스 엔진은 복구 작업 중에 해당 복구 간격 동안 처리할 수 있는 로그 레코드의 수를 예상합니다.
자동 검사점 사이의 간격도 복구 모델에 따라 달라집니다.
전체 또는 대량 로그 복구 모델을 사용하는 데이터베이스의 경우 로그 레코드의 수가 데이터베이스 엔진에서 복구 간격 옵션에 지정된 시간 동안 처리할 수 있다고 예상한 레코드의 수에 도달할 때마다 자동 검사점이 생성됩니다.
단순 복구 모델을 사용하는 데이터베이스의 경우 로그 레코드의 수가 다음의 두 값 중에서 작은 값에 도달할 때마다 자동 검사점이 생성됩니다.
- 로그의 70%가 찼을 때
- 로그 레코드의 수가 데이터베이스 엔진이 복구 간격 옵션에 지정된 시간 동안 처리할 수 있을 것으로 예상하는 수에 도달할 경우.
복구 간격 설정에 대한 자세한 내용은 복구 간격(분) 구성(서버 구성 옵션)을 참조하세요.
팁
데이터베이스 관리자는 일부 유형의 검사점에 대해 -k SQL Server 고급 설정 옵션을 사용하여 I/O 하위 시스템의 처리량에 따라 검사점 I/O 동작을 제한할 수 있습니다. -k 설정 옵션은 자동 검사점과 그 밖의 제한되지 않는 검사점에 적용됩니다.
데이터베이스가 단순 복구 모델을 사용하는 경우 자동 검사점은 트랜잭션 로그의 사용되지 않는 섹션을 자릅니다. 그러나 데이터베이스가 전체 또는 대량 로그 복구 모델을 사용하고 있을 때는 자동 검사점에서 이러한 로그를 자르지 않습니다. 자세한 내용은 트랜잭션 로그를 참조하세요.
이제 CHECKPOINT 문은 검사점이 완료되는 데 필요한 시간(초)을 지정하는 선택적 checkpoint_duration 인수를 제공합니다. 자세한 내용은 CHECKPOINT를 참조하세요.
활성 로그
마지막으로 MinLSN로부터 로그 레코드에 쓴 로그 파일 섹션을 로그의 활성 부분 또는 활성 로그라고 합니다. 이는 데이터베이스의 전체 복구를 수행하는 데 필요한 로그의 섹션입니다. 활성 로그는 어떤 부분도 잘라낼 수 없습니다. 모든 로그 레코드는 MinLSN 이전의 로그 부분에서 잘려야 합니다.
다음 다이어그램은 두 개의 활성 트랜잭션이 있는 트랜잭션 종료 로그의 간소화된 버전을 보여 줍니다. 검사점 레코드가 단일 레코드로 압축되었습니다.

LSN 148은 트랜잭션 로그의 마지막 레코드입니다. LSN 147에 기록된 검사점이 처리되면 Tran 1이 커밋되고 Tran 2만 유일한 활성 트랜잭션이 됩니다. 따라서 Tran 2의 첫 번째 로그 레코드가 마지막 검사점 당시 활성 상태인 트랜잭션에 대한 가장 오래된 로그 레코드가 됩니다. 즉, LSN 142는 Tran 2의 시작 트랜잭션 레코드인 MinLSN입니다.
장기 실행 트랜잭션
활성 로그는 커밋되지 않은 모든 트랜잭션의 모든 부분을 포함해야 합니다. 트랜잭션을 시작하고 커밋하거나 롤백하지 않는 애플리케이션이 있으면, 데이터베이스 엔진 MinLSN이 진행되지 않습니다. 이 경우 두 가지 유형의 문제가 발생할 수 있습니다.
- 트랜잭션이 커밋되지 않은 많은 수정 작업을 수행한 후에 시스템이 종료되면 시스템이 다시 시작된 후의 복구 단계 수행 시 복구 간격 옵션에 지정된 시간보다 훨씬 더 오래 걸릴 수 있습니다.
- 로그는 MinLSN을 지나서 잘려질 수 없으므로 로그가 매우 커질 수 있습니다. 이는 각 자동 검사점에서 트랜잭션 로그가 잘리는 단순 복구 모델이 데이터베이스에 사용되는 경우에도 발생합니다.
장기 실행 트랜잭션의 복구 및 이 문서에서 설명하는 문제는 SQL Server 2019(15.x)와 Azure SQL Database에서 사용할 수 있는 기능인 가속 데이터베이스 복구를 사용하여 방지할 수 있습니다.
복제 트랜잭션
로그 판독기 에이전트는 트랜잭션 복제를 위해 구성한 각 데이터베이스의 트랜잭션 로그를 모니터링하고 복제 표시된 트랜잭션을 트랜잭션 로그에서 배포 데이터베이스로 복사합니다. 활성 로그에는 복제용으로 표시되었지만 아직 배포 데이터베이스에 제공되지 않은 모든 트랜잭션이 포함되어야 합니다. 이러한 트랜잭션이 제때에 복제되지 않으면 로그 잘라내기가 수행되지 않을 수 있습니다. 자세한 내용은 트랜잭션 복제를 참조하세요.