적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric의 SQL 데이터베이스
Microsoft Fabric의 SQL 데이터베이스
OPENXML은 Transact-SQL 키워드이며, 테이블 또는 보기와 유사한 메모리 내 XML 문서에 대한 행 집합을 제공합니다. OPENXML은 관계형 행 집합인 것처럼 XML 데이터에 대한 액세스를 허용합니다. XML 문서의 내부 표현에 대한 행 집합 보기를 제공하여 이 작업을 수행합니다. 행 집합의 레코드는 데이터베이스 테이블에 저장할 수 있습니다.
행 집합 공급자, 보기 또는 OPENROWSET이 원본으로 표시될 수 있는 경우 SELECT 및 SELECT INTO 문에서 OPENXML을 사용할 수 있습니다. OPENXML 구문에 대한 자세한 내용은 OPENXML(Transact-SQL)을 참조하세요.
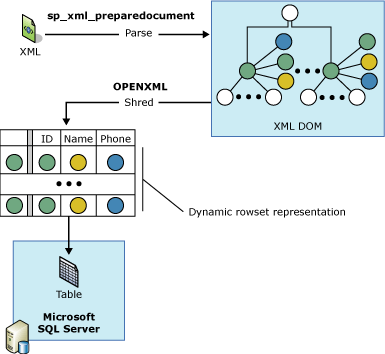
OPENXML을 사용하여 XML 문서에 대한 쿼리를 작성하려면 먼저 sp_xml_preparedocument를 호출해야 합니다. 이렇게 하면 XML 문서를 구문 분석하고 사용할 준비가 된 구문 분석된 문서에 대한 핸들을 반환합니다. 구문 분석된 문서는 XML 문서의 다양한 노드에 대한 DOM(문서 개체 모델) 트리의 표현입니다. 문서 핸들이 OPENXML에 전달됩니다. 그런 다음 OPENXML은 전달된 매개 변수에 따라 문서의 행 집합 보기를 제공합니다.
참고 항목
sp_xml_preparedocument은 MSXML 파서의 SQL 업데이트 버전인 Msxmlsql.dll 사용합니다. 이 버전의 MSXML 파서는 SQL Server를 지원하고 MSXML 버전 2.6과 호환되도록 설계되었습니다.
메모리를 확보하기 위해서는 sp_xml_removedocument 시스템 저장 프로시저를 호출하여 메모리에서 XML 문서의 내부 표현을 제거해야 합니다.
다음 그림은 이 프로세스를 보여줍니다.
OPENXML을 이해하려면 XPath 쿼리에 대한 숙달과 XML에 대한 이해가 필요합니다. SQL Server의 XPath 지원에 대한 자세한 내용은 SQLXML 4.0에서 XPath 쿼리 사용을 참조 하세요.
참고 항목
OpenXML을 사용하면 행 및 열 XPath 패턴을 변수로 매개 변수화할 수 있습니다. 이러한 매개 변수화는 프로그래머가 외부 사용자에게 매개 변수화를 노출하는 경우(예: 외부 호출 저장 절차를 통해 매개 변수가 제공되는 경우) XPath 식 삽입으로 이어질 수 있습니다. 이러한 잠재적인 보안 문제를 방지하려면 XPath 매개 변수가 외부 호출자에게 노출되어서는 안 됩니다.
예시
다음 예제는 OPENXML 문과 INSERT 문에서 SELECT을 사용하는 방법을 보여줍니다. 예제 XML 문서에 <Customers> 및 <Orders> 요소가 들어 있습니다.
먼저 sp_xml_preparedocument 저장 프로시저는 XML 문서를 구문 분석합니다. 구문 분석된 문서는 XML 문서의 노드(요소, 특성, 텍스트 및 주석)를 트리로 나타낸 것입니다.
OPENXML 은 이 구문 분석된 XML 문서를 참조하여 해당 XML 문서의 일부 또는 전체에 대한 행 집합 뷰를 제공합니다.
INSERT를 사용하는 OPENXML 문은 이러한 행 집합의 데이터를 데이터베이스 테이블에 삽입할 수 있습니다. 여러 OPENXML 호출을 사용하여 XML 문서의 다양한 부분에 대한 행 집합 보기를 제공하고 이들을 다른 테이블에 삽입하는 것과 같은 다양한 방법으로 이들을 처리할 수 있습니다. 이 프로세스를 XML을 테이블로 조각화하는 것이라고도 합니다.
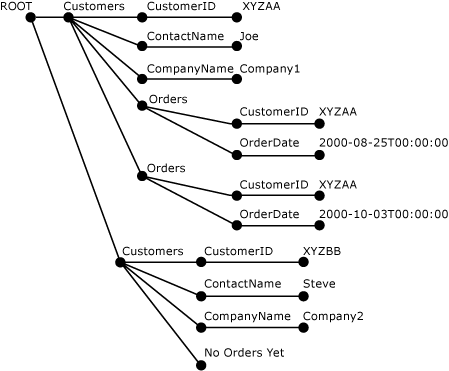
다음 예제에서 XML 문서는 두 가지 <Customers> 문을 사용하여 Customers 요소들이 <Orders> 테이블에 저장되고, Orders 요소들은 INSERT 테이블에 저장되는 방식으로 조각화됩니다. 또한, 이 예제는 XML 문서에서 SELECT과 OPENXML를 검색하는 CustomerID가 포함된 OrderDate 문을 줍니다. 마지막 단계는 함수에서 sp_xml_removedocument.를 호출하는 것입니다. 이는 구문 분석 단계에서 생성된 내부 XML 트리 표현을 포함하도록 할당된 메모리를 해제하기 위해 수행됩니다.
-- Create tables for later population using OPENXML.
CREATE TABLE Customers (CustomerID varchar(20) primary key,
ContactName varchar(20),
CompanyName varchar(20));
GO
CREATE TABLE Orders( CustomerID varchar(20), OrderDate datetime);
GO
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max); -- or xml type
SET @xmlDocument = N'<ROOT>
<Customers CustomerID="XYZAA" ContactName="Joe" CompanyName="Company1">
<Orders CustomerID="XYZAA" OrderDate="2000-08-25T00:00:00"/>
<Orders CustomerID="XYZAA" OrderDate="2000-10-03T00:00:00"/>
</Customers>
<Customers CustomerID="XYZBB" ContactName="Steve"
CompanyName="Company2">No Orders yet!
</Customers>
</ROOT>';
EXEC sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
-- Use OPENXML to provide rowset consisting of customer data.
INSERT Customers
SELECT *
FROM OPENXML(@docHandle, N'/ROOT/Customers')
WITH Customers;
-- Use OPENXML to provide rowset consisting of order data.
INSERT Orders
SELECT *
FROM OPENXML(@docHandle, N'//Orders')
WITH Orders;
-- Using OPENXML in a SELECT statement.
SELECT * FROM OPENXML(@docHandle, N'/ROOT/Customers/Orders')
WITH (CustomerID nchar(5) '../@CustomerID', OrderDate datetime);
-- Remove the internal representation of the XML document.
EXEC sp_xml_removedocument @docHandle;
다음의 그림은 sp_xml_preparedocument 사용하여 만든 이전dml XML 문서의 구문 분석된 XML 트리를 보여 줍니다.
OPENXML 매개 변수
OPENXML에 대한 매개 변수에는 다음이 포함됩니다.
XML 문서 핸들(idoc)
행에 매핑될 노드를 식별하기 위한 XPath 식(rowpattern)
생성할 행 집합의 설명입니다
행 집합 열과 XML 노드 간의 매핑
XML 문서 핸들(idoc)
문서 핸들은 sp_xml_preparedocument 저장 프로시저에서 반환됩니다.
처리될 노드를 식별하기 위한 XPath 식(rowpattern)
rowpattern 으로 지정된 XPath 식은 XML 문서의 노드 집합을 식별합니다. rowpattern으로 식별되는 각 노드는 OPENXML에서 생성되는 행 집합의 단일 행에 해당합니다.
XPath 식으로 식별되는 노드는 XML 문서의 XML 노드일 수 있습니다. rowpattern이 XML 문서의 일련의 요소 집합을 식별하는 경우 식별되는 각 요소 노드에 대한 행 집합에는 한 개의 행이 있게 됩니다. 예를 들어 rowpattern이 특성으로 끝나는 경우에는 rowpattern에 의해 지정된 각 특성 노드에 대해 한 개의 행이 생성됩니다.
생성할 행 집합의 설명입니다
행 집합 스키마는 결과 행 집합을 생성하기 위해 OPENXML에 의해 사용됩니다. 행 집합 스키마를 지정할 때 다음의 옵션을 사용할 수 있습니다.
Edge 테이블 형식 사용
행 집합 스키마를 지정하기 위해 Edge 테이블 형식을 사용해야 합니다. WITH 절을 사용하지 마십시오.
이렇게 하면 OPENXML은 Edge 테이블 형식에서 행 집합을 반환합니다. 이 테이블은 구문 분석된 XML 문서 트리의 가장 자리에 있는 모든 노드가 행 집합의 행으로 매핑되기 때문에 Edge 테이블이라고 부릅니다.
Edge 테이블은 단일 테이블 내에서 세분화된 XML 문서 구조를 나타냅니다. 이러한 구조에는 요소 및 특성 이름, 문서 계층, 네임스페이스 및 처리 명령 검색이 포함됩니다. Edge 테이블 형식을 사용하면 메타 속성을 통해 제공되지 않은 정보를 추가로 얻을 수 있습니다. OPENXML에서 메타 속성을 지정하는 방법은 OPENXML에 메타 속성 지정을 참조하세요.
Edge 테이블에서 제공되는 추가 정보를 사용하면 요소 및 특성의 데이터 형식과 노드 유형을 저장 및 쿼리할 수 있으며 XML 문서 구조에 대한 정보를 저장 및 쿼리할 수도 있습니다. 이 추가 정보를 사용하여 사용자 고유의 XML 문서 관리 시스템을 빌드할 수도 있습니다.
Edge 테이블을 사용하면 XML 문서를 BLOB(Binary Large Object) 입력으로 사용하고 Edge 테이블을 생성한 다음 보다 세부적인 수준에서 문서를 추출 및 분석하는 저장 프로시저를 작성할 수 있습니다. 이러한 세부적인 수준에는 문서 계층, 요소 및 특성 이름, 네임스페이스 및 처리 명령 검색이 포함됩니다.
또한 Edge 테이블은 다른 관계형 형식에 대한 매핑이 논리적이지 않은 경우와 ntext 필드가 구조 정보를 충분히 제공하지 않는 경우, XML 문서에 대한 스토리지 형식으로 사용할 수 있습니다.
XML 파서를 사용하여 XML 문서를 검사할 수 있는 경우 Edge 테이블을 대신 사용해도 동일한 정보를 가져올 수 있습니다.
다음 표에서는 edge 테이블의 구조에 대해 설명합니다.
| 열 이름 | 데이터 형식 | Description |
|---|---|---|
| id | bigint | 문서 노드의 고유 ID입니다. 루트 요소의 ID 값은 0입니다. 음수 ID 값은 예약된 값입니다. |
| parentid | bigint | 노드의 부모를 나타냅니다. 이 ID로 식별된 부모는 부모 요소가 아닐 수도 있습니다. 하지만, 이는 부모가 이 ID로 식별되는 노드의 NodeType에 따라 달라집니다. 예를 들어 노드가 텍스트 노드인 경우 해당 부모는 특성 노드일 수 있습니다. 노드가 XML 문서의 최상위 수준에 있으면 해당 ParentID 는 NULL입니다. |
| Node 형식 | int | 노드 형식을 식별하며 DOM(XML 개체 모델) 노드 형식 번호 부여와 일치하는 정수입니다. 다음은 이 열에 표시될 수 있는 노드 유형을 나타내는 값입니다. 1 = 요소 노드 2 = 특성 노드 3 = 텍스트 노드 4 = CDATA 섹션 노드 5 = 엔터티 참조 노드 6 = 엔터티 노드 7 = 처리 명령 노드 8 = 주석 노드 9 = 문서 노드 10 = 문서 형식 노드 11 = 문서 조각 노드 12 = 표기법 노드 자세한 내용은 MSXML(Microsoft XML) SDK의 "nodeType 속성" 문서를 참조하세요. |
| localname | nvarchar(max) | 요소 또는 특성의 로컬 이름을 지정합니다. DOM 개체에 이름이 없는 경우에는 NULL입니다. |
| prefix | nvarchar(max) | 노드 이름의 네임스페이스 접두사입니다. |
| namespaceuri | nvarchar(max) | 노드의 네임스페이스 URI입니다. 값이 NULL이면 네임스페이스가 없는 것입니다. |
| datatype | nvarchar(max) | 요소 또는 특성 행의 실제 데이터 형식이며, 그렇지 않은 경우에는 NULL입니다. 데이터 형식은 인라인 DTD 또는 인라인 스키마로부터 추정할 수 있습니다. |
| prev | bigint | 이전의 형제 요소에 대한 XML ID입니다. 바로 이전의 형제가 없으면 NULL입니다. |
| text | ntext | 특성 값 또는 텍스트 형식의 요소 내용이 포함됩니다. 또는 Edge 테이블 항목에 값이 필요하지 않은 경우 NULL입니다. |
WITH 절을 사용하여 기존 테이블 지정
WITH 절을 사용하여 기존 테이블의 이름을 지정할 수 있습니다. 이를 위해서는 행 집합을 생성하는 데 OPENXML로 스키마를 사용할 수 있는 기존 테이블 이름을 지정하기만 하면 됩니다.
WITH 절을 사용하여 스키마 지정
WITH 절을 사용하여 전체 스키마를 지정할 수 있습니다. 행 집합 스키마를 지정할 때 열 이름, 해당 데이터 형식 및 XML 문서에 대한 매핑을 지정합니다.
SchemaDeclaration에서 ColPattern 매개 변수를 사용하여 열 패턴을 지정할 수 있습니다. 지정된 열 패턴은 행 집합 열을 rowpattern으로 식별되는 XML 노드에 매핑하는 데 사용되며 매핑 유형을 결정하는 데도 사용됩니다.
열에 대해 ColPattern을 지정하지 않으면 행 집합 열은 플래그 매개 변수에 의해 지정된 매핑을 기준으로 동일한 이름의 XML 노드에 매핑됩니다. 그러나 ColPattern이 WITH 절에서 스키마 지정의 일부로 지정된 경우에는 flags 매개 변수에 지정된 매핑을 덮어씁니다.
행 집합 열과 XML 노드 간 매핑
OPENXML 문에서 행 집합 열과 rowpattern으로 식별되는 XML 노드 간 특성 중심 또는 요소 중심과 같은 매핑 형식을 선택적으로 지정할 수 있습니다. 이 정보는 XML 노드와 행 집합 열 간 변환에 사용됩니다.
두 가지 방법으로 매핑을 지정할 수 있으며 두 가지 모두를 지정할 수도 있습니다.
flags 매개 변수 사용
flags 매개 변수로 지정되는 매핑은 XML 노드가 동일한 이름을 가진 해당 행 집합 열에 매핑되는 이름 일치를 전제로 합니다.
ColPattern 매개 변수 사용
XPath 식인ColPattern은 WITH 절에서 SchemaDeclaration 의 일부로 지정됩니다. ColPattern 에 지정된 매핑은 flags 매개 변수로 지정된 매핑에 우선합니다.
ColPattern을 사용하여 flags로 표시된 기본 매핑을 덮어쓰거나 향상시키는 특성 중심 또는 요소 중심과 같은 매핑 유형을 지정할 수 있습니다.
ColPattern은 다음과 같은 상황에서 지정됩니다.
행 집합의 열 이름은 매핑되는 요소 또는 특성 이름과 다릅니다. 이러한 경우 ColPattern은 행 집합 열이 매핑되는 XML 요소 및 특성 이름을 식별하는 데 사용됩니다.
메타 속성 특성을 열에 매핑하려는 경우. 이러한 경우 ColPattern은 행 집합 열이 매핑되는 메타 속성을 식별하는 데 사용됩니다. 메타 속성을 지정하는 방법은 OPENXML에 메타 속성 지정을 참조하세요.
flags와 ColPattern 매개 변수는 모두 선택 사항입니다. 매핑을 지정하지 않으면 특성 중심 매핑이 가정됩니다. 특성 중심 매핑은 flags 매개 변수의 기본값입니다.
특성 중심 매핑
OPENXML의 flags 매개 변수를 1(XML_ATTRIBUTES)로 설정하면 특성 중심 매핑이 지정됩니다. flags에 XML_ ATTRIBUTES가 포함된 경우 노출된 행 집합은 각 XML 요소가 행으로 표시되는 행을 제공하거나 사용합니다. XML 특성은 이름 대응에 따라 SchemaDeclaration에 정의되거나 WITH 절의 TableName에서 제공하는 특성에 매핑됩니다. 이름 대응은 특정 이름의 XML 특성이 같은 이름의 행 집합에 있는 열에 저장된다는 것을 의미합니다.
열 이름이 매핑되는 특성 이름과 다른 경우 ColPattern을 지정해야 합니다.
XML 특성에 네임스페이스 한정자이 있는 경우 행 집합의 열 이름에도 한정자가 있어야 합니다.
요소 중심 매핑
OPENXML의 flags 매개 변수를 2(XML_ELEMENTS)로 설정하면 요소 중심 매핑이 지정됩니다. 요소 중심 매핑은 다음 사항을 제외하고 특성 중심 매핑과 비슷합니다.
매핑 예제의 이름 대응이며, 열 수준 패턴이 지정되어 있지 않는 한 이름이 같은 XML 요소에 대한 열 매핑은 호환되지 않는 하위 요소를 선택합니다. 검색 프로세스에서 하위 요소에 추가 하위 요소가 포함되어 있기 때문에 복잡한 경우 열은 NULL로 설정됩니다. 그런 다음 하위 요소의 특성 값은 무시됩니다.
동일 이름의 하위 요소가 여러 개 있는 경우 첫 번째 노드가 반환됩니다.