적용 대상:![]() SQL Server
SQL Server
SQL Server Always On 장애 조치(failover) 클러스터 인스턴스는 WSFC(Windows Server 장애 조치(failover) 클러스터링)를 사용하여 로컬 고가용성을 제공합니다. FCI(장애 조치(failover) 클러스터 인스턴스)는 서버 인스턴스 수준에서 중복됩니다. FCI는 Windows Server 클러스터 노드 및 여러 서브넷에 설치된 SQL Server의 단일 인스턴스입니다. 네트워크에서 FCI는 단일 컴퓨터에서 실행되는 SQL Server 인스턴스처럼 보이지만 현재 노드를 사용할 수 없을 경우 FCI가 하나의 WSFC 노드에서 다른 노드로 장애 조치(failover) 기능을 제공합니다.
FCI는 Always On 가용성 그룹을 사용하여 데이터베이스 수준에서 원격 재해 복구 기능을 제공할 수 있습니다. 자세한 내용은 장애 조치(failover) 클러스터링 및 Always On 가용성 그룹(SQL Server)을 참조하세요.
SQL Server 장애 조치(failover) 클러스터 인스턴스는 Windows Server 2016 Datacenter 버전에서 도입된 클러스터 스토리지 리소스에 대한 스토리지 공간 다이렉트를 지원합니다. 자세한 내용은 Windows Server의 스토리지 공간 다이렉트를 참조하세요.
장애 조치(failover) 클러스터 인스턴스는 CSV(클러스터 공유 볼륨)도 지원합니다. 자세한 내용은 장애 조치(failover) 클러스터의 클러스터 공유 볼륨 이해를 참조하세요.
참고
SQL Server 2025(17.x)에서는 장애 조치(failover) 클러스터 인스턴스에 엄격한 연결을 적용 하도록 지원합니다.
장애 조치(failover) 클러스터 인스턴스의 이점
서버 하드웨어 또는 소프트웨어 오류가 발생하면 서버에 연결하는 애플리케이션 또는 클라이언트에서 가동 중지 시간이 발생합니다. 중복 노드는 독립 실행형 인스턴스가 아닌 FCI인 경우 SQL Server 인스턴스의 가용성을 보호합니다. FCI에 있는 여러 노드 중에서 WSFC 리소스 그룹을 소유하는 노드는 한 번에 하나뿐입니다. 하드웨어 오류, 운영 체제 오류, 애플리케이션 또는 서비스 오류와 같은 오류가 발생하거나 계획된 업그레이드 중에 클러스터가 리소스 그룹 소유권을 다른 WSFC 노드로 이동합니다. 이 프로세스는 SQL Server에 연결하는 클라이언트 또는 애플리케이션에 투명합니다. 이 프로세스는 실패 시 애플리케이션 또는 클라이언트가 경험하는 가동 중지 시간을 최소화합니다. SQL Server 장애 조치(failover) 클러스터 인스턴스가 제공하는 몇 가지 주요 이점은 다음과 같습니다.
중복을 통한 인스턴스 수준의 보호.
오류가 발생할 경우(하드웨어 오류, 운영 체제 오류, 애플리케이션 및 서비스 오류 포함) 자동으로 장애 조치(failover)가 실행됩니다.
중요합니다
가용성 그룹에서는 FCI에서 가용성 그룹 내의 다른 노드로의 자동 장애 조치(failover)가 지원되지 않습니다. 따라서 자동 장애 조치가 고가용성 솔루션의 중요한 구성 요소인 경우 FCI와 독립 실행형 노드를 가용성 그룹 내에서 함께 결합하면 안 됩니다. 그러나 재해 복구 솔루션에 대해서는 이러한 연결이 가능합니다.
WSFC 클러스터 디스크(iSCSI, 파이버 채널 등) 및 SMB(서버 메시지 블록) 파일 공유를 비롯한 광범위한 스토리지 솔루션 지원
다중 서브넷 FCI를 통해 재해 복구하거나 가용성 그룹 내에서 FCI 호스팅 데이터베이스를 실행합니다. SQL Server 2012(11.x)의 다중 서브넷 지원을 사용하면 다중 서브넷 FCI에 가상 LAN이 필요하지 않습니다. 이 지원을 통해 다중 서브넷 FCI의 관리 효율성과 보안이 향상됩니다.
장애 조치(failover) 중 애플리케이션 및 클라이언트를 재구성할 필요 없음.
자동 장애 조치(failover)를 위해 세부적인 트리거 이벤트에 대한 유연한 장애 조치(failover) 정책.
전용 및 영구 연결을 사용하는 정기적이고 세부적인 상태 검색을 통한 안정적인 장애 조치(failover).
간접 백그라운드 검사점을 통해 장애 조치(failover) 시간에 대한 구성 및 예측 가능.
장애 조치(failover) 중 리소스 사용 조절.
권장 사항
프로덕션 환경에서는 장애 조치(failover) 클러스터 인스턴스의 가상 IP 주소와 함께 고정 IP 주소를 사용합니다.
프로덕션 환경에서는 DHCP를 사용하지 마세요. 가동 중지 시간이 발생하는 경우 DHCP IP 임대가 만료되면 DNS 이름과 연결된 새 DHCP IP 주소를 다시 등록하는 데 추가 시간이 필요합니다.
장애 조치 클러스터 인스턴스 개요
FCI는 WSFC 노드가 하나 이상 포함된 WSFC 리소스 그룹에서 실행됩니다. FCI가 시작되면 노드 중 하나가 리소스 그룹의 소유권을 갖고 해당 SQL Server 인스턴스를 온라인으로 설정합니다. 이 노드가 소유하는 리소스는 다음과 같습니다.
- 네트워크 이름
- IP 주소
- 공유 디스크
- SQL Server 데이터베이스 엔진 서비스
- SQL Server 에이전트 서비스
- SQL Server Analysis Services 서비스가 설치된 경우
- 파일 공유 리소스 하나(FILESTREAM 기능이 설치된 경우)
리소스 그룹에서 해당 SQL Server 서비스를 실행하는 노드는 언제라도 해당 리소스 그룹 소유자뿐이며 FCI의 다른 노드는 서비스를 실행할 수 없습니다. 장애 조치(failover)가 자동 장애 조치(failover) 또는 계획된 장애 조치(failover)인지에 관계없이 다음과 같은 이벤트 시퀀스가 발생합니다.
하드웨어 또는 시스템 오류가 발생하지 않은 한 버퍼 캐시에 있는 모든 더티 페이지가 디스크에 기록됩니다.
리소스 그룹의 모든 해당 SQL Server 서비스가 현재 노드에서 중지됩니다.
리소스 그룹 소유권은 FCI의 다른 노드로 전송됩니다.
새 리소스 그룹 소유자가 SQL Server 서비스를 시작합니다.
클라이언트 애플리케이션 연결 요청은 동일한 가상 네트워크 이름을 사용하여 새 활성 노드로 자동으로 전달됩니다.
FCI는 기본 WSFC 클러스터가 양수 쿼럼 상태인 한 온라인 상태입니다. (대부분의 쿼럼 WSFC 노드는 자동 장애 조치 대상으로 사용할 수 있습니다.) 하드웨어, 소프트웨어 또는 네트워크 오류 또는 부적절한 쿼럼 구성으로 인해 WSFC 클러스터가 쿼럼을 잃으면 FCI와 함께 전체 WSFC 클러스터가 오프라인 상태가 됩니다. 이러한 계획되지 않은 장애 조치(failover) 시나리오에서는 WSFC 클러스터 및 FCI를 다시 온라인으로 설정하기 위해 사용 가능한 남은 노드에서 쿼럼을 다시 설정하도록 수동 개입이 필요합니다. 자세한 내용은 WSFC 쿼럼 모드 및 투표 구성(SQL Server)을 참조하세요.
예측 가능한 장애 조치(failover) 시간
SQL Server 인스턴스가 검사점 작업을 마지막으로 언제 수행했는지에 따라 버퍼 캐시에 더티 페이지가 대량으로 남아 있을 수 있습니다. 따라서 남은 더티 페이지를 디스크에 기록하기 위한 시간만큼 장애 조치(failover)가 지속되어 장애 조치(failover) 시간이 오래 걸리고 예측할 수 없게 될 수 있습니다. SQL Server 2012(11.x)부터 FCI는 간접 검사점을 사용하여 버퍼 캐시에 보관된 더티 페이지 수를 제한할 수 있습니다. 이렇게 하면 일반 워크로드에서 더 많은 리소스를 사용하지만 장애 조치(failover) 시간을 더 예측 가능하고 더 쉽게 구성할 수 있습니다. 이는 조직의 서비스 수준 계약이 고가용성 솔루션에 대한 RTO(복구 시간 목표)를 지정하는 경우에 유용합니다. 자세한 내용은 간접 검사점을 참조하세요.
안정적인 상태 모니터링 및 유연한 장애 조치(failover) 정책
FCI가 성공적으로 시작되면 WSFC 서비스는 기본 WSFC 클러스터의 상태와 SQL Server 인스턴스의 상태를 모두 모니터링합니다. SQL Server 2012(11.x)부터 WSFC 서비스는 전용 연결을 사용하여 시스템 저장 프로시저를 통해 활성 SQL Server 인스턴스에서 자세한 구성 요소 진단을 폴링합니다. 다음과 같은 세 가지 결과가 발생합니다.
SQL Server 인스턴스에 대한 전용 연결을 통해 FCI의 부하가 높더라도 항상 구성 요소 진단을 위해 폴링을 안정적으로 수행할 수 있습니다. 이 기능을 사용하면 부하가 많은 시스템과 오류 조건이 있는 시스템을 구분하여 잘못된 장애 조치(failover)와 같은 문제를 방지할 수 있습니다.
자세한 구성 요소 진단을 사용하면 보다 유연한 장애 조치(failover) 정책을 구성할 수 있으므로 장애 조치(failover)를 트리거하는 오류 조건을 선택할 수 있습니다.
또한 자세한 구성 요소 진단은 자동 장애 조치(failover)에 대한 소급적인 문제 해결에도 도움을 줍니다. 진단 정보는 SQL Server 오류 로그와 함께 배치되는 로그 파일에 저장됩니다. 로그 파일 뷰어에 로드하여 장애 조치(failover) 발생으로 이어지는 구성 요소 상태를 검사하여 장애 조치(failover)의 원인을 확인할 수 있습니다.
자세한 내용은 장애 조치(failover) 클러스터 인스턴스에 대한 장애 조치(failover) 정책을 참조하세요.
TLS 1.3 암호화 구성
SQL Server 2025(17.x)에서는 TDS 8.0 지원을 도입하여 Windows Server 장애 조치 클러스터와 장애 조치(failover) 클러스터 인스턴스 간의 통신에 TLS 1.3 암호화를 적용할 수 있습니다.
시작하려면 엄격한 암호화를 사용하여 연결을 검토합니다.
참고
컴퓨터에서 TLS 1.2가 비활성화되면 SQL Server 2025 (17.x) 장애 조치 클러스터 인스턴스 설치가 실패합니다.
장애 조치(failover) 클러스터 인스턴스의 요소
FCI는 유사한 하드웨어 구성과 운영 체제 버전 및 패치 수준 및 SQL Server 버전, 패치 수준, 구성 요소 및 인스턴스 이름을 포함하는 동일한 소프트웨어 구성을 포함하는 물리적 서버(노드) 집합으로 구성됩니다. 노드 간에 장애 조치(fail over)할 때 FCI가 완벽하게 작동할 수 있도록 하려면 동일한 소프트웨어 구성이 필요합니다.
WSFC 리소스 그룹
SQL Server FCI는 WSFC 리소스 그룹에서 실행됩니다. 리소스 그룹의 각 노드는 장애 조치(failover) 후 FCI의 전체 기능을 보장하기 위해 구성 설정 및 체크 뾰족한 레지스트리 키의 동기화된 복사본을 유지 관리합니다. 클러스터의 노드 중 하나만 한 번에 리소스 그룹(활성 노드)을 소유합니다. WSFC 서비스는 FCI에 대한 가상 네트워크 이름 및 가상 IP 주소 외에도 서버 클러스터, 쿼럼 구성, 장애 조치(failover) 정책 및 장애 조치(failover) 작업을 관리합니다. 오류(하드웨어 오류, 운영 체제 오류, 애플리케이션 및 서비스 오류) 또는 계획된 업그레이드가 있는 경우 리소스 그룹 소유권은 FCI의 다른 노드로 이동됩니다. WSFC 리소스 그룹에서 지원되는 노드 수는 SQL Server 에디션에 따라 달라집니다. 또한 CPU, 메모리 및 디스크 수와 같은 하드웨어 용량에 따라 동일한 WSFC 클러스터가 여러 FCI(다중 리소스 그룹)를 실행할 수 있습니다.
SQL Server 바이너리 파일
제품 이진 파일은 SQL Server 독립 실행형 설치와 유사한 프로세스에서 FCI의 각 노드에 로컬로 설치됩니다. 그러나 시작하는 동안 서비스는 자동으로 시작되지 않고 WSFC에서 관리됩니다.
스토리지
가용성 그룹과 달리 FCI는 데이터베이스 및 로그 스토리지에 FCI의 모든 노드 간에 공유 스토리지를 사용해야 합니다. 공유 스토리지는 WSFC 클러스터 디스크, SAN의 디스크, 스토리지 공간 다이렉트 또는 SMB의 파일 공유 형식일 수 있습니다. 따라서 FCI의 모든 노드는 장애 조치(failover)가 발생할 때마다 인스턴스 데이터의 동일한 보기를 갖습니다. 그러나 공유 스토리지는 단일 실패 지점이 될 가능성이 있으며 FCI는 데이터 보호를 보장하기 위해 기본 스토리지 솔루션에 의존한다는 것을 의미합니다.
네트워크 이름
FCI의 가상 네트워크 이름은 FCI에 대한 통합 연결 지점을 제공합니다. 이 통합 연결점을 사용하면 애플리케이션이 현재 활성 노드를 알 필요 없이 가상 네트워크 이름에 연결할 수 있습니다. 장애 조치(failover)가 발생하면 가상 네트워크 이름이 시작된 후 새 활성 노드에 등록됩니다. 이 프로세스는 SQL Server에 연결하는 클라이언트 또는 애플리케이션에 투명하며 실패 시 애플리케이션 또는 클라이언트에서 발생하는 가동 중지 시간을 최소화합니다.
다음 스크린샷은 장애 조치(failover) 클러스터 관리자의 장애 조치(failover) 클러스터 인스턴스에 대한 네트워크 이름을 보여 줍니다.
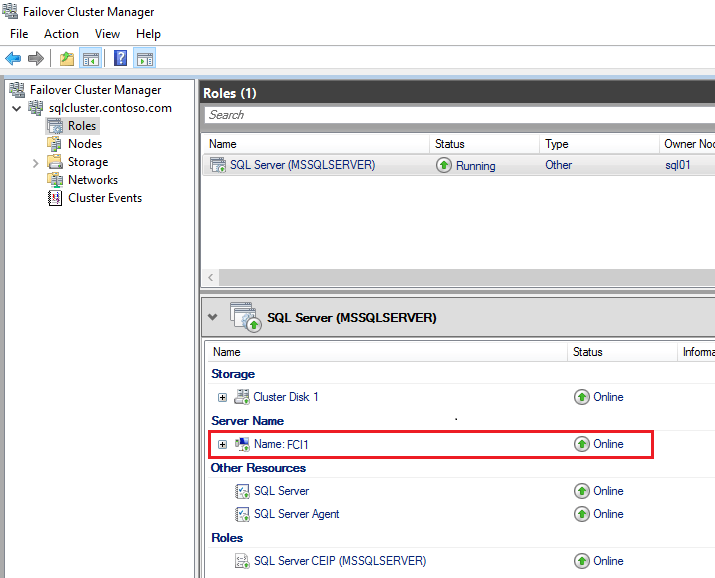
가상 IP
다중 서브넷 FCI의 경우 FCI의 각 서브넷에 가상 IP 주소가 할당됩니다. 장애 조치(failover) 중에 DNS 서버의 가상 네트워크 이름이 각 서브넷의 가상 IP 주소를 가리키도록 업데이트됩니다. 애플리케이션과 클라이언트는 다중 서브넷 장애 조치(failover) 후 동일한 가상 네트워크 이름을 사용하여 FCI에 연결할 수 있습니다.
SQL Server 장애 조치(failover) 개념 및 태스크
| 개념 및 작업 | 조항 |
|---|---|
| 오류 검색 메커니즘과 유연한 장애 조치(failover) 정책에 대해 설명합니다. | 장애 조치(failover) 클러스터 인스턴스에 대한 장애 조치(failover) 정책 |
| FCI 관리 및 유지 관리에 대한 개념을 설명합니다. | 장애 조치(failover) 클러스터 인스턴스 관리 및 유지 관리 |
| 다중 서브넷 구성 및 개념을 설명합니다. | SQL Server 다중 서브넷 클러스터링 |
WSFC에서 SQL Server FCI 지원 구성
WSFC를 기반으로 하는 SQL Server FCI는 다음 제품에서 지원됩니다.
- Windows Server 2012
- 윈도우 서버 2012 R2
- Windows Server 2016 Standard 및 Datacenter 버전
- Windows Server 2019 Standard 및 Datacenter 버전
- Windows Server 2022 Standard 및 Datacenter 버전
Windows Server는 다음 두 가지 유형의 클러스터링 서비스를 제공합니다.
노드가 손실되거나 SQL Server 인스턴스에 문제가 있는 경우 고가용성을 위해 서버 클러스터 솔루션만 SQL Server와 함께 사용할 수 있습니다. 경우에 따라 네트워크 부하 분산을 독립 실행형 읽기 전용 SQL Server 설치와 함께 사용할 수 있습니다.
각 SQL Server FCI에는 다음이 필요합니다.
- 고유하게 할당된 디스크 드라이브 문자가 있는 전용 클러스터 그룹입니다.
- 하나 이상의 고유한 IP 주소입니다.
- 도메인 내의 고유한 가상 서버 및 인스턴스 이름입니다.
비 Microsoft 클러스터 솔루션 지원
SQL Server는 Microsoft 서버 클러스터링을 사용하여 개발 및 테스트됩니다. Microsoft가 아닌 클러스터링 제품을 사용하는 경우 설치, 성능 또는 클러스터 동작 문제에 대한 기본 지원 담당자가 솔루션 공급자여야 합니다. Microsoft는 독립 실행형 SQL Server 배포 지원과 유사하게 비 Microsoft 클러스터 설치에 대해 상업적으로 합리적인 지원을 제공합니다.
지원되는 노드 수
Always On 장애 조치(failover) 클러스터 인스턴스에 대해 지원되는 최대 노드 수에 대한 자세한 내용은 다음을 참조하세요.
지원되는 운영 체제
SQL Server 장애 조치(failover) 클러스터링에 지원되는 운영 체제에 대한 자세한 내용은 장애 조치( failover) 클러스터링을 설치하기 전에 운영 체제 확인을 참조하세요.
탑재된 드라이브
탑재된 드라이브의 사용은 SQL Server 설치를 포함하는 클러스터에서 지원되지 않습니다. 자세한 내용은 탑재된 볼륨에 대한 SQL Server 지원을 참조 하세요.
CSV(클러스터 공유 볼륨)
SQL Server 2012(11.x) 및 이전 버전은 장애 조치(failover) 클러스터에서 SQL Server용 CSV 사용을 지원하지 않습니다.
SQL Server 2014(12.x) 이상 버전에서 CSV를 사용하는 방법에 대한 자세한 내용은 다음 리소스를 참조하세요.
도메인 컨트롤러 제한
SQL Server 장애 조치(failover) 클러스터 인스턴스는 도메인 컨트롤러로 구성된 장애 조치(failover) 클러스터 인스턴스 노드에서 지원되지 않습니다.
도메인 마이그레이션 고려 사항
SQL Server 2005(9.x) 이상 버전은 새 도메인으로 마이그레이션할 수 없습니다. 장애 조치(failover) 클러스터 구성 요소를 제거하고 다시 설치해야 합니다. 자세한 내용은 Windows Server 클러스터를 한 도메인에서 다른 도메인으로 이동을 참조하세요.
SQL Server를 제거하기 전에 다음 단계를 수행해야 합니다.
혼합 모드 보안을 사용하도록 SQL Server를 설정하거나 SQL Server 로그인에 새 도메인 계정을 추가합니다.
다시 설치한
DATA후 다시 교환하여 가동 중지 시간을 줄일 수 있도록 시스템 데이터베이스가 포함된 폴더의 이름을 바꿉니다.전체 노드를 다시 빌드하지 않는 한 SQL Server 지원 파일, SQL Server Native Client, Integration Services 또는 워크스테이션 구성 요소를 제거하지 마세요.
경고
제거 프로세스 중에 오류가 발생하는 경우 SQL Server를 다시 설치하려면 노드를 다시 빌드해야 할 수 있습니다.
관련 콘텐츠
- 새 Always On 장애 조치(failover) 클러스터 인스턴스 만들기(설치)
- 장애 조치 클러스터 인스턴스를 업그레이드합니다
- SQL Server의 Windows Server 장애 조치(Failover) 클러스터링
- 장애 조치(failover) 클러스터링 및 Always On 가용성 그룹(SQL Server)
- Azure Arc 지원 SQL Server
- Azure Arc에서 Always On 장애 조치(failover) 클러스터 인스턴스 보기
- 장애 조치(failover) 클러스터 인스턴스에 대한 장애 조치(failover) 정책
- 하드웨어 가상화 환경에서 실행되는 Microsoft SQL Server 제품에 대한 지원 정책