DBCC SHOW_STATISTICS(Transact-SQL)
적용 대상:![]() Microsoft Fabric의 Microsoft Fabric
Microsoft Fabric의 Microsoft Fabric![]() Warehouse에 있는 SQL Server
Warehouse에 있는 SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Platform System(PDW)
Platform System(PDW)![]() SQL 분석 엔드포인트
SQL 분석 엔드포인트
테이블 또는 인덱싱된 뷰에 대한 현재 쿼리 최적화 통계를 표시합니다. 쿼리 최적화 프로그램은 통계를 사용하여 쿼리 결과의 카디널리티 또는 행 수를 예상하며, 이를 통해 쿼리 최적화 프로그램이 고품질 쿼리 계획을 만들 수 있습니다. 예를 들어 쿼리 최적화 프로그램은 카디널리티 예상치를 통해 쿼리 계획에서 인덱스 스캔 연산자 대신 인덱스 검색 연산자를 선택하여 리소스가 많이 소요되는 인덱스 스캔을 피함으로써 쿼리 성능을 개선할 수 있습니다.
쿼리 최적화 프로그램은 테이블 또는 인덱싱된 뷰에 대한 통계를 통계 개체에 저장합니다. 테이블의 경우 통계 개체는 인덱스 또는 테이블 열의 목록에 생성됩니다. 통계 개체에는 통계에 대한 메타데이터가 있는 헤더, 통계 개체의 첫 번째 키 열에 있는 값의 분포에 대한 히스토그램, 그리고 열 간 상관 관계를 측정하는 밀도 벡터가 포함됩니다. 데이터베이스 엔진은 통계 개체의 일부 데이터를 사용하여 카디널리티 예상치를 계산할 수 있습니다. 자세한 내용은 통계 및 카디널리티 추정(SQL Server)을 참조하세요.
DBCC SHOW_STATISTICS는 통계 개체에 저장된 데이터를 바탕으로 헤더, 히스토그램 및 밀도 벡터를 표시합니다. 이 구문을 사용하면 대상 인덱스 이름, 통계 이름 또는 열 이름과 함께 테이블 또는 인덱싱된 뷰를 지정할 수 있습니다.
이전 버전 SQL Server의 중요한 업데이트:
SQL Server 2012(11.x) 서비스 팩 1부터 sys.dm_db_stats_properties 동적 관리 뷰를 사용하여 비 증분 통계에 대한 통계 개체에 포함된 헤더 정보를 프로그래밍 방식으로 검색할 수 있습니다.
SQL Server 2014(12.x) 서비스 팩 2 및 SQL Server 2012(11.x) 서비스 팩 1부터 sys.dm_db_incremental_stats_properties 동적 관리 뷰를 사용하여 증분 통계에 대한 통계 개체에 포함된 헤더 정보를 프로그래밍 방식으로 검색할 수 있습니다.
SQL Server 2016(13.x) 서비스 팩 1 CU 2부터 sys.dm_db_stats_histogram을 사용하여 통계 개체에 포함된 히스토그램 정보를 프로그래밍 방식으로 검색할 수 있습니다.
-
이 구문은 Azure Synapse Analytics의 서버리스 SQL 풀에서 지원되지 않습니다.
Microsoft Fabric의 통계에 대한 자세한 내용은 통계를 참조 하세요.
구문
SQL Server 및 Azure SQL Database에 대한 구문:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Azure Synapse Analytics, PDW(Analytics Platform System) 및 Microsoft Fabric에 대한 구문:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
참고 항목
SQL Server 2014(12.x) 및 이전 버전에 대한 Transact-SQL 구문을 보려면 이전 버전 설명서를 참조 하세요.
인수
table_or_indexed_view_name
통계 정보를 표시할 테이블 또는 인덱싱된 뷰의 이름입니다.
table_name
표시할 통계가 들어 있는 테이블의 이름입니다. 테이블은 외부 테이블일 수 없습니다.
대상
통계 정보를 표시할 인덱스, 통계 또는 열의 이름입니다. 대상은 대괄호, 작은 따옴표, 큰 따옴표 또는 따옴표 없음으로 묶입니다.
- target이 테이블 또는 인덱싱된 뷰의 기존 인덱스 또는 통계 이름인 경우 이 대상에 대한 통계 정보가 반환됩니다.
- target이 기존 열의 이름이고 이 열에 자동으로 생성된 통계 개체가 있는 경우 자동 생성된 통계에 대한 정보가 반환되며,
열 대상에 대해 자동으로 생성된 통계가 없으면 오류 메시지 2767이 반환됩니다.
Azure Synapse Analytics 및 PDW(Analytics Platform System)에서 대상 은 열 이름이 될 수 없습니다.
Microsoft Fabric 의 Warehouse에서 대상 은 단일 열 히스토그램 통계의 이름 또는 열일 수 있습니다. 대상에 열 이름을 사용하는 경우 이 명령은 자동으로 생성된 히스토그램 통계에 대한 배포 정보만 반환합니다. 수동으로 만든 히스토그램 통계에 대한 정보를 보려면 통계 이름을 대상으로 지정합니다.
NO_INFOMSGS
심각도가 0에서 10 사이인 모든 정보 메시지를 표시하지 않습니다.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
이 옵션 중 하나 이상을 지정하면 문에서 반환하는 결과 집합이 지정한 옵션으로 제한됩니다. 옵션을 지정하지 않으면 모든 통계 정보가 반환됩니다.
STATS_STREAM은 정보를 제공하기 위해서만 확인됩니다. 지원 안 됨 향후 호환성은 보장되지 않습니다.
결과 집합
다음 표에서는 STAT_HEADER를 지정한 경우 결과 집합에 반환되는 열을 설명합니다.
| 열 이름 | 설명 |
|---|---|
| Name | 통계 개체의 이름입니다. |
| 업데이트 | 통계가 마지막으로 업데이트된 날짜와 시간입니다. STATS_DATE 함수를 사용하여 이 정보를 검색할 수도 있습니다. 자세한 내용은 이 페이지의 주의 섹션을 참조하세요. |
| 행 | 통계가 마지막으로 업데이트되었을 때 테이블 또는 인덱싱된 뷰의 전체 행 수입니다. 통계가 필터링되거나 필터링된 인덱스에 해당하는 경우 행 수가 테이블의 행 수보다 적을 수 있습니다. 자세한 내용은 통계를 참조하세요. |
| 샘플링한 행 | 통계 계산을 위해 샘플링된 전체 행 수입니다. 샘플링된 행 수가 전체 행 수보다 적은 경우 표시되는 히스토그램과 밀도 결과는 샘플링된 행을 기준으로 하는 예상치입니다. |
| 단계 | 히스토그램의 총 단계 수입니다. 각 단계의 범위는 열 값에서 상한 열 값까지입니다. 히스토그램 단계는 통계의 첫 번째 키 열에 정의됩니다. 최대 단계 수는 200개입니다. |
| 밀도 | 히스토그램 경계 값을 제외하고 통계 개체의 첫 번째 키 열에 있는 모든 값에 대해 1/ 고유 값 으로 계산됩니다. 이 밀도 값은 쿼리 최적화 프로그램에서 사용되지 않으며 SQL Server 2008(10.0.x) 이전 버전과의 호환성을 위해 표시됩니다. |
| 평균 키 길이 | 통계 개체의 키 열에 있는 모든 값에 대한 값당 평균 바이트 수입니다. |
| 문자열 인덱스 | '예'는 통계 개체에 LIKE 연산자를 사용하는 쿼리 조건자(예: WHERE ProductName LIKE '%Bike')의 카디널리티 예상치 정확도를 높이기 위한 문자열 요약 통계가 있음을 나타냅니다. 문자열 요약 통계는 히스토그램과 별도로 저장되며 char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), nvarchar(max), text 또는 ntext 형식인 경우 통계 개체의 첫 번째 키 열에 생성됩니다. |
| 필터 식 | 통계 개체에 포함된 테이블 행의 하위 집합에 대한 조건자입니다. NULL = 필터링되지 않은 통계입니다. 필터링된 조건자에 대한 자세한 내용은 필터링된 인덱스 만들기를 참조하세요. 필터링된 통계에 대한 자세한 내용은 통계를 참조하세요. |
| 필터링되지 않은 행 | 필터 식을 적용하기 전 테이블에 있는 전체 행 수입니다. Filter 식이 NULL이면 Unfiltered Rows는 Rows와 같습니다. |
| 지속된 샘플 비율 | 샘플링 비율을 명시적으로 지정하지 않는 통계 업데이트에 사용되는 지속형 샘플 백분율입니다. 값이 0이면 이 통계에 대해 지속 된 샘플 백분율이 설정되지 않습니다. 적용 대상: SQL Server 2016(13.x) 서비스 팩 1 CU 4 |
다음 표에서는 DENSITY_VECTOR를 지정한 경우 결과 집합에 반환되는 열을 설명합니다.
| 열 이름 | Description |
|---|---|
| 모든 밀도 | 밀도는 1/ 고유 값입니다. 결과에는 통계 개체에 있는 각 열 접두사의 밀도가 한 행씩 표시됩니다. 고유 값은 행별 및 열 접두사별 열 값의 고유한 목록입니다. 예를 들어 통계 개체가 키 열 (A, B, C)를 포함하는 경우 결과에서 밀도는 이러한 각 열 접두사의 고유 값 목록인 (A), (A,B) 및 (A, B, C)로 보고됩니다. 접두사 (A, B, C)를 사용하면 이러한 각 목록은 다음과 같은 고유 값 목록입니다. (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). 접두사 (A, B)를 사용하면 동일한 열 값은 고유 값 목록 (3, 5), (4, 4) 및 (4, 5)를 가집니다. |
| 평균 길이 | 열 접두사의 열 값 목록을 저장하기 위한 평균 길이(바이트)입니다. 예를 들어 목록 (3, 5, 6)의 각 값에 4바이트가 필요한 경우 길이는 12바이트입니다. |
| 열 | 모든 밀도 및 평균 길이가 표시되는 접두사의 열 이름입니다. |
다음 표에서는 HISTOGRAM 옵션을 지정한 경우 결과 집합에 반환된 열을 설명합니다.
| 열 이름 | Description |
|---|---|
| RANGE_HI_KEY | 히스토그램 단계의 상한 열 값입니다. 열 값은 키 값이라고도 합니다. |
| RANGE_ROWS | 상한을 제외한 히스토그램 단계 내에 열 값이 있는 예상 행 수입니다. |
| EQ_ROWS | 히스토그램 단계에서 상한과 열 값이 동일한 예상 행 수입니다. |
| DISTINCT_RANGE_ROWS | 상한을 제외한 히스토그램 단계 내에 고유한 열 값이 있는 예상 행 수입니다. |
| AVG_RANGE_ROWS | 히스토그램 단계 내에 중복된 열 값이 있는 평균 행 수(상한 제외)입니다. DISTINCT_RANGE_ROWS가 0보다 크면 AVG_RANGE_ROWS는 RANGE_ROWS를 DISTINCT_RANGE_ROWS로 나누어 계산합니다. DISTINCT_RANGE_ROWS가 0이면 AVG_RANGE_ROWS는 히스토그램 단계에 대해 1을 반환합니다. |
설명
통계 업데이트 날짜는 히스토그램 및 밀도 벡터와 함께 메타데이터가 아닌 통계 BLOB 개체에 저장됩니다. 통계 데이터를 생성하기 위해 데이터를 읽지 않으면 통계 Blob이 생성되지 않고 날짜를 사용할 수 없으며 업데이트된 열이 NULL있습니다. 조건자가 행을 반환하지 않는 필터링된 통계 또는 빈 새 테이블의 경우입니다.
히스토그램
히스토그램은 데이터 집합에서 각 고유 값의 발생 빈도를 측정합니다. 쿼리 최적화 프로그램은 행을 통계적으로 샘플링하거나 테이블 또는 뷰의 모든 행에 대해 전체 검색을 수행하는 방법으로 열 값을 선택하여 통계 개체의 첫 번째 키 열에 있는 열 값에 대한 히스토그램을 계산합니다. 샘플링된 행 집합에서 히스토그램을 만드는 경우 행 수 및 고유 값 수에 대해 저장된 합계는 예상치이며 정수일 필요는 없습니다.
쿼리 최적화 프로그램에서는 히스토그램을 만들기 위해 열 값을 정렬하고 고유한 각 열 값과 일치하는 값의 수를 계산한 다음 열 값을 최대 200개의 연속적인 히스토그램 단계로 집계합니다. 각 단계의 범위는 열 값에서 상한 열 값까지입니다. 범위는 경계 값 자체를 제외하고 경계 값 사이의 모든 가능한 열 값을 포함합니다. 정렬된 열 값 중 가장 낮은 값은 첫 번째 히스토그램 단계의 상한 값입니다.
다음 다이어그램에서는 6단계의 히스토그램을 보여 줍니다. 첫 번째 상한 값 왼쪽의 영역이 1단계입니다.

각 히스토그램 단계를 살펴보면 다음과 같습니다.
- 굵은 선은 상한 값(RANGE_HI_KEY)과 발생한 횟수(EQ_ROWS)를 나타냅니다.
- RANGE_HI_KEY 왼쪽의 채워진 영역은 열 값의 범위와 각 열 값이 발생한 평균 횟수(AVG_RANGE_ROWS)를 나타냅니다. 첫 번째 히스토그램 단계의 AVG_RANGE_ROWS는 항상 0입니다.
- 점선은 범위 내 고유 값의 총 개수(DISTINCT_RANGE_ROWS) 및 범위 내 값의 총 개수(RANGE_ROWS)를 예상하는 데 사용되는 샘플링된 값을 나타냅니다. 쿼리 최적화 프로그램은 RANGE_ROWS 및 DISTINCT_RANGE_ROWS 사용하여 AVG_RANGE_ROWS 계산하고 샘플링된 값을 저장하지 않습니다.
쿼리 최적화 프로그램은 통계적 중요성에 따라 히스토그램 단계를 정의합니다. 또한 히스토그램의 단계 수를 최소화하면서 경계 값 간의 차이를 최대화하기 위해 최대 차이 알고리즘을 사용합니다. 최대 단계 수는 200개입니다. 히스토그램 단계 수는 경계 지점이 200개 미만인 열에서도 고유 값의 개수보다 적을 수 있습니다. 예를 들어 100개의 고유 값을 가진 열의 히스토그램에 100개 미만의 경계 지점이 있을 수 있습니다.
밀도 벡터
쿼리 최적화 프로그램은 같은 테이블 또는 인덱싱된 뷰에서 여러 열을 반환하는 쿼리의 카디널리티 예상치 정확도를 높이기 위해 밀도를 사용합니다. 밀도 벡터는 통계 개체에 있는 각 열 접두사당 한 개의 밀도를 포함합니다. 예를 들어 통계 개체에 CustomerId, ItemId, Price 키 열이 있는 경우 다음의 각 열 접두사에 대해 밀도가 계산됩니다.
| 열 접두사 | 밀도 계산 기준 |
|---|---|
(CustomerId) |
일치하는 값이 있는 행 CustomerId |
(CustomerId, ItemId) |
일치하는 값 CustomerId 이 있는 행 및 ItemId |
(CustomerId, ItemId, Price) |
에 대한 CustomerIdItemId값이 일치하는 행 및Price |
제한 사항
DBCC SHOW_STATISTICS 는 공간 인덱스 또는 메모리 최적화 columnstore 인덱스에 대한 통계를 제공하지 않습니다.
SQL Server 및 SQL Database 권한
통계 개체를 보려면 사용자에게 테이블에 대한 SELECT 권한이 있어야 합니다.
다음 요구 사항에서는 명령을 실행하기 위해 SELECT 권한이 있어야 합니다.
- 사용자는 통계 개체의 모든 열에 대해 권한이 있어야 합니다.
- 사용자는 필터 조건(있는 경우)에서 모든 열에 대해 권한이 있어야 합니다.
- 테이블에 행 수준 보안 정책이 있을 수 없습니다.
- 통계 개체 내의 열이 사용 권한 외에도
SELECT동적 데이터 마스킹 규칙으로 마스킹되는 경우 사용자에게 권한이 있거나 db_ddladmin 역할의 멤버여야 합니다UNMASK.
SQL Server 2012(11.x) 서비스 팩 1 이전 버전에서는 사용자가 테이블을 소유해야 합니다. 또는 사용자가 sysadmin 고정 서버 역할, db_owner 고정 데이터베이스 역할 또는 db_ddladmin 고정 데이터베이스 역할의 멤버여야 합니다.
참고 항목
이전 SQL Server 2012(11.x) 서비스 팩 1 동작으로 동작을 다시 변경하려면 추적 플래그 9485를 사용합니다.
Azure Synapse Analytics 및 Analytics Platform System(PDW) 권한
DBCC SHOW_STATISTICS에는 SELECT sysadmin 고정 서버 역할, db_owner 고정 데이터베이스 역할 또는 db_ddladmin 고정 데이터베이스 역할의 멤버 자격이 필요합니다.
Azure Synapse Analytics 및 분석 플랫폼 시스템(PDW)에 대한 제한 사항
DBCC SHOW_STATISTICS는 Shell 데이터베이스의 제어 노드 수준에 저장된 통계를 표시합니다. 컴퓨팅 노드에서 SQL Server에서 자동으로 만든 통계는 표시되지 않습니다.
DBCC SHOW_STATISTICS 는 외부 테이블에서 지원되지 않습니다.
Microsoft Fabric DBCC SHOW_STATISTICS 에서는 ACE-* 통계가 아닌 히스토그램 통계에 대한 결과만 표시합니다.
예제: SQL Server, Azure SQL Database
A. 모든 통계 정보 반환
다음 예제에서는 AdventureWorks2022 데이터베이스의 테이블 인덱 Person.Address 스에 대한 AK_Address_rowguid 모든 통계 정보를 표시합니다.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. HISTOGRAM 옵션 지정
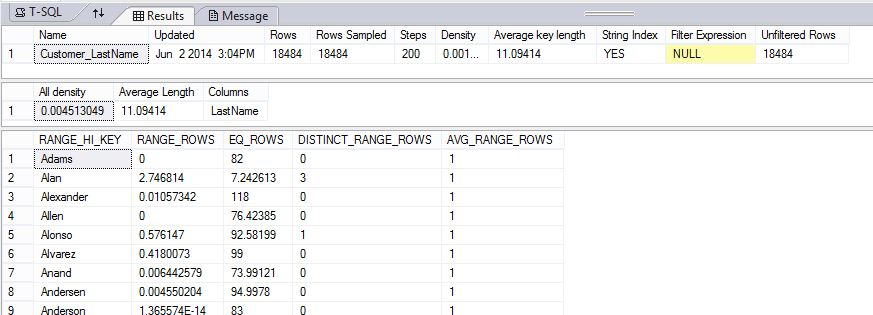
이렇게 하면 Customer_LastName에 대해 표시된 통계 정보가 HISTOGRAM 데이터로 제한됩니다.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
예: Azure Synapse Analytics 및 분석 플랫폼 시스템(PDW)
C. 하나의 통계 개체 내용 표시
다음 예제에서는 통계 개체를 만든 다음 AdventureWorksPDW2022 샘플 데이터베이스의 테이블에 있는 DimCustomer 통계의 Customer_LastName 내용을 표시합니다.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
결과는 헤더, 밀도 벡터 및 히스토그램 일부를 보여줍니다.
참고 항목
- 통계
- Microsoft Fabric의 통계
- sys.dm_db_stats_properties(Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)