적용 대상:![]() SQL Server 2016(13.x)
SQL Server 2016(13.x) ![]() SQL Server 2017(14.x)
SQL Server 2017(14.x) ![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
SQL Server Distributed Replay는 SQL Server 2022(16.x) 이상 버전에서는 사용할 수 없습니다.
Microsoft SQL Server Distributed Replay 기능을 사용하면 SQL Server 업그레이드에 따르는 영향을 쉽게 평가할 수 있습니다. 또한 하드웨어 및 운영 체제 업그레이드와 SQL Server 튜닝에 따르는 영향도 쉽게 평가할 수 있습니다.
SQL Server 2022에서 Distributed Replay 사용 중단
DISTRIBUTED Replay는 SQL Server 2022(16.x )의 사용되지 않는 데이터베이스 엔진 기능에 설명된 대로 SQL Server 2022(16.x)로 더 이상 사용되지 않습니다. Distributed Replay는 SQL Server 2022(16.x)에서 제거된 SNAC(SQL Server Native Client)에 종속됩니다. 이 변경 내용은 SQL Server Native Client에 대한 지원 정책에 설명되어 있습니다. 또한 Distributed Replay는 .trc 파일에 의존하며, 이는 더 이상 사용되지 않는 SQL 추적 및 SQL Server Profiler를 사용하여 캡처됩니다.
Distributed Replay Controller는 SQL Server 2022(16.x) 설정에서 제거되었으며 버전 18부터는 SSMS(SQL Server Management Studio)에서 Distributed Replay Client를 더 이상 사용할 수 없습니다. Distributed Replay Controller를 얻으려면 SQL Server 2019(15.x) 또는 이전 버전을 설치해야 합니다. Distributed Replay Client를 얻으려면 SSMS 17.9.1을 설치해야 합니다.
SQL Server 2022(16.x) 고객의 경우 ostress가 포함된 RML(Replay Markup Language) 유틸리티를 사용하여 워크로드를 재생할 수 있습니다.
Distributed Replay의 이점
SQL Server Profiler와 마찬가지로 Distributed Replay를 사용하면 캡처된 추적을 업그레이드된 테스트 환경에 대해 재생할 수 있습니다. SQL Server Profiler와 달리 Distributed Replay는 여러 컴퓨터의 워크로드를 재생할 수 있습니다.
Distributed Replay는 SQL Server Profiler보다 확장성이 뛰어난 솔루션을 제공합니다. Distributed Replay를 사용하면 여러 컴퓨터의 작업을 재생하고 중요한 작업을 효율적으로 시뮬레이션할 수 있습니다.
Distributed Replay 기능은 여러 컴퓨터를 사용하여 추적 데이터를 재생하고 중요 업무용 워크로드를 시뮬레이트할 수 있습니다. 애플리케이션 호환성 테스트, 성능 테스트 또는 용량 계획에 Distributed Replay를 사용할 수 있습니다.
Distributed Replay를 사용하는 경우
SQL Server Profiler와 Distributed Replay는 기능이 일부 중복됩니다.
SQL Server Profiler를 사용하면 캡처된 추적을 업그레이드된 테스트 환경에 대해 재생할 수 있습니다. 재생 결과를 분석하여 잠재적인 기능 및 성능 관련 비호환성 문제가 있는지도 검토할 수 있습니다. 그러나 SQL Server Profiler는 단일 컴퓨터에서만 워크로드를 재생할 수 있습니다. 리소스를 많이 사용하는 OLTP 애플리케이션(활성 동시 연결 수가 많거나 처리량이 많음)을 재생할 때는 SQL Server Profiler로 인해 리소스 병목 상태가 야기될 수 있습니다.
Distributed Replay는 SQL Server Profiler보다 확장성이 뛰어난 솔루션을 제공합니다. Distributed Replay를 사용하면 여러 컴퓨터의 작업을 재생하고 중요한 작업을 효율적으로 시뮬레이션할 수 있습니다.
다음 표에서는 각 도구를 사용하는 경우에 대해 설명합니다.
| 도구 | 사용할 때... |
|---|---|
| SQL Server Profiler | 단일 컴퓨터에서 기본 재생 메커니즘을 사용하려는 경우. 특히 단계, 커서까지 실행및 중단점 설정/해제 명령과 같은 줄 단위 디버깅 기능이 필요합니다. Analysis Services 추적을 재생하려는 경우 |
| 분산 재생 | 애플리케이션 호환성을 평가하려는 경우. 예를 들어 SQL Server 및 운영 체제 업그레이드 시나리오, 하드웨어 업그레이드 또는 인덱스 튜닝을 테스트하려는 경우입니다. 캡처된 추적의 동시성이 너무 높아서 재생 클라이언트 하나로는 충분히 시뮬레이션할 수 없습니다. |
Distributed Replay 개념
Distributed Replay 환경을 구성하는 요소는 다음과 같습니다.
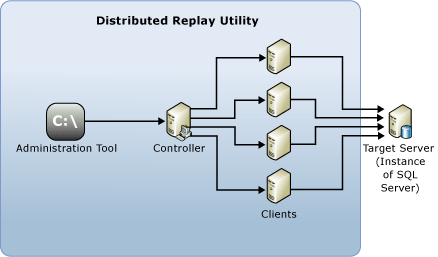
Distributed Replay 관리 도구: Distributed Replay Controller와 통신하는 데 사용되는 콘솔 애플리케이션인 DReplay.exe입니다. 관리 도구를 사용하여 Distributed Replay를 제어할 수 있습니다.
Distributed Replay 컨트롤러: SQL Server Distributed Replay Controller라는 Windows 서비스를 실행하는 컴퓨터입니다. Distributed Replay Controller는 Distributed Replay Client의 동작을 조정합니다. 각 Distributed Replay 환경에는 컨트롤러 인스턴스가 하나만 있을 수 있습니다.
Distributed Replay Client: SQL Server Distributed Replay Client라는 Windows 서비스를 실행하는 하나 이상의 컴퓨터(물리적 또는 가상)입니다. 여러 Distributed Replay Client가 함께 작동하여 SQL Server인스턴스에 대해 작업을 시뮬레이션합니다. 각 Distributed Replay 환경에 하나 이상의 클라이언트가 있을 수 있습니다.
대상 서버: Distributed Replay Client가 추적 데이터를 재생하는 데 사용할 수 있는 SQL Server 인스턴스입니다. 테스트 환경에 대상 서버를 배치하는 것이 좋습니다.
Distributed Replay 관리 도구, Controller 및 Client를 서로 다른 컴퓨터에 설치하거나 동일한 컴퓨터에 설치할 수 있습니다. Distributed Replay Controller 또는 Client 서비스 인스턴스는 동일한 컴퓨터에서 하나만 실행할 수 있습니다.
다음 그림은 SQL Server Distributed Replay 물리적 아키텍처를 보여 줍니다.
Distributed Replay 작업
| 태스크 설명 | 문서 |
|---|---|
| Distributed Replay를 구성하는 방법에 대해 설명합니다. | Distributed Replay 구성 |
| 입력 추적 데이터를 준비하는 방법에 대해 설명합니다. | 입력 추적 데이터 준비 |
| 추적 데이터를 재생하는 방법에 대해 설명합니다. | 추적 데이터 재생 |
| Distributed Replay 추적 데이터 결과를 검토하는 방법에 대해 설명합니다. | 재생 결과 검토 |
| 관리 도구를 사용하여 컨트롤러에서 작업을 시작, 모니터링 및 취소하는 방법에 대해 설명합니다. | 관리 도구 명령줄 옵션(Distributed Replay Utility) |
요구 사항
Distributed Replay 기능을 사용하기 전에 이 기사에서 설명하는 제품 요구 사항을 검토하세요.
입력 추적 요구 사항
추적 데이터를 재생하려면 데이터가 버전 및 형식 요구 사항을 충족해야 하고 필요한 이벤트 및 열을 포함해야 합니다.
입력 추적 버전
Distributed Replay는 다음 SQL Server버전에서 수집된 입력 추적 데이터를 지원합니다.
- SQL Server 2019(15.x)
- SQL Server 2017(14.x)(누적 업데이트 1 이상 버전 - SQL Server 2017 빌드 버전 참조)
- SQL Server 2016(13.x)
- SQL Server 2014(12.x)
- SQL Server 2012(11.x)
- SQL Server 2008 R2(10.50.x)
- SQL Server 2008(10.0.x)
- SQL Server 2005(9.x)
입력 추적 형식
입력 추적 데이터는 다음 형식 중 하나일 수 있습니다.
확장명이
.trc인 단일 추적 파일파일 롤오버 명명 규칙을 따르는 일련의 롤오버 추적 파일은 예를 들면
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc,<TraceFile>_n.trc와 같습니다.
입력 추적 이벤트 및 열
Distributed Replay에서 입력 추적 데이터를 재생하려면 데이터가 특정 이벤트 및 열을 포함해야 합니다. SQL Server Profiler의 TSQL_Replay 템플릿에는 필요한 모든 이벤트 및 열이 포함되어 있으며, 추가 정보도 제공됩니다. 이 템플릿에 대한 자세한 내용은 Replay Requirements을 참조하세요.
경고
TSQL_Replay 템플릿을 사용하여 입력 추적 데이터를 캡처하지 않거나 입력 추적 요구 사항이 충족되지 않은 경우 예기치 않은 재생 결과가 수신될 수 있습니다.
사용자 지정 추적 템플릿을 만들고 이를 통해 Distributed Replay를 사용하여 이벤트를 재생할 수도 있습니다. 이 경우 사용자 지정 추적 템플릿에 다음 이벤트가 포함되어 있어야 합니다.
- 로그인 감사 작업
- 감사 로그아웃
- 기존 연결
- RPC 출력 파라미터
- RPC: 완료됨
- RPC:시작 중
- SQL: 일괄 처리 완료
- SQL:BatchStarting
서버 쪽 커서를 재생하는 경우 다음 이벤트도 필요합니다.
- 커서닫기
- CursorExecute
- 커서 열기
- CursorPrepare
- 커서 준비 해제
서버 쪽 준비된 SQL 문을 재생하는 경우 다음 이벤트도 필요합니다.
- 준비된 SQL 실행
- SQL 준비
모든 입력 추적 데이터는 다음 열을 포함해야 합니다.
- 이벤트 클래스
- 이벤트 순서
- 텍스트 데이터
- 애플리케이션 이름
- 로그인 이름
- 데이터베이스 이름
- 데이터베이스 ID
- 호스트 이름
- 이진 데이터
- SPID(이탈리아 디지털 신원 인증 시스템)
- 시작 시간
- 종료 시간
- IsSystem
지원되는 입력 추적 및 대상 서버의 조합
다음 표에서는 지원되는 추적 데이터 버전과 버전마다 데이터 재생이 지원되는 SQL Server 버전을 보여 줍니다.
| 입력 추적 데이터 버전 | 대상 서버 인스턴스에 대해 지원되는 SQL Server 버전 |
|---|---|
| SQL Server 2005(9.x) | SQL Server 2008(10.0.x), SQL Server 2008 R2(10.50.x), SQL Server 2012(11.x), SQL Server 2014(12.x), SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2008(10.0.x) | SQL Server 2008(10.0.x), SQL Server 2008 R2(10.50.x), SQL Server 2012(11.x), SQL Server 2014(12.x), SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2008 R2(10.50.x) | SQL Server 2008 R2(10.50.x), SQL Server 2012(11.x), SQL Server 2014(12.x), SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2012(11.x) | SQL Server 2012(11.x), SQL Server 2014(12.x), SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2014(12.x) | SQL Server 2014(12.x), SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2016(13.x) | SQL Server 2016(13.x), SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2017(14.x) | SQL Server 2017(14.x), SQL Server 2019(15.x) |
| SQL Server 2019(15.x) | SQL Server 2019(15.x) |
운영 체제 요구 사항
관리 도구, 컨트롤러 및 클라이언트 서비스를 실행할 수 있는 운영 체제는 SQL Server 인스턴스와 동일합니다. SQL Server 인스턴스에 지원되는 운영 체제에 대한 자세한 내용은 SQL Server 2016 및 SQL Server 2017에 대한 하드웨어 및 소프트웨어 요구 사항을 참조하세요.
Distributed Replay 기능은 x86 기반 및 x64 기반 운영 체제 모두에서 지원됩니다. x64 기반 운영 체제의 경우 WOW(Windows on Windows) 모드만 지원됩니다.
설치 제한 사항
컴퓨터당 각 Distributed Replay 기능의 단일 인스턴스를 한 번만 설치할 수 있습니다. 다음 표에서는 단일 환경에서 허용되는 각 Distributed Replay 기능의 설치 횟수를 보여 줍니다.
| Distributed Replay 기능 | 재생 환경당 최대 설치 횟수 |
|---|---|
| SQL Server Distributed Replay Controller 서비스 | 1 |
| SQL Server 분산 재생 클라이언트 서비스 | 16(실제 또는 가상 컴퓨터) |
| 관리 도구 | 제한 없음 |
참고
관리 도구는 단일 컴퓨터에 한 번만 설치할 수 있지만 관리 도구의 여러 인스턴스를 시작할 수 있습니다. 여러 관리 도구에서 실행한 명령은 명령을 받은 순서대로 확인됩니다.
데이터 액세스 공급자
Distributed Replay는 SQL Server Native Client ODBC 데이터 액세스 공급자만 지원합니다.
대상 서버 준비 요구 사항
테스트 환경에 대상 서버를 배치하는 것이 좋습니다. 데이터가 원래 기록되었던 SQL Server 인스턴스가 아닌 다른 인스턴스에서 추적 데이터를 재생하려면 대상 서버에서 다음 단계를 완료해야 합니다.
추적 데이터에 포함된 모든 로그인 및 사용자가 대상 서버에서 동일한 데이터베이스에 있어야 합니다.
대상 서버에 있는 모든 로그인 및 사용자가 원래 서버에서 가진 권한과 같은 권한을 가져야 합니다.
대상에 있는 데이터베이스 ID가 원본에 있는 데이터베이스 ID와 같아야 합니다. 그러나 두 ID가 서로 다르다면 DatabaseName 이 추적에 있을 경우 이를 기준으로 일치시킬 수 있습니다.
추적 데이터에 포함된 각 로그인의 기본 데이터베이스가 대상 서버에서 로그인의 각 대상 데이터베이스로 설정되어야 합니다. 예를 들어, 재생할 추적 데이터에는 원래 SQL Server 인스턴스의 Fred_Db 데이터베이스에 있는 로그인 Fred에 대한 활동이 포함되어야 합니다. 따라서 대상 서버에서 Fred로그인에 대한 기본 데이터베이스는 Fred_Db 와 일치하는 데이터베이스로 설정되어야 합니다. 데이터베이스 이름이 다르더라도 마찬가지입니다. 로그인의 기본 데이터베이스를 설정하려면
sp_defaultdb시스템 저장 프로시저를 사용합니다.
누락되거나 잘못된 로그인과 연관된 이벤트를 재생하면 재생 오류가 발생하지만 재생 작업은 계속됩니다.