문제가 있는 쿼리 계획 식별
DBA가 쿼리 성능 문제를 해결하기 위해 취하는 일반적인 방식은 먼저 문제가 있는 쿼리(대개 시스템 리소스를 가장 많이 소모하는 쿼리)를 식별한 다음 해당 쿼리의 실행 계획을 검색하는 것입니다. 두 가지 주요 시나리오가 있습니다. 한 가지 시나리오는 쿼리가 지속적으로 성능이 좋지 않다는 것입니다. 이는 하드웨어 리소스 제약 조건(단, 일반적으로 격리되어 실행되는 단일 쿼리에는 영향을 미치지 않음), 최적화되지 않은 쿼리 구조, 데이터베이스 호환성 설정, 인덱스 누락 또는 쿼리 최적화 프로그램의 잘못된 계획 선택 등 다양한 문제로 인해 발생할 수 있습니다. 두 번째 시나리오는 쿼리가 어떤 실행에서는 좋은 성능을 보이지만 다른 실행에서는 성능이 좋지 않은 경우입니다. 이러한 불일치는 매개 변수가 있는 쿼리의 데이터 기울이기와 같은 요소로 인해 발생할 수 있는데, 이는 일부 실행에서는 효율적인 계획을 갖고 다른 실행에서는 효율적이지 않은 계획을 갖고 있기 때문입니다. 다른 일반적인 요소로는 차단, 즉 쿼리가 다른 쿼리가 완료될 때까지 기다려서 테이블에 액세스하는 경우나 하드웨어 경합이 있습니다.
각 시나리오를 더 자세히 살펴보겠습니다.
하드웨어 제약 조건
하드웨어 제약 조건은 일반적으로 단일 쿼리 실행 중에는 나타나지 않지만 CPU 스레드와 메모리가 제한되는 프로덕션 부하에서는 분명해집니다. CPU 경합은 서버의 CPU 사용량을 측정하는 성능 모니터 카운터 '% Processor Time'을 관찰하여 검색할 수 있습니다. SQL Server에서 SOS_SCHEDULER_YIELD 및 CXPACKET 대기 형식은 CPU 압력을 나타낼 수 있습니다. 저장 시스템 성능이 좋지 않으면 최적화된 단일 쿼리 실행도 느려질 수 있습니다. 스토리지 성능은 I/O 작업 완료 시간을 측정하는 성능 모니터 카운터 Disk Seconds/Read 및 Disk Seconds/Write를 사용하여 운영 체제 수준에서 가장 잘 추적됩니다. I/O가 15초 이상 걸리면 SQL Server에서 스토리지 성능이 저하된 것으로 기록됩니다. SQL Server에서 높은 PAGEIOLATCH_SH 대기는 스토리지 성능 문제를 나타낼 수 있습니다. 하드웨어 성능은 평가가 쉽기 때문에 일반적으로 문제 해결 프로세스 초기에 평가됩니다.
대부분의 데이터베이스 성능 문제는 최적화되지 않은 쿼리 패턴에서 비롯되는데, 이는 하드웨어에 과도한 부담을 줄 수 있습니다. 예를 들어, 인덱스가 누락되면 필요 이상으로 많은 데이터를 검색하게 되어 CPU, 스토리지, 메모리에 부담을 줄 수 있습니다. 하드웨어 문제를 해결하기 전에 최적이 아닌 쿼리를 처리하고 조정하는 것이 좋습니다. 다음으로 쿼리 튜닝을 살펴보겠습니다.
최적이 아닌 쿼리 구문
관계형 데이터베이스는 데이터(INSERT, UPDATE, DELETE, SELECT)를 집합으로 조작하여 단일 값이나 결과 집합을 생성하는 집합 기반 작업을 실행할 때 가장 좋은 성능을 발휘합니다. 대안은 커서나 while 루프를 사용하는 행 기반 처리로, 영향을 받는 행의 수에 따라 비용이 선형적으로 증가합니다. 이는 데이터 볼륨이 증가함에 따라 문제가 되는 규모입니다.
커서나 WHILE 루프를 사용하여 행 기반 작업을 최적화하지 못한 경우를 검색하는 것은 중요하지만, 인식해야 할 다른 SQL Server 안티 패턴도 있습니다. SQL Server 2017 이전에는 TVF(테이블 반환 함수), 특히 다중 문 TVF가 실행 계획 패턴에 문제를 일으켰습니다. 개발자는 종종 다중 문 TVF를 사용하여 단일 함수 내에서 여러 쿼리를 실행하고 결과를 단일 테이블에 집계합니다. 그러나 TVF를 사용하면 성능이 저하될 수 있습니다.
SQL Server에는 인라인 TVF와 다중 문 TVF의 두 가지 형식이 있습니다. 인라인 TVF는 뷰처럼 처리되고, 다중 문 TVF는 쿼리 처리 중에 테이블처럼 처리됩니다. TVF는 동적이며 통계가 없기 때문에 SQL Server는 고정된 행 수를 사용하여 쿼리 계획 비용을 예상합니다. 이 방법은 행 수가 적을 때는 괜찮지만, 행 수가 수천 또는 수백만 개일 때는 효율적이지 않습니다.
또 다른 안티 패턴은 스칼라 함수를 사용하는 것인데, 이는 유사한 예상 및 실행 문제를 갖습니다. Microsoft는 호환성 수준 140 및 150에서 지능형 쿼리 처리를 통해 상당한 성능 개선을 이루었습니다.
SARGability
관계형 데이터베이스에서 SARGable이라는 용어는 인덱스를 사용하여 쿼리 실행 속도를 높이도록 포맷된 조건자(WHERE 절)를 나타냅니다. 올바른 형식의 조건자를 ‘검색 인수’ 또는 SARG라고 합니다. SQL Server에서 SARG를 사용하면 최적화 프로그램이 전체 인덱스 또는 테이블을 검사하여 값을 검색하는 대신, SEEK 작업에 대해 SARG에서 참조하는 열에 대한 비클러스터형 인덱스를 사용하여 평가한다는 것을 의미합니다.
SARG가 있다고 해서 SEEK에 대한 인덱스의 사용을 보장하지는 않습니다. 최적화 프로그램의 비용 계산 알고리즘은 특히 SARG가 테이블의 행에서 많은 비율을 참조하는 경우 인덱스가 너무 비싸다고 판단할 수 있습니다. SARG가 없으면 최적화 프로그램이 비클러스터형 인덱스에서 SEEK를 평가하지 않습니다.
SARGable이 아닌 식의 예로는 문자열의 시작 부분에 와일드카드를 사용하는 LIKE 절이 있는 식(예: WHERE lastName LIKE '%SMITH%')이 있습니다. WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'와 같은 열에 함수를 사용할 때 다른 비 SARGable 조건자가 발생합니다. 이러한 쿼리는 일반적으로 인덱스 또는 테이블 검색에 대한 실행 계획을 검사하여 검사가 정상적으로 수행되어야 하는 위치를 식별합니다.
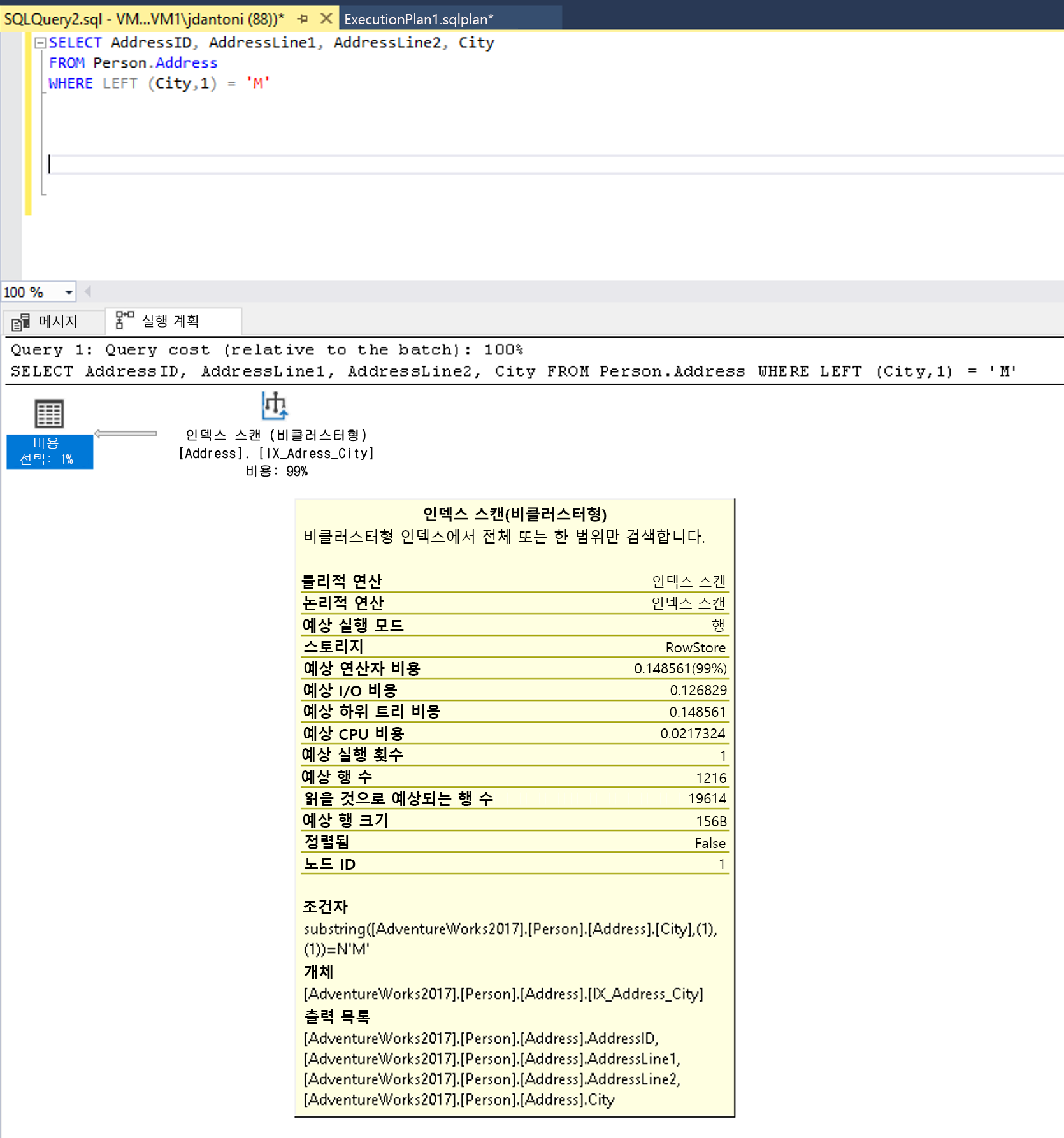
쿼리 절에 사용되는 WHERE City 열에 인덱스가 있으며 위의 실행 계획에서 사용되는 동안 인덱스가 검사되는 것을 볼 수 있습니다. 즉, 전체 인덱스가 읽혀지고 있음을 의미합니다. LEFT 조건자의 함수는 이 식을 SARGable이 아닌 것으로 만듭니다. 최적화 프로그램은 City 열에 있는 인덱스에 index seek를 사용하여 평가하지 않습니다.
이 쿼리를 SARGable 조건자를 사용하도록 작성할 수 있습니다. 그런 다음 최적화 프로그램은 City 열의 인덱스에서 SEEK를 평가합니다. 이 경우 인덱스 검색 연산자는 더 작은 행 집합을 읽습니다.

함수 LEFT를 LIKE으로 변경하면 인덱스 탐색이 발생합니다.
비고
이 예에서 LIKE 키워드에는 왼쪽에 와일드카드가 없으므로 M으로 시작하는 도시를 찾습니다. "양면"이거나 와일드카드("%M%" 또는 "%M")로 시작하는 경우 SARGable이 아닙니다. Seek 작업은 1,267개 행 또는 비SARGable 조건자가 있는 쿼리의 경우 추정치의 약 15%를 반환할 것으로 예상됩니다.
일부 다른 데이터베이스 개발 안티패턴에서는 데이터 저장소 대신 Database as a Service를 처리합니다. 데이터베이스를 사용하여 데이터를 JSON으로 변환하거나 문자열을 조작하거나 복잡한 계산을 수행하면 CPU 사용이 과도해지고 대기 시간이 길어질 수 있습니다. 쿼리가 데이터베이스에서 모든 레코드를 검색한 후 계산을 수행하려고 하면 IO 및 CPU 사용이 과도해질 수 있습니다. 데이터베이스는 데이터 액세스 작업 및 최적화된 데이터베이스 구문(예: 집계)에 사용하는 것이 가장 좋습니다.
누락된 인덱스
데이터베이스 관리자들이 겪는 가장 흔한 성능 문제는 유용한 인덱스가 부족하여 엔진이 쿼리 결과를 반환하는 데 필요한 것보다 많은 페이지를 읽는 데서 비롯됩니다. 인덱스는 리소스를 소모하며 쓰기 성능에 영향을 미치고 공간을 차지하지만, 이를 통해 얻는 성능 향상 효과는 추가 리소스 비용보다 큰 경우가 많습니다. 이러한 문제가 있는 실행 계획은 쿼리 연산자 클러스터형 인덱스 검사 또는 비클러스터형 인덱스 검사와 키 조회의 조합을 통해 식별할 수 있으며, 기존 인덱스에서 누락된 열을 나타냅니다.
데이터베이스 엔진은 실행 계획에서 누락된 인덱스를 보고하여 도움을 줍니다. 권장 인덱스의 이름과 세부 정보는 동적 관리 뷰 sys.dm_db_missing_index_details를 통해 제공됩니다. sys.dm_db_index_usage_stats 및 sys.dm_db_index_operational_stats와 같은 다른 DMV는 기존 인덱스의 활용을 강조 표시합니다.
사용하지 않는 인덱스를 삭제하는 것이 합리적일 수 있습니다. 누락된 인덱스 DMV와 계획 경고는 쿼리 튜닝을 위한 시작점이 되어야 합니다. 주요 쿼리를 이해하고 이를 지원하는 인덱스를 빌드해야 합니다. 컨텍스트에서 평가하지 않고 누락된 인덱스를 모두 만들지 않는 것이 좋습니다.
누락된 통계 및 오래된 통계
쿼리 최적화 프로그램에서 열과 인덱스 통계의 중요도를 이해하는 것은 매우 중요합니다. 또한 오래된 통계가 발생할 수 있는 조건을 인식하고 이 문제가 SQL Server에서 어떻게 나타날 수 있는지 아는 것도 중요합니다. Azure SQL 제공 사항에서는 기본적으로 통계 자동 업데이트가 켜짐으로 설정되어 있습니다. SQL Server 2016 이전에는 자동 통계 업데이트의 기본 동작은 인덱스의 열에 대한 수정 사항이 테이블의 행 수의 약 20%에 도달할 때까지 통계를 업데이트하지 않는 것이었습니다. 이러한 동작으로 인해 통계를 업데이트하지 않고 쿼리 성능을 변경하는 상당한 데이터 수정이 발생할 수 있으며, 이는 오래된 통계를 기반으로 하는 최적이 아닌 계획으로 이어질 수 있습니다.
SQL Server 2016 이전에는 추적 플래그 2371을 사용하여 동적 값에 필요한 수정 횟수를 변경할 수 있었습니다. 따라서 테이블이 커짐에 따라 통계 업데이트를 트리거하는 데 필요한 행 수정 비율이 감소했습니다. 최신 버전의 SQL Server, Azure SQL Database 및 Azure SQL Managed Instance에서는 이 동작을 기본적으로 지원합니다. 동적 관리 함수 sys.dm_db_stats_properties는 통계가 마지막으로 업데이트된 시간과 마지막 업데이트 이후 수정된 횟수를 표시하여 수동 업데이트가 필요할 수 있는 통계를 빠르게 식별할 수 있도록 합니다.
성능이 낮은 최적화 프로그램 선택
쿼리 최적화 프로그램은 대부분의 쿼리를 최적화하는 데 큰 도움이 되지만 비용 기반 최적화 프로그램에서 잘 이해되지 않는 중요한 결정을 내릴 수 있는 몇 가지 예외 사례가 있습니다. 이 문제를 해결하는 방법은 쿼리 힌트, 추적 플래그, 실행 계획 적용, 안정적인 최적의 쿼리 계획에 도달하기 위한 기타 조정 등 여러 가지가 있습니다. Microsoft에는 이러한 시나리오에서 문제를 해결할 수 있도록 도움을 주는 지원 팀이 있습니다.
AdventureWorks2017 데이터베이스의 아래 예제에서는 쿼리 힌트를 사용하여 데이터베이스 최적화 프로그램에서 항상 시애틀의 도시 이름을 사용하도록 지시합니다. 이 힌트는 모든 도시 값에 대해 최상의 실행 계획을 보장하지는 않지만 예측 가능합니다. 'Seattle' @city_name 의 값은 최적화 중에만 사용됩니다. 실행 중에는 실제로 제공된 값 (‘Ascheim’)이 사용됩니다.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
예에 있는 것처럼, 쿼리는 힌트(OPTION 절)를 통해 최적화 프로그램이 특정 변수 값을 사용하여 실행 계획을 작성하도록 지시합니다.
매개 변수 스니핑
SQL Server는 나중에 사용하기 위해 쿼리 실행 계획을 캐시합니다. 실행 계획 검색 프로세스는 쿼리의 해시 값을 기반으로 하므로 캐시된 계획을 사용하기 위해서는 쿼리를 실행할 때마다 쿼리 텍스트가 동일해야 합니다. 동일한 쿼리에서 여러 값을 지원하도록 많은 개발자는 다음 예와 같이 저장 프로시저를 통해 전달되는 매개 변수를 사용합니다.
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
프로시저 sp_executesql를 사용하여 쿼리를 명시적으로 매개 변수화할 수도 있습니다. 하지만 개별 쿼리의 명시적 매개 변수화는 API에 따라 다른 형식의 PREPARE 및 EXECUTE를 사용하여 애플리케이션에서 수행됩니다. 데이터베이스 엔진이 처음으로 해당 쿼리를 실행할 때 매개 변수의 초기 값, 이 경우 42를 기반으로 쿼리를 최적화합니다. 매개 변수 스니핑이라고 하는 이 동작을 통해 서버에서 쿼리 컴파일에 대한 전체 워크로드를 줄일 수 있습니다. 그러나 데이터 기울이기가 있는 경우 쿼리 성능이 크게 달라질 수 있습니다.
예를 들어 테이블에 레코드 1,000만 개가 있고, 이 레코드의 99%는 ID가 1이며, 나머지 1%는 고유한 숫자인 경우 쿼리를 최적화하는 데 처음 사용된 ID에 따라 성능이 결정됩니다. 이렇게 크게 변동되는 성능은 데이터 기울이기를 나타내며 매개 변수 스니핑에 내재된 문제가 아닙니다. 이러한 동작은 상당히 일반적인 성능 문제이므로 잘 알고 있어야 합니다. 이 문제를 완화하는 데 필요한 옵션을 알아야 합니다. 이 문제를 해결하는 방법은 몇 가지가 있지만, 각각 장단점이 있습니다.
- 쿼리의
RECOMPILE힌트 또는 저장 프로시저의WITH RECOMPILE실행 옵션을 사용합니다. 이 힌트를 사용하면 쿼리 또는 프로시저가 실행될 때마다 다시 컴파일되어 서버에서 CPU 사용률이 증가하지만, 항상 현재 매개 변수 값이 사용됩니다. - 쿼리 힌트를
OPTIMIZE FOR UNKNOWN사용할 수 있습니다. 이 힌트는 최적화 프로그램이 매개 변수를 탐지하지 않고 해당 값을 열 데이터 히스토그램과 비교하도록 합니다. 이 옵션을 통해 가능한 최적의 계획을 얻을 수는 없지만, 일관성 있는 실행 계획을 활용할 수는 있습니다. - 매개 변수 값에 대한 논리를 추가하여 알려진 문제가 있는 매개 변수에 대해서만 RECOMPILE을 수행하도록 프로시저 또는 쿼리를 다시 작성합니다. 아래 예에서 SalesPersonID 매개 변수가 NULL이면 쿼리는
OPTION (RECOMPILE)로 실행됩니다.
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
이 예는 유용한 솔루션이지만 상당히 많은 개발 노력과 데이터 분포에 대한 확실한 이해가 필요합니다. 데이터가 변경되면 유지 관리가 필요합니다.