Fabric의 데이터 웨어하우스 이해
Fabric의 레이크하우스는 데이터 레이크를 통해 데이터베이스처럼 작동하는 파일, 폴더, 테이블 및 바로 가기의 컬렉션입니다. Spark 엔진 및 SQL 엔진에서 빅 데이터 처리를 위해 사용되며 오픈 소스 Delta 형식 테이블을 사용하는 경우 ACID 트랜잭션을 위한 기능을 포함합니다.
Fabric의 데이터 웨어하우스 환경을 사용하면 레이크하우스의 레이크 뷰(데이터 엔지니어링 및 Apache Spark 지원)에서 기존 데이터 웨어하우스가 제공하는 SQL 환경으로 전환할 수 있습니다. 레이크하우스는 테이블을 읽고 SQL 분석 엔드포인트를 사용하는 기능을 제공하는 반면, 데이터 웨어하우스를 사용하면 데이터를 조작할 수 있습니다.
데이터 웨어하우스 환경에서는 테이블 및 뷰를 사용하여 데이터를 모델링하고, T-SQL을 실행하여 데이터 웨어하우스 및 레이크하우스에서 데이터를 쿼리하고, T-SQL을 사용하여 데이터 웨어하우스 내부에서 데이터에 대한 DML 작업을 수행하고, Power BI와 같은 보고 계층을 제공합니다.
이제 관계형 데이터 웨어하우스 스키마에 대한 기본 아키텍처 원칙을 이해했으므로 데이터 웨어하우스를 만드는 방법을 살펴보겠습니다.
Fabric의 데이터 웨어하우스 설명
Fabric의 데이터 웨어하우스 환경에서는 레이크하우스의 물리적 데이터를 기반으로 관계형 계층을 빌드하고 분석 및 보고 도구에 노출할 수 있습니다. 허브 만들기를 통해 Fabric에서 직접 또는 작업 영역 내에서 데이터 웨어하우스를 만들 수 있습니다. 빈 웨어하우스를 만든 후 개체를 추가할 수 있습니다.
웨어하우스가 만들어지면 Fabric 인터페이스에서 직접 T-SQL을 사용하여 테이블을 만들 수 있습니다.
데이터 웨어하우스에 데이터 수집
파이프라인, 데이터 흐름, 데이터베이스 간 쿼리 및 COPY INTO 명령을 포함하여 Fabric 데이터 웨어하우스에 데이터를 수집하는 몇 가지 방법이 있습니다. 수집 후에는 데이터베이스 간 쿼리, 공유 등의 기능을 사용하여 데이터에 액세스할 수 있는 여러 비즈니스 그룹이 데이터를 분석할 수 있습니다.
테이블 만들기
데이터 웨어하우스에서 테이블을 만들기 위해 SSMS(SQL Server Management Studio) 또는 다른 SQL 클라이언트를 사용하여 데이터 웨어하우스에 연결하고 CREATE TABLE 문을 실행할 수 있습니다. Fabric UI에서 직접 테이블을 만들 수도 있습니다.
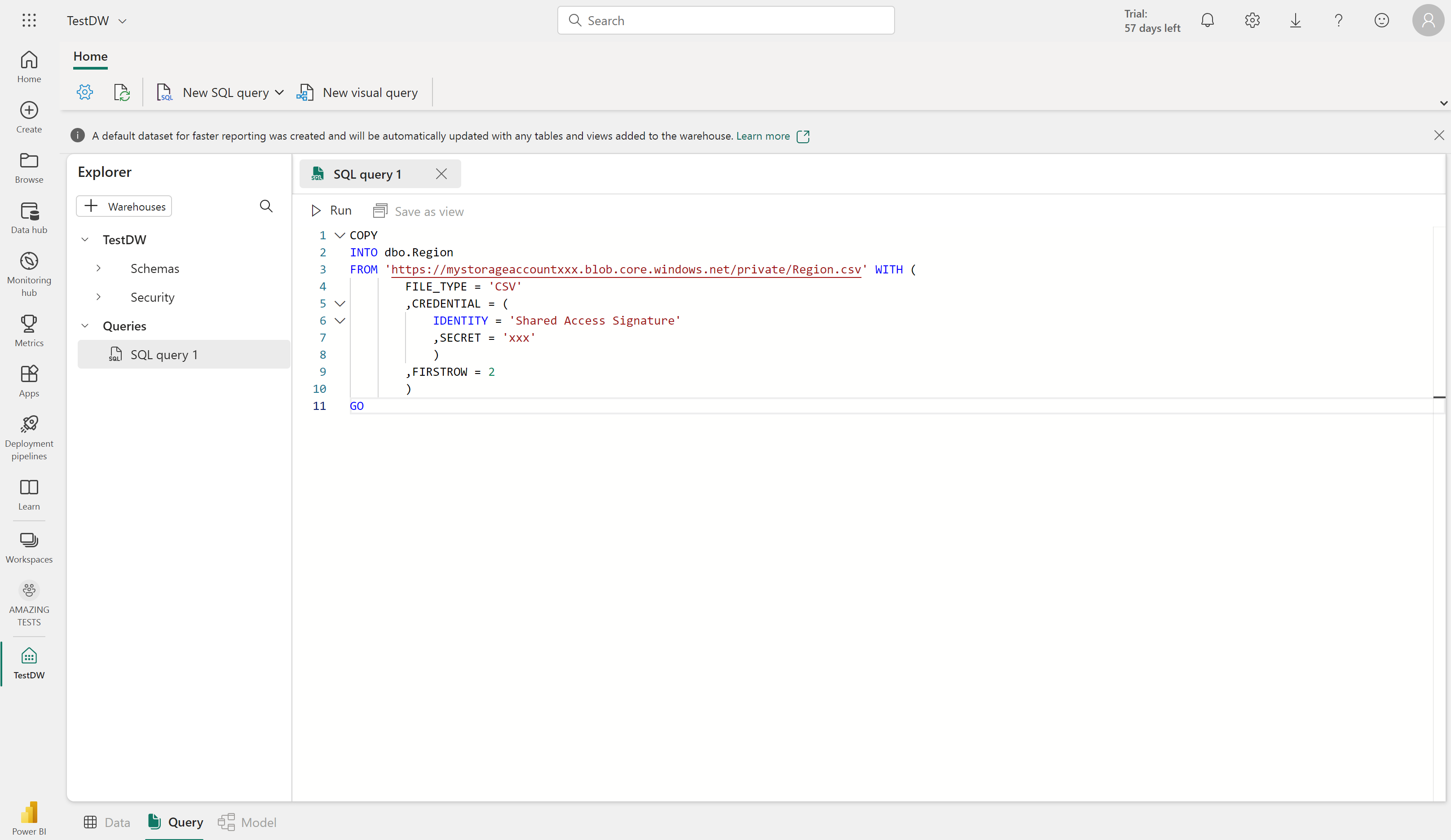
COPY INTO 구문을 사용하여 외부 위치에서 데이터 웨어하우스의 테이블로 데이터를 복사할 수 있습니다. 예를 들면 다음과 같습니다.
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
이 SQL 쿼리는 Azure Blob Storage에 저장된 CSV 파일의 데이터를 Fabric 데이터 웨어하우스의 “Region”이라는 테이블로 로드합니다.
테이블 고려 사항
데이터 웨어하우스에서 테이블을 만든 후에는 해당 테이블에 데이터를 로드하는 프로세스를 고려해야 합니다. 일반적인 접근 방식은 준비 테이블을 사용하는 것입니다. Fabric에서 T-SQL 명령을 사용하여 파일의 데이터를 데이터 웨어하우스의 준비 테이블로 로드할 수 있습니다.
준비 테이블은 데이터 정리, 데이터 변환 및 데이터 유효성 검사를 수행하는 데 사용할 수 있는 임시 테이블입니다. 준비 테이블을 사용하여 여러 원본의 데이터를 단일 대상 테이블로 로드할 수도 있습니다.
일반적으로 데이터 로드는 데이터 웨어하우스에 대한 삽입 및 업데이트가 정기적으로(예: 매일, 매주 또는 매월) 발생하도록 조정되는 주기적인 일괄 처리 프로세스로 수행됩니다.
일반적으로 다음 순서로 작업을 수행하는 데이터 웨어하우스 로드 프로세스를 구현해야 합니다.
- 데이터 레이크에 로드할 새 데이터를 수집하여 필요에 따라 사전 로드 정리 또는 변환을 적용합니다.
- 파일의 데이터를 관계형 데이터 웨어하우스의 준비 테이블로 로드합니다.
- 준비 테이블의 차원 데이터에서 차원 테이블을 로드하고, 기존 행을 업데이트하거나 새 행을 삽입하고, 필요에 따라 서로게이트 키 값을 생성합니다.
- 준비 테이블의 팩트 데이터에서 팩트 테이블을 로드하고 관련 차원에 적절한 서로게이트 키를 조회합니다.
- 인덱스 및 테이블 배포 통계를 업데이트하여 로드 후 최적화를 수행합니다.
레이크하우스에 테이블이 있고 Fabric 데이터 웨어하우스를 사용하여 웨어하우스에서 테이블을 쿼리할 수 있지만 변경할 수는 없는 경우 레이크하우스에서 데이터 웨어하우스로 데이터를 복사할 필요가 없습니다. 데이터베이스 간 쿼리를 사용하여 데이터 웨어하우스에서 직접 레이크하우스의 데이터를 쿼리할 수 있습니다.
중요
Fabric 데이터 웨어하우스의 테이블 사용에는 현재 몇 가지 제한 사항이 있습니다. 자세한 내용은 Microsoft Fabric 데이터 웨어하우징의 테이블을 참조하세요.