문서에서 정보 추출
Tip
자세한 내용은 텍스트 및 이미지 탭을 참조하세요.
오늘날의 비즈니스 프로세스는 양식, 영수증 및 청구서와 같은 문서에 포함된 데이터에 크게 의존합니다. 수동 처리로 인해 지연 및 오류가 발생할 수 있으므로 데이터 추출 자동화가 그 어느 때보다 중요해졌습니다.
Azure Content Understanding 작동 방식
Azure Content Understanding은 구조화되지 않은 콘텐츠를 수집, 분석 및 구조적 데이터로 반환하는 모델 기반 추출 워크플로를 따릅니다.
콘텐츠 수집: Azure Content Understanding에 콘텐츠를 제출합니다.
AI 기반 분석: 이 서비스는 OCR(광학 문자 인식), 음성 인식, 자연어 이해 및 다모달 AI 모델의 조합을 사용하여 콘텐츠를 분석합니다.
구조적 출력: 서비스는 모델과 일치하는 구조적 결과(예: JSON)를 반환하므로 데이터를 다운스트림 시스템에 쉽게 저장, 검색 또는 통합할 수 있습니다.
비고
JSON(JavaScript 개체 표기법)은 시스템 간에 구조화된 데이터를 저장하고 교환하는 데 사용되는 텍스트 기반 데이터 형식입니다. 인간이 읽고 쓰는 것이 쉽고 컴퓨터가 구문 분석하고 생성하기 쉽습니다.
스키마 이해
OCR(광학 문자 인식)을 사용하면 컴퓨터가 스캔한 문서, 영수증 사진 또는 인쇄된 페이지의 이미지와 같은 그림에서 텍스트를 '읽어'고 해당 텍스트를 편집 가능하고 검색 가능한 디지털 텍스트로 전환할 수 있습니다. 기본 OCR은 인쇄된 텍스트를 인식하고 텍스트 추출에 중점을 두며 단어 간의 의미, 컨텍스트 또는 관계를 이해하지 못합니다 .
Azure Content Understanding의 문서 분석 기능은 간단한 OCR 기반 텍스트 추출을 넘어 필드 및 해당 값의 스키마 기반 추출을 포함합니다. 스키마 기반 접근 방식은 Azure Content Understanding을 기본 OCR 또는 전사 서비스와 차별화하는 것입니다.
스키마는 추출할 정보와해당 정보를 구성하는 방법을 설명합니다. 스키마를 정의할 때 추출할 필드를 지정합니다. 스키마는 관심 있는 특정 필드 또는 엔터티를 나열합니다.
예를 들어 다음과 같이 청구서에 일반적으로 있는 공통 필드를 포함하는 스키마를 정의한다고 가정해 보겠습니다.
- 공급업체 이름
- 청구서 번호
- 청구서 날짜
- 고객 이름
- 사용자 지정 주소
- 항목 - 정렬된 각 항목에는 다음이 포함됩니다.
- 항목 설명
- 단가
- 주문된 수량
- 품목 합계
- 청구서 소계
- 세금
- 배송 요금
- 청구서 총계
이제 다음 청구서에서 이 정보를 추출해야 한다고 가정합니다.
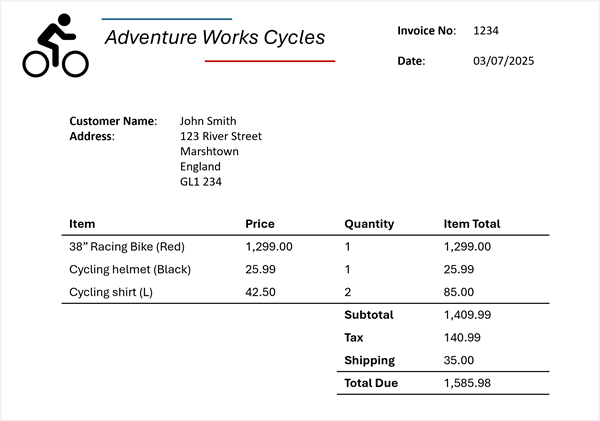
Azure Content Understanding은 청구서 스키마를 청구서에 적용하고 다른 이름으로 레이블이 지정되거나 레이블이 전혀 지정되지 않은 경우에도 해당 필드를 식별할 수 있습니다. 결과 분석은 다음과 같은 결과를 생성합니다.

스키마는 필드 구조도 정의합니다. 스키마는 플랫 텍스트뿐만 아니라 구조화된 필드와 중첩된 필드를 지원합니다. 다음은 그 예입니다.
-
Items가 컬렉션입니다. - 각 항목에는
description,unit price,quantity및line total
구조화된 필드를 식별하면 Azure Content Understanding이 OCR만으로는 수행할 수 없는 값 간의 관계를 이해할 수 있습니다.
청구서 예제에서 검색된 각 필드에 대해 중첩된 값을 추출할 수 있습니다.
- 공급업체 이름: Adventure Works Cycles
- 송장 번호: 1234
- 송장 날짜: 2025/03/07
- 고객 이름: John Smith
- 사용자 지정 주소: 123 리버 스트리트, 마쉬타운, 잉글랜드, GL1 234
-
항목:
- 항목 1:
- 항목 설명: 38" 레이싱 바이크(빨간색)
- 단가: 1299.00
- 주문한 수량: 1
- 품목 합계: 1299.00
- 항목 2:
- 항목 설명: 사이클링 헬멧(검은색)
- 단가: 25.99
- 주문한 수량: 1
- 품목 합계: 25.99
- 항목 3:
- 항목 설명: 사이클링 셔츠(L)
- 단가: 42.50
- 주문한 수량: 2
- 품목 합계: 85.00
- 항목 1:
- 청구서 부분합: 1409.99
- 세금: 140.99
- 배송 요금: 35.00
- 청구서 합계: 1585.98
Azure Content Understanding은 레이블뿐만 아니라 예상된 의미를 추출합니다. 스키마는 의미 체계적으로 적용됩니다. 즉, 다음을 의미합니다.
- 레이블이 다르더라도 필드를 추출할 수 있습니다.
- 레이블이 없는 경우에도 필드를 추출할 수 있습니다.
예를 들어 송장 번호, 청구서 #또는 레이블이 지정되지 않은 번호는 분석기에서 동일한 개념을 나타내는 것으로 판단되는 경우 모두 매핑할 InvoiceNumber 수 있습니다.
분석기 이해
분석기는 입력을 받고, AI 분석을 적용하고, 구조화된 결과를 생성하는 Azure Content Understanding의 단위입니다. 분석기는 들어오는 모든 콘텐츠에 동일한 추출 논리를 일관되게 적용합니다. 구성되면 분석기는 모든 분석 요청에 대해 스키마가 일관되게 재사용되도록 합니다. 분석기는 예측 가능한 JSON 결과도 생성합니다. 구조화된 결과를 통해 다운스트림 처리(스토리지, 검색, 자동화)가 더 쉬워집니다.
Azure Content Understanding은 일반적인 시나리오에 대해 미리 빌드된 분석기를 제공하고 요구 사항에 맞게 조정된 사용자 지정 분석기를 지원합니다. 개요:
- 분석기를 선택하거나 만듭니다.
- 분석기는 필드 및 구조를 정의하는 스키마를 포함합니다.
- 분석을 위해 콘텐츠를 제출합니다.
- 서비스가 스키마를 적용합니다.
- 스키마와 일치하는 구조화된 JSON 결과를 받습니다.
Foundry 포털에서 Azure Content Understanding 사용
비고
Foundry 포털에는 클래식 UI(사용자 인터페이스) 및 새 사용자 인터페이스가 있습니다.
Microsoft Foundry 리소스 만든 후 새로운 Foundry 포털 인터페이스를 사용하여 Azure Content Understanding을 테스트할 수 있습니다. Foundry 포털은 콘텐츠 예제를 제공하며 분석을 위해 사용자 고유의 자료를 업로드할 수 있습니다.
시각적 인터페이스를 사용하여 원본 문서를 선택하고 기본 정보 필드를 추출할 수 있습니다. 예를 들어 문서 이미지에서 Azure Content Understanding을 사용해 볼 때 서비스는 문서 텍스트 및 텍스트 레이아웃 정보를 반환합니다.

Azure Content Understanding의 분석기는 문서의 텍스트 값을 식별하고 특정 필드에 매핑합니다. 예를 들어 청구서가 제공되면 서비스는 필드(예: 공급업체 주소) 및 필드의 데이터(예: 123 456번가)를 반환합니다.

Foundry 포털에서 처리의 JSON 결과를 볼 수도 있습니다.

Azure Content Understanding을 사용하여 클라이언트 애플리케이션 빌드
Content Understanding API를 사용하여 프로그래밍 방식으로 데이터를 추출하는 간단한 클라이언트 애플리케이션을 빌드할 수 있습니다.
비고
클라이언트 애플리케이션은 사용자의 디바이스에서 실행되고 네트워크를 통해 다른 시스템(일반적으로 서버)의 서비스 또는 데이터를 요청하는 소프트웨어 프로그램입니다. 클라이언트는 사용자가 상호 작용하는 애플리케이션의 일부이며 서버는 백그라운드에서 많은 작업을 수행합니다. 애플리케이션은 서비스에서 데이터 또는 작업을 요청하고 API를 사용하여 구조화된 응답을 받을 수 있습니다.
Content Understanding API를 사용하는 경우 미리 빌드된 분석기를 선택하거나 사용자 지정 분석기를 만들 수 있습니다. 미리 빌드된 분석기는 다음을 prebuilt-invoiceprebuilt-imageSearchprebuilt-audioSearch포함합니다. prebuilt-videoSearch 분석용 콘텐츠를 분석기로 제출하면 분석이 비동기적이므로 나중에 준비가 되면 결과를 얻을 수 있습니다. 분석은 비동기이므로 작업이 성공할 때까지 Operation-Location URL(또는)을 analyzerResults해야 합니다.
Azure Content Understanding Python SDK 사용
Python SDK를 사용하여 URL에서 청구서를 분석하는 프로세스를 살펴보겠습니다.
- Azure Content Understanding Python SDK를 설치합니다.
python -m pip install azure-ai-contentunderstanding
Foundry 리소스 엔드포인트 및 API 키 또는 Microsoft Entra ID를 식별합니다. 엔드포인트는 일반적으로 다음과 같습니다.
https://<your-resource-name>.services.ai.azure.com/클라이언트 애플리케이션 코드를 만들고 실행합니다.
analzyer_id미리 빌드된 분석기의 ID입니다. 미리 빌드된 분석기 ID 값 목록은 여기에서 찾을 수 있습니다.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
결과 출력은 추출된 markdown, 필드, 필드의 데이터 및 신뢰도 점수를 보여 주는 JSON입니다. 다음은 그 예입니다.
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
다음으로, Azure Content Understanding 분석기를 사용하여 오디오 및 비디오에서 구조적 데이터를 추출하는 방법을 알아봅니다.