데이터 중복 제거의 아키텍처, 구성 요소, 기능을 정의합니다.
Contoso를 비롯한 대부분의 조직 및 기업들은 점점 더 많은 양의 데이터를 처리하고 저장해야 합니다. 데이터를 클라우드로 오프로드하고 보관할 수 있는 솔루션이 있지만, 대부분의 경우 온-프레미스 데이터 센터에서 유지 관리해야 합니다. 이러한 데이터를 효율적으로 관리하려면 적절한 도구가 필요합니다. Windows Server를 사용하는 경우, 해당 용도의 데이터 중복 제거에 대한 옵션이 있습니다.
데이터 중복 제거란 무엇입니까?
데이터 중복 제거는 데이터 무결성을 손상하지 않고 데이터 내에서 중복을 식별하고 제거하는 Windows Server의 역할 서비스입니다. 이렇게 하면 더 많은 데이터를 저장하고 실제 디스크 공간을 절약할 수 있습니다.
데이터 중복 제거는 디스크 사용률을 줄이기 위해 파일을 검색한 다음 해당 파일을 청크로 나누고 각 청크의 복사본 하나만 보존합니다. 중복 제거 후에는 파일이 더 이상 독립적인 데이터 스트림으로 저장되지 않습니다. 대신, 데이터 중복 제거는 청크 저장소에 저장된 데이터 블록을 가리키는 스텁으로 파일을 교체합니다. 사용자 및 앱에서 중복 제거된 데이터에 액세스하는 프로세스를 완전히 투명하게 알 수 있습니다.
여러 파일이 메모리에 캐시된 하나의 청크를 공유할 수 있기 때문에 대부분의 경우 데이터 중복은 전체 디스크 성능을 향상시킵니다. 이러한 방식으로 읽기 작업을 적게 수행함으로써 관련 파일에서 데이터를 검색할 수 있고, 중복 제거된 파일을 읽을 때 성능에 미치는 영향을 줄일 수 있습니다. 데이터 중복 제거는 디스크에 이미 있는 데이터에 적용되므로 디스크 쓰기 성능에 영향을 주지 않습니다.
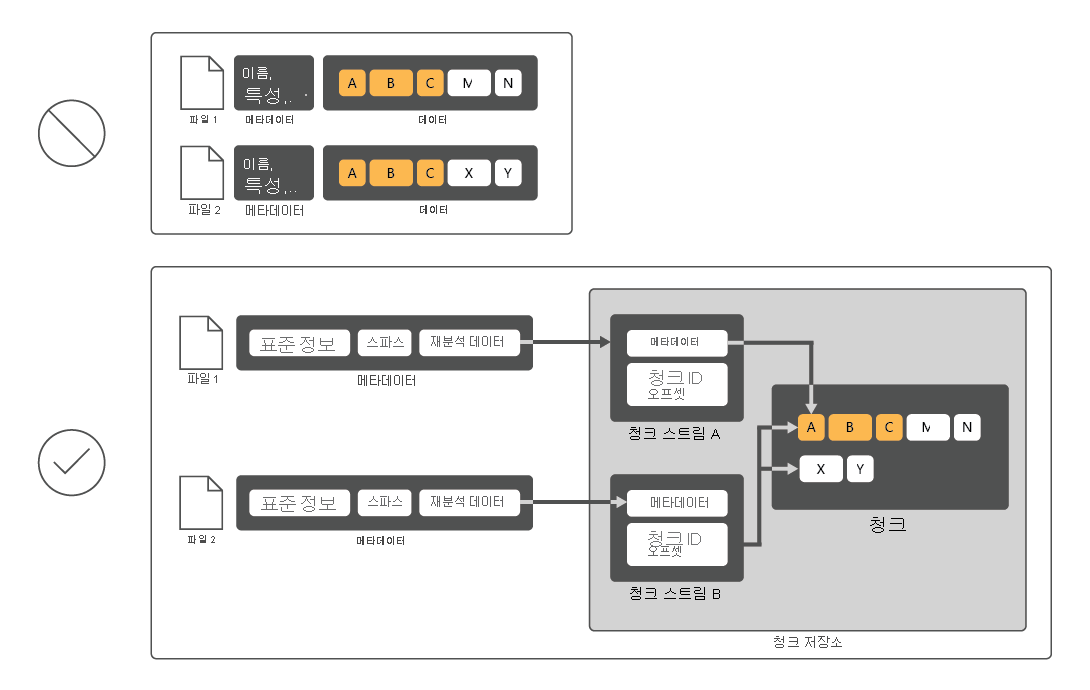
데이터 중복 제거의 구성 요소는 무엇인가요?
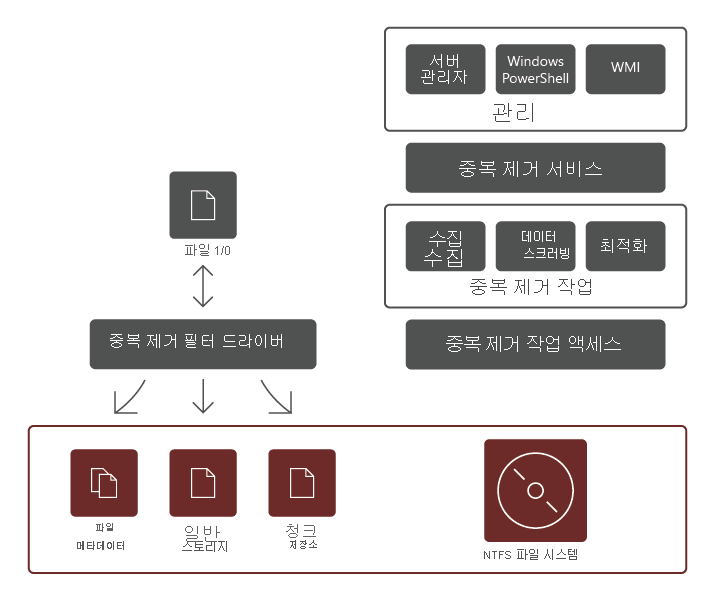
데이터 중복 제거 역할 서비스는 다음과 같은 요소로 구성됩니다.
- 필터 드라이버. 이 구성 요소는 요청되는 파일의 일부인 청크로 읽기 요청을 리디렉션합니다. 모든 볼륨에 대해 하나의 필터 드라이버가 있습니다.
- 중복 제거 서비스. 이 구성 요소는 다음 작업을 관리합니다.
- 중복 제거 및 압축. 해당 작업은 볼륨의 데이터 중복 제거 정책에 따라 파일을 처리합니다. 파일의 초기 최적화 후에 파일이 수정되고 최적화를 위한 데이터 중복 제거 정책 임계값이 충족되면 파일은 다시 최적화됩니다.
- 가비지 수집. 이 작업은 볼륨에서 삭제 또는 수정된 데이터를 처리함으로써 더 이상 참조하지 않는 데이터 청크를 정리하고 사용 가능한 디스크 공간을 확보합니다. 기본적으로 가비지 수집은 매주 실행되지만 많은 파일을 삭제한 후에 호출하는 것도 좋습니다.
- 스크러빙. 이 작업은 체크섬 유효성 검사 및 메타데이터 일관성 검사와 같은 복원력 기능을 사용하여 가능한 경우 데이터 무결성 문제를 자동으로 해결합니다.
참고
추가 유효성 검사 기능에 따라 중복 제거는 데이터 손상의 초기 기호를 검색하고 보고할 수 있습니다.
- 최적화 해제. 이 작업은 볼륨에서 최적화된 모든 파일에 대한 중복 제거를 취소합니다. 일반적으로 중복 제거된 데이터 문제 해결 또는 데이터 중복 제거를 지원하지 않는 다른 시스템으로 데이터 마이그레이션을 한 경우 해당 작업을 합니다.
참고
작업을 시작하기 전에 Disable-DedupVolumeWindows PowerShell cmdlet을 통해 하나 이상의 볼륨에서 추가 데이터 중복 제거 작업을 하지 않도록 설정해야 합니다.
참고
데이터 중복 제거를 하지 않도록 설정한 후, 볼륨은 중복 제거된 상태로 유지되고 기존의 중복 제거된 데이터에는 계속 액세스할 수 있습니다. 그러나 서버가 볼륨에 대한 최적화 작업 실행을 중지하고 새 데이터를 중복 제거하지 않습니다. 그런 다음 최적화 해제 작업을 통해 볼륨에서 중복 제거된 기존 데이터를 실행 취소할 수 있습니다. 성공적인 최적화 작업이 끝나면 모든 데이터 중복 제거 메타데이터가 볼륨에서 삭제됩니다.
중요
최적화 해제 작업을 사용하는 경우 중복 제거된 모든 파일이 원래 크기로 되돌아가므로 데이터를 호스팅하는 볼륨에 사용 가능한 공간이 충분한지 확인해야 합니다.
데이터 중복 제거의 범위
데이터 중복 제거는 다음과 같은 몇 가지 예외를 제외하고 선택한 볼륨의 모든 데이터를 처리합니다.
- 구성하는 중복 제거 정책을 충족하지 않는 파일.
- 중복 제거 범위에서 분명히 제외된 폴더의 파일.
- 시스템 상태 파일.
- 대체 데이터 스트림
- 암호화된 파일.
- 확장된 특성이 있는 파일.
- 32KB보다 작은 파일.
참고
Windows Server 2019부터 ReFS(복원 파일 시스템)는 볼륨 크기가 64TB(terabytes) 이하이고 파일 크기가 4TB 이하인 데이터 중복 제거를 지원합니다. 또한 디스크 공간 절약을 최대화하기 위해 선택적 압축을 포함하는 가변 크기의 청크 저장소를 사용합니다. 반면 다중 스레드 후처리 아키텍처는 성능에 거의 영향을 주지 않습니다.