확장 클러스터 구현
기존의 장애 조치(failover) 클러스터는 동일한 물리적 위치에 상주하는 하나 이상의 클러스터 노드로 장애 조치(failover)하여 지역화된 실패로부터 보호하고 고가용성을 제공했습니다. 여러 물리적 위치에서 동등한 기능을 제공해야 하는 경우 스트레치 클러스터를 사용할 수 있습니다.
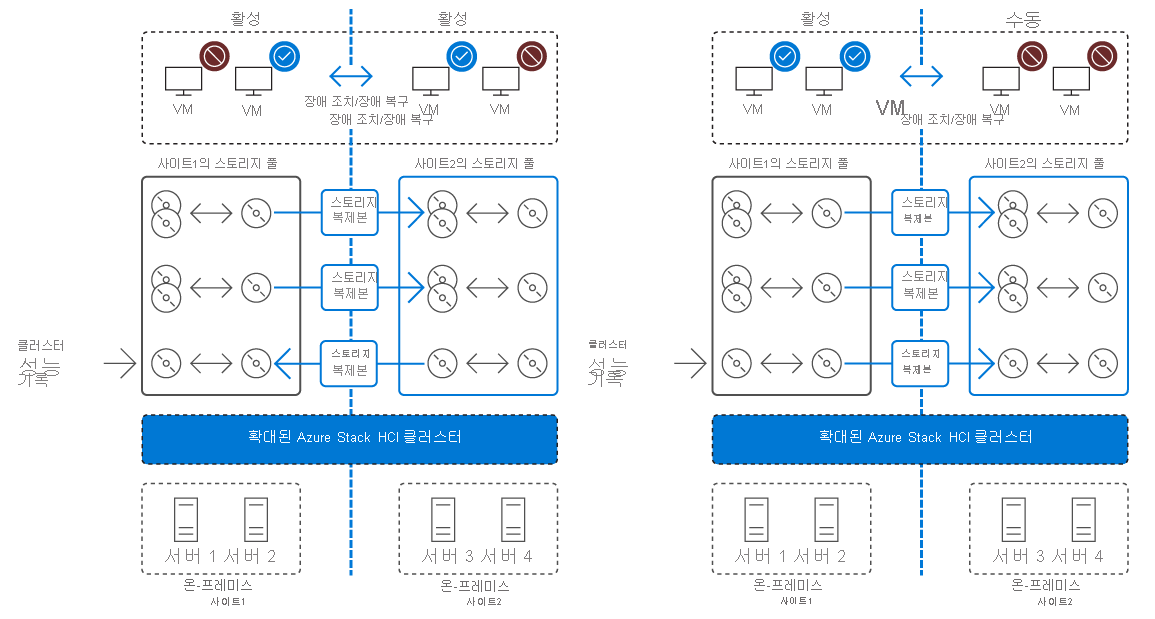
스트레치 클러스터란?
스트레치 클러스터는 별도의 두 물리적 위치에서 고가용성 및 재해 복구를 구현합니다. 두 위치 모두 기본 사이트에서 보조 사이트로의 단방향 동기 복제를 통해 별도의 스토리지 시스템을 호스팅합니다. 오류가 기본 사이트의 가용성에 영향을 주면 가동 중지 시간을 최소화하기 위해 클러스터는 자동으로 해당 워크로드를 보조 사이트의 노드로 전환합니다. 기본 사이트에서 계획된 유지 관리 이벤트의 경우 Hyper-V 실시간 마이그레이션을 사용하여 워크로드를 다른 사이트로 원활하게 전환하여 가동 중지 시간을 완전히 방지할 수 있습니다.
스트레치 클러스터를 사용하면 재해 복구 사이트를 수동으로 유지 관리하는 것에 비해 몇 가지 이점이 있습니다.
- 클러스터형 워크로드의 자동 복제 및 자동 장애 조치(failover)
- 관리 오버헤드를 줄입니다.
- 수동 프로세스에 내재된 사용자 오류의 가능성을 최소화합니다.
반면에 스트레치 클러스터는 디자인과 구현이 더 복잡합니다. 또한 일반적으로 스토리지 및 네트워크 인프라에 대한 추가 투자가 필요합니다.
스토리지 복제본 개요
스트레치 클러스터는 재해 복구를 위해 서버 또는 클러스터 간에 볼륨 복제를 제공하는 Windows Server 기능인 스토리지 복제본을 활용합니다. 스토리지 복제본을 사용하여 스트레치 클러스터는 별도의 두 위치에서 스트레치 클러스터 노드에 연결된 스토리지 볼륨을 동기화할 수 있습니다.
스토리지 복제본은 동기 및 비동기 복제를 지원합니다.
- 동기 복제는 왕복 시간(밀리초) 내에 짧은 대기 시간 네트워크를 통해 데이터를 복제하여 장애 조치(failover) 중에 파일 시스템 수준에서 데이터가 손실되지 않도록 합니다.
- 비동기 복제는 대기 시간이 길지만 장애 조치(failover) 시 두 사이트에 동일한 데이터 복사본이 있다는 보장 없이 더 긴 거리에서 데이터를 복제합니다.
중요합니다
확장 클러스터에는 동기 복제가 필요합니다. 이 요구 사항을 위해 복제된 사이트에서 두 클러스터 노드 그룹 간 왕복 네트워크 대기 시간은 5ms로 제한됩니다. 실제 네트워크 연결 특성에 따라 이 제약 조건은 일반적으로 약 20-30마일의 거리로 변환됩니다.
스토리지 복제본 기능
스토리지 복제본의 주요 기능은 다음 표에 나와 있습니다.
| 특징 | 설명 |
|---|---|
| 블록 수준 복제 | 블록 수준 복제를 사용하면 파일이 잠길 가능성이 없습니다. |
| 단순 | Windows Admin Center에서 두 서버 간 복제 파트너 관계를 만드는 프로세스를 안내받을 수 있습니다. 확장 클러스터를 배포하려면 장애 조치(failover) 클러스터 관리자 기반 마법사를 사용합니다. |
| SMB(서버 메시지 블록) 3.0 사용 | 스토리지 복제본은 Windows Server 2012에서 도입되었으며 이후 버전의 Windows Server에서 상당히 향상된 SMB 3.x를 사용합니다. SMB 다중 채널 및 SMB 다이렉트와 같은 모든 SMB의 고급 특성을 스토리지 복제본에서 사용할 수 있습니다. |
| 안전 | 스토리지 복제본은 패킷 서명, AES-128-GCM 전체 데이터 암호화, 타사 암호화 가속 지원 및 사전 인증 무결성 중간 공격 방지를 비롯한 광범위한 보안 메커니즘을 제공합니다. 또한 스토리지 복제본은 노드 간 모든 인증에 Kerberos AES256을 사용합니다. |
| 네트워크 제약 조건 | 복제된 볼륨 간에 여러 네트워크 경로가 있는 경우 지정된 네트워크 어댑터를 사용하도록 스토리지 복제본 트래픽을 구성할 수 있습니다. 이렇게 하면 복제 트래픽이 프로덕션 워크로드에 미치는 잠재적 영향을 최소화할 수 있습니다. |
| 씬 프로비저닝 | 스토리지 공간 다이렉트에서 씬 프로비저닝을 구현하여 초기 복제 시간을 최소화할 수 있습니다. |
스트레치 클러스터 배포를 위한 필수 구성 요소
확장된 클러스터를 구현하기 위한 필수 구성 요소는 다음과 같습니다.
클러스터 노드는 동일하거나 신뢰할 수 있는 AD DS 포리스트의 멤버여야 합니다.
각 클러스터 노드에는 서버당 2GB 이상의 RAM과 2개의 CPU 코어가 있어야 합니다.
각 클러스터 노드는 Windows Server 2025 Datacenter 또는 Windows Server 2016 Datacenter 버전을 실행해야 합니다. Windows Server 2025 Standard Edition을 사용할 수 있지만 이러한 구성은 크기만 최대 2TB(테라바이트)의 단일 볼륨 복제를 지원합니다.
RDMA(원격 직접 메모리 액세스)가 바람직하지만 각 클러스터 노드에는 동기 복제를 위한 최소 1기가비트 이더넷 어댑터가 있어야 합니다.
기본 사이트와 보조 사이트에서 다음 설정을 사용하여 두 개의 볼륨 집합(데이터용 및 로그에 대한 볼륨)을 설정합니다.
디스크는 MBR(마스터 부트 레코드)이 아닌 GPT(GUID 파티션 테이블)로 초기화되어야 합니다.
- 볼륨은 ReFS 또는 NTFS로 포맷되어야 합니다.
- 데이터 볼륨 크기와 섹터 크기가 일치해야 합니다.
- 로그 볼륨 크기와 섹터 크기가 일치해야 합니다.
- 로그 볼륨이 데이터 볼륨보다 빠른 스토리지를 사용해야 합니다.
- 로그 볼륨은 다른 워크로드에 사용되지 않아야 합니다.
두 사이트 간의 ICMP(인터넷 제어 메시지 프로토콜), SMB(포트 445 및 SMB Direct용 포트 5445) 및 웹 Services-Management(WS-MAN)(포트 5985)를 통한 양방향 연결
클러스터된 워크로드의 I/O 쓰기 및 5ms 미만의 왕복 대기 시간과 일치하기에 충분한 대역폭이 있는 서버 간의 네트워크입니다.
스트레치 클러스터 배포에 대한 고려 사항
스트레치 클러스터는 모든 워크로드 및 모든 시나리오에 적합하지 않습니다. 스트레치 클러스터 솔루션을 설계할 때 조직의 요구 사항 및 기대치를 명확하게 식별합니다. 또한 스트레치 클러스터는 모든 노드가 동일한 물리적 위치 내에 있는 기존 클러스터보다 더 많은 관리 오버헤드를 부과한다는 사실에 유의하세요. 또한 전체 물리적 사이트에 영향을 주는 재해가 발생할 경우 가용성을 최대화하기 위해 쿼럼 감시의 최적의 선택을 신중하게 고려해야 합니다.
중요합니다
Microsoft SQL Server, Hyper-V, Microsoft Exchange Server 및 AD DS와 같은 상태 저장 애플리케이션 및 서비스는 고가용성을 위해 스트레치 클러스터를 사용하는 대신 고유한 네이티브 복원력 메커니즘을 사용해야 합니다.
확장 클러스터의 장애 조치(failover) 및 장애 복구(failback) 시 고려 사항
스트레치 클러스터 배포 계획의 일환으로 다음 고려 사항을 고려하여 장애 조치(failover) 및 장애 복구(failback) 구성을 정의해야 합니다.
- 인프라 종속성. 보조 사이트로 장애 조치(failover) 후 계속 사용할 수 있어야 하는 AD DS, DNS 및 DHCP와 같은 중요한 서비스를 명확하게 정의해야 합니다.
- 쿼럼 모델. 장애 조치(failover) 후 클러스터 기능을 유지하는 쿼럼 모델을 선택하는 것이 중요합니다.
- 서비스 게시 및 이름 확인. 내부 또는 외부 사용자에게 게시되는 전자 메일 및 웹 페이지와 같은 서비스가 있는 경우, 일부 경우에는 다른 사이트로 장애 극복을 위해 이름 또는 IP 주소를 변경해야 할 수 있습니다. 이 경우 내부 또는 공용 DNS에서 DNS 레코드를 변경하는 절차가 있어야 합니다. 가동 중지 시간을 줄이려면 중요한 DNS 레코드의 TTL(Time to Live) 값을 줄이는 것이 좋습니다.
- 클라이언트 연결. 재해가 발생할 경우 장애 조치(failover) 계획은 클라이언트 애플리케이션에서 클러스터된 워크로드로의 연결을 수용해야 합니다. 여기에는 내부 및 외부 클라이언트가 모두 포함됩니다.
- 장애 복구(failback) 절차. 기본 사이트가 다시 온라인 상태가 된 후 수행할 장애 복구 프로세스를 계획하고 구현해야 합니다. 장애 복구는 장애 조치(failover)와 마찬가지로 중요합니다. 잘못 수행하면 데이터 손실 및 서비스 가동 중지 시간이 발생할 수 있기 때문입니다.
스트레치 클러스터 만들기
Windows Admin Center, 장애 조치(failover) 클러스터 관리자 또는 Windows PowerShell을 사용하여 스트레치 클러스터를 만들 수 있습니다. Windows Admin Center는 프로비저닝 프로세스를 안내하고 대부분의 구성 작업을 자동화하여 스트레치 클러스터의 구현을 간소화합니다. 여기에는 다음에 대한 지원이 포함됩니다.
- 하이퍼컨버지드 클러스터(페일오버 클러스터링, 하이퍼-V, 스토리지 스페이스 다이렉트).
- 스토리지 클러스터(장애 조치 클러스터링 및 스토리지 스페이스 다이렉트).
비고
장애 조치(failover) 클러스터 관리자 또는 Windows PowerShell을 사용하여 스트레치 클러스터를 만드는 것이 더 복잡합니다. 두 방법 모두 각 중간 구현 단계를 수행해야 합니다. 가장 간단한 용어로, 기본 및 보조 사이트의 모든 노드로 구성된 기존의 확장되지 않은 장애 조치(failover) 클러스터를 만드는 것으로 시작합니다. 클러스터를 만들고 유효성 검사를 완료한 후 각 사이트에서 별도의 스토리지 볼륨 집합을 만듭니다. 마지막으로 두 사이트 간에 스토리지 볼륨을 복제하도록 스토리지 복제본을 구성합니다.