순환 신경망을 사용하여 패턴 캡처
이전 단원에서는 텍스트의 풍부한 의미 체계 표현을 설명했습니다. 사용했던 아키텍처는 문장에서 단어의 집계된 의미를 캡처하지만 포함 뒤에 오는 집계 작업이 원래 텍스트에서 이 정보를 제거하므로 단어 의 순서 를 고려하지 않습니다. 이러한 모델은 단어 순서를 나타낼 수 없으므로 텍스트 생성 또는 질문 답변과 같은 더 복잡하거나 모호한 작업을 해결할 수 없습니다.
텍스트 시퀀스의 의미를 포착하기 위해 되풀이 신경망 또는 RNN이라는 신경망 아키텍처를 사용합니다. RNN을 사용하는 경우 한 번에 하나의 토큰으로 네트워크를 통해 문장을 전달하고, 네트워크는 일부 상태를 생성한 다음, 다음 토큰을 사용하여 네트워크에 다시 전달합니다.
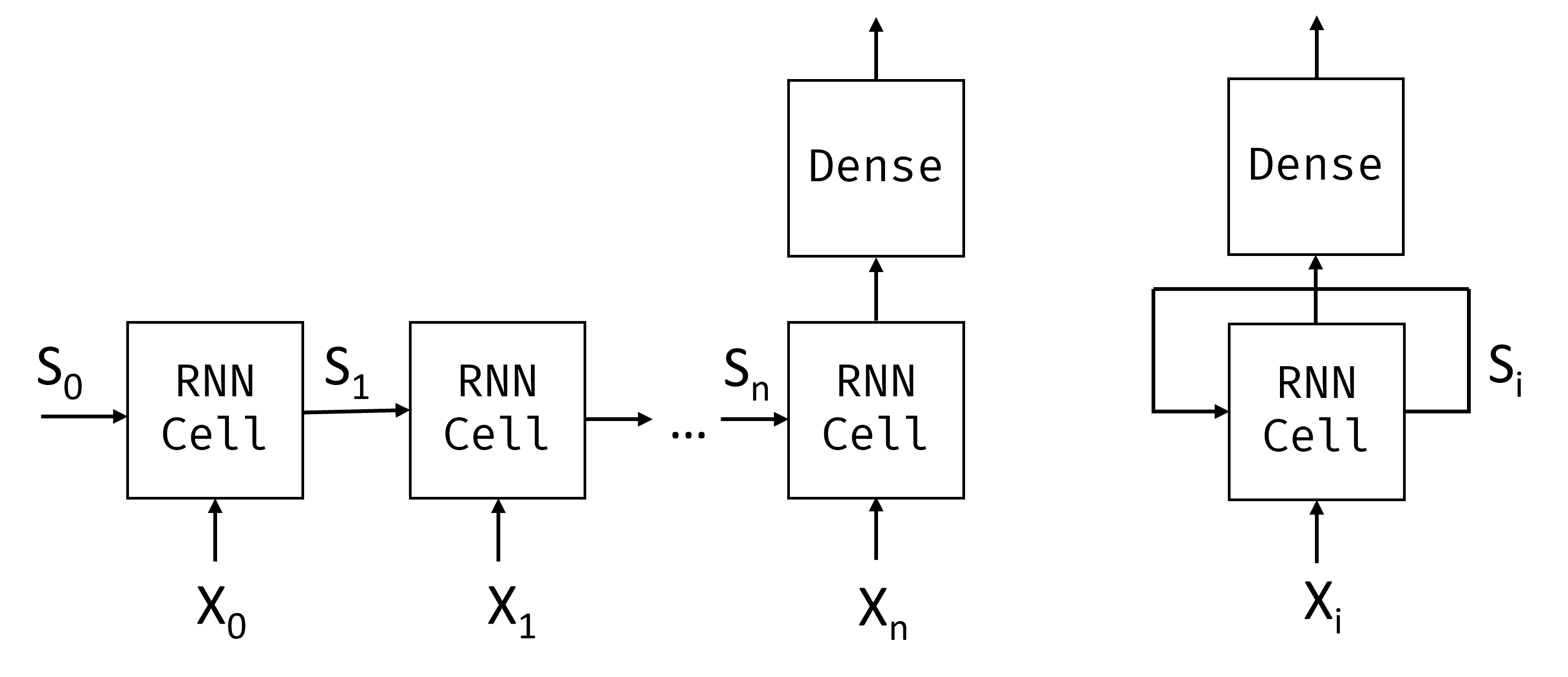
토큰 $X_0,\dots,X_n$의 입력 시퀀스를 감안할 때 RNN은 신경망 블록 시퀀스를 만들고 백프로포지션을 사용하여 이 시퀀스 엔드투엔드 학습을 수행합니다. 각 네트워크 블록은 $(X_i,S_i)$ 쌍을 입력으로 사용하고 결과적으로 $S_{i+1}$를 생성합니다. 최종 상태 $S_n$ 또는 출력 $Y_n$은 선형 분류자로 전환되어 결과를 생성합니다. 모든 네트워크 블록은 동일한 가중치를 공유하며 하나의 백프로포지션 패스를 사용하여 엔드 투 엔드로 학습됩니다.
상태 벡터 $S_0,\dots,S_n$은 네트워크를 통해 전달되므로 RNN은 단어 간의 순차적 종속성을 학습할 수 있습니다. 예를 들어 시퀀스의 어딘가에 단어 not이 나타나면, 상태 벡터 내의 특정 요소를 부정하는 방법을 배울 수 있습니다.
내부에는 각 RNN 셀에는 $W_H$ 및 $W_I$의 두 가지 가중치 행렬과 바이어스 $b$가 포함되어 있습니다. 입력 $X_i$ 및 입력 상태 $S_i$가 지정된 각 RNN 단계에서 출력 상태는 $S_{i+1} = f(W_H\times S_i + W_I\times X_i+b)$로 계산됩니다. 여기서 $f$는 활성화 함수(종종 $\tanh$)입니다.
메모
텍스트 생성 또는 기계 번역과 같은 문제로 각 RNN 단계에서 일부 출력 값을 구하려고 합니다. 이 경우 다른 행렬 $W_O$도 있으며 출력은 $Y_i=f(W_O\times S_{i+1}+b_O)$로 계산됩니다. 여기서 $S_{i+1}$는 현재 단계에서 업데이트된 상태입니다.
되풀이 신경망이 다음 코드로 뉴스 데이터 세트를 분류하는 데 어떻게 도움이 되는지 살펴보겠습니다.
import tensorflow as tf
import keras
import tensorflow_datasets as tfds
import numpy as np
# We are going to be training pretty large models. In order not to face errors, we need
# to set tensorflow option to grow GPU memory allocation when required
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices)>0:
tf.config.set_memory_growth(physical_devices[0], True)
dataset = tfds.load('ag_news_subset')
ds_train = dataset['train']
ds_test = dataset['test']
큰 모델을 학습할 때 GPU 메모리 할당이 문제가 될 수 있습니다. 또한 데이터가 GPU 메모리에 맞도록 다양한 미니배치 크기를 실험해야 할 수도 있지만 학습은 충분히 빠릅니다. 사용자 고유의 GPU 컴퓨터에서 이 코드를 실행하는 경우 학습 속도를 높이기 위해 미니배치 크기를 조정하는 실험을 할 수 있습니다.
메모
nVidia 드라이버의 특정 버전은 모델을 학습한 후 메모리를 해제하지 않는 것으로 알려져 있습니다. 이 단원에서는 몇 가지 예제를 실행하고 있으며, 특히 사용자 고유의 실험을 수행하는 경우 특정 설정에서 메모리가 소진될 수 있습니다. 모델 학습을 시작할 때 몇 가지 비정상적인 오류가 발생하는 경우 Python 환경을 다시 시작할 수 있습니다.
batch_size = 16
embed_size = 64
단순 RNN 분류자
간단한 RNN의 경우 각 되풀이 단위는 입력 벡터 및 상태 벡터를 사용하고 새 상태 벡터를 생성하는 간단한 선형 네트워크입니다. Keras에서는 SimpleRNN 계층으로 이를 나타낼 수 있습니다.
원 핫 인코딩된 토큰을 RNN 계층에 직접 전달할 수 있지만, 차원이 너무 높아 좋은 방법은 아닙니다. 따라서 포함 계층을 사용하여 단어 벡터의 차원을 축소하고, RNN 계층 및 마지막으로 Dense 분류자를 사용합니다.
메모
예를 들어 문자 수준 토큰화를 사용하는 경우와 같이 차원이 너무 높지 않은 경우 원 핫 인코딩된 토큰을 RNN 셀에 직접 전달하는 것이 합리적일 수 있습니다.
# We use a smaller vocabulary (20,000) here than in previous units because
# RNN models have more parameters per token, and a smaller vocabulary
# helps keep training time and memory usage manageable.
vocab_size = 20000
vectorizer = keras.layers.TextVectorization(max_tokens=vocab_size)
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.summary()
이 코드를 실행하면 다음과 같은 출력이 생성됩니다.
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ text_vectorization │ (None, None) │ 0 │
│ (TextVectorization) │ │ │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ embedding (Embedding) │ (None, None, 64) │ 1,280,000 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ simple_rnn (SimpleRNN) │ (None, 16) │ 1,296 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 4) │ 68 │
└──────────────────────────────┴───────────────────────────┴───────────────┘
Total params: 1,281,364 (4.89 MB)
Trainable params: 1,281,364 (4.89 MB)
Non-trainable params: 0 (0.00 B)
메모
여기서는 단순성을 위해 학습되지 않은 포함 계층을 사용하지만, 더 나은 결과를 위해 이전 단원에서 설명한 대로 Word2Vec를 사용하여 미리 학습된 포함 계층을 사용할 수 있습니다. 미리 학습된 임베딩과 작동하도록 이 코드를 조정해보는 것이 좋은 연습이 될 것입니다.
이제 RNN을 학습해 보겠습니다. 일반적으로 RNN은 학습하기 어렵습니다. 이는 RNN 셀이 시퀀스의 길이에 따라 펼쳐지면, 역전파에 관여하는 레이어 수가 많아지기 때문입니다. 따라서 더 작은 학습 속도를 선택하고 더 큰 데이터 세트에서 네트워크를 학습시켜 좋은 결과를 생성해야 합니다. 시간이 오래 걸릴 수 있으므로 GPU를 사용하는 것이 좋습니다.
속도를 높이기 위해 뉴스 제목에 대한 RNN 모델만 학습하고 설명을 생략합니다. 설명을 사용하여 학습을 시도하고 학습할 모델을 가져올 수 있는지 확인할 수 있습니다.
def extract_title(x):
return x['title']
def tupelize_title(x):
return (extract_title(x),x['label'])
print('Training vectorizer')
vectorizer.adapt(ds_train.take(2000).map(extract_title))
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize_title).batch(batch_size),validation_data=ds_test.map(tupelize_title).batch(batch_size))
메모
여기서는 뉴스 타이틀에 대해서만 학습하기 때문에 정확도가 낮을 수 있습니다.
변수 시퀀스를 다시 검토하기
레이어는 TextVectorization 패드 토큰이 있는 미니배치에서 가변 길이의 시퀀스를 자동으로 패딩합니다. 이러한 토큰도 학습에 참여하고 모델의 수렴을 복잡하게 만들 수 있습니다.
안쪽 여백의 양을 최소화하기 위해 취할 수 있는 몇 가지 방법이 있습니다. 그 중 하나는 시퀀스 길이별로 데이터 세트의 순서를 다시 지정하고 모든 시퀀스를 크기별로 그룹화하는 것입니다. 이 작업은 함수를 tf.data.bucket_by_sequence_length 사용하여 수행할 수 있습니다( 설명서 참조).
또 다른 방법은 마스킹을 사용하는 것입니다. Keras에서 일부 계층은 학습 시 고려해야 할 토큰을 보여 주는 추가 입력을 지원합니다. 마스킹을 모델에 통합하기 위해 별도의 Masking 계층(문서)을 포함하거나 레이어의 mask_zero=True 매개 변수를 Embedding 지정할 수 있습니다.
메모
사용하는 mask_zero=True경우 토큰 인덱스 0은 패딩으로 처리되며 유효한 어휘 항목이 아닙니다. 즉, 모든 어휘 단어 인덱스가 하나씩 이동됩니다. 계층은 TextVectorization 기본적으로 패딩을 위해 인덱스 0을 이미 예약하므로 두 항목이 함께 사용될 때 원활하게 작동합니다.
def extract_text(x):
return x['title']+' '+x['description']
def tupelize(x):
return (extract_text(x),x['label'])
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size,embed_size,mask_zero=True),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
이제 마스킹을 사용하므로 타이틀 및 설명의 전체 데이터 세트에서 모델을 학습시킬 수 있습니다.
LSTM: 장단기 메모리
RNN의 주요 문제 중 하나는 그라데이션이 사라지는 것입니다. RNN은 길 수 있으며 백프로포지션 중에 그라데이션을 네트워크의 첫 번째 계층으로 전파하는 데 어려움이 있을 수 있습니다. 이 경우 네트워크에서 먼 토큰 간의 관계를 배울 수 없습니다. 이 문제를 방지하는 한 가지 방법은 게이트를 사용하여 명시적 상태 관리를 도입하는 것입니다. 게이트를 도입하는 가장 일반적인 두 가지 아키텍처는 LSTM( 장기 메모리 )과 GRU( 제어된 되풀이 단위 )입니다. 여기서는 LSTM을 다룹니다.

LSTM 네트워크는 RNN과 유사한 방식으로 구성되지만 계층에서 계층으로 전달되는 두 가지 상태, 즉 실제 상태 $c$와 숨겨진 벡터 $h$가 있습니다. 각 단위에서 숨겨진 벡터 $h_{t-1}$은 입력 $x_t$와 결합되며, 함께 상태 $c_t$에 어떤 일이 일어나는지 제어하고 게이트를 통해 $h_{t}$ 출력합니다. 각 게이트에는 시그모이드 활성화($[0,1]$범위의 출력)가 있으며, 상태 벡터를 곱할 때 비트 마스크로 생각할 수 있습니다. LSTM에는 Olah 블로그의 규칙에 따라 위의 그림에서 왼쪽에서 오른쪽으로 다음과 같은 게이트가 있습니다.
- 망각 게이트는 벡터 $c_{t-1}$의 어떤 구성 요소를 잊고 어떤 것을 통과시킬지를 결정합니다.
- 입력 벡터 및 이전 숨겨진 벡터의 정보를 상태 벡터에 통합해야 하는 양을 결정하는 입력 게이트입니다.
- 새 상태 벡터를 사용하고 새 숨겨진 벡터 $h_t$를 생성하는 데 사용할 구성 요소를 결정하는 출력 게이트입니다.
상태 $c$의 구성 요소는 켜고 끌 수 있는 플래그로 생각할 수 있습니다. 예를 들어 시퀀스에서 Alice 라는 이름이 발견되면 여성을 가리키는 것으로 추측하고 문장에 여성 명사가 있다고 말하는 상태에서 플래그를 올립니다. 우리가 단어 그리고 톰을 더 만날 때, 우리가 복수 명사를 가지고 있다는 깃발을 올릴 것입니다. 따라서 상태를 조작하여 문장의 문법 속성을 추적할 수 있습니다.
LSTM 셀의 내부 구조는 복잡해 보일 수 있지만 Keras는 계층 내에서 LSTM 이 구현을 숨기므로 위의 예제에서 수행해야 하는 유일한 작업은 되풀이 계층을 바꾸는 것입니다.
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.LSTM(8),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
메모
LSTM 학습도 느리며, 학습 초반에는 정확도가 크게 향상되지 않을 수 있습니다. 정확한 정확도를 얻으려면 일정 시간 동안 학습을 계속해야 할 수 있습니다.
양방향 및 다층 RNN
지금까지의 예제에서 되풀이 네트워크는 시퀀스의 시작부터 끝까지 작동합니다. 이것은 우리가 읽거나 연설을 듣는 것과 같은 방향을 따르기 때문에 우리에게 자연스러운 느낌입니다. 그러나 입력 시퀀스에 임의로 액세스해야 하는 시나리오의 경우 양방향으로 되풀이 계산을 실행하는 것이 더 합리적입니다. 양방향으로 계산을 허용하는 RNN을 양방향 RNN이라고 하며, 되풀이 계층을 특수 Bidirectional 계층으로 래핑하여 만들 수 있습니다.
메모
레이어는 자체 내부에 있는 레이어의 두 복사본을 만들고, 그 복사본 중 하나의 Bidirectional 속성을 go_backwards으로 설정하여 시퀀스를 따라 반대 방향으로 이동하게 합니다.
되풀이 네트워크, 단방향 또는 양방향 네트워크는 시퀀스 내에서 패턴을 캡처하고 상태 벡터에 저장하거나 출력으로 반환합니다. 나선형 네트워크와 마찬가지로 첫 번째 계층에 따라 다른 되풀이 계층을 빌드하여 첫 번째 계층에서 추출한 하위 수준 패턴에서 빌드된 더 높은 수준의 패턴을 캡처할 수 있습니다. 따라서 이전 계층의 출력이 입력으로 다음 계층에 전달되는 두 개 이상의 되풀이 네트워크로 구성된 다중 계층 RNN의 개념으로 이어집니다.
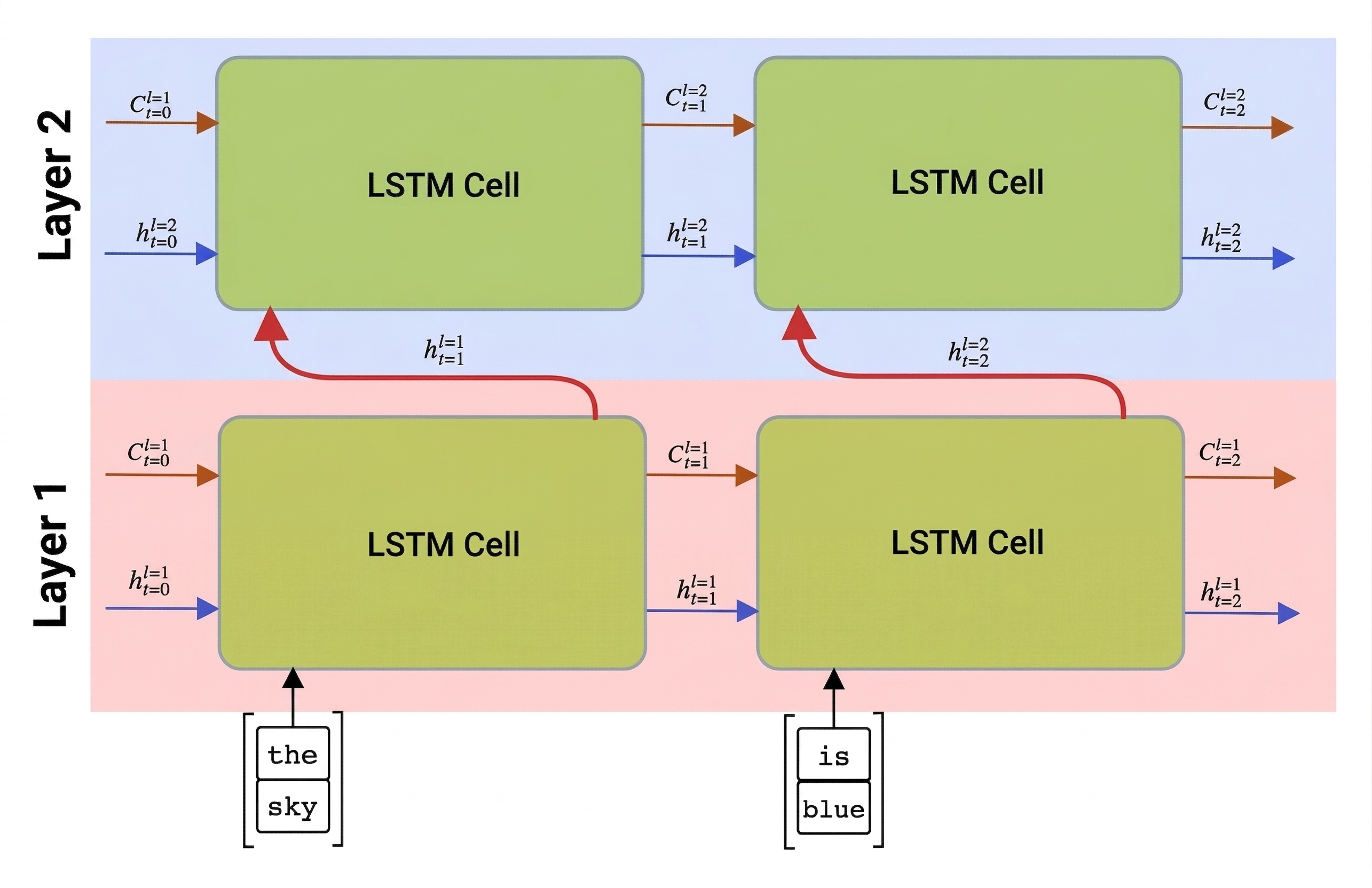
페르난도 로페즈의 이 다층 LSTM 관련 게시물에서 가져온 사진.
Keras를 사용하면 모델에 되풀이 계층을 더 추가하기만 하면 되므로 이러한 네트워크를 쉽게 생성할 수 있습니다. 마지막 계층을 제외한 모든 계층의 경우 반복 계산의 최종 상태뿐만 아니라 모든 중간 상태를 반환하는 계층이 필요하기 때문에 매개 변수를 지정 return_sequences=True 해야 합니다.
다음 코드는 분류 문제에 대한 2층 양방향 LSTM을 구현합니다.
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, 128, mask_zero=True),
keras.layers.Bidirectional(keras.layers.LSTM(64,return_sequences=True)),
keras.layers.Bidirectional(keras.layers.LSTM(64)),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),
validation_data=ds_test.map(tupelize).batch(batch_size))