Azure Data Explorer 작동 방식
이 단원에서는 시스템의 주요 구성 요소를 토론하여 Azure Data Explorer가 백그라운드에서 어떻게 작동하는지 살펴봅니다. 그런 다음 일반적인 워크플로를 탐색하여 서비스와 상호 작용하는 방법을 알아봅니다.
- 데이터 수집
- Kusto 쿼리 언어
- 데이터 시각화
이 지식은 Azure Data Explorer가 데이터 요구 사항에 적합한지 결정하는 데 도움이 됩니다.
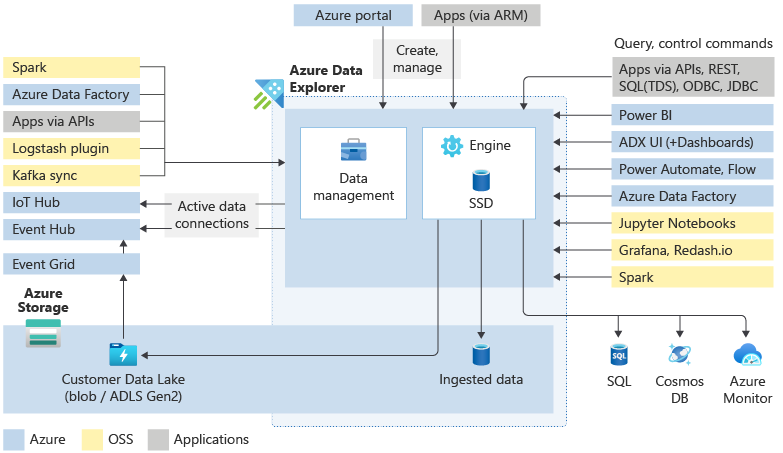
주요 구성 요소
Azure Data Explorer 클러스터는 데이터를 수집, 처리, 쿼리하기 위한 모든 작업을 수행합니다. 클러스터는 필요에 따라 자동 확장이 가능합니다. 또한 Azure Data Explorer는 Azure Storage에 데이터를 저장하고 클러스터 컴퓨팅 노드에 일부 데이터를 캐시하여 최적의 쿼리 성능을 달성합니다.
Azure Data Explorer 클러스터에는 어떤 항목이 포함되어 있나요?
각 Azure Data Explorer 클러스터는 최대 10,000개의 데이터베이스를 포함할 수 있고 각 데이터베이스는 최대 10,000개의 테이블을 포함할 수 있습니다. 각 테이블의 데이터는 익스텐트라는 데이터 분할 데이터베이스에 저장됩니다. 모든 데이터는 수집 시간에 따라 자동으로 인덱싱되고 분할됩니다. 관계형 데이터베이스와 달리, 기본 외래 키 제약 조건이나 고유성과 같은 다른 제약 조건이 없습니다. 이 디자인은 대량의 다양한 데이터를 저장할 수 있음을 의미합니다. 그리고 저장 방식 때문에 쿼리에 빠르게 액세스할 수 있습니다.
데이터베이스의 논리 구조는 다른 많은 관계형 데이터베이스와 비슷합니다. Azure Data Explorer 데이터베이스에는 다음이 포함될 수 있습니다.
- 테이블: 열 세트로 구성됩니다. 각 열은 9개의 데이터 형식 중 하나입니다.
- 외부 테이블: 기본 스토리지가 Azure Data Lake 등의 다른 위치에 있는 테이블입니다.
일반 워크플로 알아보기
일반적으로 Azure Data Explorer와 상호 작용할 때 다음 워크플로를 진행합니다. 먼저 데이터를 수집하여 시스템에 가져옵니다. 그런 다음 데이터를 분석합니다. 다음으로 분석 결과를 시각화합니다. 언제든지 데이터 관리 기능을 사용할 수도 있습니다. 이러한 Azure Data Explorer를 통한 작업은 클러스터와의 상호 작용을 통해 수행됩니다. 웹 UI에서 또는 SDK를 사용하여 이러한 리소스에 액세스할 수 있습니다.
내 데이터를 Azure Data Explorer로 가져오려면 어떻게 하나요?
데이터 수집은 하나 이상의 원본에 있는 데이터 레코드를 Azure Data Explorer의 테이블로 로드하는 데 사용되는 프로세스입니다. 그 외에도 스키마 매칭, 데이터 구성, 데이터 인덱싱, 데이터 인코딩, 데이터 압축 등의 데이터 조작이 더 있습니다. 그러면 Data Manager는 쿼리에 사용할 수 있는 엔진에 데이터를 수집합니다.
네이티브 웹 UI 마법사 외에도 다양한 수집 도구를 사용할 수 있습니다. 관리 파이프라인, Event Grid, IoT Hub 및 Azure Data Factory가 포함됩니다. Logstash 플러그 인, Kafka 커넥터, Power Automate, Apache Spark 커넥터 등의 커넥터와 플러그 인을 사용할 수 있습니다. SDK 또는 LightIngest를 사용하여 프로그래밍 방식의 수집을 사용할 수도 있습니다.
데이터는 일괄 처리 또는 스트리밍의 두 가지 모드로 수집할 수 있습니다. 일괄 처리 수집은 높은 수집 처리량 및 빠른 쿼리 결과에 최적화되어 있습니다. 스트리밍 수집은 테이블마다 소량의 데이터 세트에 대해 거의 실시간 대기 시간을 허용합니다.
데이터를 분석하려면 어떻게 하나요?
Azure Data Explorer는 독점 KQL(Kusto 쿼리 언어)을 사용하여 데이터를 분석합니다. Microsoft(Azure Monitor - Log Analytics 및 Application Insights, Microsoft Sentinel 및 Microsoft Defender XDR)에서 널리 사용됩니다. KQL은 빠르게 흐르는 다양한 빅 데이터 탐색에 최적화되어 있습니다. 쿼리는 테이블, 뷰, 함수, 기타 테이블 형식 식을 참조합니다. 다른 데이터베이스 또는 클러스터의 테이블을 포함합니다. 쿼리는 웹 UI, 다양한 쿼리 도구 또는 Azure Data Explorer SDK 중 하나를 사용하여 실행할 수 있습니다.
Kusto 쿼리 언어는 어떻게 작동하나요?
Kusto 쿼리 언어는 표현적이고 간편하며 생산성이 뛰어난 쿼리 언어입니다. 간단한 한 줄에서 복잡한 데이터 처리 스크립트까지 원활하게 전환할 수 있도록 하며, 정형, 반정형, 비정형(텍스트 검색) 데이터 쿼리하도록 지원합니다. 다양한 쿼리 언어 연산자 및 함수(집계, 필터링, 시계열 함수, 지리 공간적 함수, 조인, 합집합 등) 언어로 제공됩니다. KQL은 클러스터 간 및 데이터베이스 간 쿼리를 지원하며 구문 분석(json, XML 등) 관점에서 풍부한 기능을 제공합니다. 또한 이 언어는 기본적으로 고급 분석을 지원합니다.
쿼리 결과를 표시하려면 어떻게 하나요?
Azure Data Explorer 웹 UI는 빅 데이터를 염두에 두고 설계되어 쿼리를 실행하고 대시보드를 빌드할 수 있도록 합니다. 최대 500,000개 레코드와 수천 개의 열 표시를 지원합니다. 스케일링 성능이 뛰어나고 데이터에서 빠른 인사이트를 얻을 수 있는 풍부한 기능을 제공합니다. Azure Data Explorer 대시보드에서 데이터의 다양한 시각적 표시를 사용할 수도 있습니다. 네이티브 커넥터를 사용하여 현재 사용할 수 있는 몇 가지 주요 시각화 서비스(예: Power BI 및 Grafana)에 결과를 표시할 수도 있습니다. Azure Data Explorer에서는 Tableau 및 Qlik과 같은 도구에 대한 ODBC 및 JDBC 커넥터도 지원합니다.
내 데이터를 관리하려면 어떻게 하나요?
관리자는 Azure Data Explorer 클러스터에서 다양한 유지 관리 및 정책 작업을 수행하려고 하며 제어 명령을 통해 이를 수행할 수 있습니다. 제어 명령을 사용하여 새 클러스터 또는 데이터베이스를 만들고, 데이터 연결을 설정하고, 자동 크기 조정을 수행하고, 클러스터 구성을 조정할 수 있습니다. 또한 엔터티, 메타데이터 개체, 권한 관리 및 보안 정책을 제어하고 수정할 수도 있습니다. 또한 이러한 명령은 구체화된 뷰(지속적으로 업데이트되는 다른 테이블의 필터링된 뷰), 함수(저장된 함수 및 사용자 정의 함수) 및 업데이트 정책(수집 이후에 트리거되는 함수)을 수정할 수 있습니다.
제어 명령은 WebUI, Azure Portal, 다양한 쿼리 도구 또는 Azure Data Explorer SDK 중 하나를 사용하여 엔진에서 직접 실행됩니다.